
Đối với các kỹ sư AI và DevOps, việc quản lý tài nguyên GPU trong môi trường production Kubernetes thường xuyên gặp phải một bài toán hóc búa: Sự phân mảnh tài nguyên (Resource Fragmentation).
Hãy tưởng tượng bạn đang chạy một mô hình Nhận dạng giọng nói tự động (ASR) hoặc Chuyển văn bản thành giọng nói (TTS) cực kỳ nhẹ chỉ ngốn khoảng 10GB VRAM. Tuy nhiên, trong các bản triển khai Kubernetes tiêu chuẩn, mô hình “bé hạt tiêu” này lại ngang nhiên chiếm dụng toàn bộ một chiếc GPU đắt đỏ (như A100 40GB hay 80GB).
Bởi vì bộ lập lịch (scheduler) mặc định sẽ map một mô hình với một (hoặc nhiều) GPU và rất khó để chia sẻ GPU vắt chéo giữa các mô hình, dẫn đến việc các tài nguyên tính toán siêu đắt đỏ bị lãng phí nghiêm trọng. Việc giải quyết vấn đề này không chỉ đơn thuần là bài toán cắt giảm chi phí (cost reduction) — mà cốt lõi là việc tối ưu hóa mật độ cluster (cluster density) để phục vụ nhiều người dùng đồng thời hơn trên cùng một hệ thống phần cứng đẳng cấp thế giới.
Bài viết này sẽ đi sâu vào việc triển khai và benchmark các chiến lược phân mảnh GPU (GPU partitioning), cụ thể là NVIDIA Multi-Instance GPU (MIG) và Time-slicing, nhằm vắt kiệt từng giọt hiệu năng của hệ thống.

Bài Toán Đau Đầu Về Sự Phân Mảnh Tài Nguyên GPU
Theo mặc định, NVIDIA Device Plugin cho Kubernetes hiển thị các GPU dưới dạng tài nguyên số nguyên. Khi một pod gửi request nvidia.com/gpu: 1, scheduler sẽ ngay lập tức “trói chặt” (bind) nó vào một thiết bị vật lý duy nhất.
Các Mô hình Ngôn ngữ Lớn (LLM) như NVIDIA Nemotron, Llama 3, hoặc Qwen 7B/8B hiển nhiên cần tài nguyên compute chuyên biệt (dedicated) để duy trì chỉ số Thời gian ra token đầu tiên (TTFT – Time To First Token) ở mức thấp và Throughput theo batch cao. Tuy nhiên, các “kép phụ” (support models) trong một pipeline Generative AI — như mô hình Embedding, ASR, TTS, hoặc Guardrails — thường chỉ xài một phần rất nhỏ sức mạnh của card đồ họa.
Việc chạy các mô hình nhẹ này trên các GPU chuyên dụng (dedicated GPUs) gây ra hàng loạt hệ lụy:
-
Độ tận dụng thấp (Low utilization): GPU compute utilization thường lẹt đẹt ở mức 0-10%.
-
Phình to Cluster (Cluster bloat): Bạn phải provision (cấp phép) nhiều node hơn chỉ để chạy cùng một số lượng pod.
-
Rào cản mở rộng (Scaling friction): Cứ muốn thêm một tính năng (capability) mới, bạn lại phải cắm thêm một GPU vật lý.
Để phá vỡ thế bế tắc này, chúng ta buộc phải đập bỏ mối quan hệ 1:1 cứng nhắc giữa Pod và GPU.
Kiến Trúc: Các Chiến Lược Phân Mảnh (Partitioning Strategies)
Chúng tôi đã đánh giá hai chiến lược chính được hỗ trợ bởi NVIDIA GPU Operator.
1. Phân mảnh bằng Phần mềm: Time-slicing và MPS
Time-slicing (Cắt lát thời gian) cho phép nhiều process CUDA chia sẻ chung một GPU bằng cách thực thi xen kẽ (interleaving). Bạn cứ tưởng tượng nó giống hệt CPU scheduler: Context A chạy, tạm dừng, rồi đến lượt Context B chạy.
