
Lượng tử hóa mô hình (Model Quantization) là một phương pháp hiệu quả để giảm mức sử dụng VRAM và cải thiện hiệu năng suy luận trên các thiết bị tiêu dùng như GPU NVIDIA GeForce RTX. Bằng cách giảm yêu cầu về tính toán và bộ nhớ trong khi vẫn duy trì chất lượng mô hình, lượng tử hóa giúp các mô hình AI chạy hiệu quả hơn trong những môi trường bị hạn chế về tài nguyên.
Bài viết này hướng dẫn cách sử dụng NVIDIA Model Optimizer để lượng tử hóa một mô hình CLIP ở định dạng FP8 bằng phương pháp lượng tử hóa sau huấn luyện (post-training quantization, PTQ). Để có phần giới thiệu tổng quát về lượng tử hóa mô hình, hãy xem Model Quantization: Concepts, Methods, and Why It Matters.
NVIDIA Model Optimizer là gì?
Thư viện NVIDIA Model Optimizer (ModelOpt) tích hợp các kỹ thuật tối ưu hóa mô hình tiên tiến nhất để nén và tăng tốc các mô hình AI. Các kỹ thuật này bao gồm lượng tử hóa, chưng cất, cắt tỉa, giải mã suy đoán và thưa hóa. ModelOpt nhận đầu vào là các mô hình ở định dạng Hugging Face, PyTorch hoặc ONNX, đồng thời cung cấp các API Python để người dùng dễ dàng kết hợp các kỹ thuật tối ưu hóa khác nhau nhằm tạo ra các checkpoint đã được tối ưu hóa.
ModelOpt hỗ trợ các định dạng lượng tử hóa hiệu năng cao như FP4, FP8, INT8 và INT4, cùng các thuật toán nâng cao bao gồm SmoothQuant, AWQ, SVDQuant và Double Quantization. Công cụ này hỗ trợ cả PTQ và quantization-aware training (QAT).
CLIP là gì?
CLIP (Contrastive Language-Image Pretraining), được OpenAI giới thiệu vào năm 2021, là một foundation vision language model (VLM) học một không gian embedding chung cho hình ảnh và văn bản thông qua học tương phản trên các cặp hình ảnh-văn bản quy mô lớn. Khả năng tạo ra các biểu diễn được căn chỉnh về mặt ngữ nghĩa đã khiến CLIP trở thành một khối xây dựng cốt lõi trong các hệ thống đa phương thức hiện đại.
Bộ mã hóa văn bản CLIP được tái sử dụng rộng rãi như một mô-đun điều kiện hóa cho tổng hợp văn bản-sang-hình ảnh, chẳng hạn như Stable Diffusion, và văn bản-sang-video, chẳng hạn như AnimateDiff. Bộ mã hóa thị giác của nó đóng vai trò backbone trực quan trong các LLM đa phương thức, chẳng hạn như LLaVA, và các mô hình nhận thức từ vựng mở, chẳng hạn như OWL-ViT. Các phiên bản kế nhiệm như OpenCLIP và SigLIP mở rộng quy mô dữ liệu và tinh chỉnh mục tiêu, nhưng vẫn giữ nguyên mô thức tương phản bộ mã hóa kép.
Công thức lượng tử hóa
Công thức lượng tử hóa sau đây được sử dụng trong bài viết này như một hướng dẫn từng bước để chạy lượng tử hóa mô hình CLIP bằng ModelOpt, nhằm hiểu cách quy trình này hoạt động.
