
Sự xuất hiện của điện toán suy luận cho Agentic AI (Agentic inference) đã làm thay đổi hoàn toàn động lực học thời gian thực (runtime dynamics) của các workload suy luận hiện đại. Nó đưa vào hệ thống các quỹ đạo phi định quyết (non-deterministic trajectories) — bao gồm hàng loạt hành động, quan sát, gọi công cụ (tool calls), và các quyết định mà một AI agent sinh ra trong quá trình tự xử lý tác vụ. Dưới góc độ hạ tầng, những quỹ đạo rẽ nhánh này liên tục cộng dồn độ trễ end-to-end (end-to-end latency) xuyên suốt hàng trăm yêu cầu suy luận ngẫu nhiên trong một phiên làm việc duy nhất.
Hiện tại, NVIDIA Vera Rubin NVL72 đang đảm nhận phần lớn tải suy luận đó như một engine tính toán cốt lõi của nền tảng NVIDIA Vera Rubin. Tuy nhiên, các workload đa đặc vụ (multi-agent) thế hệ mới khắt khe nhất hiện nay đang đòi hỏi khả năng sinh (generation) văn bản phải đáp ứng được đồng thời hai yếu tố: độ trễ cực thấp (low-latency) và thông lượng cao (high-throughput) trên các cụm mô hình dạng Mixture-of-Experts (MoE) quy mô nghìn tỷ tham số với cửa sổ ngữ cảnh (context windows) siêu lớn.
Cho đến nay, chưa có bất kỳ nền tảng nào phục vụ được tập workload mới này với mức hiệu quả kinh tế đủ tốt. Sự xuất hiện của bộ xử lý NVIDIA Groq 3 LPX, khi được ghép nối chặt chẽ với Vera Rubin NVL72, chính là giải pháp đầu tiên phá vỡ rào cản này, mang lại cả thông lượng cao và độ trễ thấp tại điểm tối ưu trên đường cong Pareto.
Bài viết này sẽ đi sâu vào cách nền tảng NVIDIA Vera Rubin giải quyết thách thức trên thông qua phương pháp “extreme co-design” (đồng thiết kế phần cứng ở mức độ cực độ), kết hợp sức mạnh tính toán thông lượng cao với khả năng thực thi định quyết (deterministic execution) có độ trễ cực thấp trên hàng trăm đến hàng nghìn con chip.
Tại sao các workload Agentic lại đòi hỏi mạng Scale-Up có tính dự đoán?
Các kiến trúc mạng kết nối trung tâm dữ liệu (networking fabrics) truyền thống vốn được tối ưu hóa cho các tác vụ huấn luyện (training) quy mô lớn và các workload suy luận khối lượng lớn (volume inference). Ở đó, những biến động nhỏ về độ trễ mạng (network jitter) thường được khấu hao và làm phẳng bên trong các batch tính toán lớn.
Ad
Ngược lại, ở các dịch vụ AI cao cấp (Premium AI services) với khả năng hiển thị thời gian thực cho người dùng, suy luận giải mã của Agentic (agentic decode) mang đến một tập hợp các yêu cầu hoàn toàn khác biệt ở mức hạ tầng:
-
Các yêu cầu mô hình nhiều lượt (Multi-turn model requests) liên tục được gọi.
-
Kích thước Batch nhỏ hơn (Smaller batches), khiến hệ thống không thể tận dụng hết hiệu suất tính toán thô nếu thiết kế theo hướng throughput-bound.
