
Retrieval-Augmented Generation (RAG) là một kỹ thuật AI cho phép kết nối một nguồn dữ liệu bên ngoài với mô hình ngôn ngữ lớn (LLM) để tạo ra các phản hồi theo từng lĩnh vực (domain-specific) hoặc cập nhật theo thời gian thực.
RAG hoạt động như thế nào?
Các mô hình LLM rất mạnh mẽ, nhưng kiến thức của chúng bị giới hạn trong dữ liệu tiền huấn luyện. Điều này gây khó khăn cho doanh nghiệp khi cần xây dựng các ứng dụng AI dựa trên tài liệu nội bộ và dữ liệu riêng của họ.
RAG giải quyết hạn chế này bằng cách bổ sung dữ liệu bên ngoài vào LLM. Kỹ thuật này sẽ truy xuất những thông tin liên quan từ nhiều nguồn dữ liệu có cấu trúc và phi cấu trúc—bao gồm văn bản, hình ảnh và video—để giúp LLM tạo ra câu trả lời dựa trên dữ liệu độc quyền của doanh nghiệp, từ đó tăng độ chính xác và giảm hiện tượng ảo giác.
Việc truy xuất chủ động này—thường được hỗ trợ bởi vector database để tìm kiếm ngữ nghĩa hiệu quả—cho phép LLM cung cấp phản hồi đầy đủ thông tin và phù hợp ngữ cảnh hơn, thay vì chỉ dựa vào dữ liệu tiền huấn luyện.
Tóm lại, RAG hoạt động như sau:
-
Truy vấn của người dùng được mã hóa thành một vector.
-
Hệ thống tìm kiếm các dữ liệu tương đồng về ngữ nghĩa.
-
Những thông tin liên quan nhất được thêm vào ngữ cảnh của mô hình.
-
Mô hình tạo ra phản hồi dựa trên dữ liệu đã được truy xuất.
RAG cho phép bạn tích hợp kiến thức chuyên ngành mà không cần huấn luyện lại toàn bộ LLM, giúp tiết kiệm tài nguyên tính toán.
Tìm kiếm ngữ nghĩa so với tìm kiếm từ khóa
Tìm kiếm từ khóa tập trung vào việc tìm kết quả khớp chính xác với các từ hoặc cụm từ mà người dùng nhập vào, xử lý truy vấn theo nghĩa đen và với mức hiểu biết hạn chế về từ đồng nghĩa hoặc ngữ cảnh. Ví dụ: tìm kiếm từ khóa “giày chạy bộ tốt nhất cho bàn chân bẹt” chỉ có thể trả về kết quả có chứa cụm từ chính xác đó.
Ngược lại, tìm kiếm ngữ nghĩa hướng tới việc hiểu ý nghĩa và mục đích đằng sau truy vấn bằng cách phân tích ngữ cảnh, mối quan hệ giữa các từ, và lịch sử người dùng để cung cấp kết quả phù hợp hơn. Ví dụ, khi tìm kiếm ngữ nghĩa cho cụm “best running shoes for flat feet” (những đôi giày chạy tốt nhất cho người bị bàn chân bẹt), hệ thống có thể trả về các kết quả như “stability running shoes” (giày chạy ổn định), “arch support running shoes” (giày chạy hỗ trợ vòm chân), hoặc thậm chí các bài đánh giá những mẫu giày phù hợp cho người có bàn chân bẹt — ngay cả khi những từ khóa đó không xuất hiện chính xác trong truy vấn tìm kiếm.
Về cơ bản, tìm kiếm từ khóa tìm kiếm các từ, trong khi tìm kiếm ngữ nghĩa tìm kiếm ý nghĩa.
Thông tin truy xuất (Information Retrieval) là gì và nó khác RAG như thế nào?
Information retrieval là quá trình tìm kiếm các tài liệu hoặc dữ liệu liên quan dựa trên truy vấn của người dùng. Nó sử dụng các thuật toán như BM25, TF-IDF và vector search để trả về một danh sách nguồn thông tin, và người dùng phải tự xem xét các tài liệu này để rút ra hiểu biết. Thay vì chỉ trả về tài liệu, RAG tổng hợp một câu trả lời trực tiếp dựa trên dữ liệu đã truy xuất, giúp giảm nhu cầu diễn giải thủ công. Trong khi information retrieval tập trung vào việc tìm nội dung liên quan, RAG sử dụng nội dung đó để tạo ra các câu trả lời có ngữ cảnh và mạch lạc theo thời gian thực.
