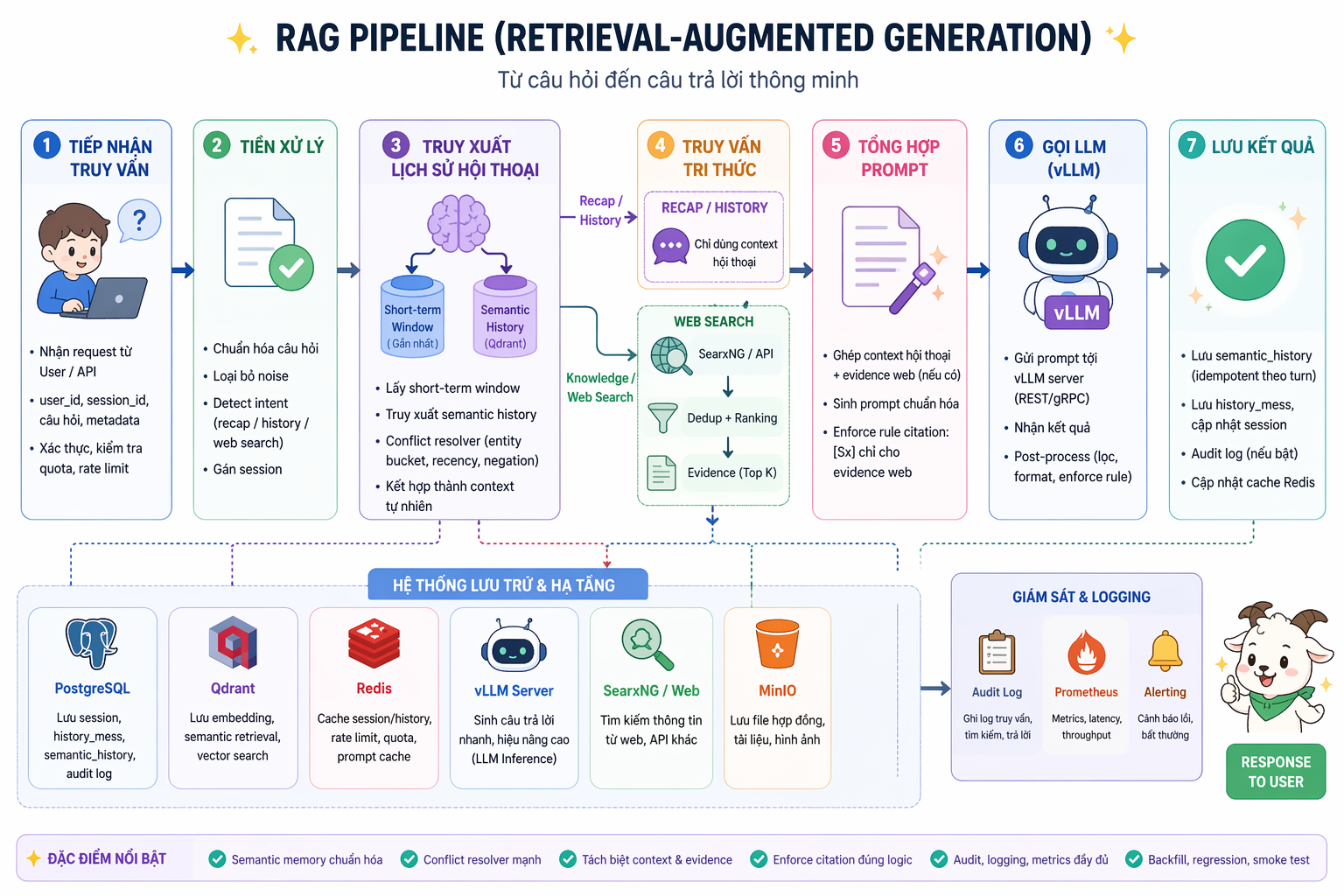
Dạo một vòng qua các bài tutorial, các khóa học hay thậm chí là document của những framework RAG đình đám hiện nay, bạn sẽ dễ dàng nhận ra một xu hướng: kiến trúc RAG đang ngày càng “phình to” một cách đáng sợ.