-
Yêu cầu độ trễ cực thấp (Extremely low latency).
Ngoài ra, ngữ cảnh dài và các mô hình MoE kích thước lớn (thường dùng trong các dịch vụ AI Tier 1) còn đưa vào các thách thức mạng (networking challenges) đáng gờm khác.
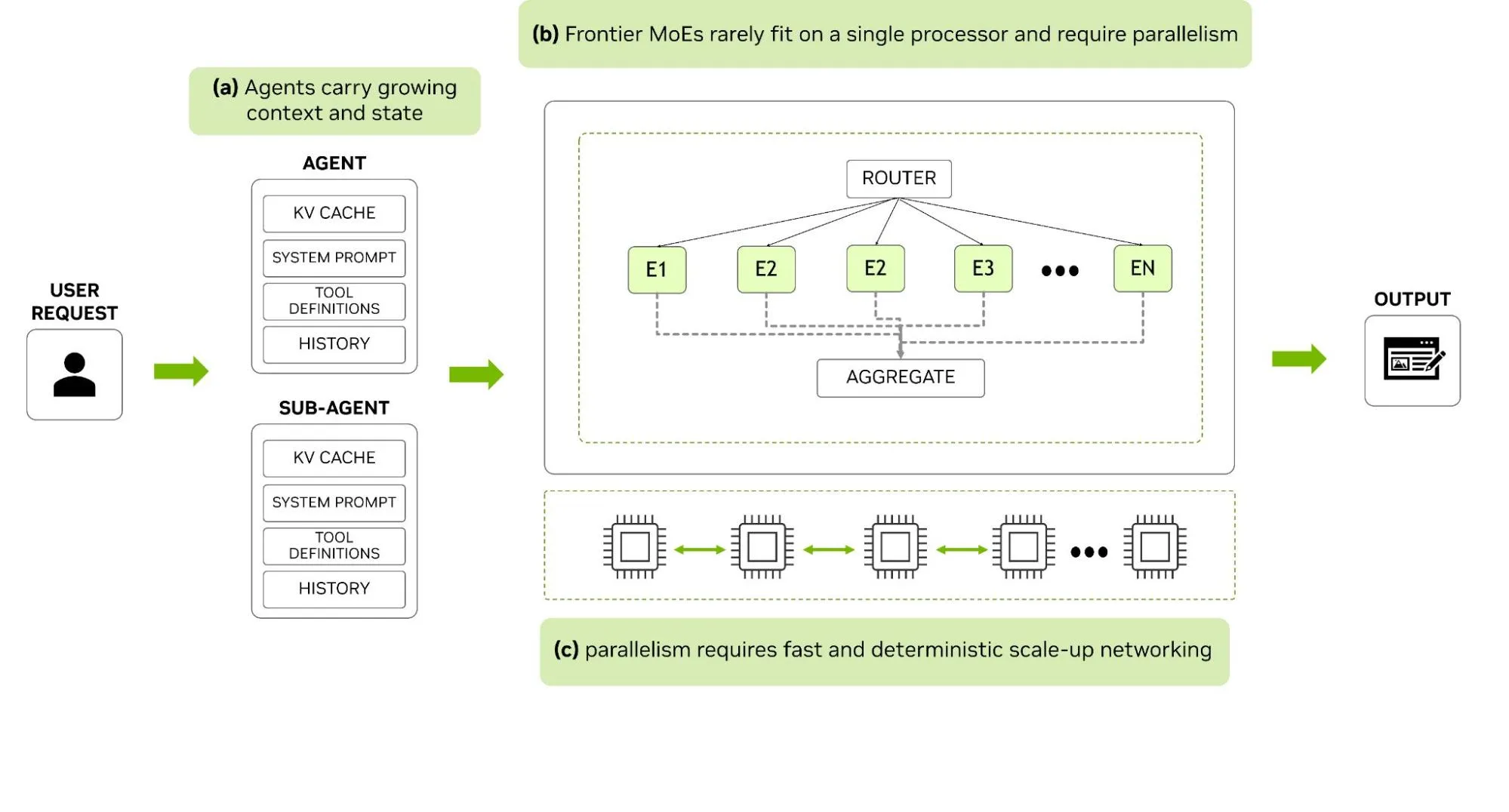
(Hình 1: Sơ đồ khái niệm minh họa cách các workload agentic gia tăng ngữ cảnh và trạng thái liên tục. Các mô hình MoE tiên tiến yêu cầu kỹ thuật xử lý song song, khiến chúng phụ thuộc nghiêm ngặt vào các kết nối liên vi xử lý nhanh và có tính định quyết).
Hãy hình dung: Mỗi agent trong một pipeline multi-agent đều mang theo một không gian trạng thái phình to liên tục gồm KV cache (bộ nhớ đệm Key-Value), system prompt, định nghĩa công cụ (tool definitions), và lịch sử hội thoại. Bản thân KV cache đó cùng các token mới sinh ra phải được định tuyến (routed) luân chuyển qua các mô hình nghìn tỷ tham số và trỏ tới đúng “các chuyên gia” (experts) nằm rải rác trên nhiều bộ tăng tốc (accelerators) khác nhau.
Quá trình giao tiếp liên chip (cross-chip exchange) này là không thể tránh khỏi đối với bất kỳ kiến trúc nào sử dụng SRAM mà không đủ không gian chứa toàn bộ mô hình trên một die duy nhất. Khi đó, cơ chế vật lý chịu trách nhiệm truyền tải dữ liệu sẽ lập tức trở thành “nút thắt cổ chai” (bottleneck) lớn nhất của hệ thống phục vụ (serving system).
Để xử lý thách thức này, ngành công nghiệp từ trước đến nay thường dùng 2 cách:
-
Dùng các cấu trúc mạng phân xử tại runtime (runtime-arbitrated networking fabrics) nơi việc kiểm soát luồng chỉ mang tính phản ứng (reactive), thời gian chờ chỉ giới hạn về mặt thống kê chứ không thể cam kết (guaranteed).
-
Tích hợp lượng lớn compute và bộ nhớ lên một die duy nhất để trì hoãn việc phải đối mặt với bài toán mở rộng (scale-up). Nhưng khi kích thước mô hình vỡ mốc giới hạn phần cứng, hiệu năng đa chip (multi-chip performance) sẽ suy giảm trầm trọng.
Để phá vỡ sự đánh đổi giữa thông lượng và độ trễ (throughput-latency tradeoff) ở kỷ nguyên Agentic, chúng ta buộc phải thiết kế một kiến trúc networking fabric đồng bộ hoàn toàn với silicon, trình biên dịch (compiler), và serving stack. Giao thức LPU C2C đạt được điều này qua extreme co-design.
Cách NVIDIA Groq 3 LPX giải quyết thách thức Scale-Up
Công nghệ kết nối LPU C2C (Chip-to-Chip) của NVIDIA Groq 3 LPX được thiết kế trực diện để giải quyết các vấn đề liên quan đến việc mở rộng quy mô. Thay vì coi các kết nối vật lý như một mạng lưới thông thường phải tự gồng gánh tắc nghẽn và độ trễ không chắc chắn trong runtime, LPU C2C mở rộng mô hình thực thi định quyết (deterministic execution model) của Groq trên nhiều LPU.