-
Cơ chế: Lập lịch ở tầng phần mềm (Software-level scheduling) thông qua CUDA driver.
-
Ưu điểm: Tối đa hóa utilization. Cho phép hiện tượng “bursting” (mượn tài nguyên đột biến) — nếu Pod A đang rảnh rỗi (idle), Pod B có thể scale lên để dùng 100% compute cores của GPU.
-
Nhược điểm: Không có khả năng cô lập phần cứng (No hardware isolation). Nếu xảy ra lỗi tràn bộ nhớ (OOM) ở một pod, nó có thể tác động đến toàn bộ shared execution context. Ngoài ra, việc một pod “nhai” quá nhiều compute có thể throttle (bóp nghẹt) hiệu năng của các neighbor (đây gọi là hiệu ứng Noisy Neighbor).
Ngoài Time-slicing, NVIDIA MPS (Multi-Process Service) cũng là một giải pháp software-based đáng chú ý. MPS dùng kiến trúc server-client để nhiều tiến trình cùng chia sẻ tài nguyên GPU đồng thời, mang lại tính linh hoạt cao hơn và chống chịu lỗi memory leak tốt hơn Time-slicing. Tuy nhiên, ở môi trường production, cả hai đều dùng chung một execution context. Một lỗi truy cập bộ nhớ trái phép (illegal memory access) từ một tiến trình có thể lây lan và khiến toàn bộ GPU bị reset.
2. MIG: Cách tiếp cận bằng Phần cứng (Hardware-level Partitioning)
NVIDIA MIG phân chia vật lý chiếc GPU thành các instance hoàn toàn tách biệt. Mỗi instance sẽ sở hữu bộ nhớ, cache (L2), và Streaming Multiprocessors (SMs) chuyên dụng. Đối với Hệ điều hành và K8s, chúng hiển thị như những thiết bị PCI riêng rẽ.
-
Cơ chế: Cô lập ở tầng phần cứng (Hardware-level isolation).
-
Ưu điểm: Quality of Service (QoS) được bảo đảm tuyệt đối. Việc workload này chạy nặng hay crash cũng không thể tác động đến hiệu năng hoặc độ ổn định bộ nhớ của workload kia.
