
Khi workload suy luận mô hình ngôn ngữ lớn (LLM) ngày càng phức tạp, một quy trình phục vụ duy nhất, nguyên khối bắt đầu bộc lộ những hạn chế của nó. Các giai đoạn điền trước và giải mã có cấu hình tính toán khác nhau về cơ bản, nhưng các triển khai truyền thống lại buộc chúng phải sử dụng cùng một phần cứng, dẫn đến việc GPU không được tận dụng tối đa và khả năng mở rộng bị hạn chế.
Việc phân tách dịch vụ (service disaggregation) giải quyết vấn đề này bằng cách chia quy trình suy luận thành các giai đoạn riêng biệt như điền trước dữ liệu, giải mã và định tuyến, mỗi giai đoạn hoạt động như một dịch vụ độc lập có thể được cấp phát tài nguyên và mở rộng quy mô theo cách riêng của nó.
Bài viết này sẽ cung cấp tổng quan về cách triển khai suy luận phân tách trên Kubernetes, khám phá các giải pháp hệ sinh thái khác nhau và cách chúng hoạt động trên cụm, cũng như đánh giá những gì chúng cung cấp ngay từ đầu.
Suy luận tổ hợp và suy luận phân tách khác nhau như thế nào?
Trước khi đi sâu vào các cấu hình Kubernetes, một điều quan trọng là cần hiểu hai chế độ triển khai suy luận cho LLM: Trong chế độ dịch vụ tổ hợp (aggregated serving), một tiến trình duy nhất (hoặc một nhóm các tiến trình liên kết chặt chẽ) xử lý toàn bộ vòng đời suy luận từ đầu vào đến đầu ra. Chế độ phục vụ phân tách chia đường dẫn xử lý thành các giai đoạn riêng biệt như điền trước, giải mã và định tuyến, mỗi giai đoạn chạy như một dịch vụ độc lập (xem Hình 1 bên dưới).
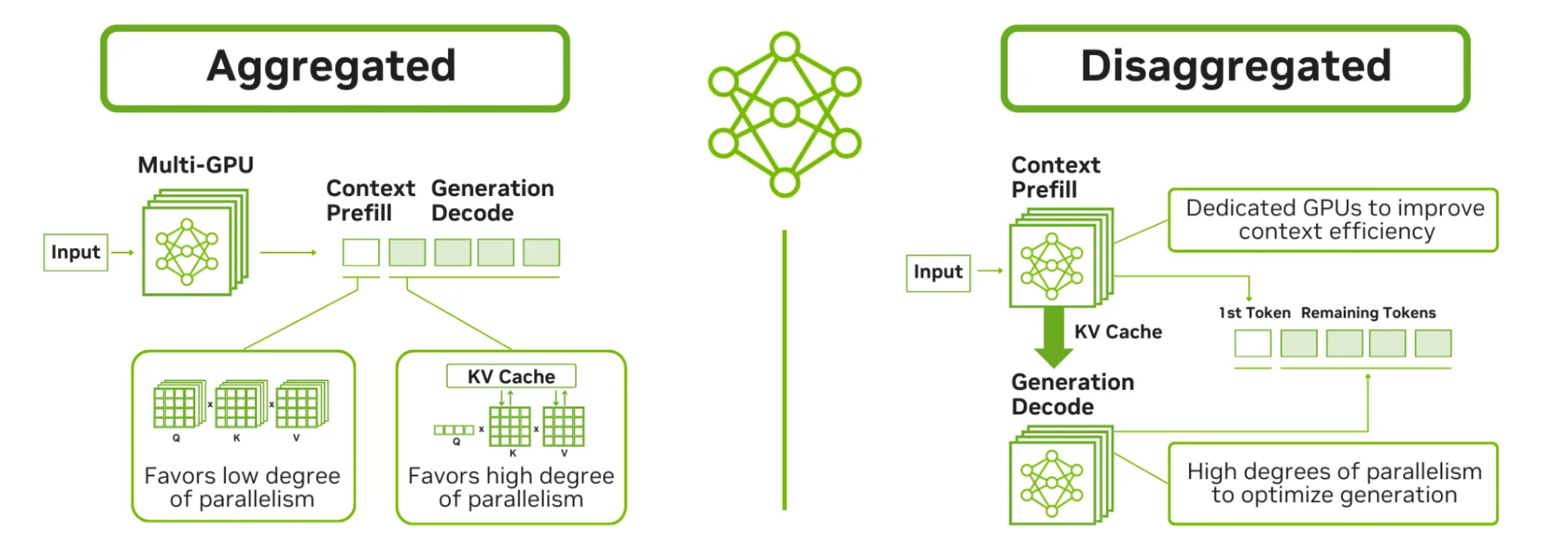
Hình 1. So sánh việc dịch vụ tổ hợp và phục vụ riêng lẻ
Suy luận tổ hợp (aggregated)
Trong thiết lập tổ hợp truyền thống, một máy chủ mô hình duy nhất (hoặc một nhóm máy chủ phối hợp trong cấu hình song song) xử lý toàn bộ vòng đời yêu cầu. Khi người dùng đưa ra yêu cầu, máy chủ sẽ mã hóa yêu cầu đó, chạy hàm điền trước để xây dựng ngữ cảnh, tạo ra các mã thông báo đầu ra một cách tự hồi quy (giải mã) và trả về phản hồi. Tất cả diễn ra trong một tiến trình duy nhất hoặc một nhóm pod được kết nối chặt chẽ.