Hệ thống đạt được độ trễ bằng 0 ở mức overhead bằng cách ứng dụng 3 công nghệ liên kết cực kỳ chặt chẽ:
1. Liên kết điểm-điểm có High-Radix (High-radix point-to-point links) Mỗi LPU hỗ trợ tới 96 liên kết C2C hoạt động ở tốc độ 112 Gbps, cung cấp lượng băng thông scale-up khoảng 2.5 TB/s mỗi LPU và lên tới 640 TB/s ở cấp độ tủ mạng (rack-level). Được xây dựng dựa trên kiến trúc rack-scale NVIDIA MGX, thiết kế này sử dụng các khay compute không cáp (cableless trays) và cấu trúc liên kết mạng high-radix theo topology điểm-điểm để ghép nối chặt chẽ sức mạnh tính toán và giao tiếp giữa các khay và rack.
Các kết nối ngang hàng trực tiếp (direct peer connections), định tuyến đối xứng khi chịu tải, và số lượng hop vật lý cực thấp giúp tối đa hóa khả năng giao tiếp tập hợp (collective communication), trong khi Trình biên dịch (Compiler) sẽ lên trước kế hoạch tĩnh cho toàn bộ luồng truyền tải thay vì phải đoán định tại runtime.
2. Luồng dữ liệu được định thời bằng Trình biên dịch LPU (Compiler-scheduled data movement) Khả năng mở rộng của LPU C2C hoàn toàn là software-scheduled. Giao tiếp giữa các LPU di chuyển theo các vector 320-byte, đây cũng là đơn vị kích