-
Nhược điểm: Rigid sizing (Phân chia cứng nhắc). Nếu một partition đang rảnh, tài nguyên compute của nó không thể được “chia sẻ” hoặc “mượn” bởi neighbor.
Trong môi trường Production đòi hỏi SLA doanh nghiệp ngặt nghèo, MIG luôn là sự lựa chọn ưu tiên nhờ khả năng cô lập lỗi phần cứng, bảo vệ an toàn cho các tác vụ mang tính sống còn (mission-critical) như Voice AI.
Môi Trường Thực Nghiệm: Pipeline Voice AI
Để validate các chiến lược này dưới lăng kính thực tế, chúng tôi sử dụng một pipeline Voice-to-voice AI đa phương thức. Workload này là “bài test nhân phẩm” tuyệt vời vì nó trộn lẫn 3 pattern traffic riêng biệt:
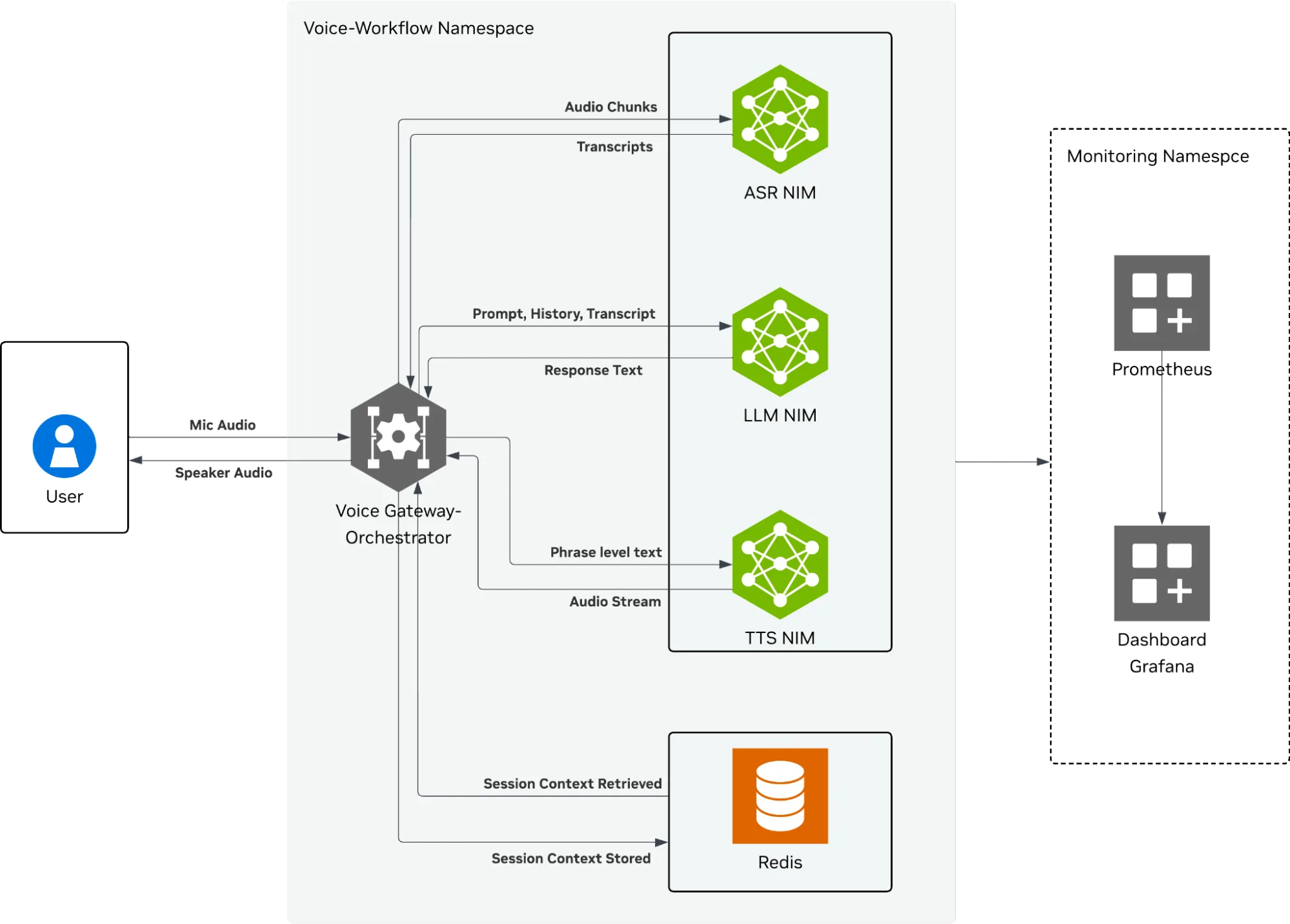
Quy trình AI voice-to-voice – Sơ đồ kiến trúc kỹ thuật của một hệ thống AI giọng nói đa phương thức.
-
ASR (Streaming): Quá trình stream liên tục, yêu cầu compute thấp với mô hình NVIDIA Parakeet 1.1B.
-
TTS (Bursty): Tắt nghỉ từng đợt. Idle trong vài giây, rồi “spike” lên 100% usage để render audio trong vài phần nghìn giây bằng NVIDIA Magpie.
-
Multilingual LLM (Heavy): Ngốn cả compute lẫn memory với Llama-3.1-Nemotron-Nano-VL-8B-V1.
Lưu ý về Latency: Trong pipeline này, LLM chính là “trùm” tạo ra nút thắt cổ chai (bottleneck). Dưới tải nặng, LLM mất tới ~9 giây để xử lý toàn bộ tiến trình. Khi context length càng dài, thời gian này càng tăng.
Giả thuyết của chúng tôi: Việc gộp chung ASR và TTS lên một GPU duy nhất sẽ duy trì được latency và jitter ở mức ổn định, đồng thời “giải phóng” một GPU nguyên vẹn để cắm thêm một instance LLM. Dù việc gộp chung có thể làm trễ khoảng 100-200ms, lợi ích về mặt ROI hạ tầng là không thể chối cãi.