Các thành phần chính của kiến trúc RAG là gì?
Một pipeline RAG chuẩn gồm ba giai đoạn: trích xuất (extraction) — nơi dữ liệu được thu nhận và tạo embedding, truy xuất (retrieval) và tạo sinh (generation). Mỗi giai đoạn đều đóng vai trò quan trọng trong việc đảm bảo hệ thống RAG truy xuất dữ liệu chính xác, đáng tin cậy và phù hợp.
Extraction (Trích xuất)
Trong giai đoạn trích xuất, dữ liệu doanh nghiệp được thu thập, chuyển đổi, lập chỉ mục và lưu trữ trong cơ sở dữ liệu vector. Ở bước này, mô hình embedding chuyển đổi nội dung dạng văn bản, âm thanh hoặc hình ảnh thành các vector đa chiều, cho phép tìm kiếm dựa trên độ tương đồng. Các vector embedding được lập chỉ mục (ví dụ: dưới dạng đồ thị) trước khi lưu để hỗ trợ truy xuất nhanh bằng các phương pháp approximate nearest neighbor (ANN).
Retrieval (Truy xuất)
Giai đoạn truy xuất có nhiệm vụ xác định và lấy ra dữ liệu liên quan bằng các kỹ thuật tìm kiếm vector và từ khóa. Nhiều hệ thống RAG cũng sử dụng mô hình reranking để xác định dữ liệu nào trong số những kết quả truy xuất là liên quan nhất. Thêm bước reranking vào giai đoạn retrieval giúp hệ thống RAG nâng cao độ chính xác tổng thể của câu trả lời cuối cùng.
Generation (Tạo sinh)
Cuối cùng, ở giai đoạn tạo sinh, các mô hình ngôn ngữ lớn (LLM) kết hợp prompt của người dùng với dữ liệu đã được truy xuất để tạo ra câu trả lời vừa có tính ngữ nghĩa, vừa chính xác theo ngữ cảnh. Sự kết hợp này đem lại lợi thế nổi bật cho RAG so với các giải pháp chỉ dùng LLM.
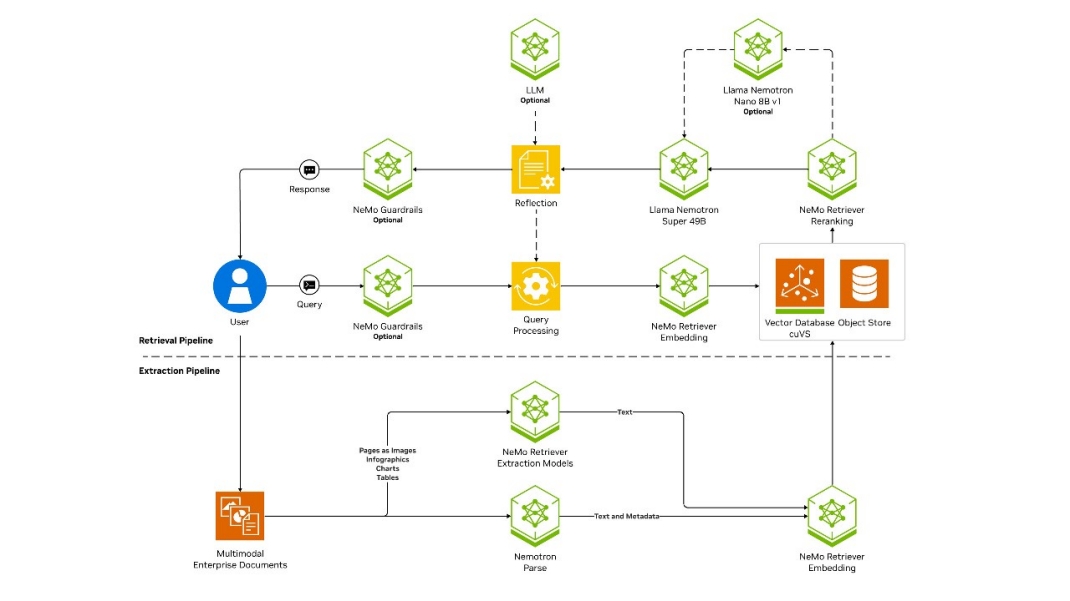
Một sơ đồ kiến trúc RAG mô tả ba giai đoạn: trích xuất dữ liệu, truy xuất và tạo sinh — được vận hành bởi các mô hình nền tảng NVIDIA Nemotron™ và các microservice NeMo™ Retriever, đồng thời được tăng tốc bằng NVIDIA cuVS.