thước tiêu chuẩn cho xử lý tính toán. Luồng giao tiếp được kiểm soát và định thời (scheduled) ngay tại thời điểm biên dịch (compile time) như một đơn vị chức năng “hạng nhất”, đặt ngang hàng với các module xử lý ma trận và vector. Trình biên dịch vạch sẵn kế hoạch từ khi vector rời LPU gốc, đi qua link nào, và khi nào tới đích. Việc cân bằng tải (load balancing) hay đồng bộ hóa đều giải quyết bằng cấp độ tĩnh (statically) thay vì nhường cho phần cứng xử lý lúc tắc nghẽn. Nhờ vậy, hàng nghìn LPU interconnected được hệ thống hiểu là một khối nguyên khối (single execution surface) duy nhất.
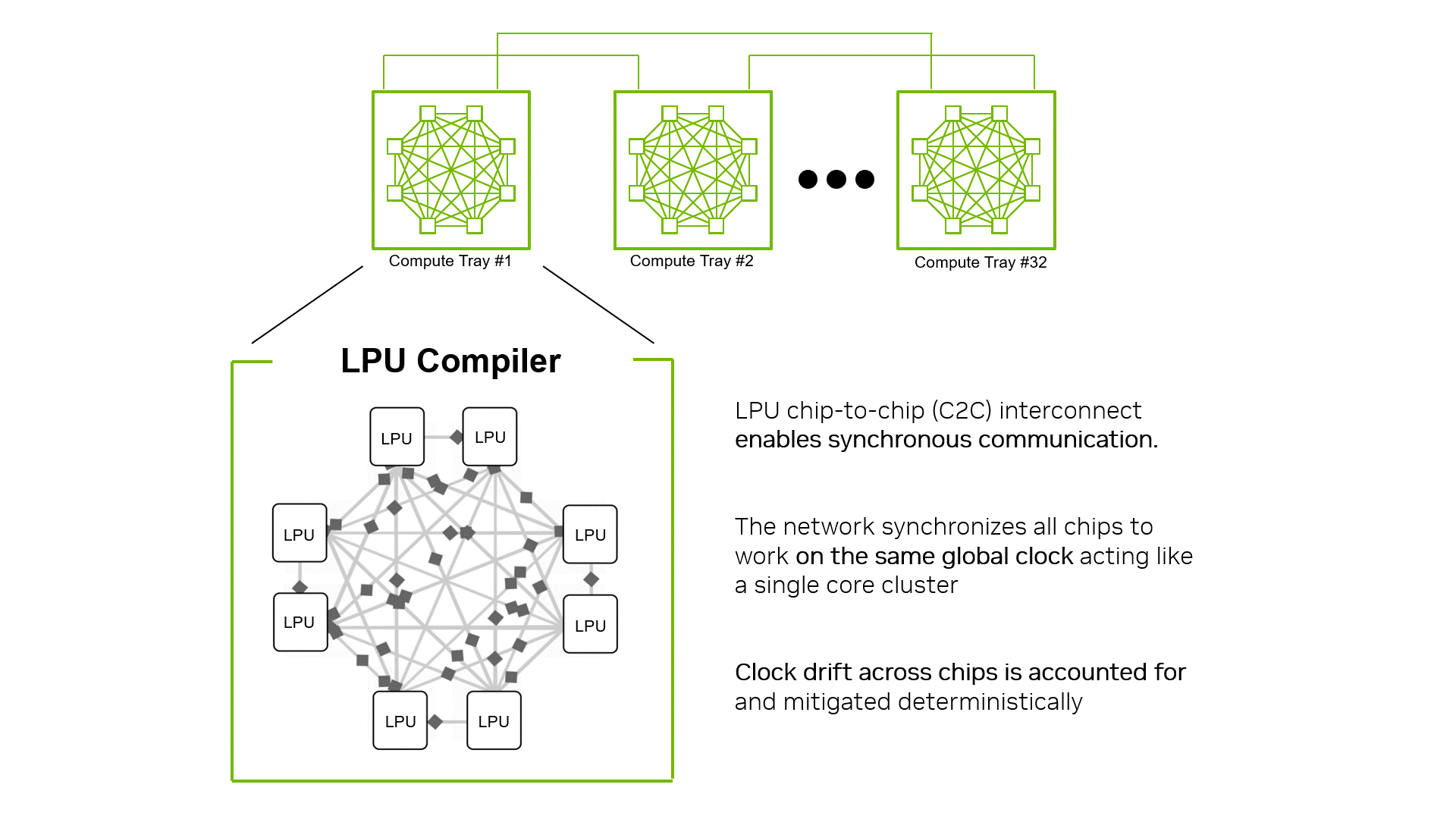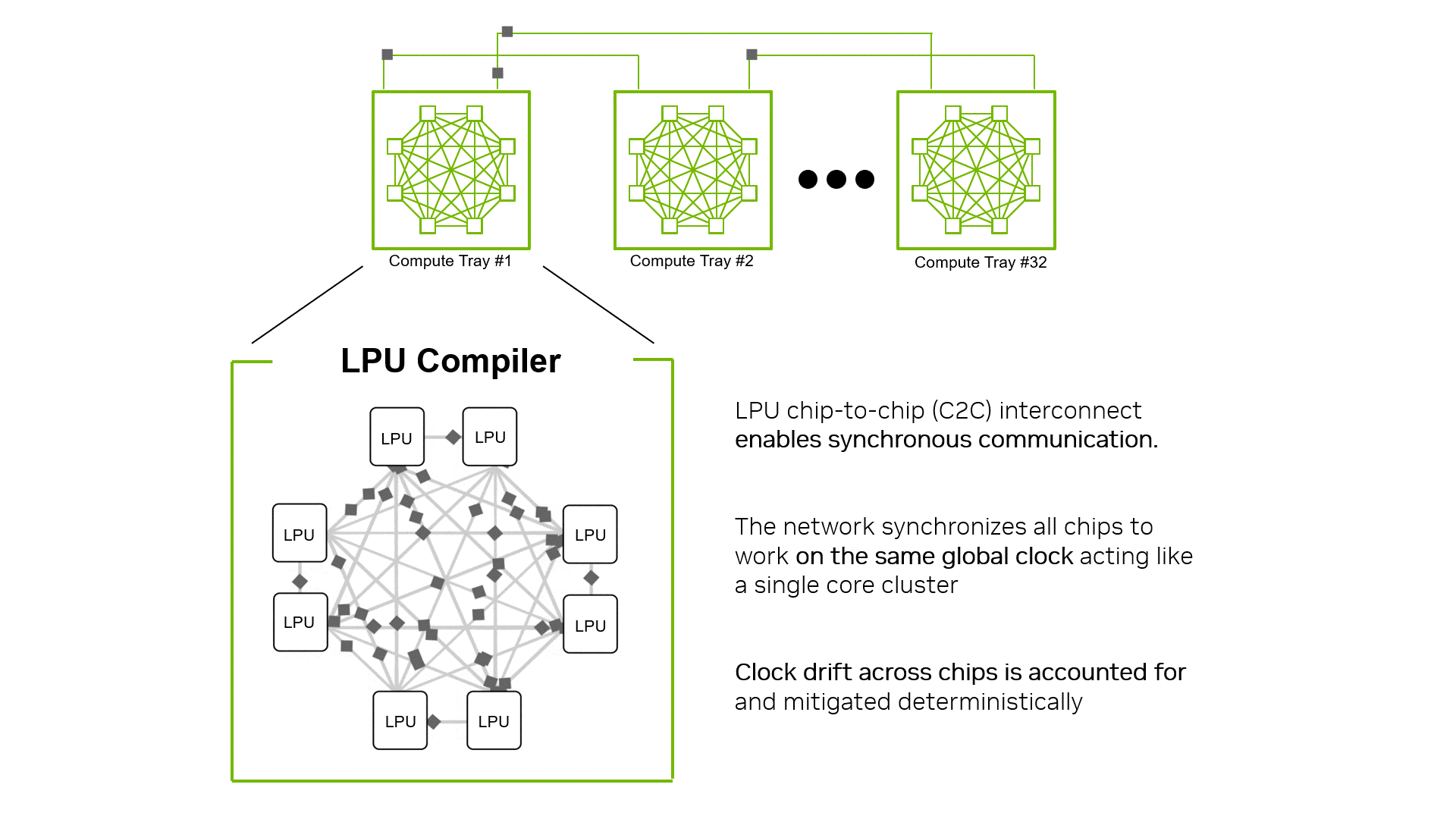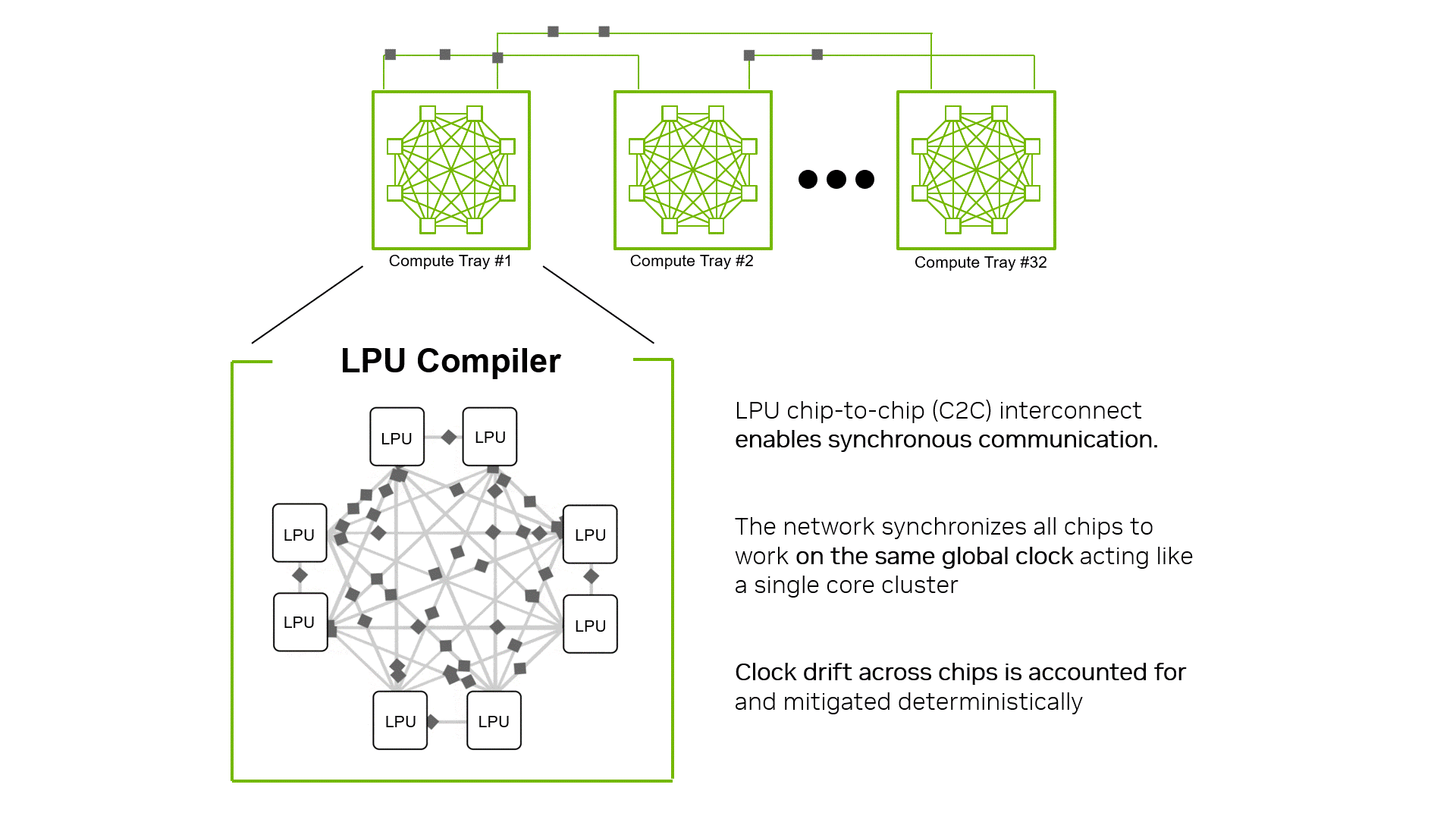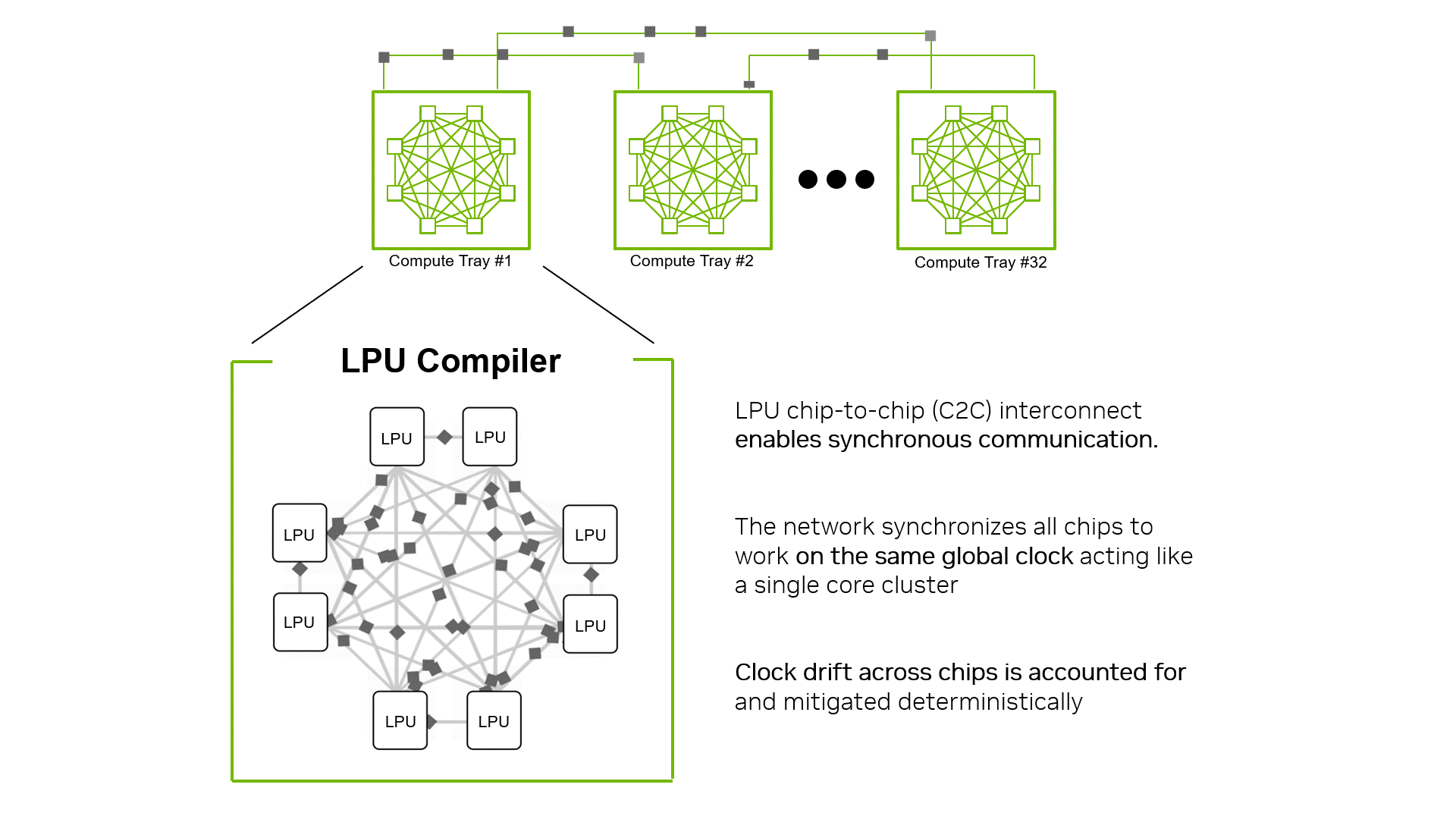
(Hình 2: Trình biên dịch LPU coi toàn bộ các chip liên kết với nhau thông qua mạng C2C đồng bộ hóa như một cụm thực thi định quyết duy nhất).
3. Đồng bộ thời gian Plesiosynchronous điều khiển bằng phần cứng Mỗi LPU có một đồng hồ (clock) riêng, và vì các đồng hồ luôn có hiện tượng trôi (clock drift), LPU C2C scale-up sử dụng giao thức plesiosynchronous (cận đồng bộ) để triệt tiêu sự trượt này, qua đó đồng bộ hàng