Thiết Lập Thử Nghiệm (Experiment Setups)

Cấu hình topology thử nghiệm – Hình ảnh minh họa ba thiết lập thử nghiệm.
Cụm test sử dụng Kubernetes, mô hình deploy qua NVIDIA NIM, và worker node gắn 3 card NVIDIA A100 Tensor Core GPUs.
-
Experiment 1 (Baseline – 3 GPUs): 1 GPU riêng biệt cho mỗi mô hình (LLM, ASR, TTS). Đây là mức “Gold Standard” để làm mốc so sánh. (Tài nguyên:
nvidia.com/gpu: 1cho mỗi pod). -
Experiment 2 (Time-slicing – 2 GPUs): LLM giữ 1 GPU. ASR và TTS “đóng họ” chung trên GPU 0 bằng software-level time-slicing. Mục tiêu là test xem dynamic scheduling có xử lý được “noisy neighbor” giữa stream và burst hay không.
-
Experiment 3 (MIG Partitioning – 2 GPUs): LLM giữ 1 GPU. GPU 0 được phân mảnh vật lý thành 2 instance cách ly (Tài nguyên:
nvidia.com/mig-3g.40gb: 1cho mỗi pod).
Kết Quả Benchmark & Phân Tích
Hệ thống được test ở cả Tải nhẹ (Light load: 5 users) và Tải nặng (Heavy load: 50 users). Cả ba setup đều đạt tỷ lệ thành công 100%, không rớt request nào.
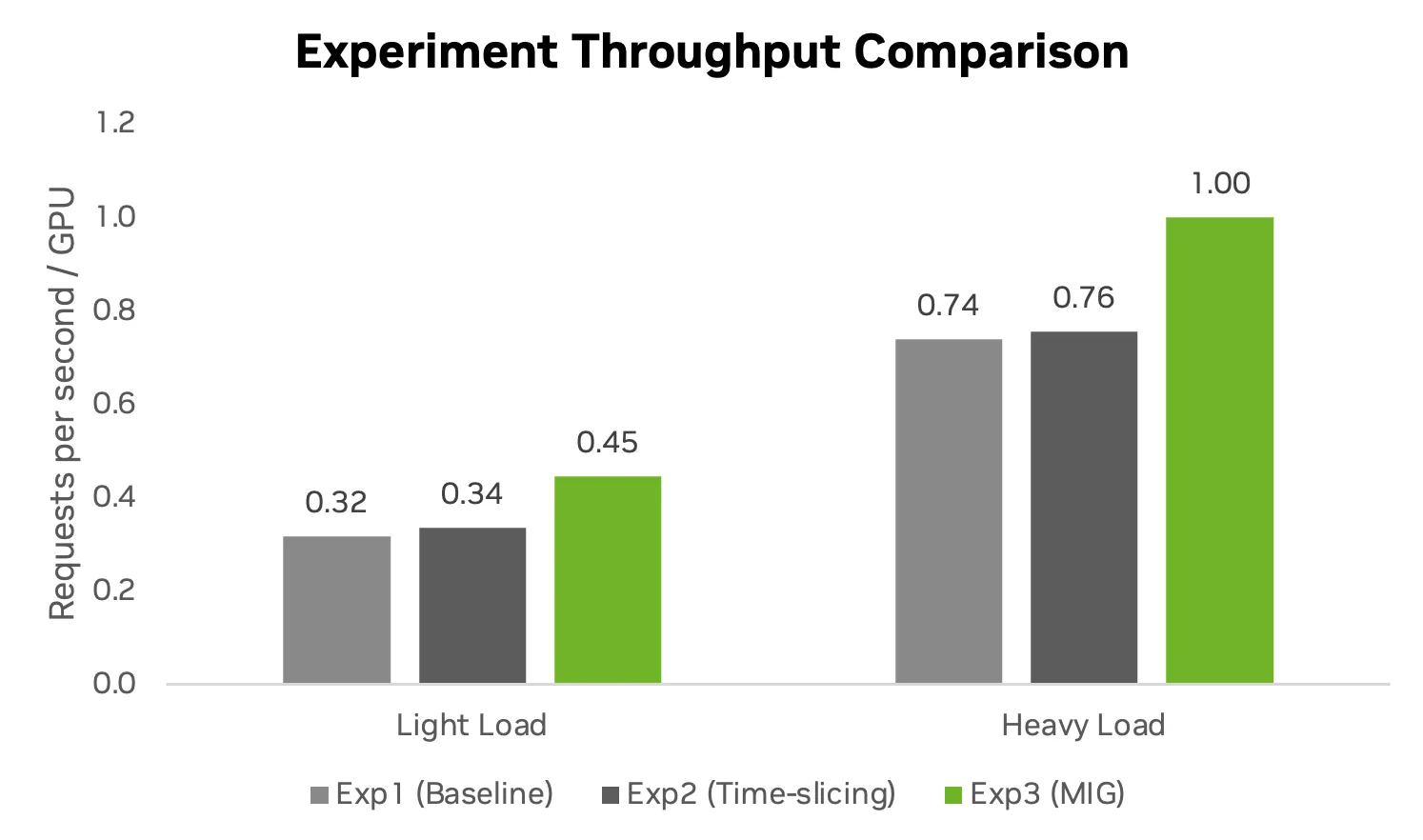
So sánh hiệu suất – Biểu đồ cột so sánh hiệu suất suy luận GenAI theo số yêu cầu mỗi giây trên mỗi GPU.
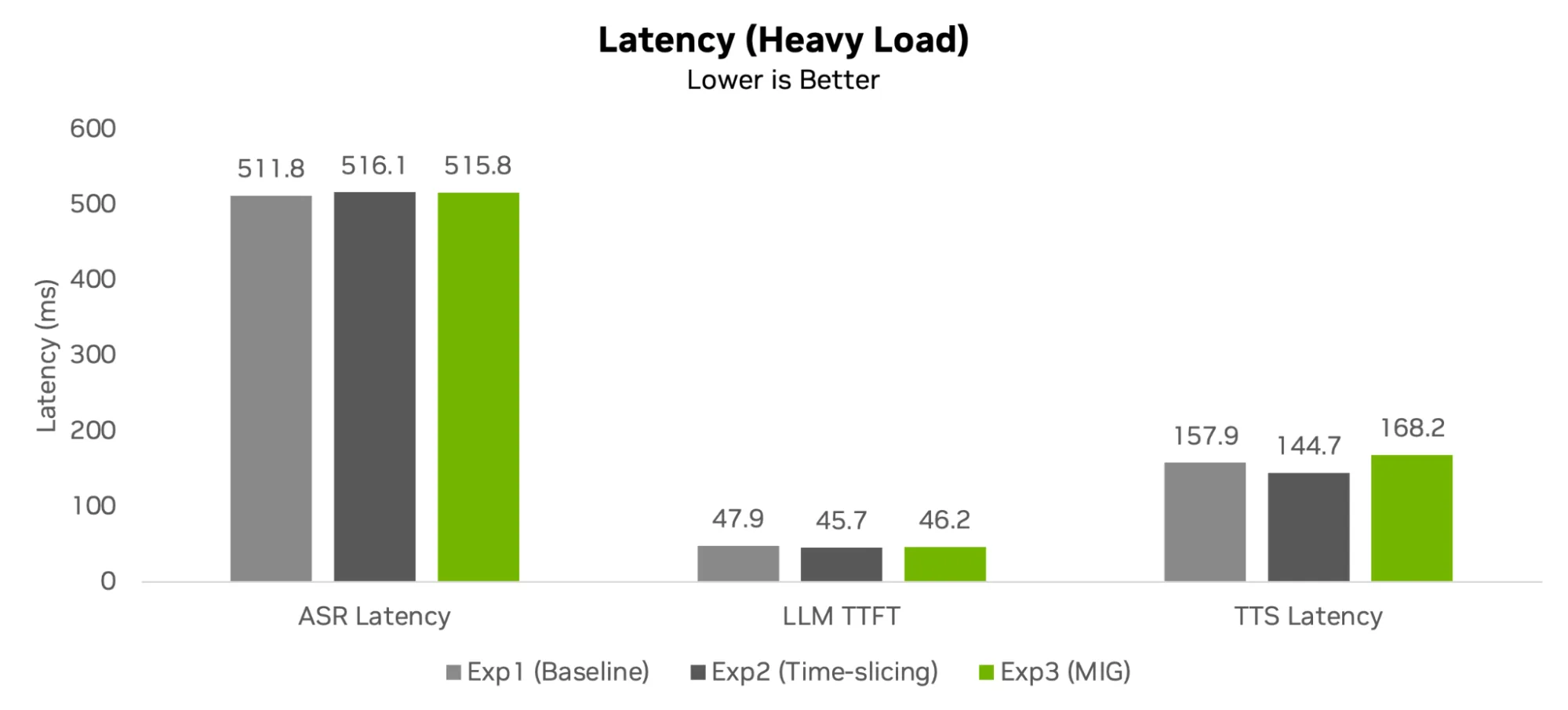
Độ trễ khi tải nặng – Biểu đồ cột thể hiện độ trễ trung bình tính bằng mili giây.