Để trả lời một truy vấn đôi khi rất đơn giản của người dùng, hệ thống bị ép phải đi qua hàng tá bước cồng kềnh. Nào là query routing, nhồi nhét một cái retriever phức tạp, thêm một model cross-encoder siêu nặng tốn cả mớ VRAM chỉ để re-ranking, rồi lại ép luồng chạy qua vài vòng LLM calls để mô hình tự suy luận, tự kiểm tra (self-reflection).
Chạy demo trên Jupyter Notebook hay khoe với sếp thì kết quả trả về trông có vẻ rất “thông minh” và lung linh. Nhưng khi thực sự bế hệ thống đó ném lên môi trường production thực tế, chúng ta mới vỡ mộng: Time-To-First-Token (TTFT) tăng vọt. Một hệ thống AI mà người dùng phải nhìn con trỏ chuột nhấp nháy 5-10 giây mới nặn ra được chữ đầu tiên thì xét về mặt sản phẩm, đó là một thất bại. Sự kiên nhẫn của user tỷ lệ nghịch với độ phức tạp của hệ thống.
Và độ trễ (latency) cao làm hỏng trải nghiệm người dùng mới chỉ là phần nổi của tảng băng chìm. Nỗi đau thực sự của anh em dev và người vận hành hệ thống nằm ở hai chữ: Chi phí và Kiểm soát.
Khi bạn chồng chéo quá nhiều component và đẩy toàn bộ logic suy luận lên các API của bên thứ ba, chi phí compute và API token sẽ đội lên không kiểm soát. Tệ hơn nữa là cái bẫy “vendor lock-in”. Bạn giao phó toàn bộ huyết mạch hệ thống, từ quyền riêng tư dữ liệu (data privacy) đến luồng vận hành, vào tay một vài nhà cung cấp Cloud API. Ngày đẹp trời họ đổi bảng giá, thay đổi policy bảo mật, hay đơn giản là hạ tầng của họ gặp sự cố, hệ thống của bạn chỉ có nước nằm im chịu trận.
Đó chính là lý do tôi quyết định đi ngược lại số đông trong dự án lần này. Mục tiêu tôi đặt ra rất rõ ràng: Thiết kế một pipeline RAG “lean & mean” (tinh gọn và thực dụng).
Tôi chấp nhận gạt bỏ những hào nhoáng của multi-agent hay reasoning phức tạp để đưa kiến trúc về dạng cơ bản nhất, nhưng được tối ưu hiệu năng đến từng millisecond. Trọng tâm của hệ thống này là: phục vụ luồng dữ liệu nhanh nhất có thể, giữ toàn bộ data và model on-premise/local để giành lại 100% quyền kiểm soát, và thiết kế sao cho việc scale (mở rộng) khi throughput tăng cao trở thành một bài toán dễ thở.
Kiến trúc tổng quan
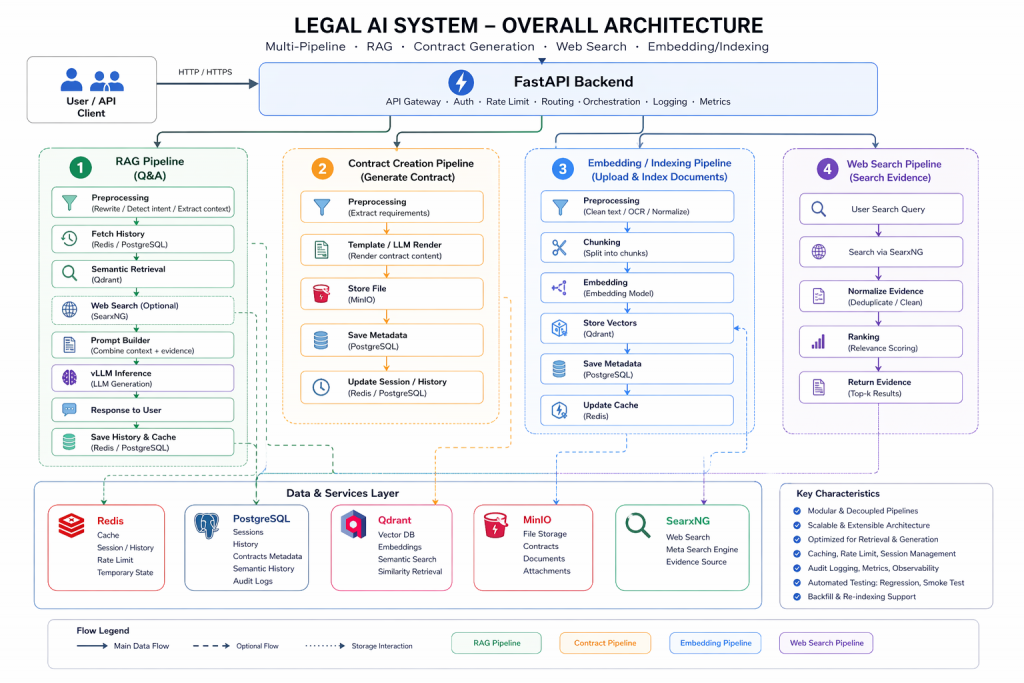
Để giải quyết bài toán độ trễ và thông lượng cao (high concurrency), tôi quyết định đập đi xây lại tư duy thiết kế luồng dữ liệu. Thay vì “nhồi nhét”, tôi chọn cách “tỉa cành”. Hệ thống chỉ giữ lại những component thực sự sinh ra giá trị trực tiếp cho việc trả lời câu hỏi của người dùng.
