NVIDIA TensorRT-LLM cho phép các nhà phát triển xây dựng các engine suy luận (inference engines) hiệu suất cao cho các mô hình ngôn ngữ lớn (LLM). Tuy nhiên, việc triển khai một kiến trúc mới theo cách truyền thống đòi hỏi một nỗ lực lập trình thủ công khổng lồ. Để giải quyết thách thức này, NVIDIA đã chính thức ra mắt AutoDeploy dưới dạng tính năng beta trong TensorRT-LLM.
AutoDeploy biên dịch các mô hình PyTorch có sẵn (off-the-shelf) thành các đồ thị (computation graphs) đã được tối ưu hóa cho inference. Điều này giúp loại bỏ việc phải nhúng trực tiếp các tối ưu hóa đặc thù của suy luận vào mã nguồn mô hình, từ đó giảm thiểu thời gian triển khai LLM. AutoDeploy tạo ra một sự dịch chuyển lớn: từ việc triển khai lại và tối ưu hóa thủ công từng mô hình sang một workflow dựa trên trình biên dịch (compiler-driven), giúp tách biệt rõ ràng giữa quá trình thiết kế mô hình (model authoring) và tối ưu hóa inference.
Bài viết này sẽ giới thiệu kiến trúc, các khả năng của AutoDeploy, và cách công cụ này hỗ trợ các mô hình NVIDIA Nemotron mới nhất ngay từ khi ra mắt.
AutoDeploy là gì?
Mỗi kiến trúc LLM mới đều đi kèm với những thách thức inference riêng biệt, từ các mô hình transformer tiêu chuẩn, mô hình ngôn ngữ thị giác lai (VLMs) cho đến các mô hình không gian trạng thái (SSMs). Để biến một bản triển khai tham chiếu (reference implementation) thành một engine suy luận hiệu suất cao, bạn thường phải tự tay xây dựng hệ thống quản lý KV cache, phân mảnh trọng số (sharding) trên nhiều GPU, gộp các phép toán (kernel fusion) và tinh chỉnh đồ thị thực thi cho phần cứng cụ thể.
AutoDeploy chuyển đổi workflow này sang một phương pháp tiếp cận dựa trên trình biên dịch (compiler). Thay vì yêu cầu AI Developer tự viết lại logic inference, AutoDeploy tự động trích xuất một computation graph từ một mô hình PyTorch nguyên bản và áp dụng một loạt các phép biến đổi tự động để tạo ra đồ thị TensorRT-LLM đã được tối ưu hóa. Điều này cho phép bạn định nghĩa mô hình một lần duy nhất bằng PyTorch và ủy thác mọi mối bận tâm về inference — như caching, sharding, lựa chọn kernel, và tích hợp runtime — cho compiler và runtime xử lý.
Phương pháp này đặc biệt lý tưởng cho các mô hình “long-tail”, bao gồm các kiến trúc nghiên cứu mới, các biến thể nội bộ và các mô hình mã nguồn mở thay đổi nhanh chóng, nơi việc tự viết lại code thường tốn kém và không khả thi. AutoDeploy cho phép triển khai ngay lúc mô hình ra mắt với hiệu suất cơ sở cạnh tranh, đồng thời giữ nguyên lộ trình tối ưu hóa tăng dần khi mô hình dần hoàn thiện.
Các tính năng cốt lõi của AutoDeploy:
-
Dịch mô hình liền mạch: Tự động chuyển đổi các mô hình Hugging Face thành các đồ thị TensorRT-LLM mà không cần viết lại mã.
-
Nguồn sự thật duy nhất (Single source of truth): Giữ nguyên mô hình PyTorch gốc làm định nghĩa chuẩn mực.
-
Tối ưu hóa Inference: Áp dụng sharding, lượng tử hóa (quantization), chèn KV cache, attention fusion, tối ưu hóa CUDA Graphs và nhiều tính năng khác.
-
Triển khai tại thời điểm ra mắt (Deployment at launch): Cho phép tích hợp hệ thống ngay lập tức với các cải tiến hiệu suất liên tục theo thời gian.