Trước tiên, hãy chuẩn bị các mô hình và tập dữ liệu tương ứng như dưới đây:
- Mô hình CLIP cơ sở: CLIP-ViT-L-14-laion2B-s32B-b82K
- Tập dữ liệu hiệu chuẩn cho lượng tử hóa: tập con 10K từ MS-COCO
- Các tác vụ đánh giá độ chính xác của mô hình tập trung vào ba tác vụ từ CLIP_benchmark:
- cifar100 (phân loại zero-shot),
- imagenet1k (phân loại zero-shot),
- mscoco_captions (truy xuất zero-shot)
Cách chạy PTQ với ModelOpt
Mẫu mã sau đây cho thấy cách chạy PTQ cho mô hình CLIP ở FP8 bằng ModelOpt:
import torch
from torch.utils.data import DataLoader, Subset
from transformers import CLIPModel, CLIPTokenizer, CLIPImageProcessor
from transformers.models.clip.modeling_clip import CLIPAttention
import modelopt.torch.opt as mto
import modelopt.torch.quantization as mtq
from modelopt.torch.quantization.plugins.diffusion.diffusers import _QuantAttention
# FP8 (E4M3) per-tensor static quantization
FP8_CFG = {
"quant_cfg": {
"*weight_quantizer": {"num_bits": (4, 3), "axis": None, "trt_high_precision_dtype": "Half"},
"*input_quantizer": {"num_bits": (4, 3), "axis": None, "trt_high_precision_dtype": "Half"},
"*[qkv]_bmm_quantizer": {"num_bits": (4, 3), "axis": None, "trt_high_precision_dtype": "Half"},
"*bmm2_output_quantizer": {"num_bits": (4, 3), "axis": None, "trt_high_precision_dtype": "Half"},
"default": {"enable": False},
},
"algorithm": "max",
}
mto.enable_huggingface_checkpointing()
mtq.QuantModuleRegistry.register({CLIPAttention: "CLIPAttention"})(_QuantAttention)
model = CLIPModel.from_pretrained(args.model_ckpt, attn_implementation="sdpa").half().eval().cuda()
tokenizer = CLIPTokenizer.from_pretrained(args.model_ckpt)
processor = CLIPImageProcessor.from_pretrained(args.model_ckpt)
calib_set = Subset(CLIP_COCO_dataset(ANN, IMG_DIR, tokenizer, processor), range(8192))
loader = DataLoader(calib_set, batch_size=512, num_workers=4)
# Calibration: 8k MS-COCO image-text pairs
def calibrate(m):
for img, txt in loader:
m.get_text_features(input_ids=txt.cuda())
m.get_image_features(pixel_values=img.cuda())
q_model = mtq.quantize(model, FP8_CFG, forward_loop=calibrate)
# Save quantized modelopt checkpoint
q_model.save_pretrained(ckpt_path)
mtq.print_quant_summary(q_model)FP8_CFG chỉ là một công thức: W8A8 (FP8 trên cả trọng số và activation), lượng tử hóa tĩnh theo từng tensor, được hiệu chuẩn bằng thuật toán AbsMax đơn giản. ModelOpt hỗ trợ nhiều chiều lựa chọn hơn nữa (độ hạt theo từng kênh / theo từng khối, lượng tử hóa activation động, các thuật toán hiệu chuẩn nâng cao như AWQ / GPTQ, và nhiều tùy chọn khác).
Để xem schema cấu hình chi tiết, hãy tham khảo ModelOpt quantization guide. Các siêu tham số trong cấu hình lượng tử hóa luôn có thể được tinh chỉnh khi cần, và việc tìm ra các giá trị tối ưu thường đòi hỏi một vài vòng lặp thử nghiệm.
Sau khi mtq.quantize trả về, tất cả các lớp Linear của CLIP đều mang các bộ lượng tử hóa trọng số và kích hoạt—nhưng các khối attention vẫn chưa được động đến. Điều này là do multi-head attention được chuyển tiếp đến torch.nn.functional.scaled_dot_product_attention, một functional API mà trình duyệt module của ModelOpt không thể tự chặn được.
