NVIDIA dẫn đầu hiệu suất Agentic Coding trên bài đo benchmark Agentic AI đầu tiên
AI agents đã thay đổi cơ bản độ phức tạp của các khối lượng công việc suy luận. Cho đến nay, ngành công nghiệp đã lay hoay để xác định …
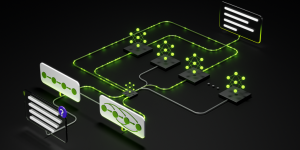
AI agents đã thay đổi cơ bản độ phức tạp của các khối lượng công việc suy luận. Cho đến nay, ngành công nghiệp đã lay hoay để xác định …
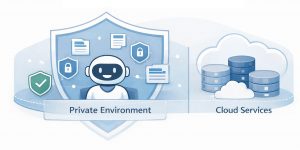
Mỗi ngày, doanh nghiệp mất rất nhiều thời gian cho những câu hỏi tưởng như đơn giản:Hợp đồng này quy định điều gì, báo giá nằm ở đâu, quy trình …

Các mô hình ngôn ngữ lớn (LLM) đang cách mạng hóa bối cảnh giao dịch tài chính bằng cách cho phép phân tích tinh vi khối lượng lớn dữ liệu …

Bạn có bao giờ nhận được một file PDF dài vài chục trang — báo cáo thường niên, paper nghiên cứu, tài liệu nội bộ công ty — rồi tự …

“Một truy vấn nghiên cứu không nên chỉ trả về câu trả lời; nó cần trả về một chuỗi lập luận có nguồn, có kiểm chứng và có thể mở …

Ollama so với vLLM: Lựa chọn hệ thống quản lý học từ xa (LLM) phù hợp Hiện nay, việc chạy các mô hình ngôn ngữ lớn tại chỗ không còn …

Việc phát hành MiniMax M2.7 bổ sung các cải tiến cho mô hình MiniMax M2.5 phổ biến, được xây dựng cho dây nịt tác nhân và các trường hợp sử dụng phức …
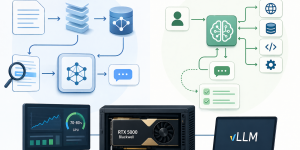
Với sự ra mắt của Gemma 4 cùng context window khổng lồ lên đến 256K, bài toán đặt ra cho các kỹ sư hệ thống không còn là “mô hình …
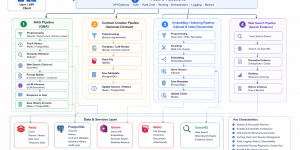
Dạo một vòng qua các bài tutorial, các khóa học hay thậm chí là document của những framework RAG đình đám hiện nay, bạn sẽ dễ dàng nhận ra một …

Khi workload suy luận mô hình ngôn ngữ lớn (LLM) ngày càng phức tạp, một quy trình phục vụ duy nhất, nguyên khối bắt đầu bộc lộ những hạn chế …