Về mặt khái niệm, điều này khá đơn giản và hoạt động tốt trong nhiều trường hợp sử dụng. Nhưng điều đó có nghĩa là phần cứng của bạn phải luân phiên giữa hai workload hoàn toàn khác nhau: Điền trước (Prefill) đòi hỏi nhiều tài nguyên tính toán và được hưởng lợi từ tốc độ xử lý dấu phẩy động cao (FLOPS), trong khi giải mã (decode) bị giới hạn bởi băng thông bộ nhớ và được hưởng lợi từ bộ nhớ lớn, tốc độ cao.
Suy luận phân tách (disaggregated)
Kiến trúc phân tách tách biệt các giai đoạn này thành các dịch vụ riêng biệt:
- Các worker xử lý dữ liệu nhập vào sẽ xử lý lời nhắc nhập liệu. Quá trình này đòi hỏi nhiều tài nguyên tính toán. Bạn cần tối ưu hóa GPU để đạt hiệu suất cao và có thể song song hóa mạnh mẽ.
- Các tiến trình giải mã tạo ra các token đầu ra từng cái một. Quá trình này bị giới hạn bởi băng thông bộ nhớ do bản chất tự hồi quy của LLM. Bạn cần GPU có khả năng truy cập bộ nhớ băng thông cao (HBM) nhanh.
- Bộ định tuyến/cổng điều hướng các yêu cầu đến, quản lý định tuyến bộ nhớ đệm Khóa-Giá trị (KV) giữa các giai đoạn điền trước và giải mã, và xử lý cân bằng tải các yêu cầu trên các máy chủ xử lý của bạn.
Tại sao cần phân tách? Có ba lý do nổi bật:
- Các cấu hình tài nguyên và tối ưu hóa khác nhau cho từng giai đoạn: Với việc phân tách, bạn có thể điều chỉnh tài nguyên GPU, kỹ thuật phân chia mô hình và kích thước lô cho phù hợp với nhu cầu của từng giai đoạn thay vì phải thỏa hiệp với một phương pháp duy nhất.
- Mở rộng quy mô độc lập: Mô hình lưu lượng truy cập điền trước và giải mã khác nhau. Một lời nhắc ngữ cảnh dài tạo ra một lượng lớn lưu lượng điền trước nhưng luồng giải mã ổn định. Mở rộng quy mô từng giai đoạn độc lập cho phép bạn đáp ứng nhu cầu thực tế.
- Tận dụng GPU tốt hơn: Việc tách biệt các giai đoạn cho phép mỗi giai đoạn khai thác tối đa tài nguyên mục tiêu của nó (tính toán cho giai đoạn điền trước, băng thông bộ nhớ cho giai đoạn giải mã) thay vì luân phiên giữa cả hai.
Các framework như NVIDIA Dynamo và llm-d đều triển khai mô hình này. Câu hỏi đặt ra là: Làm thế nào để điều phối nó trên Kubernetes?