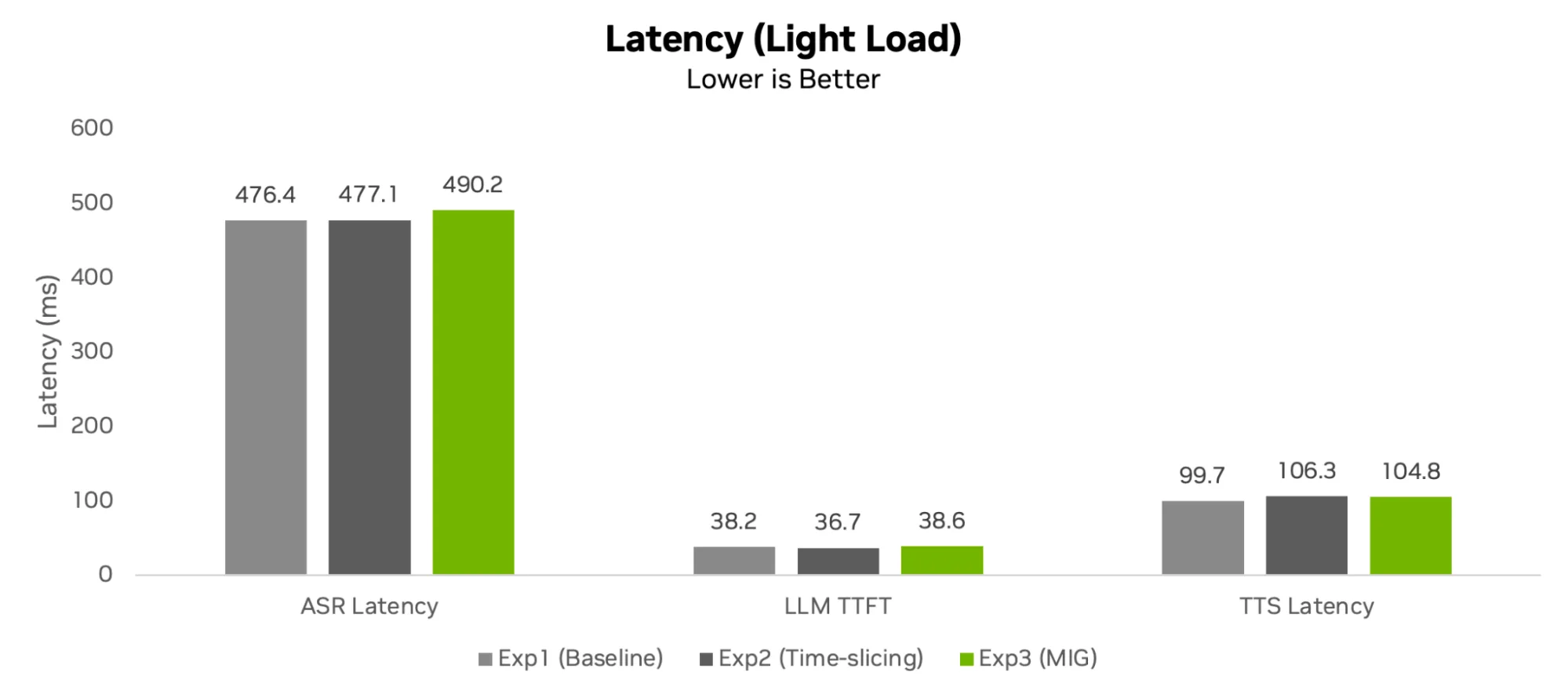
Độ trễ khi tải nhẹ – Biểu đồ cột đo độ trễ của các thành phần đường dẫn xử lý trong điều kiện tải nhẹ.