-
Thiết lập Turnkey: Được tích hợp sẵn như một phần của TensorRT-LLM với các ví dụ và tài liệu đầy đủ.
Use-case của AutoDeploy:
-
Kiến trúc mới hoặc thử nghiệm: Triển khai thần tốc các mô hình nghiên cứu, thiết kế hybrid hoặc các cơ chế attention mới.
-
Hỗ trợ mô hình “long-tail”: Phục vụ các mô hình nội bộ, fine-tuned mà không cần các bản triển khai chuyên biệt.
-
Tăng tốc hiệu suất nhanh chóng: Đạt baseline hiệu suất cạnh tranh ngay lập tức, sau đó tối ưu hóa từ từ.
-
Workflow thống nhất từ Training đến Inference: Dùng PyTorch cho định nghĩa mô hình, dùng TensorRT-LLM cho tích hợp runtime.
Nền tảng kỹ thuật của AutoDeploy
AutoDeploy nằm giữa mô hình Hugging Face gốc và runtime của TensorRT-LLM. LLM API nhận vào tên mô hình hoặc thư mục checkpoint và trả về một đối tượng LLM cấp cao. Ở tầng dưới, đối tượng đó có thể chạy bằng backend AutoDeploy (tự động) hoặc backend thủ công.
Như Hình 1 bên dưới biểu diễn, luồng AutoDeploy tự động trích xuất đồ thị, áp dụng các kỹ thuật tối ưu hóa và sinh ra một đồ thị suy luận tối ưu. Ngược lại, luồng thủ công đòi hỏi kỹ sư phải tự viết lại mô hình (thêm logic KV cache, attention kernels, sharding, kernel fusion…) trước khi đưa vào runtime.
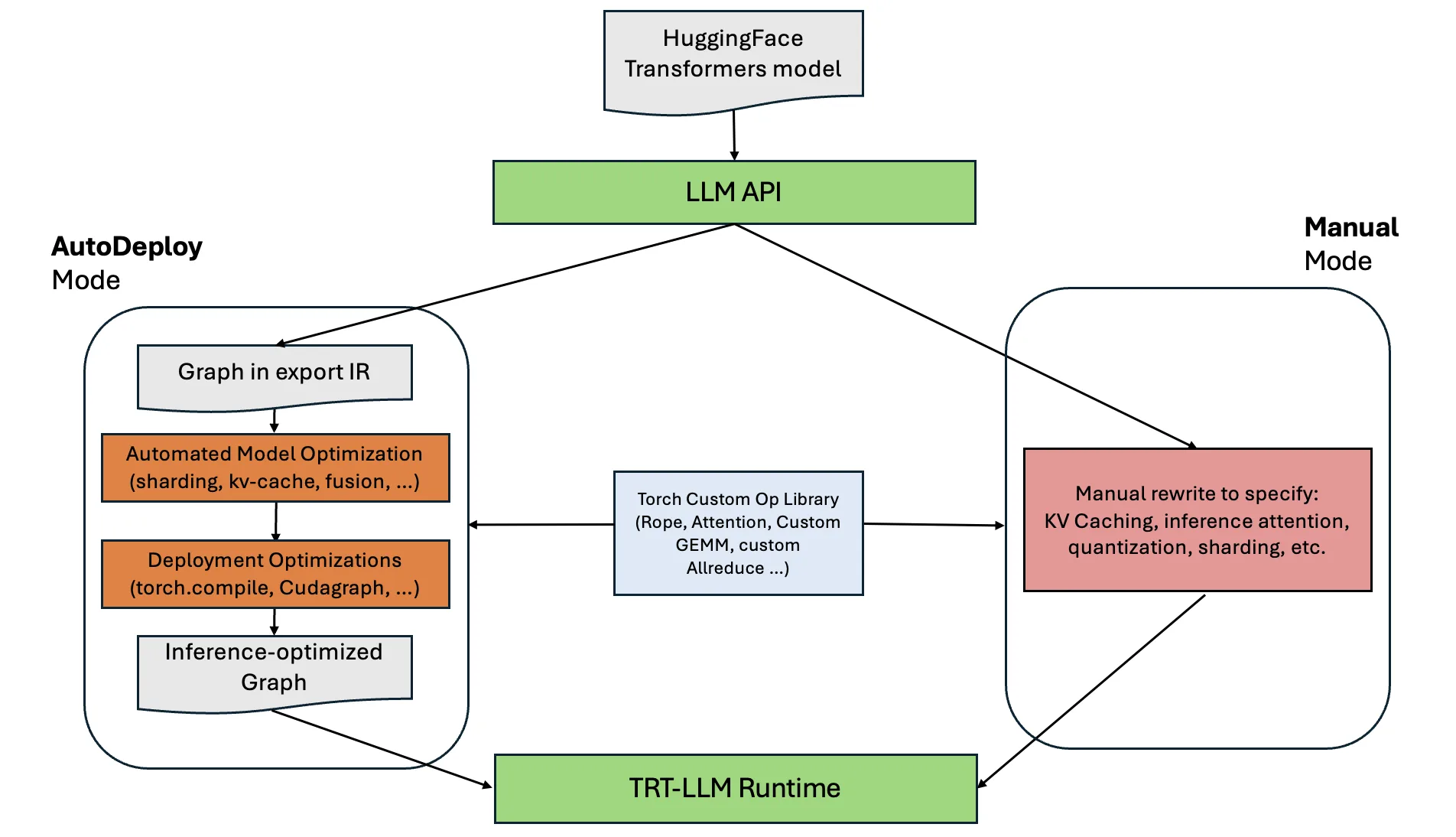
(Hình 1: Tổng quan về chế độ AutoDeploy và quá trình tích hợp vào TensorRT-LLM runtime)
Chụp đồ thị và khớp mẫu (Graph capture and pattern matching)
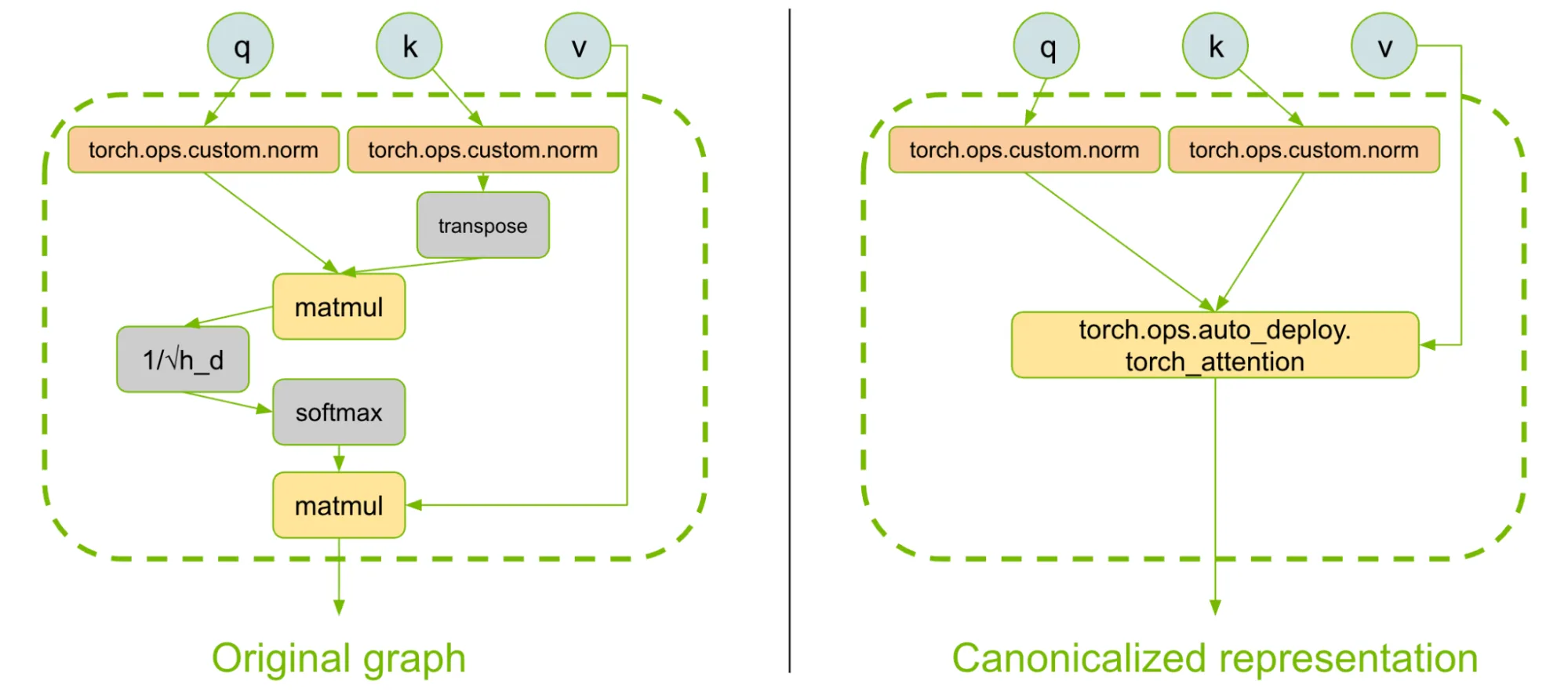
AutoDeploy sử dụng API torch.export để “chụp” mô hình dưới dạng một đồ thị Torch chuẩn hóa, bao gồm các phép toán ATen cốt lõi và các phép toán tùy chỉnh. Đồ thị sau đó trải qua một loạt các biến đổi tự động để khớp mẫu (pattern-match) và chuẩn hóa biểu diễn đồ thị của các building blocks phổ biến.
Trong bước này, AutoDeploy đảm bảo rằng các thành phần cốt lõi như Mixture of Experts (MoE), attention, RoPE hoặc state-space layers được biểu diễn bằng các bản triển khai tham chiếu dưới dạng custom ops và là các node đơn lẻ trong đồ thị. (Ví dụ: attention được gom lại thành một toán tử tùy chỉnh duy nhất, dễ quản lý).