Vì sao lập lịch là chìa khóa cho hiệu suất suy luận multi-pod trên Kubernetes
Triển khai workload suy luận đa pod (bao gồm cả các mô hình tổ hợp song song hoặc các mô hình riêng lẻ) chỉ là một nửa câu chuyện. Cách bộ lập lịch đặt các pod trên cụm ảnh hưởng trực tiếp đến hiệu suất; việc đặt các pod của nhóm Tensor Parallel (TP) trên cùng một rack với các kết nối NVIDIA NVLink băng thông cao có thể tạo ra sự khác biệt giữa suy luận nhanh và tắc nghẽn mạng. Ba khả năng lập lịch quan trọng nhất ở đây là:
- Lập lịch nhóm đảm bảo tất cả các pod trong một nhóm được đặt theo nguyên tắc “tất cả hoặc không có gì”, ngăn ngừa việc triển khai một phần gây lãng phí GPU.
- Lập lịch nhóm phân cấp mở rộng lập lịch nhóm cơ bản cho các workload đa cấp. Trong suy luận phân tách, bạn cần các đảm bảo tối thiểu lồng nhau cho mỗi thành phần hoặc vai trò: mỗi nhóm Tensor Parallel (ví dụ: bốn pod tạo thành một phiên bản giải mã) phải được lập lịch một cách nguyên tử, và toàn bộ hệ thống (ít nhất n phiên bản điền trước + ít nhất m phiên bản giải mã + bộ định tuyến) cũng cần sự phối hợp ở cấp hệ thống. Nếu không có điều này, một vai trò có thể tiêu thụ tất cả GPU có sẵn trong khi vai trò khác chờ đợi vô thời hạn — một triển khai không đầy đủ, nắm giữ tài nguyên nhưng không thể phục vụ các yêu cầu.
- Phương pháp đặt vị trí dựa trên cấu trúc mạng cho phép đặt các cụm máy chủ được kết nối chặt chẽ trên các nút có kết nối băng thông cao, giảm thiểu độ trễ giao tiếp giữa các nút.
Ba khả năng này quyết định cách một bộ lập lịch AI, chẳng hạn như KAI Scheduler , đặt các pod dựa trên các ràng buộc lập lịch của ứng dụng. Ngoài ra, điều quan trọng là lớp điều phối AI phải xác định những gì cần được lập lịch theo nhóm và khi nào . Ví dụ, khi quá trình điền trước mở rộng độc lập, cần có một cơ chế nào đó quyết định rằng các pod mới tạo thành một nhóm với mức độ khả dụng tối thiểu được đảm bảo, mà không làm gián đoạn các pod giải mã hiện có. Do đó, lớp điều phối và bộ lập lịch cần phối hợp chặt chẽ trong toàn bộ vòng đời của ứng dụng, xử lý việc tự động mở rộng đa cấp, cập nhật cuốn chiếu, v.v., để đảm bảo điều kiện hoạt động tối ưu cho workload AI.
Đây là lúc các lớp trừu tượng hóa workload cấp cao hơn phát huy tác dụng. Các API như LeaderWorkerSet (LWS) và NVIDIA Grove cho phép người dùng thể hiện một cách khai báo cấu trúc của ứng dụng suy luận của họ: các vai trò nào tồn tại, chúng liên quan đến nhau như thế nào, chúng nên được mở rộng quy mô ra sao và những ràng buộc về cấu trúc liên kết nào là quan trọng. Toán tử của API sẽ dịch ý định ở cấp độ ứng dụng đó thành các ràng buộc lập lịch cụ thể (bao gồm PodGroups, yêu cầu nhóm, gợi ý về cấu trúc liên kết) để xác định nhóm nào cần tạo và khi nào.
Bộ lập lịch KAI đóng vai trò quan trọng trong việc đáp ứng các ràng buộc đó, giải quyết vấn đề làm thế nào: lập lịch nhóm, lập lịch nhóm phân cấp và đặt vị trí dựa trên cấu trúc liên kết. Trong bài viết này, chúng tôi sử dụng KAI làm bộ lập lịch, mặc dù có các bộ lập lịch khác trong cộng đồng hỗ trợ một số tính năng này. Người đọc có thể khám phá bức tranh tổng quan về lập lịch thông qua hệ sinh thái của Cloud Native Computing Foundation (CNCF).