Để đưa attention vào phạm vi lượng tử hóa, hãy đăng ký một phần thay thế đã lượng tử hóa cho CLIPAttention:
mtq.QuantModuleRegistry.register({CLIPAttention:
"CLIPAttention"})(_QuantAttention)Mỗi instance CLIPAttention giờ đây được nâng cấp thành _QuantAttention từ plugin ModelOpt diffusers. Bên trong forward pass của nó, _QuantAttention chặn một cách minh bạch lệnh gọi SDPA và chèn bốn quantizer xung quanh kernel đã hợp nhất:
- q_bmm_quantizer, k_bmm_quantizer, v_bmm_quantizer bọc các tensor Q / K / V đã được chiếu trước khi chúng đi vào kernel
- bmm2_output_quantizer bọc đầu ra của kernel (softmax @ V) trước khi nó đi vào out_proj
Điều này đảm bảo lượng tử hóa đúng cách trong toàn bộ cơ chế attention.
Để khôi phục một phần độ chính xác, thường nên vô hiệu hóa một số quantizer bằng mtq.disable_quantizer. Hàm này nhận một hàm làm đầu vào, trong đó chính hàm đó nhận tên module làm đầu vào. Bằng cách dùng regex hoặc khớp chuỗi, bạn có thể chọn các layer cần vô hiệu hóa. Trong ví dụ sau, các quantizer được vô hiệu hóa trong layer patch_embedding của mô hình CLIP.
import re
def filter_func(name):
pattern = re.compile(
r".*(patch_embedding).*"
)
return pattern.match(name) is not None
mtq.disable_quantizer(q_model, filter)Đánh giá benchmark CLIP
Checkpoint ModelOpt đã lưu có thể được khôi phục vào bất kỳ script đánh giá hạ nguồn nào. Để biết chi tiết, hãy tham khảo Restoring ModelOpt Models. Checkpoint CLIP đã lượng tử hóa được đánh giá trên ba benchmark: phân loại zero-shot (CIFAR-100, ImageNet-1k) và truy xuất zero-shot (MS-COCO Captions). Mô hình CLIP FP16 đóng vai trò làm baseline.
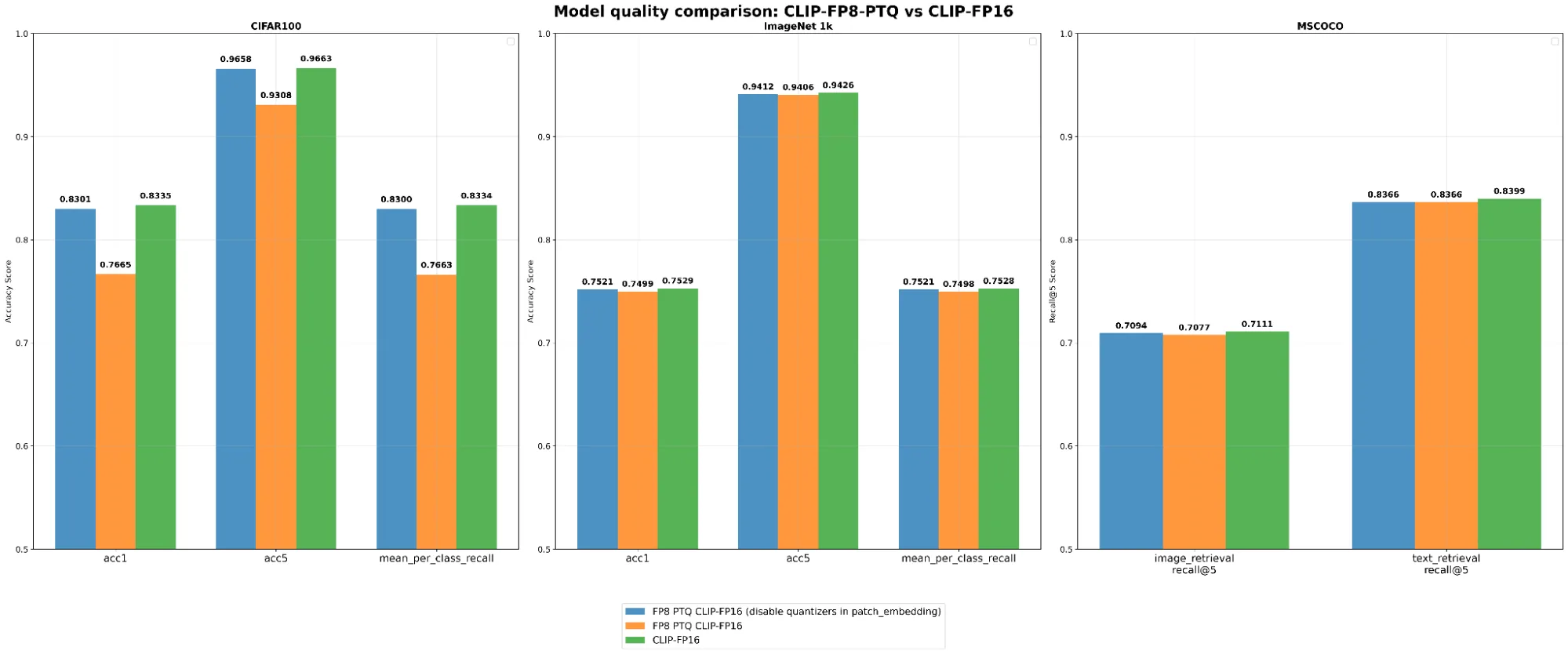
Hình 1. So sánh chất lượng mô hình CLIP giữa baseline FP16 và các mô hình được lượng tử hóa FP8-PTQ
