
Việc triển khai các ứng dụng AI trên nhiều phần cứng tiêu dùng khác nhau theo truyền thống đòi hỏi sự đánh đổi. Bạn có thể tối ưu hóa cho các cấu hình GPU cụ thể và đạt hiệu suất cao nhất với cái giá là tính di động. Hoặc, bạn có thể xây dựng các engine chung, có tính di động cao và chấp nhận hiệu suất thấp hơn. Thu hẹp khoảng cách này thường đòi hỏi việc tinh chỉnh thủ công, nhiều mục tiêu xây dựng khác nhau hoặc chấp nhận các sự thỏa hiệp.
NVIDIA TensorRT dành cho RTX hướng đến việc loại bỏ sự đánh đổi này. Với dung lượng dưới 200 MB, thư viện suy luận gọn nhẹ này cung cấp trình tối ưu hóa Just-In-Time (JIT) giúp biên dịch các engine trong vòng chưa đầy 30 giây. Điều này làm cho nó trở nên lý tưởng cho các ứng dụng AI phản hồi nhanh, thời gian thực trên các thiết bị dành cho người tiêu dùng.
TensorRT dành cho RTX giới thiệu công nghệ suy luận thích ứng (Adaptive Inference) — engine tự động tối ưu hóa trong thời gian chạy cho hệ thống cụ thể của bạn, dần dần cải thiện hiệu suất biên dịch và suy luận khi ứng dụng của bạn hoạt động. Không cần tinh chỉnh thủ công, không cần nhiều mục tiêu biên dịch, không cần can thiệp.
Xây dựng một engine nhẹ, có tính di động cao chỉ một lần, triển khai ở bất cứ đâu và để nó tự thích ứng với phần cứng của người dùng. Trong quá trình hoạt động, engine sẽ tự động biên dịch các kernel chuyên dụng dành riêng cho GPU, học hỏi từ các mẫu workload của bạn và cải thiện hiệu suất theo thời gian — tất cả mà không cần bất kỳ sự can thiệp nào của nhà phát triển. Để biết thêm chi tiết, hãy xem tài liệu NVIDIA TensorRT for RTX .
Adaptive Inference (suy luận thích ứng)
Với TensorRT cho RTX , hiệu năng trong quá trình chạy được cải thiện theo thời gian mà không cần can thiệp thủ công. Ba tính năng hoạt động song song để cho phép tự tối ưu hóa này: các kernel được chuyên biệt hóa theo chiều động (Dynamic Shapes) sẽ tinh chỉnh hiệu năng phù hợp với hình dạng workload của bạn, CUDA Graphs loại bỏ chi phí phát sinh khi thực thi các kernel đó, và cơ chế runtime caching giúp duy trì những cải tiến này giữa các phiên chạy. Kết quả: engine của bạn sẽ nhanh hơn khi hoạt động.
- Dynamic Shapes Kernel Specialization: Tự động biên dịch các kernel nhanh hơn cho những shape xuất hiện trong quá trình chạy và hoán đổi chúng một cách liền mạch, từ đó cải thiện hiệu năng bằng cách chuyên biệt hóa theo điều kiện workload.
- Built-in CUDA Graphs: Tự động thu thập, khởi tạo và thực thi các kernel dưới dạng một batch duy nhất, giảm chi phí khởi chạy kernel (kernel launch overhead) và tăng hiệu năng suy luận, đồng thời tích hợp với Dynamic Shapes.
- Runtime caching: Giảm overhead của quá trình JIT bằng cách lưu trữ các kernel đã được biên dịch giữa các phiên chạy, từ đó tránh biên dịch lặp lại và giảm chi phí thực thi.
Để xem bản demo trực tiếp cách các tính năng này phối hợp hoạt động trên một diffusion pipeline thực tế, với các mức cải thiện hiệu năng cụ thể, hãy xem video hướng dẫn về Tăng tốc suy luận thích ứng với TensorRT cho RTX .