Triển khai suy luận phân tách
Kiến trúc phân tách có nhiều vai trò, mỗi vai trò có cấu hình tài nguyên và nhu cầu mở rộng khác nhau. Vì mỗi vai trò trong một quy trình phân tách là một workload riêng biệt, nên cách tiếp cận tự nhiên với LWS là tạo một tài nguyên riêng cho mỗi vai trò.
Các worker điền trước dữ liệu (bốn bản sao, song song Tensor bậc 2):
apiVersion: leaderworkerset.x-k8s.io/v1 kind: LeaderWorkerSet metadata: name: prefill-workers spec: replicas: 4 leaderWorkerTemplate: size: 2 restartPolicy: RecreateGroupOnPodRestart leaderTemplate: metadata: labels: role: prefill-leader spec: containers: - name: prefill image: args: ["--role=prefill", "--tensor-parallel-size=2"] resources: limits: nvidia.com/gpu: "1" workerTemplate: spec: containers: - name: prefill image: args: ["--role=prefill"] resources: limits: nvidia.com/gpu: "1"
Các tiến trình giải mã (hai bản sao, song song Tensor bậc 4):
apiVersion: leaderworkerset.x-k8s.io/v1 kind: LeaderWorkerSet metadata: name: decode-workers spec: replicas: 2 leaderWorkerTemplate: size: 4 restartPolicy: RecreateGroupOnPodRestart leaderTemplate: metadata: labels: role: decode-leader spec: containers: - name: decode image: args: ["--role=decode", "--tensor-parallel-size=4"] resources: limits: nvidia.com/gpu: "1" workerTemplate: spec: containers: - name: decode image: args: ["--role=decode"] resources: limits: nvidia.com/gpu: "1"
Bộ định tuyến (cấu hình triển khai tiêu chuẩn—không cần cấu trúc liên kết lãnh đạo-nhân viên):
apiVersion: apps/v1 kind: Deployment metadata: name: router spec: replicas: 2 selector: matchLabels: app: router template: metadata: labels: app: router spec: containers: - name: router image: env: - name: PREFILL_ENDPOINT value: "prefill-workers" - name: DECODE_ENDPOINT value: "decode-workers"
Mỗi vai trò được quản lý như một tài nguyên riêng biệt. Bạn có thể mở rộng quy mô, điền trước dữ liệu và giải mã độc lập, cũng như cập nhật chúng theo các lịch trình khác nhau.
Điều quan trọng cần lưu ý là bộ lập lịch coi các worker điền trước và worker giải mã là các workload độc lập. Bộ lập lịch sẽ phân bổ chúng thành công, nhưng nó không biết rằng chúng tạo thành một đường dẫn suy luận duy nhất. Trên thực tế, điều này có nghĩa là một vài điều sau:
- Việc phối hợp cấu trúc liên kết giữa quá trình điền trước và giải mã (đặt chúng trên cùng một giá đỡ để truyền bộ nhớ đệm KV nhanh) yêu cầu thêm thủ công các quy tắc liên kết pod tham chiếu đến các nhãn trên hai tài nguyên LWS.
- Việc mở rộng quy mô một vai trò không tự động điều chỉnh cho vai trò khác: Nếu một lượng lớn yêu cầu ngữ cảnh dài đòi hỏi dung lượng điền trước lớn hơn, bạn sẽ mở rộng quy mô các worker điền trước, nhưng các pod điền trước mới không được đảm bảo sẽ nằm gần các pod giải mã hiện có trừ khi bạn đã tự cấu hình liên kết.
- Việc triển khai một phiên bản mô hình mới đòi hỏi phải phối hợp cập nhật trên ba nguồn tài nguyên độc lập — cơ chế cập nhật phân vùng của LWS hỗ trợ triển khai theo từng giai đoạn trên mỗi nguồn tài nguyên, nhưng việc đồng bộ hóa giữa các nguồn tài nguyên được quản lý từ bên ngoài.