Quy trình trích xuất dữ liệu trong RAG hoạt động như thế nào?
Trong một pipeline RAG, trích xuất dữ liệu bao gồm ba bước: thu thập dữ liệu, tạo embedding và lập chỉ mục.
Data Collection (Thu thập dữ liệu)
Đầu tiên, bạn cần thu thập, phân tích và làm sạch dữ liệu — như tài liệu, PDF, danh mục sản phẩm, hình ảnh hoặc thậm chí bản ghi âm đã được chuyển thành văn bản. Văn bản thường được chia nhỏ thành các đoạn hoặc phần để giới hạn kích thước cửa sổ ngữ cảnh và tối ưu độ chính xác khi truy xuất.
Việc trích xuất chất lượng cao (gồm metadata chính xác và ít trùng lặp) là cực kỳ quan trọng, vì ngay cả những LLM tiên tiến nhất cũng sẽ gặp khó khăn nếu dữ liệu nền bị thiếu hoặc bị tổ chức kém.
Phương pháp thu thập dữ liệu phù hợp phụ thuộc vào loại nguồn dữ liệu:
-
Batch (Theo lô): Phù hợp với các bộ dữ liệu ổn định hoặc ít thay đổi. Xử lý embedding theo lô.
-
Streaming (Liên tục): Thích hợp với dữ liệu thường xuyên được cập nhật (ví dụ: mạng xã hội, tin tức).
Embedding Generation (Tạo embedding)
Trong giai đoạn trích xuất, mô hình embedding chuyển đổi dữ liệu thành các vector embedding. Đây là các biểu diễn số của dữ liệu — như văn bản, hình ảnh hoặc âm thanh — trong một không gian nhiều chiều. Những embedding này nắm bắt ý nghĩa ngữ nghĩa của nội dung, cho phép truy xuất dựa trên độ tương đồng trong hệ thống RAG.
Những mục có ý nghĩa liên quan sẽ nằm gần nhau trong không gian vector, giúp việc tìm kiếm nhanh và hiệu quả.
Ví dụ: trong hệ thống tìm kiếm, truy vấn “fast GPU for deep learning” sẽ truy xuất được những tài liệu có embedding gần tương đồng, đảm bảo kết quả phù hợp về mặt ngữ cảnh. Embedding chất lượng cao là yếu tố cốt lõi để truy xuất chính xác và có ý nghĩa trong các ứng dụng AI.
Indexing (Lập chỉ mục)
Cuối cùng, khi các embedding đã được tạo và lưu trữ, hệ thống sẽ lập chỉ mục chúng trong một cơ sở dữ liệu vector. Vector database là thành phần trung tâm của các hệ thống RAG, dùng để lưu trữ hiệu quả thông tin dạng các chunk dữ liệu — mỗi chunk tương ứng với một vector đa chiều được tạo bởi mô hình embedding.
Các cơ sở dữ liệu này xử lý tốt những thao tác đặc thù của không gian vector như cosine similarity, đồng thời cung cấp các lợi thế quan trọng như:
- Tìm kiếm dựa trên độ tương đồng hiệu quả
-
Khả năng xử lý dữ liệu nhiều chiều
-
Khả năng mở rộng
-
Xử lý thời gian thực
-
Nâng cao độ liên quan của kết quả tìm kiếm
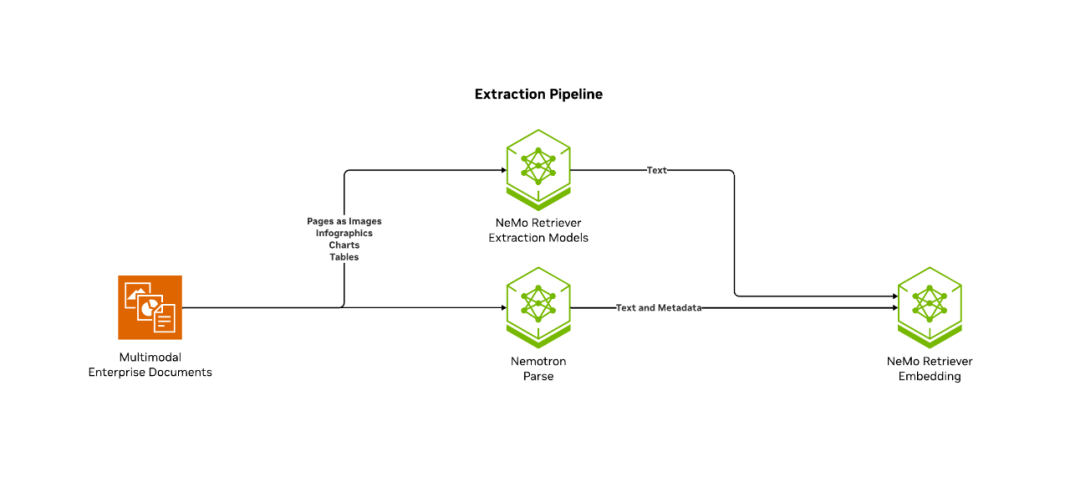
Một sơ đồ kiến trúc RAG mô tả ba giai đoạn: trích xuất dữ liệu, truy xuất và tạo sinh — được vận hành bởi các mô hình nền tảng NVIDIA Nemotron™ và các microservice NeMo™ Retriever, và được tăng tốc bằng NVIDIA cuVS.