So sánh giữa tối ưu hóa tĩnh và quy trình suy luận thích ứng
Các framework suy luận truyền thống yêu cầu nhà phát triển phải dự đoán trước kích thước đầu vào (input shape) và xây dựng các engine đã được tối ưu cho từng cấu hình phần cứng ngay từ thời điểm biên dịch. TensorRT cho RTX áp dụng một cách tiếp cận khác: các engine thích ứng với khối lượng công việc thực tế trong thời gian chạy. Bảng 1 so sánh hai quy trình làm việc này.
| Thành phần | Quy trình làm việc tĩnh | Suy luận thích ứng |
| Mục tiêu xây dựng | Nhiều engine cho mỗi GPU | Một engine duy nhất, có tính di động cao |
| Tính linh hoạt về các chiều | Được tối ưu hóa trong quá trình xây dựng cho các chiều dự đoán. | Được tối ưu hóa tự động trong quá trình chạy dựa trên các chiều thực tế đã quan sát |
| Lần chạy suy luận 1 | Hiệu suất tối ưu (nếu hình dạng được tinh chỉnh trước) | Hiệu suất gần tối ưu |
| Chạy suy luận N | Hiệu suất tương tự | Hiệu năng sẽ được cải thiện theo thời gian khi gặp phải các hình dạng mới (cộng với các chuyên môn hóa được lưu trong bộ nhớ cache). |
| Nỗ lực của nhà phát triển | Điều chỉnh thủ công cho từng cấu hình | Không can thiệp |
Suy luận thích ứng thu hẹp khoảng cách với quy trình làm việc tĩnh, mang lại hiệu suất tối ưu đồng thời loại bỏ sự phức tạp trong quá trình xây dựng và giảm bớt công sức của nhà phát triển.
So sánh hiệu năng: Thích ứng so với tĩnh
Để chứng minh hiệu năng của suy luận thích ứng, chúng tôi đã so sánh mô hình FLUX.1 [dev] với độ chính xác FP8 ở kích thước 512×512 và các hình dạng động trên card đồ họa RTX 5090 (Windows 11) sử dụng TensorRT cho RTX 1.3 so với trình tối ưu hóa tĩnh. Như thể hiện trong Hình 1, suy luận thích ứng vượt trội hơn so với