Điểm cuối cùng này đáng được lưu ý. Các framework suy luận thay đổi nhanh chóng và không phải lúc nào cũng đảm bảo khả năng tương thích ngược giữa các phiên bản, vì vậy các pod xử lý trước dữ liệu trên phiên bản cũ và các pod giải mã trên phiên bản mới có thể không giao tiếp được với nhau. Mô hình cũng cần thời gian để tải, và các worker xử lý trước dữ liệu và giải mã thường sẵn sàng với tốc độ khác nhau. Trong quá trình triển khai không đồng bộ, điều này có thể tạo ra sự mất cân bằng tạm thời, trong đó nhiều pod giải mã mới đã sẵn sàng nhưng rất ít pod xử lý trước dữ liệu mới sẵn sàng (hoặc ngược lại). Điều này có thể tạo ra nút thắt cổ chai trong quy trình suy luận của bạn cho đến khi mọi thứ được đồng bộ hóa.
Các mô hình này hoạt động hiệu quả. Việc phối hợp chỉ diễn ra bên ngoài các thành phần cơ bản của Kubernetes: trong lớp định tuyến của khung suy luận, trong các bộ tự động mở rộng tùy chỉnh, các toán tử được thiết kế riêng, hoặc thậm chí là thủ công. Một lựa chọn khác là sử dụng API của Grove , API này áp dụng một cách tiếp cận khác bằng cách chuyển việc phối hợp đó vào chính tài nguyên Kubernetes.
Nó thể hiện tất cả các vai trò trong một PodCliqueSet duy nhất:
apiVersion: grove.io/v1alpha1 kind: PodCliqueSet metadata: name: inference-disaggregated spec: replicas: 1 template: cliqueStartupType: CliqueStartupTypeExplicit terminationDelay: 30s cliques: - name: router spec: roleName: router replicas: 2 podSpec: schedulerName: kai-scheduler containers: - name: router image: resources: requests: cpu: 100m - name: prefill spec: roleName: prefill replicas: 4 startsAfter: [router] podSpec: schedulerName: kai-scheduler containers: - name: prefill image: args: ["--role=prefill", "--tensor-parallel-size=2"] resources: limits: nvidia.com/gpu: "1" autoScalingConfig: maxReplicas: 8 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 70 - name: decode spec: roleName: decode replicas: 2 startsAfter: [router] podSpec: schedulerName: kai-scheduler containers: - name: decode image: args: ["--role=decode", "--tensor-parallel-size=4"] resources: limits: nvidia.com/gpu: "1" autoScalingConfig: maxReplicas: 6 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 80 topologyConstraint: packDomain: rack
Trình điều khiển Grove quản lý các PodClique cho từng vai trò và điều phối việc lập lịch, khởi động và vòng đời của tất cả chúng. Một vài điều cần lưu ý trong tệp YAML:
- startsAfter: [router]Lệnh `on prefill and decode` yêu cầu người vận hành trì hoãn quá trình khởi động cho đến khi bộ định tuyến sẵn sàng. Điều này được thể hiện một cách khai báo và được thực thi thông qua các container khởi tạo. Khi bạn triển khai lần đầu, các pod bộ định tuyến sẽ khởi động và sẵn sàng trước, sau đó các pod `prefill` và `decode` sẽ khởi động song song (vì cả hai đều phụ thuộc vào bộ định tuyến).
- autoScalingConfigMỗi nhóm cho phép bạn xác định các chính sách mở rộng quy mô theo vai trò. Trình điều khiển tạo ra một bộ tự động mở rộng quy mô pod theo chiều ngang (HPA) cho mỗi nhóm, do đó việc điền trước và giải mã sẽ mở rộng quy mô độc lập dựa trên các chỉ số riêng của chúng.
- topologyConstraint with packDomain:Lệnh `rack` yêu cầu Bộ lập lịch KAI đóng gói tất cả các nhóm con vào cùng một giá đỡ, tối ưu hóa việc truyền dữ liệu bộ nhớ đệm KV giữa các giai đoạn điền trước và giải mã thông qua các kết nối băng thông cao.
