Với sự ra mắt của Gemma 4 cùng context window khổng lồ lên đến 256K, bài toán đặt ra cho các kỹ sư hệ thống không còn là “mô hình có đọc được không?”, mà là “làm sao để duy trì throughput và low-latency trên production?”.
Bài viết này ghi nhận lại các đánh giá hiệu năng thực tế của Gemma 4 khi triển khai luồng RAG ngữ cảnh lớn và kiến trúc Agentic, chạy trực tiếp trên hạ tầng Blackwell.
Môi trường Triển khai & Thông số Cơ sở
Việc setup môi trường inference đóng vai trò quyết định đến 50% độ trễ của hệ thống. Dưới đây là cấu hình benchmark thực tế:
-
Phần cứng: 1x NVIDIA RTX 5000 Blackwell (48GB VRAM). Tải hệ thống (GPU Memory Utilization) duy trì ở mức an toàn 70-80% để chừa không gian cho KV Cache.
-
Engine Inference:
vLLM(sử dụng container image tương thích OpenAI API chuẩnopenai:latest). -
Định dạng Model: Native
BF16. -
Tốc độ sinh token (Decode Phase): Ổn định ở mức 50 – 90 tokens/s (phụ thuộc vào batch size).
Gemma 4 cho Luồng RAG Ngữ cảnh lớn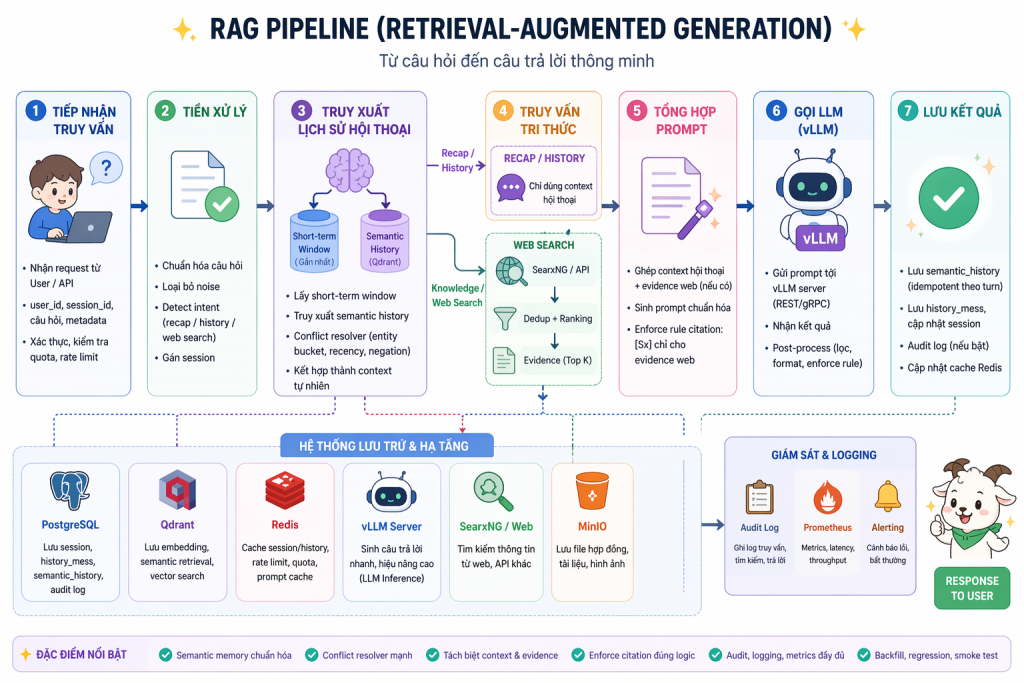
Kiến trúc RAG (Retrieval-Augmented Generation) để tra cứu tài liệu kỹ thuật/hợp đồng thường đòi hỏi việc nhồi một lượng lớn text đã bóc tách (từ PDF, Docx) vào prompt. Lúc này, áp lực lớn nhất không nằm ở tốc độ sinh chữ (Decode), mà nằm ở pha đọc hiểu ban đầu (Prefill).