tối ưu hóa tĩnh ở lần lặp thứ 2 và đạt tốc độ nhanh hơn 1,32 lần khi tất cả các tính năng được bật. Bộ nhớ đệm thời gian chạy cũng giúp tăng tốc quá trình biên dịch JIT từ 31,92 giây xuống còn 1,95 giây (gấp 16 lần), cho phép các phiên tiếp theo bắt đầu ngay lập tức với hiệu năng cao nhất.
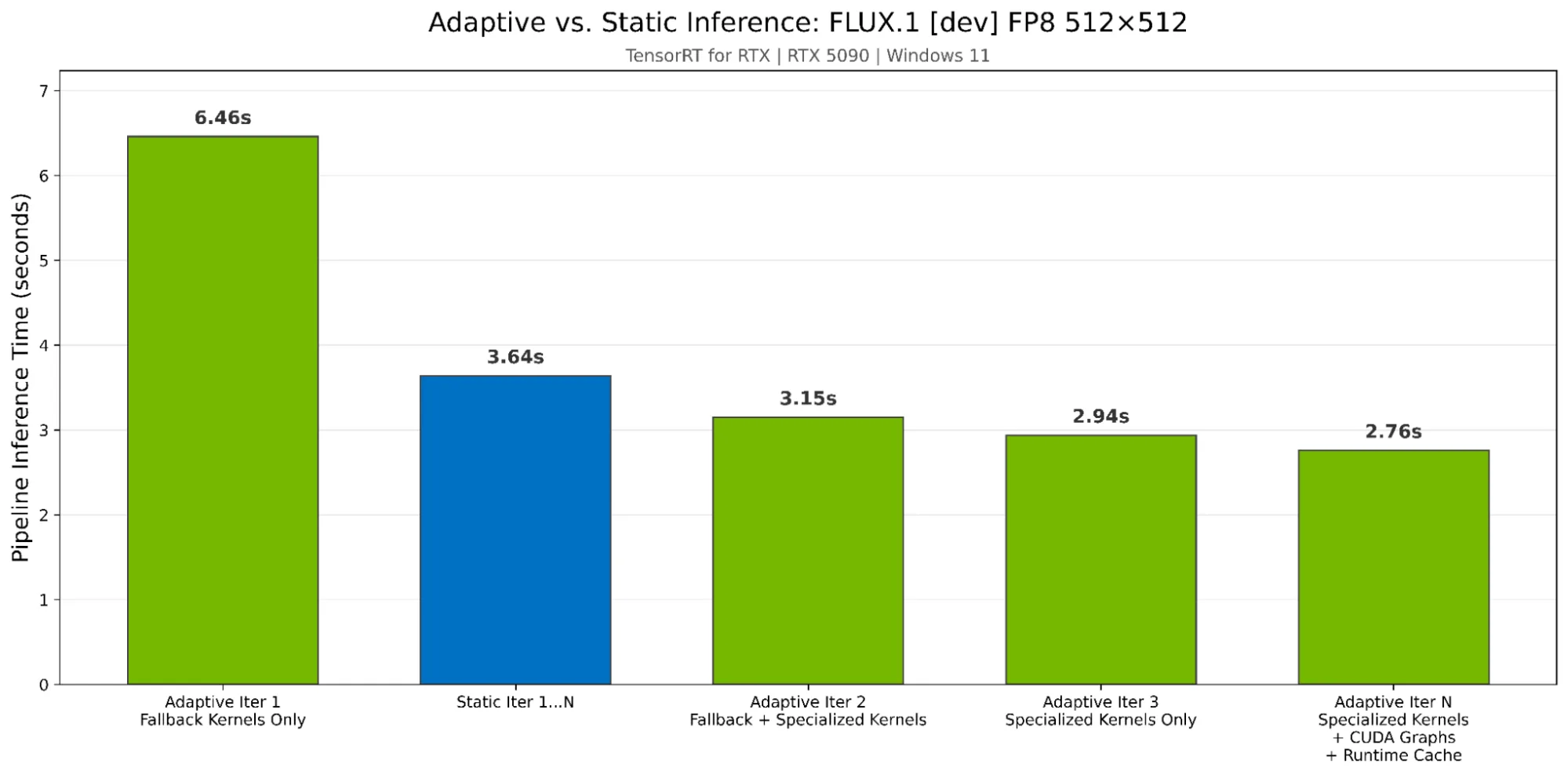
Ví dụ tạo động lực
Việc tạo ra một engine TensorRT từ mô hình ONNX là một ví dụ điển hình giúp người dùng dễ hình dung hơn:
import tensorrt_rtx as trt_rtxlogger = trt_rtx.Logger(trt.Logger.WARNING)builder = trt_rtx.Builder(logger)network = builder.create_network()parser = trt_rtx.OnnxParser(network, logger)with open("your_model.onnx", "rb") as f: parser.parse(f.read()) |
Chuyên môn hóa hạt nhân hình dạng động
Các mô hình thường có kích thước đầu vào khác nhau tùy thuộc vào độ phân giải hình ảnh, độ dài chuỗi thay đổi hoặc kích thước lô động. Chuyên môn hóa kernel hình dạng động (Dynamic Shapes Kernel Specialization) tự động tạo và lưu trữ các kernel được tối ưu hóa cho các hình dạng mà ứng dụng của bạn gặp phải trong quá trình chạy, được điều chỉnh cụ thể cho kích thước đầu vào của mô hình. Các kernel được tối ưu hóa này được lưu trữ và tái sử dụng, do đó các suy luận tiếp theo với cùng một hình dạng sẽ chạy ở hiệu suất cao nhất, giảm thiểu sự đánh đổi giữa tính linh hoạt và tốc độ.
Hình 1 trình bày tốc độ tăng hiệu suất suy luận với TensorRT cho Chuyên môn hóa Kernel Hình dạng Động RTX trên các loại mô hình trên NVIDIA GeForce RTX 5090 (Windows 11). Mỗi thanh biểu thị mức tăng hiệu suất trung bình khi các kernel chuyên biệt được tự động tạo và thay thế cho các hình dạng đầu vào gặp phải so với việc sử dụng các kernel “dự phòng” chung.