Sau khi áp dụng bản kê khai này, bạn có thể kiểm tra tất cả các tài nguyên mà Grove tạo ra:
$ kubectl get pcs,pclq,pg,pod NAME AGE podcliqueset.grove.io/inference-disaggregated 45s NAME AGE podclique.grove.io/inference-disaggregated-0-router 44s podclique.grove.io/inference-disaggregated-0-prefill 44s podclique.grove.io/inference-disaggregated-0-decode 44s NAME AGE podgang.scheduler.grove.io/inference-disaggregated-0 44s NAME READY STATUS AGE pod/inference-disaggregated-0-router-k8x2m 1/1 Running 44s pod/inference-disaggregated-0-router-w9f4n 1/1 Running 44s pod/inference-disaggregated-0-prefill-abc12 1/1 Running 44s pod/inference-disaggregated-0-prefill-def34 1/1 Running 44s pod/inference-disaggregated-0-prefill-ghi56 1/1 Running 44s pod/inference-disaggregated-0-prefill-jkl78 1/1 Running 44s pod/inference-disaggregated-0-decode-mn90p 1/1 Running 44s pod/inference-disaggregated-0-decode-qr12s 1/1 Running 44s
Một PodCliqueSet, ba PodClique (một cho mỗi vai trò), một PodGang để lập lịch phối hợp và các pod có số lượng bản sao tương ứng với mỗi vai trò. Sự startsAfterphụ thuộc được thực thi thông qua các container khởi tạo: Các pod điền trước và giải mã chờ bộ định tuyến sẵn sàng trước khi các container chính của chúng bắt đầu.
Mở rộng quy mô workload phân tách
Khi workload được phân tách và chạy, việc mở rộng quy mô trở thành thách thức vận hành chính. Quá trình điền trước dữ liệu và giải mã có những điểm nghẽn khác nhau; các nhóm có thể muốn tự động mở rộng quy mô các worker điền trước dữ liệu dựa trên thời gian nhận token đầu tiên (TTFT) và các worker giải mã dựa trên độ trễ giữa các token (ITL) một cách độc lập, để đáp ứng các thỏa thuận mức dịch vụ (SLA) đồng thời giảm thiểu chi phí GPU.
Trên thực tế, việc mở rộng quy mô phân tách hoạt động ở ba cấp độ:
- Mở rộng quy mô theo vai trò: thêm hoặc bớt các pod trong cùng một vai trò (ví dụ: mở rộng quy mô prefill từ 4 lên 6 bản sao)
- Điều chỉnh tỷ lệ theo từng nhóm TP: điều chỉnh tỷ lệ các nhóm Tensor Parallel hoàn chỉnh như các đơn vị nguyên tử, vì bạn không thể cộng một nửa nhóm TP.
- Phối hợp giữa các vai trò : khi bạn thêm dung lượng điền trước, bạn cũng có thể cần mở rộng bộ định tuyến để xử lý thông lượng tăng lên, hoặc mở rộng bộ giải mã để tiêu thụ lượng dữ liệu điền trước bổ sung.
Các công cụ khác nhau phục vụ các cấp độ khác nhau.
Cách các framework suy luận phối hợp việc mở rộng quy mô
Các framework suy luận giải quyết vấn đề mở rộng quy mô ở cấp độ ứng dụng bằng các bộ tự động mở rộng quy mô tùy chỉnh có khả năng hiển thị các chỉ số cụ thể của quá trình suy luận. Bộ tự động mở rộng quy mô biến thể workload (WVA) của llm-d giám sát mức sử dụng bộ nhớ cache KV trên mỗi pod và độ sâu hàng đợi thông qua Prometheus , sử dụng mô hình dung lượng dự phòng để xác định thời điểm nên thêm hoặc bớt bản sao. Thay vì mở rộng quy mô triển khai trực tiếp, WVA phát ra số lượng bản sao mục tiêu dưới dạng các chỉ số Prometheus mà cơ chế tự động mở rộng quy mô theo sự kiện (KEDA) dựa trên HPA/Kubernetes tiêu chuẩn sẽ xử lý — giữ cho việc thực thi mở rộng quy mô nằm trong các thành phần cơ bản của Kubernetes.