Dưới đây là sơ đồ luồng dữ liệu (Data flow) của pipeline RAG tối giản mà tôi áp dụng:
graph TD;
User[User / Client] -->|1. Query| API[FastAPI Backend]
API -->|2. Lấy Context siêu tốc| Cache[Redis: Cache & Short-term History]
API -->|3. Semantic Search| VectorDB[Qdrant: Vector Database]
API -->|4. Context Injection| Prompt[Tổng hợp Prompt chuẩn hóa]
Prompt -->|5. Local Inference| LLM[vLLM Server]
LLM -->|6. Streaming Text| User
LLM -.->|7. Async Background Task| DB[PgBouncer + PostgreSQL]
Nhìn vào sơ đồ này, có 3 quyết định thiết kế cốt lõi tạo nên sức mạnh của hệ thống:
Quyết định 1: Loại bỏ sự chờ đợi vô lý – Chặt đứt điểm nghẽn Database
Trong các tutorial thông thường, người ta hay thiết kế vòng đời (lifecycle) của một request theo kiểu tuyến tính:
Mở kết nối Database -> Tìm context -> Gọi LLM -> Đợi LLM sinh xong text -> Lưu lịch sử -> Đóng kết nối Database.
Trên môi trường production, đây là một thảm họa! LLM sinh text (streaming) có thể mất đến vài giây. Nếu dùng thiết kế cũ (như việc inject trực tiếp Depends(get_db) ở mức Controller trong FastAPI), kết nối Database sẽ bị “treo” chờ trong suốt thời gian đó. Với vài trăm request đồng thời, PostgreSQL với cấu hình max_connections = 100 mặc định sẽ sập ngay lập tức.
Cách tôi giải quyết: Biến lớp API (FastAPI) thành một chiếc “cửa cuốn” cực nhẹ. Tôi rút hoàn toàn phiên làm việc của Database ra khỏi luồng gọi LLM. Việc truy xuất lịch sử ngắn hạn (short-term window) được đẩy sang Redis để lấy tốc độ đọc mili-giây. Các tương tác với PostgreSQL chỉ được thực hiện thông qua PgBouncer (Connection Pooler) theo tiêu chí “Micro-transaction” – mở kết nối, đọc/ghi cực nhanh rồi đóng ngay lập tức. Sau khi LLM sinh xong toàn bộ câu trả lời và trả về cho user, một background task (tiến trình chìm) chạy bất đồng bộ mới lẳng lặng mở một connection siêu ngắn để lưu đoạn chat vào lịch sử. Luồng chính (Main flow) hoàn toàn không bị block.
Quyết định 2: Tính toán trước, truy vấn sau
Nhiều hệ thống RAG mắc sai lầm ở chỗ đẩy quá nhiều logic xử lý text, dọn dẹp dữ liệu (clean up) và phân tích vào lúc runtime (lúc người dùng đặt câu hỏi). Điều này làm Time-To-First-Token tăng không kiểm soát.