Dựa trên kết quả đánh giá, mô hình CLIP-FP8 đã lượng tử hóa cho thấy chất lượng tương đương với mô hình CLIP-FP16. Đáng chú ý, khi các quantizer bị vô hiệu hóa trong lớp patch embedding, tác động của lượng tử hóa đối với chất lượng mô hình trở nên không đáng kể.
Bên trong luồng PTQ của ModelOpt
Điều quan trọng cần hiểu là giai đoạn này liên quan đến việc làm việc với “fake quantization” vì kiểu dữ liệu thực tế của mô hình chưa thay đổi. Thay vào đó, các quantizer được chèn vào này đóng vai trò như những observer, mô phỏng tác động của lượng tử hóa trong khi vẫn giữ mô hình ở định dạng dấu phẩy động ban đầu.
Quy trình fake quantization hoạt động theo hai cách chính:
- Thu thập thống kê: Các quantizer thu thập thống kê tensor (ví dụ: giá trị nhỏ nhất và lớn nhất) khi dữ liệu đi qua chúng. Các thống kê này được dùng để tính toán các tham số lượng tử hóa tối ưu, chẳng hạn như hệ số tỷ lệ.
- Mô phỏng lượng tử hóa: Các quantizer thực hiện thao tác quantize-then-dequantize (QDQ) trên các tensor đi qua mạng. Thao tác này chỉ mô phỏng phép tính độ chính xác thấp; mức tăng tốc thực tế và tiết kiệm bộ nhớ nên đạt được bằng cách xuất mô hình sang các framework triển khai như NVIDIA TensorRT.
Việc mô phỏng này rất quan trọng vì nó cho phép bạn đánh giá độ chính xác của mô hình trước khi cam kết lượng tử hóa thực sự. Các quantizer áp dụng cùng các giới hạn về làm tròn và độ chính xác như sẽ xảy ra trong mô hình đã lượng tử hóa khi triển khai với các framework suy luận downstream, vì vậy bạn có thể:
- Đo lường tác động đến độ chính xác trước khi triển khai
- Thử nghiệm với các cấu hình lượng tử hóa khác nhau
- Xác định các lớp có vấn đề có thể cần xử lý đặc biệt
Nhìn chung, quy trình PTQ của ModelOpt gồm sáu giai đoạn:
- Chuẩn bị: Thiết lập cấu hình lượng tử hóa để chèn các mô-đun quantizer quanh trọng số và/hoặc activation của mô hình.