RAG trích xuất loại dữ liệu nào?
Vì RAG không giới hạn ở văn bản, nó cũng có thể xử lý dữ liệu hình ảnh, âm thanh và video bằng cách chuyển chúng thành các embedding thông qua các mô hình thị giác máy tính và xử lý giọng nói. Điều này cho phép truy xuất đa phương thức (cross-modal), nơi người dùng có thể truy vấn xuyên giữa nhiều loại dữ liệu.
Ví dụ, một nền tảng thương mại điện tử có thể tạo embedding cho cả mô tả sản phẩm và hình ảnh sản phẩm, nhờ vậy người dùng có thể tìm kiếm bằng hình ảnh (“Tìm các hình tương tự với ảnh tham chiếu này”) hoặc bằng văn bản. Việc hỗ trợ nhiều định dạng dữ liệu giúp các ứng dụng doanh nghiệp và người dùng trở nên thông minh hơn.
Các mô hình đa ngôn ngữ (embedding và LLM) được sử dụng trong RAG cho phép khả năng truy cập toàn cầu cho các ứng dụng AI sinh tạo doanh nghiệp bằng cách hỗ trợ cả truy vấn và tài liệu ở nhiều ngôn ngữ khác nhau.
Quy trình truy xuất trong RAG hoạt động như thế nào?
Truy xuất có nhiệm vụ xác định dữ liệu liên quan nhất để nâng cao chất lượng phản hồi của LLM. Quá trình này thường bắt đầu với query rewriting—tự động tinh chỉnh truy vấn gốc. Điều này có thể bao gồm mở rộng truy vấn bằng từ đồng nghĩa, xử lý các trường hợp mơ hồ, hoặc bổ sung ngữ cảnh từ các tương tác trước đó nhằm cải thiện độ chính xác của truy xuất.
Tiếp theo, truy vấn được chuyển đổi thành một embedding — một vector số — bằng mô hình embedding. Việc chuyển đổi này đảm bảo truy vấn tương thích với các embedding đã được lưu trữ. Do đó, cần duy trì sự nhất quán giữa embedding lúc ingestion (khi đưa dữ liệu vào hệ thống) và embedding lúc truy vấn.
Cuối cùng, hệ thống thực hiện tìm kiếm dựa trên độ tương đồng (similarity search), truy xuất top-k các đoạn liên quan nhất bằng cách đo khoảng cách vector theo các metric như cosine similarity, Euclidean distance hoặc dot product. Các thuật toán ANN giúp tối ưu bước này bằng cách thu hẹp nhanh tập ứng viên tiềm năng.
Nội dung được truy xuất — dù là văn bản, hình ảnh hay dữ liệu khác — sẽ cung cấp ngữ cảnh quan trọng cho phản hồi cuối cùng của LLM.