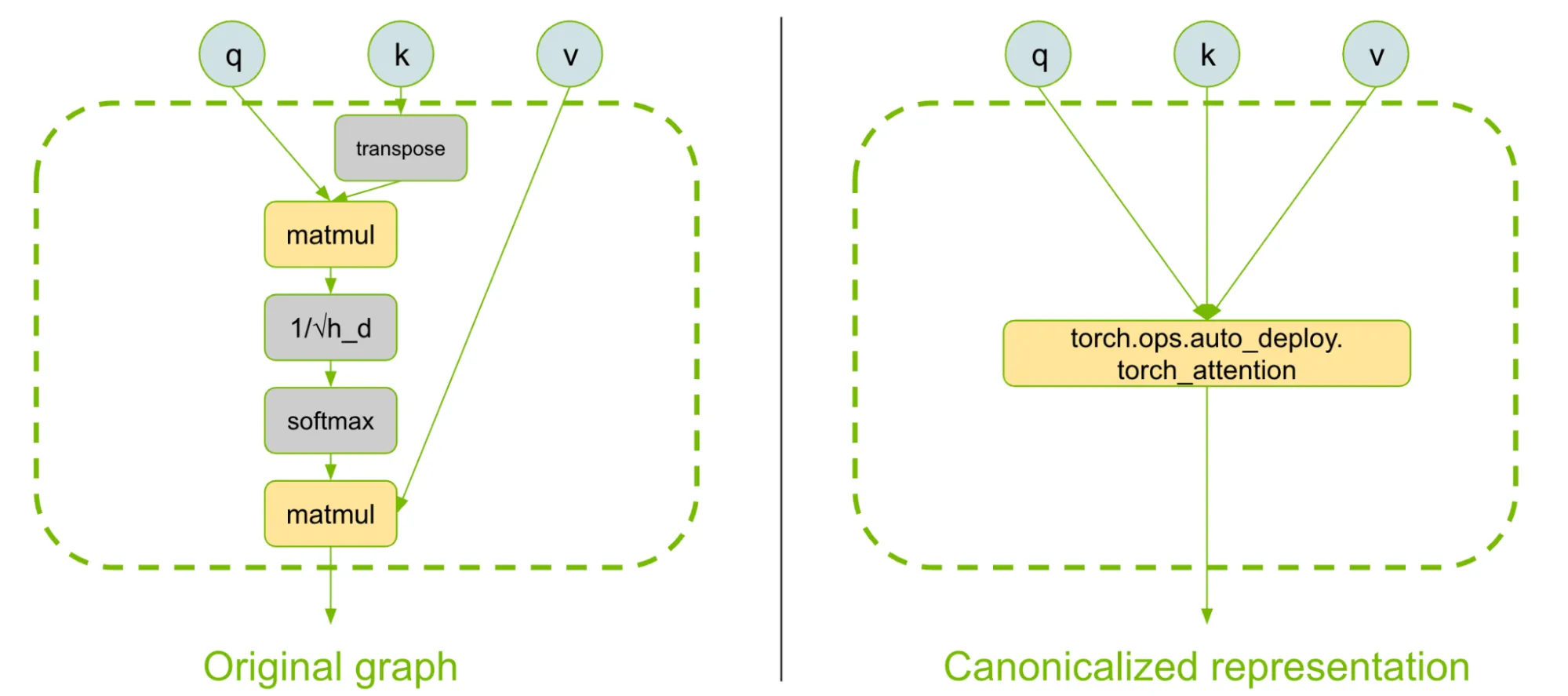
(Hình 2. AutoDeploy đảm bảo rằng các biểu diễn được chuẩn hóa được sử dụng cho các khối xây dựng chung, chẳng hạn như cơ chế chú ý, để đơn giản hóa việc tối ưu hóa hiệu suất ở các bước tiếp theo, chẳng hạn như bộ nhớ đệm và lựa chọn nhân.)
Phương pháp này tách bạch hoàn toàn quá trình “onboarding” mô hình khỏi quá trình tối ưu hóa hiệu suất và tích hợp runtime.
Hơn nữa, nếu bạn có một toán tử quá phức tạp, bạn hoàn toàn có thể inject (tiêm) các custom kernels của riêng mình vào bằng cách dùng decorator PyTorch. Trình biên dịch của AutoDeploy sẽ tôn trọng và không sửa đổi các toán tử đã được đánh dấu này.
Phân mảnh, gộp toán tử và tối ưu hiệu suất (Sharding, fusion, and performance optimization)
Ở giai đoạn tiếp theo, AutoDeploy tự động áp dụng các tối ưu hóa hiệu suất thông qua các compiler-like passes. Quá trình này kết hợp kernel fusion, các công thức tinh chỉnh hiệu suất và chèn các kernel tối ưu vào đồ thị. Trong giai đoạn này, mô hình cũng được tự động sharding để chạy trên đa GPU dựa trên các heuristic có sẵn hoặc tái sử dụng sharding hints của Hugging Face.
Hỗ trợ linh hoạt cho attention và caching
Trong quá trình chụp đồ thị, AutoDeploy coi các toán tử token mixing (như attention) là các thao tác “prefill-only” đơn giản. Hệ thống sau đó tự động swap (hoán đổi) chúng thành các attention kernels đã được tối ưu hóa hiệu suất và tự động liên kết cơ chế caching vào hệ thống quản lý cache của TensorRT-LLM. Hiện tại, AutoDeploy xử lý trơn tru các mô hình sử dụng kết hợp softmax attention, state-space layers (Mamba2), linear attention (DeltaNet), và causal convolution.
Công cụ biên dịch (Compilation tooling)
AutoDeploy kết hợp sức mạnh với các công cụ biên dịch mạnh mẽ khác như torch.compile, hỗ trợ CUDA Graphs cho các lô decode-only có kích thước batch cố định, và tối ưu hóa đa luồng (multistream optimizations).