Quan sát sự suy giảm TTFT (Time-To-First-Token)
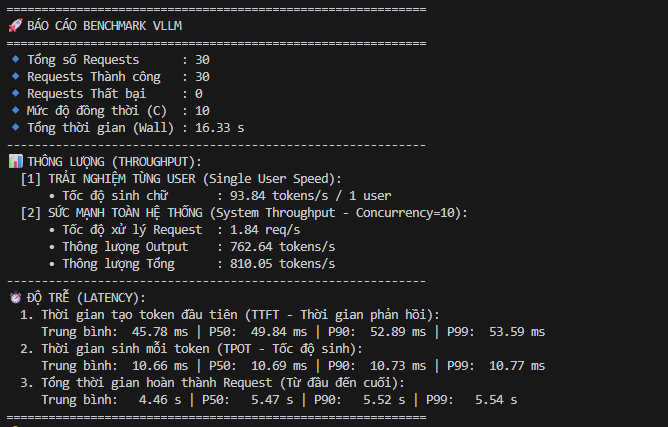
Khi nhìn vào benchmark hiện tại (concurrency = 10, context không quá dài), TTFT đạt mức ~45ms (P50 ~49ms, P99 ~53ms) — gần như phản hồi tức thời ở góc nhìn người dùng.
Tuy nhiên, điều này không phản ánh toàn bộ bản chất hệ thống.
Khi scale lên các workload nặng hơn (ví dụ context dài hàng trăm nghìn tokens như 256K), kiến trúc Transformer bắt đầu bộc lộ rõ giới hạn: memory-bandwidth-bound.
- TTFT không còn giữ được mức mili-giây
- Thời gian chờ token đầu tiên bắt đầu tăng theo kích thước context
- Bottleneck không nằm ở VRAM (48GB vẫn đủ), mà ở:
→ băng thông bộ nhớ khi tính toán attention trên hàng chục nghìn token
Kết luận:
- Benchmark hiện tại: rất nhanh (UX tốt)
- Nhưng nếu “nhồi context” không kiểm soát:
→ TTFT sẽ tăng mạnh
→ UX giảm rõ rệt
Việc dump toàn bộ PDF vào context thay vì chunking + retrieval đúng cách sẽ nhanh chóng trở thành điểm nghẽn.
Hiệu năng cứu cánh từ Automatic Prefix Caching (APC)
Trong hệ thống RAG, các thành phần như:
- system prompt
- luật / policy
- đoạn context cố định
thường lặp lại giữa nhiều request.
vLLM tận dụng điều này thông qua RadixAttention + Prefix Caching (APC).
Hiệu quả:
- Request đầu tiên: vẫn phải chạy full prefill
- Request sau (cùng prefix):
→ bypass phần prefill nặng
→ giảm tải compute đáng kể
Trong benchmark nhẹ như hiện tại (TTFT ~45ms), lợi ích chưa quá rõ ràng.
Nhưng ở workload lớn (context dài, nhiều user), APC sẽ:
- giữ TTFT ổn định
- giảm spike latency
- tăng throughput toàn hệ thống
Độ chính xác (Grounding) & Hallucination
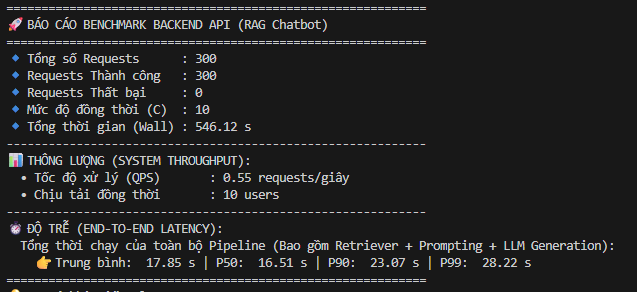
Gemma 4 cho thấy khả năng “bám rễ” (grounding) rất tốt vào context được cung cấp. Khi cố tình chèn các đoạn text nhiễu (noise) vào giữa dữ liệu RAG, mô hình vẫn trích xuất đúng Entity cần thiết mà không bị ảo giác. Tuy nhiên, hiệu ứng “Lost in the middle” vẫn xuất hiện nhẹ nếu dồn các điều khoản quan trọng vào giữa một context dài 16K.
Gemma 4 cho Kiến trúc Agentic (Multi-turn & Tool Calling)
Khác với RAG, Agentic AI yêu cầu mô hình hoạt động như một “Node logic”: Context ngắn hơn, gọi đi gọi lại liên tục (multi-turn), và output phải tuân thủ định dạng khắt khe để chuyển giao cho các hệ thống khác.
Độ trễ trong vòng lặp Tool Calling
Trong cấu hình Agentic, mô hình phải liên tục thực hiện chu trình: Đọc query -> Parse Function -> Yêu cầu gọi API -> Chờ kết quả API -> Tổng hợp câu trả lời.
-
Đánh giá Latency: Mọi độ trễ ở pha inference sẽ bị nhân lên theo số bước của Agent. Mức 50-80 t/s của Gemma 4 trên Blackwell xử lý rất mượt các luồng ngắn. Tuy nhiên, nếu thiết kế multi-agent quá phức tạp, UX sẽ suy giảm nhanh chóng do thời gian mạng và hệ thống phân giải hàm cộng dồn. Lời khuyên: Giữ luồng Agent càng mỏng càng tốt.