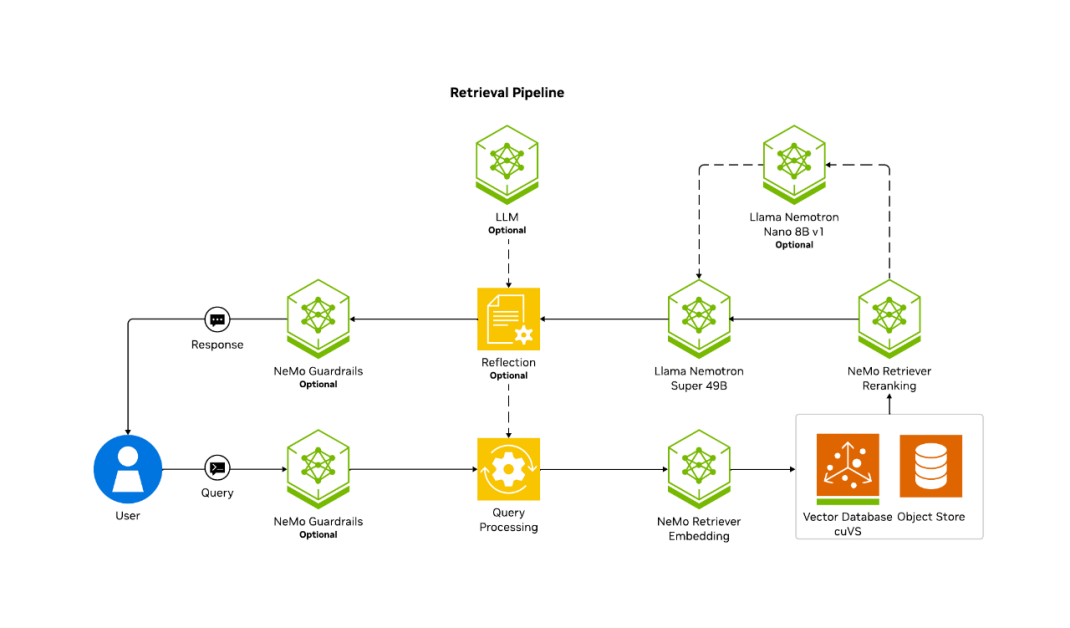
Sơ đồ kiến trúc mô tả bước truy xuất trong pipeline RAG với cơ sở dữ liệu vector được tăng tốc bằng GPU — vận hành bởi các mô hình NVIDIA Nemotron, các microservice NeMo Retriever và NVIDIA cuVS.
Sau bước truy xuất, hệ thống sẽ thực hiện reranking để tinh chỉnh kết quả bằng cách ưu tiên những dữ liệu liên quan nhất thông qua một mô hình reranking. Việc ưu tiên này có thể dựa trên tính mới (recency), mức độ liên quan theo miền dữ liệu (domain relevance) hoặc sở thích của người dùng.
Các mô hình reranking — dù dựa trên heuristic hay sử dụng machine learning (ML) — đều giúp cải thiện khả năng thu hồi (recall) trong truy xuất, đảm bảo rằng LLM sẽ xử lý những thông tin chất lượng cao nhất trước tiên.
Reranking model là gì?
Reranking model (mô hình xếp hạng lại) tinh chỉnh các kết quả được truy xuất bằng cách ưu tiên những đoạn dữ liệu liên quan nhất trước khi đưa chúng vào LLM. Sau bước truy xuất ban đầu, các mô hình reranking sẽ sắp xếp lại nội dung dựa trên các tín hiệu về mức độ liên quan, chẳng hạn như tần suất từ khóa, độ tương đồng ngữ nghĩa, tính mới (recency) hoặc mức độ khớp với metadata.
Chúng có thể là mô hình dựa trên quy tắc (heuristics như BM25), mô hình học máy (ML-driven, được huấn luyện để dự đoán mức độ liên quan), hoặc mô hình lai kết hợp nhiều yếu tố. Reranking hiệu quả giúp LLM xử lý những dữ liệu hữu ích nhất trước, cải thiện độ chính xác và hiệu suất của hệ thống RAG.
Các kỹ thuật truy xuất nâng cao là gì?
Để tối ưu hóa phản hồi của LLM, có nhiều kỹ thuật truy xuất nâng cao giúp tăng độ chính xác của tìm kiếm bằng cách kết hợp nhiều phương pháp, xử lý lượng dữ liệu lớn và thích ứng với sự tinh tế trong truy vấn.
| Các kỹ thuật truy xuất nâng cao | |
|---|---|
| Hybrid Retrieval (Truy xuất lai) | Cách tiếp cận này kết hợp tìm kiếm vector với các kỹ thuật truyền thống như BM25. |
| Long Context Retrieval (Truy xuất ngữ cảnh dài) | Một số LLM có thể xử lý hàng nghìn token trong một prompt, cho phép chúng xem xét lượng lớn nội dung được truy xuất. Điều này đặc biệt hữu ích trong các lĩnh vực nghiên cứu, pháp lý và kỹ thuật — nơi câu trả lời cần tổng hợp từ nhiều nguồn. Tuy nhiên, prompt càng dài thì chi phí tính toán và mức sử dụng bộ nhớ càng tăng. |
| Contextual Retrieval (Truy xuất theo ngữ cảnh) | Bổ sung thêm ngữ cảnh cho mỗi chunk thông qua metadata — chẳng hạn như tài liệu mà chunk thuộc về, tóm tắt nội dung xung quanh hoặc ngày chunk được lập chỉ mục — là một cách khác để tăng khả năng pipeline truy xuất đúng ngữ cảnh. Phương pháp này, được gọi là “contextual retrieval”, đặc biệt hiệu quả khi xử lý các tài liệu phức tạp đa nguồn, như kho mã nguồn, tài liệu pháp lý và các bài nghiên cứu khoa học. |
Quy trình tạo sinh (Generation) trong RAG hoạt động như thế nào?