ngàn LPU hành xử như một core xử lý duy nhất. Bằng cách định thời điểm dữ liệu đến có thể dự đoán được và kết hợp đồng bộ hóa phần mềm định kỳ, môi trường runtime không cần đến các bộ đệm phòng thủ (defensive buffering). Việc khóa cứng độ trễ ở mức biên dịch giúp triệt tiêu hoàn toàn network hops ngẫu nhiên và biến hàng ngàn LPU trở thành một hệ thống đồng nhất, low-jitter hoàn hảo cho Agentic AI.
Các workload Agentic hưởng lợi như thế nào từ LPU C2C?
Quả ngọt lớn nhất của LPU C2C là tính định quyết ở cấp độ tủ mạng (rack-scale determinism): mang đến không gian lưu trữ 128 GB SRAM hợp nhất trên chip với hiệu năng luôn có thể dự đoán được cho dù bạn mở rộng quy mô đến đâu.
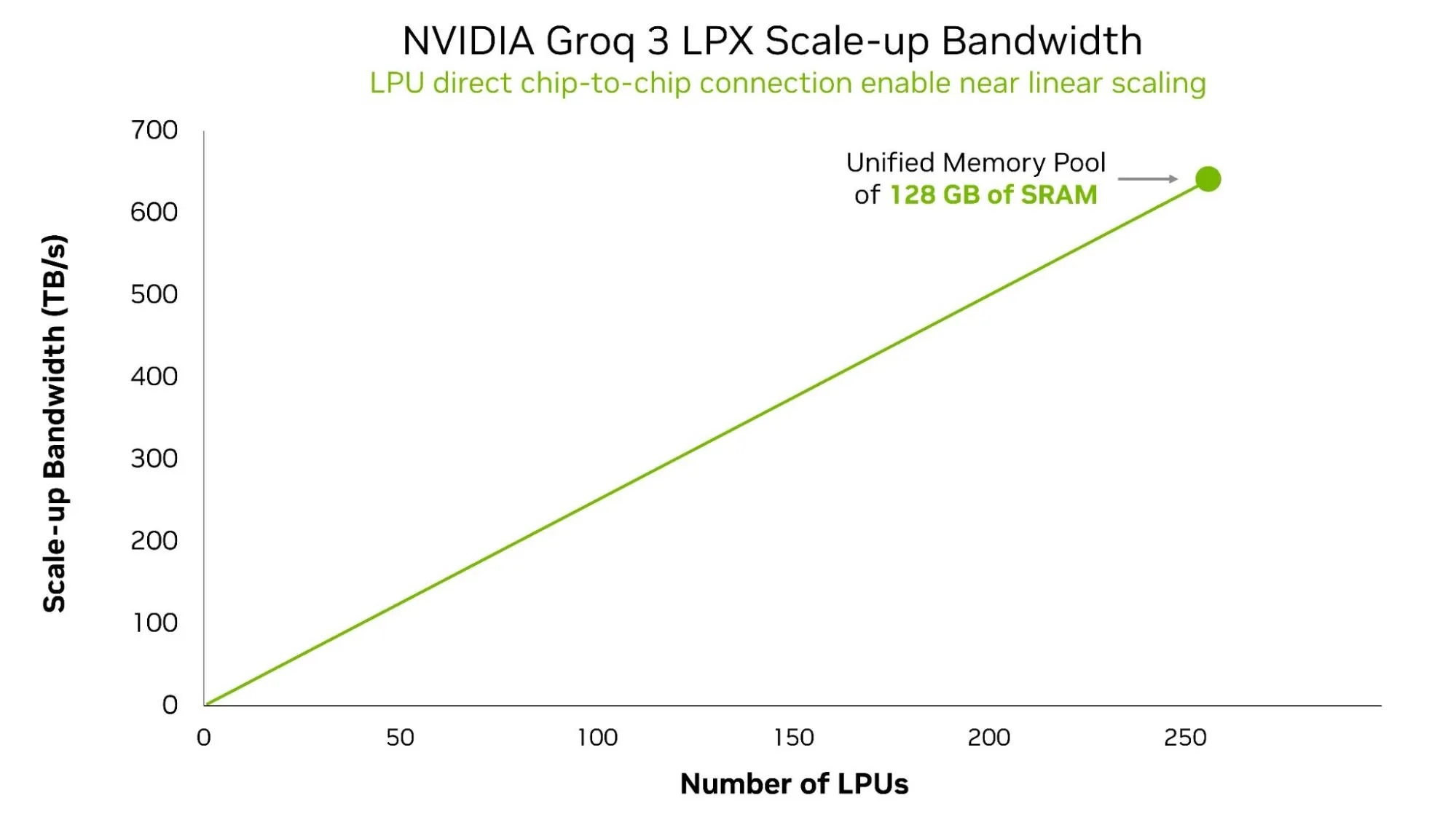
(Hình 3: Biểu đồ băng thông scale-up của NVIDIA Groq 3 LPX tăng trưởng gần như tuyến tính khi tăng số lượng LPU, chạm mốc 640 TB/s và tạo ra pool 128 GB SRAM hợp nhất ở cấp độ tủ LPX gồm 256 LPU).
Trình biên dịch LPU phân vùng các mô hình hàng nghìn tỷ tham số qua pool SRAM khổng lồ này thông qua các chiến lược như phân vùng theo lớp (layer-wise partitioning). Đối với Agentic AI, điều này cho phép các siêu mô hình MoE hoạt động với độ trễ tối