Chiến lược ở đây là đẩy mọi “việc nặng” về phía offline/asynchronous pipeline. Quá trình xử lý tài liệu, băm nhỏ (chunking), tạo embedding và lưu metadata được làm từ trước và nhét gọn gàng vào Qdrant. Lúc runtime, hệ thống chỉ làm một việc duy nhất: query vector để lấy đúng đoạn chunk cần thiết. Không nhồi nhét cross-encoder reranking quá nặng nếu không thực sự cần thiết (trừ luồng web search phải đối mặt với dữ liệu nhiễu). Điều này giúp giảm tải cực lớn cho CPU/RAM lúc query và trả về context gần như tức thì.
Quyết định 3: Ưu tiên Local LLM (vLLM)
Đây là quyết định mang tính sống còn để đạt được độ trễ cực thấp.
Nếu bạn gọi API của OpenAI hay Anthropic, dù mô hình có nhanh đến đâu, bạn vẫn phải chịu một khoản “thuế mạng” (Network Latency) do round-trip time (thời gian gói tin đi và về) qua internet, cộng thêm thời gian TLS handshake. Con số này có thể lên tới vài trăm mili-giây cho mỗi request.
Bằng việc tự host mô hình Open-source thông qua vLLM, inference engine nằm ngay cạnh (hoặc cùng mạng nội bộ) với Backend FastAPI. Network latency lúc này tiệm cận 0. Hơn thế nữa, vLLM tối ưu hóa PagedAttention và Continuous Batching cực tốt, giúp hệ thống không chỉ trả lời nhanh cho 1 người (Low Latency) mà còn duy trì được tốc độ đó khi có hàng trăm người hỏi cùng lúc (High Throughput).
Deep Dive: Tối ưu hóa từng “Nút thắt cổ chai”
Kiến trúc đẹp trên giấy là một chuyện, nhưng khi hệ thống phải hứng hàng trăm request đồng thời (high concurrency), mọi thứ sẽ sụp đổ nếu bạn không biết cách “thông tắc” các nút thắt cổ chai. Dưới đây là những kỹ thuật “dưới nắp capo” mà tôi đã áp dụng để giữ cho pipeline RAG này chạy ở tốc độ giới hạn của phần cứng.
Retrieval Phase: Tốc độ phải tính bằng mili-giây
Ở pha truy xuất, cơ sở dữ liệu vector (Vector Database) chính là trái tim. Khác với các truy vấn SQL thông thường, truy vấn Semantic Search đòi hỏi tính toán khoảng cách vector cực kỳ nặng nề.
Trong dự án này, tôi chọn Qdrant làm chốt chặn. Nhờ được viết bằng Rust, Qdrant quản lý bộ nhớ cực kỳ chặt chẽ và không bị vướng bận bởi Garbage Collection như các DB viết bằng Java hay Go. Để tối ưu tốc độ query, toàn bộ index được cấu hình theo thuật toán HNSW (Hierarchical Navigable Small World). Cấu trúc đồ thị đa tầng này cho phép hệ thống tìm kiếm xấp xỉ (ANN) hàng triệu vector tài liệu chỉ trong vài mili-giây, bỏ qua rủi ro làm chậm luồng trước khi kịp đưa ngữ cảnh vào cho LLM.
LLM Serving: Vắt kiệt sức mạnh phần cứng với vLLM
Nếu Retrieval tính bằng mili-giây, thì LLM Inference là nơi ngốn thời gian tính bằng giây. Để giải quyết bài toán serving, tôi bỏ qua các công cụ wrapper cơ bản và sử dụng trực tiếp vLLM.
Tối ưu bộ nhớ với PagedAttention (Chống tràn RAM): Nút thắt lớn nhất khi chạy mô hình ngôn ngữ lớn cục bộ (Local LLM) với context dài không phải là tham số mô hình, mà là KV Cache (bộ nhớ tạm lưu trữ trạng thái của các token đã xử lý). Càng nhiều request, context càng dài, KV Cache càng phình to và dẫn đến lỗi OOM (Out Of Memory). vLLM giải quyết triệt để chuyện này bằng PagedAttention – một cơ chế lấy cảm hứng từ bộ nhớ ảo (virtual memory) của hệ điều hành. Thay vì cấp phát một khối RAM liên tục khổng lồ, vLLM chia KV Cache thành các “block” nhỏ. Điều này giúp loại bỏ hoàn toàn sự phân mảnh bộ nhớ (memory fragmentation), cho phép hệ thống nhồi nhét ngữ cảnh cực dài mà vẫn an toàn nằm gọn trong bộ nhớ.