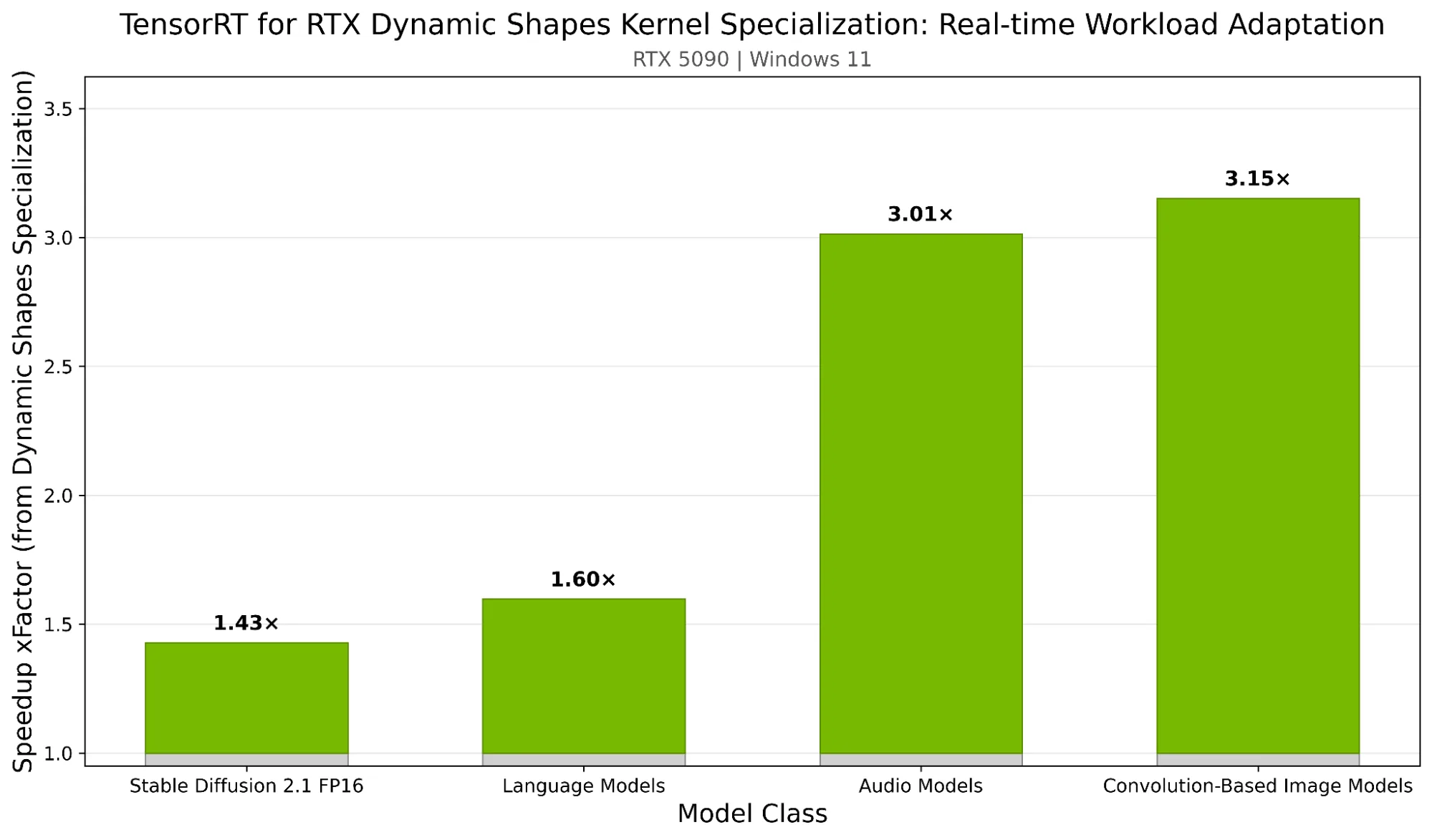
Lợi ích sẽ tăng theo mức độ đa dạng của khối lượng công việc. Các mô hình xử lý các hình dạng đầu vào đa dạng sẽ thấy hiệu suất ổn định trên mọi cấu hình, đồng thời duy trì tính linh hoạt để xử lý bất cứ điều gì tiếp theo. Tìm hiểu thêm về cách làm việc với các hình dạng động .