- Hiệu chuẩn: Chạy forward một batch nhỏ dữ liệu đại diện qua mô hình để mỗi quantizer có thể thu thập thống kê (ví dụ: activation amax) và suy ra hệ số tỷ lệ của nó.
- Lượng tử hóa giả: Các quantizer lúc này áp dụng một vòng khứ hồi Q → DQ ở dạng dấu phẩy động, mô phỏng trung thực mức suy giảm độ chính xác của định dạng mục tiêu trong khi mô hình vẫn chạy ở FP16/BF16.
- Đánh giá: Đo độ chính xác trên một tập đánh giá được giữ riêng và so sánh với baseline chưa lượng tử hóa.
- Lặp lại: Nếu khoảng chênh lệch không chấp nhận được, hãy điều chỉnh cấu hình lượng tử hóa (độ hạt, thuật toán, các lớp được lượng tử hóa), tắt lượng tử hóa đối với các lớp nhạy cảm và hiệu chuẩn lại.
- Xuất và triển khai: Khi độ chính xác đã chấp nhận được, các trọng số được lượng tử hóa giả sẽ được nén về dạng độ chính xác thấp thực sự và được xuất dưới dạng checkpoint cho các engine hạ nguồn. Trong trường hợp của chúng tôi, chúng tôi xuất checkpoint PyTorch sang ONNX và chạy suy luận bằng TensorRT. Việc tăng tốc và tiết kiệm bộ nhớ sẽ diễn ra ở đó.

Hình 2. Quy trình PTQ của ModelOpt
QAT khôi phục phần suy giảm chất lượng do lượng tử hóa gây ra bằng cách tinh chỉnh trọng số mô hình với các trạng thái quantizer được đóng băng. Phương pháp này đòi hỏi nhiều tài nguyên tính toán hơn PTQ nhưng có thể cải thiện chất lượng mô hình đã lượng tử hóa tốt hơn. Để biết thêm chi tiết, hãy xem các ví dụ ModelOpt.
Bắt đầu với NVIDIA Model Optimizer
Bài viết này đã giới thiệu NVIDIA Model Optimizer và minh họa một quy trình lượng tử hóa sau huấn luyện điển hình bằng cách lượng tử hóa mô hình CLIP sang FP8 với một ví dụ mã thực tế. Kết quả trên ba tập dữ liệu đánh giá cho thấy lượng tử hóa FP8 có thể duy trì chất lượng mô hình đồng thời mở ra một hướng triển khai hiệu quả hơn.
Bạn đã sẵn sàng bắt đầu sử dụng ModelOpt với các mô hình của riêng mình chưa? Hãy làm theo quy trình này: chuẩn bị mô hình và dữ liệu hiệu chuẩn, thiết lập cấu hình lượng tử hóa, hiệu chuẩn, xác thực mô hình đã lượng tử hóa theo các chỉ số chất lượng dành riêng cho tác vụ, lưu và khôi phục checkpoint của ModelOpt.
Để khám phá thêm các workflow bổ sung và điều chỉnh ModelOpt cho các trường hợp sử dụng của riêng bạn, hãy xem tài liệu ModelOpt.
Bài viết liên quan
- Cách đánh giá các chính sách Robot đa năng cho triển khai thực tế
- Xác suất xảy ra các sự kiện cực đoan với các mô hình tạo sinh được hướng dẫn
- Triển khai NVIDIA Cosmos 3 sau huấn luyện trong một ngày bằng Kỹ năng Agent
- NVIDIA Ising Decoding giảm tỷ lệ lỗi Logic mã màu hơn 300 lần
- Xây dựng Ứng dụng Theo dõi 3D Đa Camera với Kỹ năng NVIDIA DeepStream 9.1
- Nâng cao hiệu suất trong huấn luyện LLM quy mô lớn bằng cách sử dụng song song tensor không đồng nhất