Khi thông tin liên quan đã được truy xuất, giai đoạn tạo sinh trong RAG sẽ tổng hợp câu trả lời cuối cùng bằng cách sử dụng LLM. Quá trình này bao gồm:
- LLM-Based Synthesis (Tổng hợp dựa trên LLM): Các chunk top-k được truy xuất sẽ được chèn vào prompt của mô hình cùng với truy vấn của người dùng. LLM tạo câu trả lời dựa trên dữ liệu đã truy xuất, giúp giảm ảo giác (hallucination) và tăng độ chính xác thực tế. Nhiều hệ thống RAG trong doanh nghiệp còn tăng tính minh bạch bằng cách trích dẫn hoặc gắn link các nguồn trực tiếp trong nội dung tạo sinh.
-
Summarization and Reasoning (Tóm tắt và suy luận): Trong các lĩnh vực đòi hỏi nhiều kiến thức như y khoa, pháp lý hoặc nghiên cứu, RAG có thể tóm tắt thông tin từ nhiều nguồn và trình bày chúng dưới dạng có cấu trúc như bullet point hoặc đoạn văn ngắn. Điều này giúp người dùng nhanh chóng nắm được nội dung chính mà không cần đọc nhiều tài liệu.
Các triển khai RAG nâng cao còn cho phép mô hình suy luận dựa trên nội dung được truy xuất, tạo ra câu trả lời mạch lạc và giàu ngữ cảnh. - Output Validation (Kiểm định đầu ra): Trong các ứng dụng quan trọng, một bước kiểm định bổ sung giúp đảm bảo câu trả lời tạo sinh trung thực với dữ liệu đã truy xuất. Việc này có thể bao gồm:
-
So sánh đầu ra với dữ liệu đã truy xuất để phát hiện điểm không nhất quán.
-
Dùng một LLM thứ hai để kiểm tra các tuyên bố của mô hình đầu tiên.
-
Ghi log câu trả lời cùng với các nguồn tham chiếu để đảm bảo khả năng kiểm tra và tuân thủ.
-
-
Bằng cách xây dựng câu trả lời dựa trên thông tin đã được xác minh, RAG tăng mạnh độ tin cậy và tính minh bạch của nội dung AI tạo ra.
Advanced RAG là gì?
Các đường ống RAG nâng cao mang lại lợi ích cho các ứng dụng phức tạp đòi hỏi phản hồi phong phú theo ngữ cảnh, như các công cụ hỗ trợ khách hàng, dịch vụ pháp lý và quản lý kiến thức doanh nghiệp.
Các pipeline RAG nâng cao hỗ trợ những ứng dụng phức tạp cần câu trả lời giàu ngữ cảnh, như công cụ hỗ trợ khách hàng, dịch vụ pháp lý và quản lý tri thức doanh nghiệp.
Trong khi retrieval đơn giản có thể đủ với một số trường hợp, nhiều quy trình AI tác tử (agentic AI) đòi hỏi nhiều tác tử AI phối hợp để đạt mục tiêu chung. Ví dụ: thiết kế phần mềm, tự động hóa IT và sinh mã — đều cần quá trình trích xuất và xử lý dữ liệu sâu rộng để đảm bảo độ chính xác.
Lợi Ích Của RAG Là Gì?
RAG nâng cao chất lượng phản hồi do AI tạo ra bằng cách tích hợp khả năng truy xuất dữ liệu bên ngoài, mang lại một số lợi ích quan trọng:
- Cải thiện độ chính xác thực tế (Improved Factual Accuracy): Bằng cách truy xuất dữ liệu từ nguồn đáng tin cậy và cập nhật, RAG giúp giảm hiện tượng “hallucination” và đảm bảo câu trả lời bám sát sự thật.