Tiếp tục với ví dụ ban đầu:
# Define optimization profile: min/opt/max shapes for dynamic dimensionsprofile = builder.create_optimization_profile()profile.set_shape("input", min=(1, 3, 224, 224), opt=(8, 3, 224, 224), max=(32, 3, 224, 224))config.add_optimization_profile(profile)# ... build engine ...# Configure dynamic shape kernel specialization strategy# The default is Lazy compilation, explicitly set below for illustrative purposes# Lazy compilation automatically swaps in kernels compiled in the background, adaptively improving perf for shapes encountered at runtimeruntime_config = engine.create_runtime_config()runtime_config.dynamic_shapes_kernel_specialization_strategy = ( trt_rtx.DynamicShapesKernelSpecializationStrategy.LAZY) |
Đồ thị CUDA tích hợp sẵn
Các mạng nơ-ron hiện đại có thể thực thi hàng trăm nhân GPU riêng lẻ cho mỗi lần suy luận. Mỗi lần khởi chạy nhân đều có chi phí phát sinh—thường là 5-15 micro giây xử lý của CPU và trình điều khiển. Đối với các mô hình chủ yếu sử dụng các phép toán nhỏ (phép tích chập nhỏ gọn, phép nhân ma trận nhỏ, các phép toán theo từng phần tử), thời gian khởi chạy này trở thành một nút thắt cổ chai.
Khi chi phí khởi chạy trên mỗi nhân chiếm ưu thế trong thời gian thực thi, GPU sẽ ở trạng thái nhàn rỗi trong khi CPU xếp hàng chờ xử lý công việc — thời gian xếp hàng chờ gần bằng hoặc vượt quá thời gian tính toán thực tế của GPU. Tình trạng này, được gọi là “bị giới hạn bởi thời gian xếp hàng chờ”, có thể được giải quyết bằng CUDA Graphs.
CUDA Graphs nắm bắt toàn bộ chuỗi suy luận dưới dạng cấu trúc đồ thị, loại bỏ chi phí khởi chạy kernel và tối ưu hóa các trường hợp sử dụng phổ biến, bao gồm cả các lệnh gọi mô hình lặp lại. TensorRT cho RTX khởi chạy toàn bộ đồ thị tính toán trong một thao tác duy nhất, thay vì khởi chạy từng kernel riêng lẻ.
Tính năng này có thể rút ngắn nhiều mili giây cho mỗi lần lặp suy luận, ví dụ như tăng tốc 1,8 ms (23%) cho mỗi lần chạy mô hình SD 2.1 UNet khi đo trên máy tính Windows với GPU RTX 5090. Tính năng này đặc biệt hữu ích trên các hệ thống Windows đã bật Lập lịch GPU tăng tốc phần cứng. Các mô hình có nhiều nhân nhỏ sẽ thấy được lợi ích lớn nhất, giúp tăng hiệu suất của các khối lượng công việc bị giới hạn bởi hàng đợi.
Hơn nữa, trong ngữ cảnh của các hình dạng động, tính năng hỗ trợ CUDA Graphs tích hợp chỉ nắm bắt và thực thi các nhân xử lý chuyên biệt cho từng hình dạng. Cách tiếp cận này đảm bảo rằng CUDA Graph tập trung vào việc tăng tốc các nhân xử lý hiệu quả nhất—thường là những nhân xử lý được sử dụng thường xuyên nhất. Tìm hiểu thêm về cách làm việc với CUDA Graphs tích hợp .
Hình 3 thể hiện tốc độ suy luận được cải thiện khi sử dụng TensorRT cho RTX với CUDA Graphs tích hợp sẵn trên GPU RTX 5090 (Windows 11, đã bật Lập lịch GPU tăng tốc phần cứng). Lưu ý rằng hiệu quả của CUDA Graphs rõ rệt hơn trên các mạng xử lý hình ảnh với nhiều kernel có thời gian chạy tương đối ngắn.