Công cụ lập kế hoạch NVIDIA Dynamo áp dụng một cách tiếp cận khác: Nó hiểu rõ việc phân chia máy chủ, chạy các vòng lặp mở rộng quy mô giải mã và điền trước riêng biệt nhằm mục tiêu đạt được SLA TTFT và ITL tương ứng. Nó dự đoán nhu cầu sắp tới bằng cách sử dụng các mô hình chuỗi thời gian, tính toán yêu cầu bản sao từ các đường cong thông lượng trên mỗi GPU đã được phân tích và thực thi ngân sách GPU toàn cầu cho cả hai vai trò.
Khả năng hiển thị toàn cầu này rất quan trọng vì trên thực tế, có một tỷ lệ tối ưu giữa việc điền trước dữ liệu và giải mã, tỷ lệ này thay đổi tùy thuộc vào mô hình yêu cầu. Nếu tăng quy mô điền trước dữ liệu lên 3 lần mà không tăng quy mô giải mã, lượng dữ liệu dư thừa sẽ không có nơi xử lý—gây ra tắc nghẽn giải mã và làm tăng hàng đợi truyền dữ liệu bộ nhớ cache KV. Các bộ tự động mở rộng quy mô cấp ứng dụng xử lý vấn đề này vì chúng có thể nhìn thấy toàn bộ quy trình; HPA gốc của Kubernetes nhắm mục tiêu vào từng tài nguyên riêng lẻ không tự động duy trì tỷ lệ giữa các tài nguyên.
Mở rộng quy mô với các nguồn lực LWS riêng biệt
Với một LWS cho mỗi vai trò, bạn có thể mở rộng quy mô từng LWS một cách độc lập:
kubectl scale lws prefill-workers --replicas=6 kubectl scale lws decode-workers --replicas=3
HPA tiêu chuẩn có thể nhắm mục tiêu vào từng LWS riêng biệt, hoặc một trình tự động mở rộng quy mô bên ngoài (như trình lập kế hoạch của Dynamo hoặc trình tự động mở rộng quy mô của llm-d) sẽ đưa ra các quyết định phối hợp và cập nhật cả hai. Logic phối hợp nằm trong trình tự động mở rộng quy mô, chứ không phải trong chính các tài nguyên Kubernetes.
Mở rộng quy mô với Grove
Grove mang khả năng mở rộng theo từng vai trò vào một tài nguyên duy nhất. Mỗi PodClique có số lượng bản sao riêng và tùy chọn autoScalingConfig, do đó HPA có thể quản lý các vai trò một cách độc lập dựa trên các chỉ số cho từng vai trò:
kubectl scale pclq inference-disaggregated-0-prefill --replicas=6
Người vận hành tạo thêm các hộp chứa dữ liệu được nạp sẵn mà không động đến bộ định tuyến và bộ giải mã:
NAME AGE podclique.grove.io/inference-disaggregated-0-router 5m podclique.grove.io/inference-disaggregated-0-prefill 5m podclique.grove.io/inference-disaggregated-0-decode 5m NAME READY STATUS AGE pod/inference-disaggregated-0-router-k8x2m 1/1 Running 5m pod/inference-disaggregated-0-router-w9f4n 1/1 Running 5m pod/inference-disaggregated-0-prefill-abc12 1/1 Running 5m pod/inference-disaggregated-0-prefill-def34 1/1 Running 5m pod/inference-disaggregated-0-prefill-ghi56 1/1 Running 5m pod/inference-disaggregated-0-prefill-jkl78 1/1 Running 5m pod/inference-disaggregated-0-prefill-tu34v 1/1 Running 12s # new pod/inference-disaggregated-0-prefill-wx56y 1/1 Running 12s # new pod/inference-disaggregated-0-decode-mn90p 1/1 Running 5m pod/inference-disaggregated-0-decode-qr12s 1/1 Running 5m
Sáu mô-đun nạp sẵn, hai mô-đun định tuyến, hai mô-đun giải mã—chỉ có mô-đun nạp sẵn là thay đổi.