Constrained Decoding (Khả năng tuân thủ cấu trúc)
Đây là điểm sáng khi kết hợp Gemma 4 với vLLM. Khi ép mô hình trả về dữ liệu dạng JSON (ví dụ: JSON State Tracker cho hệ thống tạo hợp đồng) hoặc yêu cầu chèn tag trích dẫn, Gemma 4 đáp ứng tỷ lệ lỗi cú pháp (Syntax Error) gần như bằng 0. Khi sử dụng kèm tính năng Guided Decoding của vLLM, luồng parse data cho backend (FastAPI/Next.js) diễn ra hoàn hảo.
Chi phí cho Reasoning: Direct vs. ReAct
Sự chênh lệch về Throughput là rất rõ ràng:
-
Direct Query: Xử lý nhanh, tiêu thụ ít compute.
-
ReAct (Reasoning and Acting) / Plan-and-Solve: Agent phải sinh ra các chuỗi suy nghĩ (Thought) trước khi hành động. Việc này đốt một lượng lớn token đầu ra (Decode Phase), làm giảm trực tiếp số lượng Concurrent Users mà 1 GPU RTX 5000 có thể gánh được.
Triển khai
Để “ép khô” hiệu năng của Gemma 4 trong môi trường Production thực tế, hệ thống không thể chỉ cắm chạy mặc định. Dưới đây là chiến lược thiết kế:
Các cấu hình vLLM “Must-Have”
Bắt buộc phải truyền các cờ (flags) sau khi khởi chạy engine:
-
--enable-prefix-caching: Vũ khí tối thượng để giảm TTFT cho RAG và duy trì context system cho Agent. -
--gpu-memory-utilization 0.85(hoặc 0.9): Dành không gian tối đa cho KV Cache (PagedAttention) để tăng batch size. -
Tối ưu hoá PagedAttention block size phù hợp với kiến trúc bộ nhớ của Blackwell.
Nên dùng bản nén (Quantization) không?
Dù RTX 5000 Blackwell có 48GB VRAM và chạy ổn BF16 cho các request đơn lẻ, nhưng để tối đa hóa Throughput và concurrent requests, NÊN chuyển sang các định dạng FP8 hoặc FP4.
-
Kiến trúc Blackwell hỗ trợ native FP8 siêu việt. Việc sử dụng các container vLLM (đặc biệt là các bản build tối ưu từ NVIDIA) với model định dạng FP8 sẽ giúp bạn nhân đôi KV Cache, giảm một nửa áp lực băng thông bộ nhớ mà mức độ suy giảm Accuracy gần như không thể nhận ra trong nghiệp vụ tra cứu/tóm tắt.
“Điểm ngọt” (Sweet Spot) trên tổng 256K Token
Đừng để con số 256K đánh lừa chiến lược kiến trúc của bạn. Nhồi toàn bộ 256K vào một prompt là cách nhanh nhất để làm sập hệ thống (OOM hoặc latency đo bằng phút).
-
Với RAG: Điểm ngọt thực tế là 8K – 16K tokens (tương đương 80% context window dành cho dữ liệu lõi). Phần history (20%) chỉ nên duy trì dạng State JSON hoặc 3-5 turns gần nhất.
-
Với Agentic: Điểm ngọt là dưới 4K tokens. Hãy giữ Agent sắc bén, bối cảnh ngắn gọn, và dùng Vector DB để cung cấp trí nhớ dài hạn (Long-term RAG Facts) thay vì nhồi nhét text raw vào memory của Agent. Mọi thứ nên tuân thủ nguyên tắc thiết kế tối giản và thực dụng.
Bài viết liên quan
- NVIDIA dẫn đầu hiệu suất Agentic Coding trên bài đo benchmark Agentic AI đầu tiên
- Xây dựng chatbot AI nội bộ cho doanh nghiệp: Nhanh hơn, đúng ngữ cảnh hơn, kiểm soát tốt hơn
- NVIDIA Blackwell lập kỷ lục STAC-AI về suy luận LLM trong lĩnh vực tài chính
- NVIDIA Riva giải pháp Voice RAG: tối ưu luồng dữ liệu âm thanh và đồng bộ Avatar 3D
- Triển khai hệ thống Voice RAG bằng NVIDIA Riva framework trên hạ tầng cục bộ
- Blueprint: PDF-to-Podcast – Biến tài liệu PDF thành Podcast bằng AI