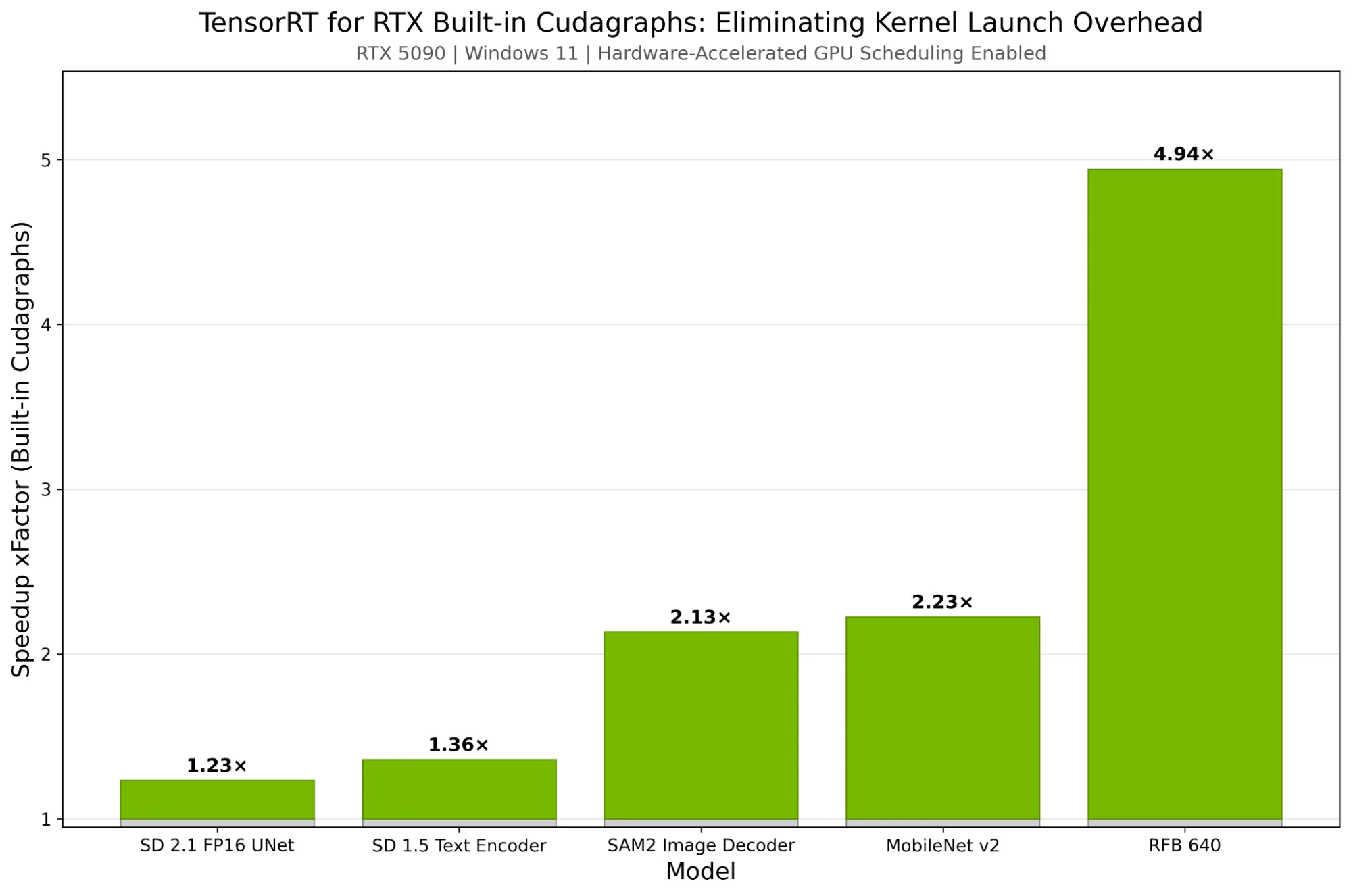
Bổ sung thêm vào ví dụ:
# Enable CUDA Graph capture for reduced kernel launch overheadruntime_config.cuda_graph_strategy = trt_rtx.CudaGraphStrategy.WHOLE_GRAPH_CAPTURE |
Bộ nhớ đệm thời gian chạy
Biên dịch JIT cung cấp tính di động và tối ưu hóa tự động dành riêng cho GPU trong TensorRT cho RTX. Bộ nhớ đệm thời gian chạy còn tiến xa hơn bằng cách bảo toàn các nhân đã biên dịch—bao gồm cả các nhân hình dạng động chuyên dụng đã đề cập trước đó—giữa các phiên làm việc, loại bỏ công việc biên dịch dư thừa.