Tối ưu Prefill và Decode: Trận chiến của Băng thông (Bandwidth-bound) Trong quá trình sinh text của LLM, có 2 pha rõ rệt:
-
Prefill phase (xử lý prompt đầu vào): Rất nặng về tính toán (Compute-bound).
-
Decode phase (sinh từng token kết quả): Chủ yếu bị giới hạn bởi băng thông bộ nhớ (Memory-bandwidth bound).
Khi có nhiều request ập vào, nếu để vLLM xử lý ngây thơ, các request đang ở pha Decode sẽ bị “đói” tài nguyên và khựng lại khi có một request mới to đùnh bước vào pha Prefill. Để đẩy cao Throughput (số token/giây), tôi áp dụng kỹ thuật Chunked Prefill. Các prompt dài được băm nhỏ ra để xử lý xen kẽ, giúp các request đang sinh text (Decode) duy trì được luồng chảy liên tục, tận dụng tối đa băng thông bộ nhớ để đọc trọng số mô hình ra liên tục mà không bị gián đoạn.
Cơ bản lại thì tôi sẽ dùng vllm và setup mọi cờ tối ưu có thể bật sau cho cơm gạo nhất có thể đập tối đa vào tốc độ xử lý nếu nó không quá ảnh hưởng đến hiệu năng thực tế.
Định dạng mô hình (Quantization) và Container tối ưu: Để triển khai các mô hình open-source hàng đầu hiện nay (như Qwen, Gemma) lên môi trường production doanh nghiệp, việc sử dụng trọng số FP16 nguyên bản là một sự lãng phí băng thông không cần thiết, như trong dự án này tôi triển khai thẳng bằng qwen3.5 9b fp8 thì độ trể nó nhanh hơn cả gemma 4 4b BF 16 khoảng 20%.
Tại sau không phải các định dạng 4bit thì bạn nên cẩn thận khi triển khai một modle 4 bit lên vllm đấy, chưa tính đến việc hiệu năng tuột thảm hai do bản nén kém thì việc chạy 4 bit trên vllm sau cho tối ưu cũng không đơn giản.
Số liệu Benchmark thực tế
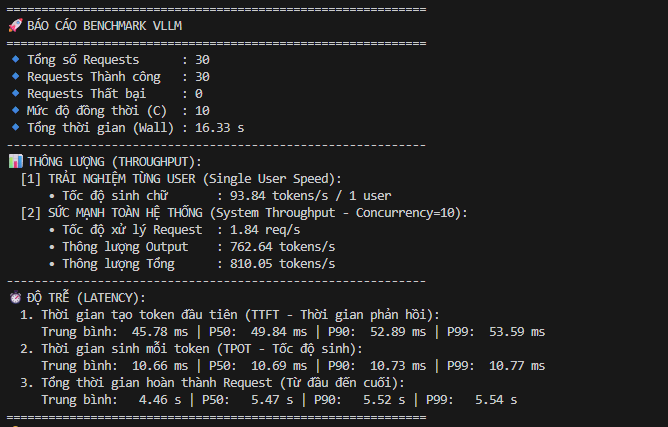
Sức mạnh lõi: Cỗ máy vLLM (The Engine) Hãy nhìn vào khả năng xử lý thô của riêng cụm Inference trước khi bị vướng vào các logic của RAG. Sức mạnh của nó thực sự đáng kinh ngạc:
-
Độ trễ chạm đáy (Latency): Thời gian sinh token đầu tiên (TTFT – Time-To-First-Token) trung bình chỉ vỏn vẹn 45.78 ms (P99 cũng chỉ ở mức 53.59 ms). Thời gian sinh mỗi token (TPOT) duy trì ở mức 10.66 ms.
-
Thông lượng khủng khiếp (Throughput): Ở góc nhìn một user duy nhất, tốc độ sinh chữ đạt 93.84 tokens/s – nhanh hơn tốc độ đọc của con
-
người rất nhiều. Khi đẩy tải lên 10 users cùng lúc, tổng thông lượng hệ thống đạt 810.05 tokens/s (1.84 req/s).