Tích hợp Runtime (Runtime integration)
AutoDeploy đảm nhiệm mọi công đoạn phức tạp nhất khi đưa mô hình vào runtime của TensorRT-LLM, bao gồm: overlap scheduler, chunked prefill, speculative decoding, hay quản lý cache/state. AI Developer giờ đây không còn phải đau đầu vì mớ bòng bong dependency giữa mô hình và runtime nữa.
Ví dụ về hiệu suất: Nemotron 3 Nano
Để chứng minh sức mạnh của AutoDeploy, nhóm kỹ sư NVIDIA đã onboarding mô hình NVIDIA Nemotron 3 Nano (một kiến trúc MoE lai). Việc tinh chỉnh thủ công một mô hình phức tạp như vậy thường mất hàng tuần. Với AutoDeploy, nó được onboarding chỉ trong vài ngày, đạt hiệu suất hoàn toàn ngang ngửa với một baseline được tinh chỉnh bằng tay tốn kém.
Trên một GPU NVIDIA Blackwell DGX B200, AutoDeploy mang lại throughput lên tới 350 tokens/giây/người dùng và throughput tổng hệ thống đạt mức 13.000 output tokens/giây, chứng minh tính khả thi cho các ứng dụng yêu cầu độ trễ thấp và throughput cực cao.
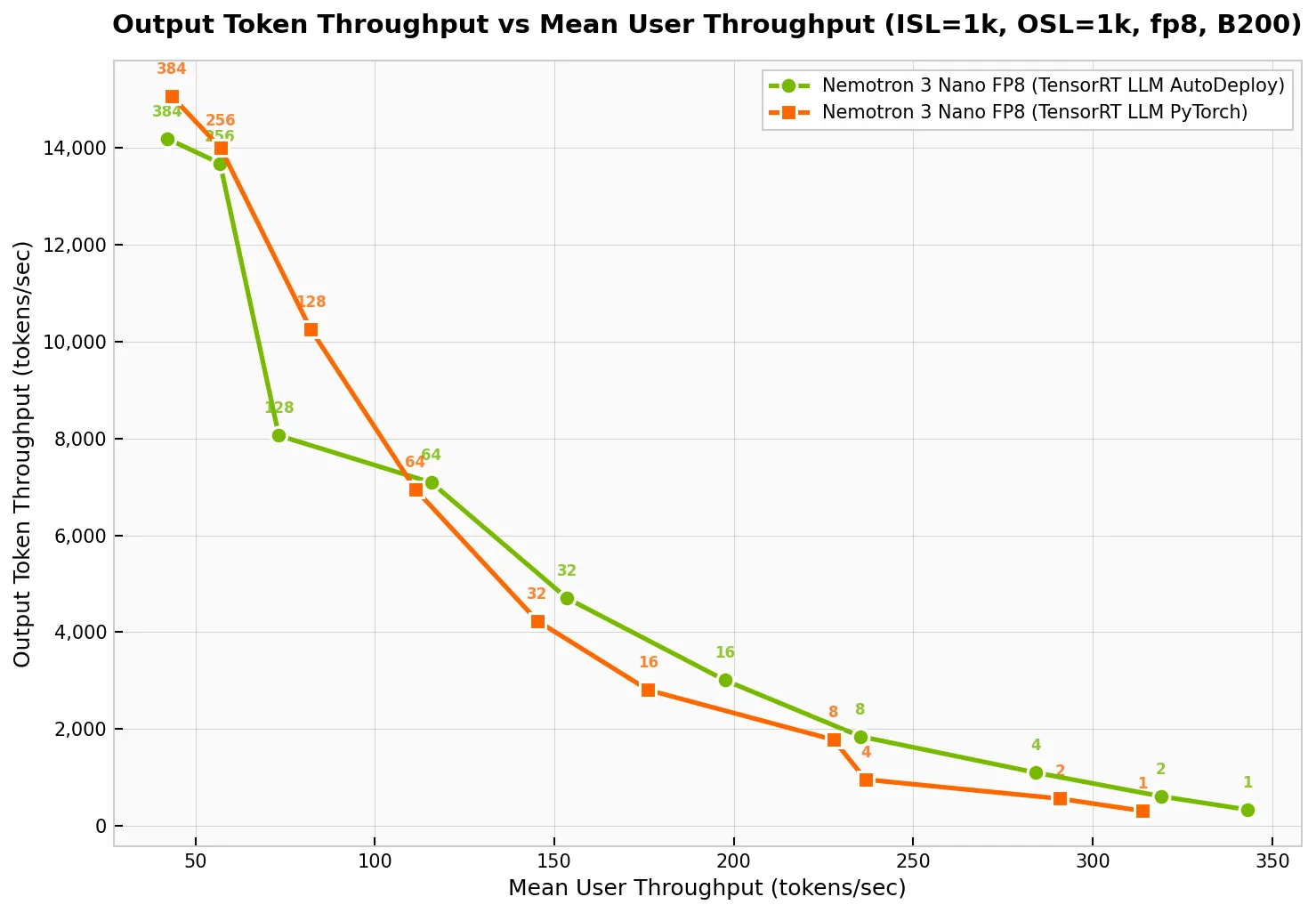