thiểu mà không bắt chúng ta phải đánh đổi kích thước cửa sổ ngữ cảnh hay tính chính xác. Độ trễ đuôi (tail latency) được khóa chặn cực tốt ngay cả dưới các mẫu bung tải (bursty fan-out) đột ngột của các phiên chat multi-agent.
Tuy nhiên, “low latency” không bao giờ tự mình giải quyết được tất cả. Các trung tâm dữ liệu AI Factory còn cần năng lực tính toán cực sâu, thông lượng khổng lồ và khả năng phục vụ lượng truy cập lớn từ một pool GPU mạnh mẽ. Đó là lúc sức mạnh đồng thiết kế giữa nền tảng LPU và Vera Rubin NVL72 lên tiếng.
Vera Rubin NVL72 cung cấp lên tới 3,600 PFLOPS tính toán NVFP4, 20.7 TB HBM4, và băng thông bộ nhớ 1.6 PB/s mỗi rack. Sức mạnh này gồng gánh hoàn hảo các pha tải Prefill (nạp tiền xử lý), Decode Attention (chú ý giải mã) cho ngữ cảnh siêu dài, và phục vụ đồng thời ở mức rất cao. Khi ngân sách về độ trễ bị thu hẹp khắt khe hơn, hệ thống phần mềm NVIDIA Dynamo sẽ tham gia điều phối vòng lặp giải mã không đồng nhất (heterogeneous decode loop) thông qua kiến trúc có tên Attention-FFN Disaggregation (AFD).
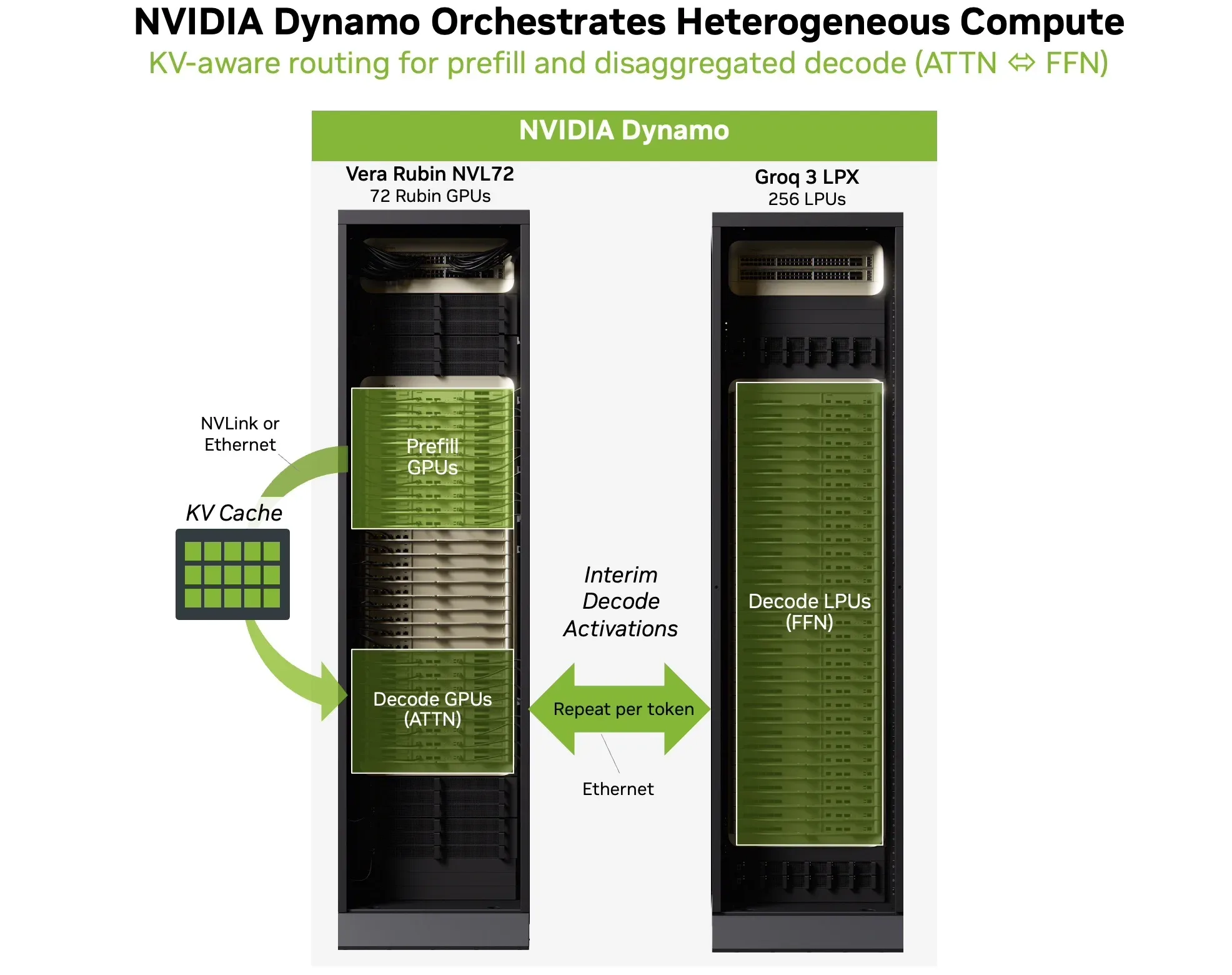