Đối với các vai trò sử dụng song song Tensor đa nút bên trong, PodCliqueScalingGroup đảm bảo nhiều PodClique mở rộng quy mô cùng nhau như một đơn vị trong khi vẫn duy trì tỷ lệ bản sao giữa chúng. Ví dụ, trong cấu hình mà mỗi phiên bản điền trước bao gồm một pod lãnh đạo và bốn pod worker:
podCliqueScalingGroups: - name: prefill cliqueNames: [pleader, pworker] replicas: 2 minAvailable: 1 scaleConfig: maxReplicas: 4
Với tùy chọn “Bản sao: Hai”, điều này tạo ra hai phiên bản điền sẵn hoàn chỉnh: hai x (một leader + bốn worker) = tổng cộng 10 pod. Sự minAvailable: Oneđảm bảo này có nghĩa là hệ thống sẽ không mở rộng quy mô xuống dưới một nhóm Tensor Parallel hoàn chỉnh.
Việc mở rộng nhóm từ hai lên ba bản sao sẽ bổ sung thêm một phiên bản hoàn chỉnh thứ ba trong khi vẫn duy trì tỷ lệ lãnh đạo-thủ lĩnh là 1:4:
$ kubectl scale pcsg inference-disaggregated-0-prefill --replicas=3
Cả nhóm lãnh đạo và nhóm công nhân đều phát triển cùng nhau như một thể thống nhất, bản sao mới (prefill-2) có một pleader nhóm chính và bốn pworkernhóm phụ, phù hợp với tỷ lệ. Một PodGang mới được tạo ra cho bản sao thứ ba để đảm bảo nó được lên lịch theo nhóm.
NAME AGE podcliquescalinggroup.grove.io/inference-disaggregated-0-prefill 10m NAME AGE podclique.grove.io/inference-disaggregated-0-prefill-0-pleader 10m podclique.grove.io/inference-disaggregated-0-prefill-0-pworker 10m podclique.grove.io/inference-disaggregated-0-prefill-1-pleader 10m podclique.grove.io/inference-disaggregated-0-prefill-1-pworker 10m podclique.grove.io/inference-disaggregated-0-prefill-2-pleader 8s # new podclique.grove.io/inference-disaggregated-0-prefill-2-pworker 8s # new NAME AGE podgang.scheduler.grove.io/inference-disaggregated-0 10m podgang.scheduler.grove.io/inference-disaggregated-0-prefill-0 10m podgang.scheduler.grove.io/inference-disaggregated-0-prefill-1 8s # new
Bắt đầu
Cho dù bạn đang vận hành một pipeline riêng lẻ hay vận hành hàng chục pipeline trên toàn cụm máy chủ, các khối xây dựng cơ bản cho việc này đang dần hình thành và cộng đồng đang xây dựng chúng một cách công khai. Mỗi cách tiếp cận trong bài viết này đại diện cho một điểm khác nhau trên phổ giữa sự đơn giản và sự phối hợp tích hợp.
Sự lựa chọn phù hợp phụ thuộc vào workload của bạn, mô hình hoạt động của nhóm và mức độ quản lý vòng đời mà bạn muốn nền tảng xử lý so với lớp ứng dụng.
Hãy tham khảo các nguồn tài liệu này để biết thêm thông tin.
Hãy tham gia cùng chúng tôi tại Kubecon EU
Nếu bạn tham dự KubeCon EU 2026 tại Amsterdam , hãy ghé thăm gian hàng số 241 và tham gia phiên thảo luận nơi chúng tôi sẽ giới thiệu về một hệ thống suy luận AI mã nguồn mở hoàn chỉnh. Khám phá Hướng dẫn triển khai Grove và đặt câu hỏi trên GitHub hoặc Discord . Chúng tôi rất muốn nghe ý kiến của bạn về suy luận phân tách trên Kubernetes .
Bài viết liên quan
- Xây dựng chatbot AI nội bộ cho doanh nghiệp: Nhanh hơn, đúng ngữ cảnh hơn, kiểm soát tốt hơn
- NVIDIA Blackwell lập kỷ lục STAC-AI về suy luận LLM trong lĩnh vực tài chính
- Blueprint: PDF-to-Podcast – Biến tài liệu PDF thành Podcast bằng AI
- Giải mã NVIDIA AI-Q Blueprint: Kiến trúc multi-agent và bài toán hiệu năng trong Deep Research
- Ollama hay vLLM – Giải pháp nào phù hợp hơn với môi trường triển khai của bạn?
- MiniMax M2.7 nâng cao quy trình làm việc tác nhân có thể mở rộng trên nền tảng NVIDIA cho các ứng dụng AI phức tạp