(Hình 4: Đánh giá hiệu suất backend AutoDeploy vs PyTorch thủ công trên TensorRT-LLM cho Nemotron 3 Nano FP8)
Ví dụ về tích hợp mô hình: Nemotron-Flash
Nemotron-Flash là ví dụ điển hình cho một kiến trúc gần như “ác mộng” nếu phải tự code tay hệ thống inference. Mô hình nghiên cứu lai này mix rất nhiều token mixers: state space layers, softmax attention, và linear attention.
Thay vì phải đập đi xây lại, AutoDeploy cho phép tái sử dụng ngay lập tức các optimization passes hiện có. Các loại layer mới, như bản cập nhật quy tắc của DeltaNet, được thêm vào dưới dạng phần mở rộng và có thể tái sử dụng trong tương lai. Nhờ vậy, Nemotron-Flash đã được tối ưu hóa hiệu suất trong vỏn vẹn vài ngày và sẵn sàng chạy out-of-the-box.
Khi benchmark Nemotron Flash 3B Instruct với Qwen2.5 3B Instruct (một mô hình đã được cộng đồng tối ưu thủ công cực kỳ kỹ lưỡng), Nemotron-Flash chạy trên AutoDeploy thậm chí còn vượt trội hơn, cho thấy các kiến trúc mới giờ đây có thể on-board và đạt hiệu suất production-ready nhanh đến mức nào.