- Tính linh hoạt và khả năng thích ứng theo lĩnh vực (Flexibility and Domain Adaptation): RAG dễ dàng được tùy chỉnh theo từng lĩnh vực hoặc kho tri thức mà không cần huấn luyện lại hoặc tinh chỉnh LLM. Chỉ cần thay đổi hoặc cập nhật nguồn dữ liệu.
- Dữ liệu luôn cập nhật (Up-to-Date Information): Khác với LLM truyền thống chỉ dựa trên dữ liệu tĩnh, RAG luôn truy xuất dữ liệu mới nhất để đưa vào câu trả lời.
- Dễ hiểu và minh bạch (Interpretability and Transparency): Người dùng và nhà phát triển có thể xem những tài liệu nào được truy xuất và dùng để tạo câu trả lời. Điều này tăng tính kiểm chứng, minh bạch và sự tin tưởng.
- Những lợi ích này khiến RAG trở thành phương pháp mạnh mẽ cho các ứng dụng yêu cầu câu trả lời cập nhật, chính xác và có ngữ cảnh.
Ứng dụng của RAG là gì?
Sự phát triển từ chatbot AI lên trợ lý AI và tiếp theo là các tác nhân AI (AI agents) đánh dấu một cột mốc quan trọng đối với doanh nghiệp và lực lượng lao động số. Các ứng dụng phần mềm được hỗ trợ bởi AI sinh tữ này sử dụng RAG để truy vấn cơ sở dữ liệu theo thời gian thực, cung cấp các câu trả lời phù hợp với ngữ cảnh câu hỏi của người dùng và được bổ sung bằng những thông tin mới nhất mà không cần phải huấn luyện lại mô hình ngôn ngữ nền tảng (LLM). Tiến bộ này tạo ảnh hưởng sâu rộng đến mức độ tương tác của người dùng, đặc biệt trong các ngành như dịch vụ khách hàng, giáo dục và giải trí — nơi nhu cầu về phản hồi tức thời, chính xác và giàu thông tin là vô cùng quan trọng.
Các lĩnh vực yêu cầu trí tuệ nhân tạo cung cấp thông tin chính xác dựa trên dữ liệu đáng tin cậy theo thời gian thực bao gồm:
| Tìm kiếm Doanh nghiệp & Quản lý Tri thức (Enterprise Search & Knowledge Management)
Cải thiện khả năng tìm kiếm nội bộ bằng cách truy xuất và tổng hợp thông tin từ các tài liệu doanh nghiệp, wiki và cơ sở tri thức lớn, giúp giảm thời gian tìm kiếm câu trả lời. |
Tài chính & Thông tin Thị trường (Financial and Market Intelligence)
Hỗ trợ các nhà phân tích bằng cách truy xuất và tóm tắt xu hướng thị trường theo thời gian thực, báo cáo doanh nghiệp và hồ sơ pháp lý để ra quyết định chính xác. |
Hỗ trợ Khách hàng & Chatbot (Customer Support and Chatbots)
Cung cấp sức mạnh cho các trợ lý ảo dựa trên AI với khả năng trả lời chính xác và cập nhật bằng cách truy xuất chính sách công ty, FAQ và hướng dẫn xử lý sự cố — thay vì chỉ dựa vào kiến thức được huấn luyện sẵn. |
|
Y tế & Nghiên cứu Lâm sàng (Healthcare and Medical Research) Hỗ trợ bác sĩ và nhà nghiên cứu bằng cách truy xuất và tóm tắt các nghiên cứu y khoa mới nhất, hướng dẫn lâm sàng và hồ sơ bệnh án để hỗ trợ quá trình ra quyết định. |
Pháp lý & Tuân thủ (Legal and Compliance Assistance) Truy xuất và tổng hợp tài liệu pháp lý, án lệ và hướng dẫn quy định để hỗ trợ luật sư và đội ngũ tuân thủ trong nghiên cứu và phân tích hợp đồng. |
Mã nguồn & Tài liệu kỹ thuật (Code and Software Documentation) Hỗ trợ nhà phát triển bằng cách truy xuất đoạn mã liên quan, tài liệu API và hướng dẫn khắc phục sự cố từ kho mã và tài liệu kỹ thuật. |
Làm thế nào để bạn cải thiện độ chính xác của RAG?
Có nhiều cách để cải thiện độ chính xác của một pipeline RAG, từ phương pháp tham số (như fine-tuning) cho đến các điều chỉnh phi tham số trong pipeline.