(Hình 4: Sơ đồ khái niệm minh họa NVIDIA Dynamo điều phối hạ tầng tính toán không đồng nhất: định tuyến work prefill và attention tới Vera Rubin NVL72 GPUs, và nhường FFN decode work cho Groq 3 LPX, cùng việc trao đổi dữ liệu tinh tế qua KV-aware transfer).
Vòng lặp AFD được triển khai khéo léo như sau:
-
Các GPU Vera Rubin sẽ chạy module decode attention chạy dọc theo KV cache tích lũy khổng lồ.
-
Các bộ tăng tốc LPX sẽ tiếp quản việc tăng tốc tính toán module FFN.
-
Các activations (kích hoạt) trung gian được luân chuyển chéo ở mỗi token với mức overhead siêu nhỏ nhờ quy trình truyền tải nhận thức KV (KV-aware transfers).
Sự phân công tác vụ tinh vi này thành công vì hai động cơ giải quyết hai cấu hình thời gian khác nhau. Prefill và decode attention là những giai đoạn thiên về cấu hình thông lượng (throughput-dominated) với kích thước Batch lớn và tần suất đọc KV cache được khấu hao dàn đều qua nhiều token — cực kỳ phù hợp với kết nối NVLink siêu băng thông cao. Ở chiều ngược lại, vòng lặp FFN Decode lại nhạy cảm với các cấu hình Batch nhỏ, sinh token tuần tự — nơi mà hiện tượng micro-jitter sẽ khuếch đại thành lag mà người dùng có thể trực tiếp cảm nhận. Khả năng truyền tải C2C với lộ trình biên dịch tĩnh sinh ra là “khắc tinh” của cấu hình trễ này.