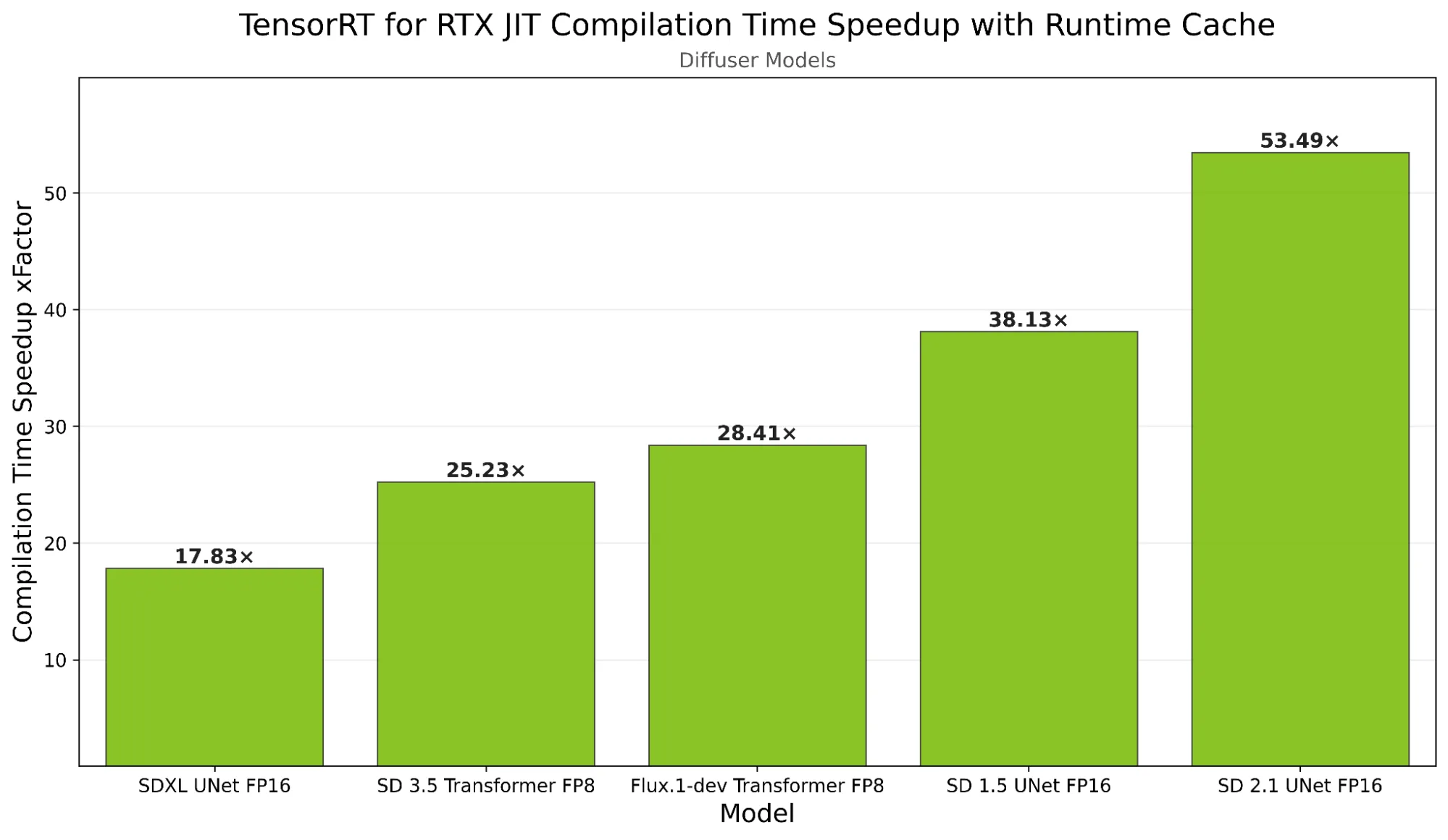
Để sử dụng bộ nhớ đệm thời gian chạy, hãy bắt đầu bằng cách chạy các suy luận ban đầu bằng cách sử dụng các triển khai được tối ưu hóa cho các hình dạng thường được sử dụng. Quá trình này tạo ra các nhân chuyên biệt được thiết kế riêng cho các hình dạng đó. Sử dụng API bộ nhớ đệm thời gian chạy, các nhân này sau đó có thể được tuần tự hóa thành một khối nhị phân, có thể được lưu vào đĩa để sử dụng lại trong tương lai.