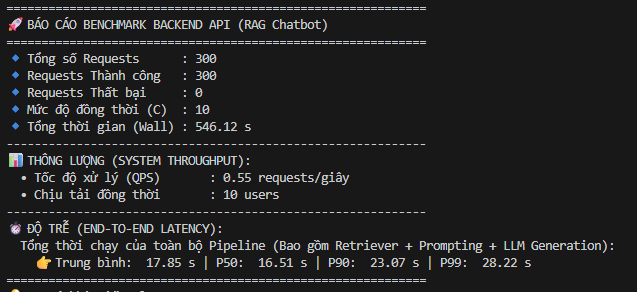
Độ trễ toàn trình: Pipeline RAG End-to-End (The Real World) Sức mạnh của LLM là một chuyện, nhưng khi ráp nối thành một luồng RAG hoàn chỉnh (bao gồm: Tiếp nhận -> Semantic Search qua Qdrant -> Tổng hợp Context -> Sinh Text -> Lưu History) thì câu chuyện sẽ thực tế và “phũ phàng” hơn.
Tôi đã bắn thử 300 requests liên tục (Concurrency 10) vào Backend API.
-
Độ ổn định: Tỷ lệ thành công là 300/300 (100%). Số request thất bại là 0. Nhờ việc tái cấu trúc lifecycle của Database (dùng PgBouncer và xử lý background task như đã đề cập ở phần trên), hệ thống hoàn toàn miễn nhiễm với các lỗi sập connection pool hay HTTP 50x.
-
Độ trễ thực tế: Tổng thời gian chạy trung bình của toàn bộ pipeline là 17.85 s. So với việc chỉ gọi raw LLM (Avg 4.46 s), toàn bộ overhead của pipeline RAG làm hệ thống chậm hơn khoảng 3.3x.
-
Sức chịu tải: Hệ thống duy trì tốc độ xử lý 0.55 requests/giây cho full luồng RAG hội thoại phức tạp.
Sự đánh đổi giữ tốc dộ và độ chính xác
Trong kỹ thuật hệ thống, không có viên đạn bạc (silver bullet). Để đạt được tốc độ phản hồi tính bằng mili-giây và khả năng chịu tải cao, tôi đã phải chấp nhận những sự đánh đổi có chủ đích. Một kỹ sư giỏi không phải là người giấu giếm điểm yếu, mà là người hiểu rõ giới hạn của hệ thống do chính mình tạo ra.
Những gì hệ thống này phải hy sinh:
-
Chiều sâu suy luận đa bước (Complex Reasoning): Bằng việc gạt bỏ các framework Agentic như AutoGen hay LangGraph với các vòng lặp self-reflection rườm rà, pipeline RAG này ưu tiên tốc độ hiển thị thông tin. Đổi lại, nếu người dùng đặt một câu hỏi mang tính chất “logic puzzle” đòi hỏi model phải tự tranh luận và đào xới qua 5-7 lớp dữ liệu, kiến trúc 1-pass này sẽ gặp khó khăn.
-
Chi phí vận hành và bảo trì (Ops Overhead): Dùng API của bên thứ ba thì nhàn, nhưng tự host một hệ thống RAG toàn diện (từ Vector DB, LLM Inference đến Connection Pooler) đòi hỏi kỹ năng DevOps cứng. Bạn phải tự lo liệu mọi thứ từ log rotation, giám sát tài nguyên, đến việc xử lý nghẽn mạng.
Bài học triển khai thực tế (Lessons Learned): Bản thân dự án này cũng đi lên từ những lần “sập server”. Có hai bài học lớn nhất mà tôi rút ra được:
-
Cái bẫy Database Lifecycle: Như đã đề cập, lỗi ngớ ngẩn nhất ban đầu là giữ kết nối PostgreSQL mở đồng bộ trong suốt quá trình LLM streaming. Hậu quả là chỉ với vài chục request, pool connection cạn kiệt và hệ thống ném thẳng lỗi HTTP 50x vào mặt user. Việc tách rời sinh mệnh của DB session ra khỏi luồng LLM và đẩy vào background task/PgBouncer là cứu cánh thực sự.