Tựu trung lại, bộ ba Groq 3 LPX, Vera Rubin NVL72 và Dynamo kết hợp để tạo ra một kỷ nguyên phục vụ hoàn toàn mới. Ở mức 400 token/giây trên mỗi người dùng với các mô hình MoE nghìn tỷ tham số (ngữ cảnh 400K-token), kiến trúc extreme co-design của NVIDIA cung cấp thông lượng suy luận trên mỗi Megawatt điện cao gấp 35 lần so với NVIDIA GB200 NVL72, và mở ra khả năng thu về doanh thu (revenue opportunity) lớn gấp 10 lần cho các nền tảng chạy Agentic workloads.
Đây không chỉ là bước tiến về phần cứng, nó là màn tái cấu trúc hệ sinh thái phục vụ AI của tương lai.
Bài viết liên quan
- Hướng dẫn tạo LangChain Deep Agents Harness Profile cho NVIDIA Nemotron-3 Ultra để tối ưu hóa hiệu năng hệ thống Agent
- BioNeMo Agent Toolkit: Khi AI Agent bước vào phòng thí nghiệm số
- CPU NVIDIA Vera tăng cường thông lượng của AI Factory để đẩy nhanh các workload Agentic AI
- NVIDIA dẫn đầu hiệu suất Agentic Coding trên bài đo benchmark Agentic AI đầu tiên
- Khám phá Omniverse: 3 quy trình giúp cải thiện độ chính xác của Vision AI Agent với dữ liệu tổng hợp và fine-tuning
- Xây dựng chatbot AI nội bộ cho doanh nghiệp: Nhanh hơn, đúng ngữ cảnh hơn, kiểm soát tốt hơn