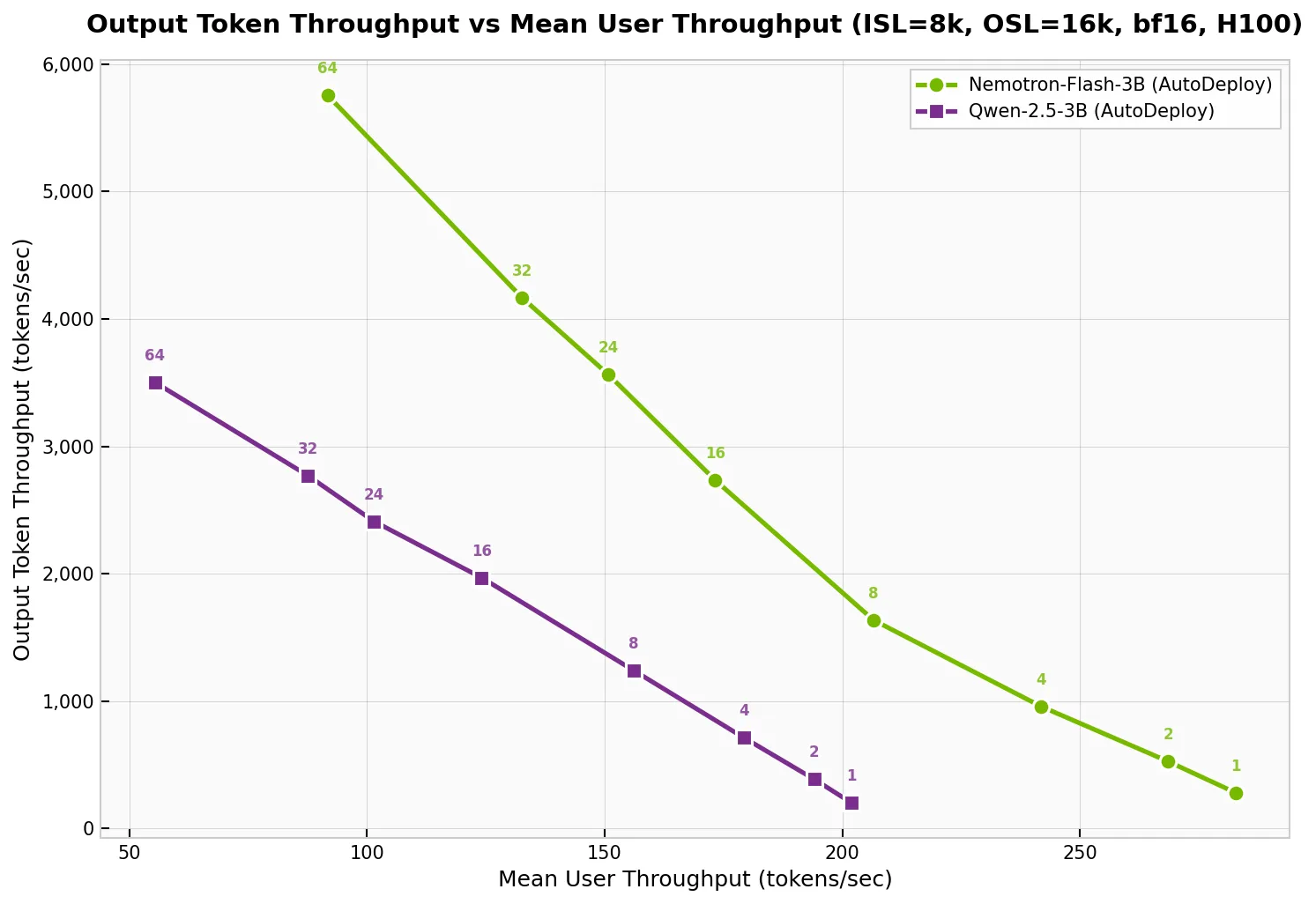 (Hình 5. Đường cong biểu diễn sự đánh đổi giữa thông lượng và độ trễ khi so sánh Nemotron Flash 3B và Qwen2.5 3B trong AutoDeploy.)
(Hình 5. Đường cong biểu diễn sự đánh đổi giữa thông lượng và độ trễ khi so sánh Nemotron Flash 3B và Qwen2.5 3B trong AutoDeploy.)
Dữ liệu được thu thập cho ISL/OSL 8k/16k, TP=1, trên NVIDIA DGX H100 sử dụng TensorRT LLM v1.3.0rc1 và công cụ trtllm-serveđo hiệu năng AIPerf.
Bắt đầu với TensorRT-LLM AutoDeploy
Sự ra mắt của TensorRT-LLM AutoDeploy đánh dấu một bước chuyển mình quan trọng: Đưa trọng trách tối ưu hóa inference từ đôi vai của AI Developer sang cho Compiler và Runtime. Cấu trúc này mở ra kỷ nguyên mới nơi tốc độ thử nghiệm được đẩy nhanh, hỗ trợ đa dạng mọi loại mô hình kiến trúc kỳ lạ nhất, và tách biệt hoàn toàn giữa Model Design và Deployment.
Là những AI Developer, thay vì dành hàng tuần để vọc vạch tinh chỉnh từng mô hình, nay bạn chỉ cần định nghĩa kiến trúc một lần duy nhất. Nếu bạn đang muốn vọc vạch tính năng cực nóng này, hãy xem ngay tài liệu AutoDeploy và các script ví dụ để trực tiếp trải nghiệm.