-
Đừng đùa với môi trường Container của GPU: Khi triển khai hệ thống những lần chạy thử nghiệm đầu tiên vLLM liên tục báo lỗi hệ thống và văng khỏi bộ nhớ. Kinh nghiệm xương máu là không dùng các image docker trôi nổi. Tôi bắt buộc phải chuyển sang sử dụng trực tiếp các vLLM containers của openai để tương thích sâu với CUDA. Đồng thời, model phải được ép về định dạng lượng tử hóa FP8 để tối ưu hóa việc phân bổ bộ nhớ dùng chung (Unified Memory) của dòng chip này. Tốc độ sau đó mới thực sự cất cánh.
Kết luận
Nhìn lại toàn bộ kiến trúc “Lean & Mean” này, giá trị cốt lõi lớn nhất không chỉ nằm ở những con số benchmark hào nhoáng. Giá trị thực sự là sự làm chủ hệ thống từ A đến Z.
Chúng ta làm chủ luồng dữ liệu, không rò rỉ bất kỳ một byte thông tin nội bộ hay hợp đồng nào ra ngoài internet. Chúng ta làm chủ tốc độ (latency), quyết định được Time-To-First-Token mà không phụ thuộc vào tình trạng cáp quang biển hay lệnh “cấm vận” API. Và quan trọng nhất, chúng ta đập tan nỗi sợ “vendor lock-in”, sẵn sàng scale hạ tầng hoặc thay thế bất kỳ model mã nguồn mở nào trong tương lai mà không phải viết lại toàn bộ logic backend.
Triết lý “Less is More” đã phát huy tác dụng ở giai đoạn này. Nhưng để hệ thống thực sự hoàn hảo cho mức độ Enterprise, đây là những dự định nâng cấp tiếp theo trong roadmap của tôi:
-
Semantic Caching ở lớp viền: Hiện tại Redis đang dùng để lưu short-term history. Tôi sẽ tích hợp thêm bộ đệm ngữ nghĩa (Semantic Cache) để nếu người dùng hỏi lại một câu tương tự, hệ thống sẽ trả thẳng kết quả từ Redis trong 5ms mà không cần đánh thức LLM hay Qdrant.
-
Citation Validator (Hậu kiểm trích dẫn): Dù model sinh câu trả lời dựa trên context, rủi ro ảo giác (hallucination) vẫn luôn tồn tại. Tôi đang xây dựng một node
synthesize/verifyđể parse toàn bộ các nhãn nguồn[Sx]trong output, đối chiếu ngược lại với evidence để đảm bảo độ tin cậy tuyệt đối cho các luồng Web Search. -
Cơ chế Circuit Breaker cho truy vấn ngoài: Đối với các luồng phải gọi SearxNG ra ngoài internet, một cơ chế ngắt mạch tự động kèm adaptive budget (tự điều chỉnh số lượng URL thu thập) sẽ được áp dụng để bảo vệ backend không bị treo khi có một nguồn web phản hồi quá chậm.
Xây dựng một hệ thống RAG không khó, nhưng làm cho nó chạy mượt mà, ổn định và “chịu đòn” tốt trên production lại là một nghệ thuật của sự tinh giản. Chúc các bạn kỹ sư tìm được điểm cân bằng hoàn hảo cho hệ thống của riêng mình!
Bài viết liên quan
- Hướng dẫn tạo LangChain Deep Agents Harness Profile cho NVIDIA Nemotron-3 Ultra để tối ưu hóa hiệu năng hệ thống Agent
- BioNeMo Agent Toolkit: Khi AI Agent bước vào phòng thí nghiệm số
- NVIDIA dẫn đầu hiệu suất Agentic Coding trên bài đo benchmark Agentic AI đầu tiên
- Khám phá Omniverse: 3 quy trình giúp cải thiện độ chính xác của Vision AI Agent với dữ liệu tổng hợp và fine-tuning
- Xây dựng chatbot AI nội bộ cho doanh nghiệp: Nhanh hơn, đúng ngữ cảnh hơn, kiểm soát tốt hơn
- NVIDIA Nemotron 3 Ultra tăng cường khả năng suy luận nhanh hơn, hiệu quả hơn cho các agent chạy trong thời gian dài