Bằng cách tải khối dữ liệu nhị phân này trong các phiên tiếp theo, bạn đảm bảo rằng các nhân được tối ưu hóa nhất sẽ có sẵn ngay lập tức—loại bỏ nhu cầu về thời gian khởi động, tránh mọi sự suy giảm hiệu suất và ngăn chặn việc chuyển sang sử dụng các nhân chung chung. Điều này cho phép ứng dụng của bạn đạt được hiệu suất cao nhất ngay từ lần chạy suy luận đầu tiên.
Ngoài ra, tệp bộ nhớ đệm thời gian chạy có thể được đóng gói cùng với ứng dụng của bạn. Nếu bạn biết nền tảng cụ thể của người dùng mục tiêu—chẳng hạn như hệ điều hành, GPU, phiên bản CUDA và TensorRT—bạn có thể tạo trước bộ nhớ đệm thời gian chạy cho các môi trường đó. Sử dụng tệp bộ nhớ đệm thời gian chạy được cung cấp, người dùng có thể bỏ qua hoàn toàn mọi chi phí biên dịch kernel, cho phép hiệu suất tối ưu ngay từ lần chạy đầu tiên. Tìm hiểu thêm về cách làm việc với bộ nhớ đệm thời gian chạy .
Hoàn thành ví dụ:
from polygraphy import util# Create runtime cache to persist compiled kernels across runsruntime_cache = runtime_config.create_runtime_cache()# Load existing cache if availableruntime_cache_file = "runtime.cache"with util.LockFile(runtime_cache_file): try: loaded_cache_bytes = util.load_file(runtime_cache_file) if loaded_cache_bytes: runtime_cache.deserialize(loaded_cache_bytes) except: pass # No cache yet, will be populated during inferenceruntime_config.set_runtime_cache(runtime_cache)context = engine.create_execution_context(runtime_config)# ... run inference ...# Save cache for future runsruntime_cache = runtime_config.get_runtime_cache()with util.LockFile(runtime_cache_file): with runtime_cache.serialize() as buffer: util.save_file(buffer, runtime_cache_file, description="runtime cache") |
Hãy bắt đầu với suy luận thích ứng
Ba công nghệ phối hợp với nhau giúp đơn giản hóa quá trình tối ưu hóa suy luận thích ứng:
- Chuyên môn hóa nhân hình dạng động đảm bảo mỗi hình dạng hoạt động tối ưu.
- Đồ thị CUDA giúp loại bỏ chi phí phát sinh khi thực thi các nhân được tối ưu hóa đó.
- Việc lưu vào bộ nhớ đệm trong quá trình chạy giúp duy trì các tối ưu hóa đó xuyên suốt các phiên làm việc.
Các ứng dụng AI có thể thích ứng với mọi kích thước đầu vào trong khi vẫn duy trì các đặc tính hiệu suất của suy luận hình dạng tĩnh. Không có sự thỏa hiệp hay ràng buộc nhân tạo nào đối với thiết kế ứng dụng của bạn. Tìm hiểu thêm về các phương pháp hay nhất để đạt hiệu suất cao nhất khi sử dụng TensorRT cho RTX.
Để trải nghiệm khả năng suy luận thích ứng với NVIDIA TensorRT cho RTX , hãy truy cập kho lưu trữ GitHub NVIDIA/TensorRT-RTX và thử notebook FLUX.1 [dev] Pipeline Optimized with TensorRT RTX . Bạn cũng có thể xem video hướng dẫn Adaptive Inference Acceleration with TensorRT for RTX để xem minh họa trực tiếp về các tính năng này.
Bắt đầu xây dựng các ứng dụng AI cho PC NVIDIA RTX để chạy các mô hình nhanh hơn và riêng tư hơn trên thiết bị, đồng thời tối ưu hóa quá trình phát triển với các công cụ, SDK và mô hình của NVIDIA trên Windows.