Việc hợp nhất ASR và TTS lên một GPU đã tạo ra một pipeline tối ưu hơn, gánh được nhiều luồng AI stream cùng lúc. Tuy nhiên, sự khác biệt nằm ở bản chất kỹ thuật:
MIG (Phần cứng) – Đạt Hiệu năng Đỉnh (Highest Efficiency): Experiment 3 vươn lên dẫn đầu với năng suất ~1.00 req/s mỗi GPU. Bằng cách cung cấp luồng phần cứng chuyên dụng, MIG “tiêu diệt” hoàn toàn sự tranh chấp tài nguyên (resource contention). Bạn vừa tận dụng tối đa capacity hệ thống, vừa rảnh tay 1 card GPU để gánh thêm LLM.
Time-slicing (Phần mềm) – Density Cao nhưng dính Overhead: Experiment 2 cũng tăng mật độ (density) tốt hơn bản baseline (~0.76 req/s mỗi GPU). Tuy nhiên, việc CUDA driver phải liên tục “nhảy cóc” (context switches) giữa mô hình streaming và mô hình bursty đã tạo ra overhead cho bộ lập lịch. Nó hoạt động tốt, nhưng không thể chạm ngưỡng aggregate throughput tối đa như MIG.
Độ trễ và Yếu tố Đột biến (Bursty Factor): Về mặt con số, Time-slicing xử lý các task “giật cục” nhanh hơn một chút (Mean TTS latency là 144.7ms so với 168.2ms của MIG). Khác biệt 23.5ms này nghe có vẻ hay, nhưng lại hoàn toàn vô nghĩa trong trải nghiệm người dùng cuối (End-user) bởi vì họ vốn đã phải đợi tới ~9 giây cho LLM chạy. Do đó, sự ổn định Throughput mà MIG mang lại có giá trị thực chiến lớn hơn rất nhiều so với vài ms latency nhặt nhạnh được.
Khuyến nghị
Dựa trên dữ liệu benchmark thực tế, chúng tôi đề xuất quy trình ra quyết định như sau:
-
Mặc định dùng MIG cho Production (Cần Scale và Độ ổn định): Experiment 3 chứng minh MIG “gánh” được volume request cao hơn (lên tới 2 req/s) với mức đánh đổi latency xấp xỉ bằng không. Sự cô lập lỗi nghiêm ngặt ở tầng phần cứng bảo vệ hệ thống khỏi những cú sập dây chuyền. Đây là lựa chọn “Chân ái” cho môi trường Production.
-
Dùng Time-slicing cho Môi trường Dev, PoC hoặc App ít truy cập: Với Time-slicing, bạn chấp nhận giảm khoảng 32% tổng thông lượng và sống chung với share resources. Đổi lại, nó cực kỳ linh hoạt và phù hợp cho môi trường Dev, CI/CD, hoặc dựng Proof-of-Concepts (PoC) nơi bạn muốn nhét toàn bộ pipeline AI siêu to khổng lồ vào một lượng phần cứng tối thiểu nhất định.
Việc dọn dẹp và tối ưu hóa hạ tầng chưa bao giờ là bài toán lỗi thời. Hy vọng rằng bài phân tích này sẽ giúp các anh em MLOps/DevOps có cái nhìn sắc bén hơn khi quyết định chia chác tài nguyên GPU trong hệ sinh thái Kubernetes!
Bài viết liên quan