Lựa chọn mô hình:
Việc chọn đúng mô hình cho pipeline RAG ảnh hưởng lớn đến độ chính xác. Hãy đảm bảo bạn đang sử dụng mô hình tốt nhất cho từng chức năng (mô hình embedding, mô hình reranking và mô hình tạo sinh) để tối ưu hóa hiệu suất tổng thể.
Fine-tuning:
Một phương pháp phổ biến để cải thiện độ chính xác là fine-tune mô hình tạo sinh (LLM tạo ra câu trả lời cuối cùng) và/hoặc mô hình embedding (dùng trong retrieval và extraction). Bằng cách thu thập phản hồi của người dùng về các câu trả lời, bạn có thể thiết lập một “data flywheel” tự động fine-tune mô hình tạo sinh theo thời gian.
Reranking:
Sử dụng mô hình reranking giúp chọn ra ngữ cảnh liên quan nhất để trả lời truy vấn. Mặc dù thêm một chút độ trễ, nhưng lợi ích về độ chính xác thường vượt trội.
Hyperparameters trong RAG:
Bằng cách điều chỉnh và thử nghiệm các siêu tham số như kích thước chunk, mức độ chồng lặp chunk, và kích thước embedding, bạn có thể cải thiện pipeline một cách đáng kể. Những phương pháp này cần hệ thống đánh giá mạnh (ví dụ NeMo Evaluator Microservice), nhưng có thể tác động lớn đến độ chính xác.
Tăng cường truy vấn (Query Augmentation):
Thông qua việc áp dụng các kỹ thuật như chuyển đổi truy vấn, viết lại truy vấn, v.v., bạn có thể đảm bảo truy vấn phù hợp hơn với pipeline đã xây dựng cho từng miền dữ liệu.
Làm thế nào để có thể tăng tốc RAG?
Pipeline RAG—kết hợp sức mạnh của LLM với nguồn dữ liệu bên ngoài—có thể tăng tốc nhờ các kỹ thuật sau:
Dùng mô hình nhỏ, đã fine-tune:
Thay vì chỉ dựa vào các LLM lớn, có thể dùng các mô hình nhỏ được fine-tune cho những tác vụ cụ thể để tạo câu trả lời.
→ Giảm chi phí tính toán và tăng tốc độ suy luận.
Tận dụng cơ sở dữ liệu tăng tốc bằng GPU:
Đẩy việc retrieval sang hệ thống dùng GPU để truy cập dữ liệu nhanh hơn.
→ Giảm đáng kể độ trễ trong giai đoạn truy xuất dữ liệu.
Tối ưu hóa cấu trúc indexing.
Caching dữ liệu được truy cập thường xuyên.
Làm thế nào bạn có thể bắt đầu với RAG?
Để bắt đầu xây dựng các ứng dụng RAG mẫu, hãy tải NVIDIA AI Blueprint dành cho việc xây dựng các pipeline RAG cấp doanh nghiệp. Kiến trúc tham chiếu này cung cấp cho các nhà phát triển một nền tảng vững chắc để xây dựng các pipeline truy xuất có khả năng mở rộng, tùy chỉnh, đồng thời đạt độ chính xác và thông lượng cao.
Blueprint này tích hợp những công nghệ tiên tiến nhất của NVIDIA, bao gồm:
- NVIDIA Nemotron (các mô hình nền tảng),
-
NVIDIA NeMo Retriever cho extraction, embedding và reranking,
-
NVIDIA cuVS để tăng tốc xử lý dữ liệu và cung cấp giải pháp RAG mở rộng với chi phí tối ưu
Để kết nối các AI agent với lượng dữ liệu lớn và đa dạng, bạn có thể xây dựng AI Query Engine. Bắt đầu với AI-Q, Blueprint của NVIDIA dành cho xây dựng AI agent—được vận hành bằng RAG và NeMo Retriever. Ngoài ra, các lập trình viên có thể dùng NVIDIA NeMo Agent Toolkit mã nguồn mở để kết nối các nhóm agent và tối ưu hệ thống AI đa tác nhân.
Việc đưa ứng dụng RAG vào sản xuất đi kèm với các thách thức như chọn lọc dữ liệu, quản trị, bảo mật, mở rộng và độ phức tạp triển khai. NVIDIA AI Enterprise đơn giản hóa phát triển và triển khai bằng bộ công cụ mạnh mẽ gồm NVIDIA Blueprints, NVIDIA NeMo, và NVIDIA NIM.
Hãy đăng ký dùng thử 90 ngày để truy cập mức độ bảo mật cấp doanh nghiệp và nhận được sự hỗ trợ cần thiết để mở rộng quy mô AI một cách tự tin.