
Hợp đồng này quy định điều gì, báo giá nằm ở đâu, quy trình mới nhất là bản nào, tài liệu nào mới là nguồn cần dùng?

🔽
Đó là lý do dự án chatbot RAG nội bộ của NTC AI được xây dựng: không phải để tạo ra một chatbot “nói cho hay”, mà để giúp người dùng hỏi trực tiếp trên kho tài liệu doanh nghiệp, nhận câu trả lời theo ngữ cảnh, và giữ dữ liệu trong phạm vi kiểm soát của hệ thống.
Ad
Điểm khác biệt không nằm ở việc “có AI”, mà ở cách AI được đưa vào vận hành
Nhiều chatbot demo có thể trả lời khá ấn tượng trong một vài tình huống mẫu. Nhưng khi triển khai vào môi trường thật, bài toán sẽ khác hẳn: dữ liệu nhiều hơn, câu hỏi đa dạng hơn, người dùng truy cập đồng thời nhiều hơn, và yêu cầu kiểm soát dữ liệu cũng nghiêm túc hơn.
Dự án này được thiết kế theo hướng thực dụng: giữ pipeline vừa đủ, tách các bước nặng ra khỏi luồng hỏi đáp trực tiếp, ưu tiên truy xuất nhanh, streaming kết quả về người dùng, và dùng các thành phần hạ tầng có thể quan sát, đo đạc, tối ưu.
Nói ngắn gọn: hệ thống không cố làm mọi thứ. Hệ thống tập trung làm đúng một việc quan trọng trước tiên: giúp người dùng tìm và hiểu thông tin trong tài liệu nội bộ nhanh hơn, có kiểm soát hơn.
Chatbot này giải quyết vấn đề gì trong doanh nghiệp?
1. Giảm thời gian tìm kiếm trong tài liệu nội bộ.
Người dùng có thể đặt câu hỏi bằng ngôn ngữ tự nhiên thay vì tự mở từng file, tìm từng từ khóa, đọc từng trang. Với các nhóm làm việc thường xuyên phải tra hợp đồng, báo giá, quy trình, hồ sơ kỹ thuật hoặc tài liệu vận hành, đây là phần tiết kiệm thời gian rõ nhất.
2. Giữ dữ liệu nhạy cảm trong hệ thống kiểm soát được.
Thay vì phụ thuộc hoàn toàn vào API bên thứ ba cho mọi truy vấn, kiến trúc của dự án ưu tiên mô hình chạy local/on-premise bằng vLLM. Điều này phù hợp với các bài toán có dữ liệu nội bộ, hợp đồng, tài liệu khách hàng hoặc thông tin nghiệp vụ không nên đưa ra ngoài nếu chưa có chính sách rõ ràng.
3. Trả lời theo ngữ cảnh, không chỉ trả lời theo “trí nhớ” của mô hình.
Chatbot dùng RAG để truy xuất các đoạn tài liệu liên quan trước khi tạo câu trả lời. Cách tiếp cận này giúp câu trả lời bám vào nguồn dữ liệu doanh nghiệp hơn so với việc chỉ hỏi trực tiếp một mô hình ngôn ngữ.
4. Có nền tảng để audit, logging và cải tiến.
Một hệ thống AI dùng trong doanh nghiệp không thể chỉ dừng ở việc “trả lời được”. Cần có lịch sử phiên, log, lưu trữ, đo độ trễ, theo dõi lỗi và cơ chế cải tiến pipeline theo dữ liệu thực tế.
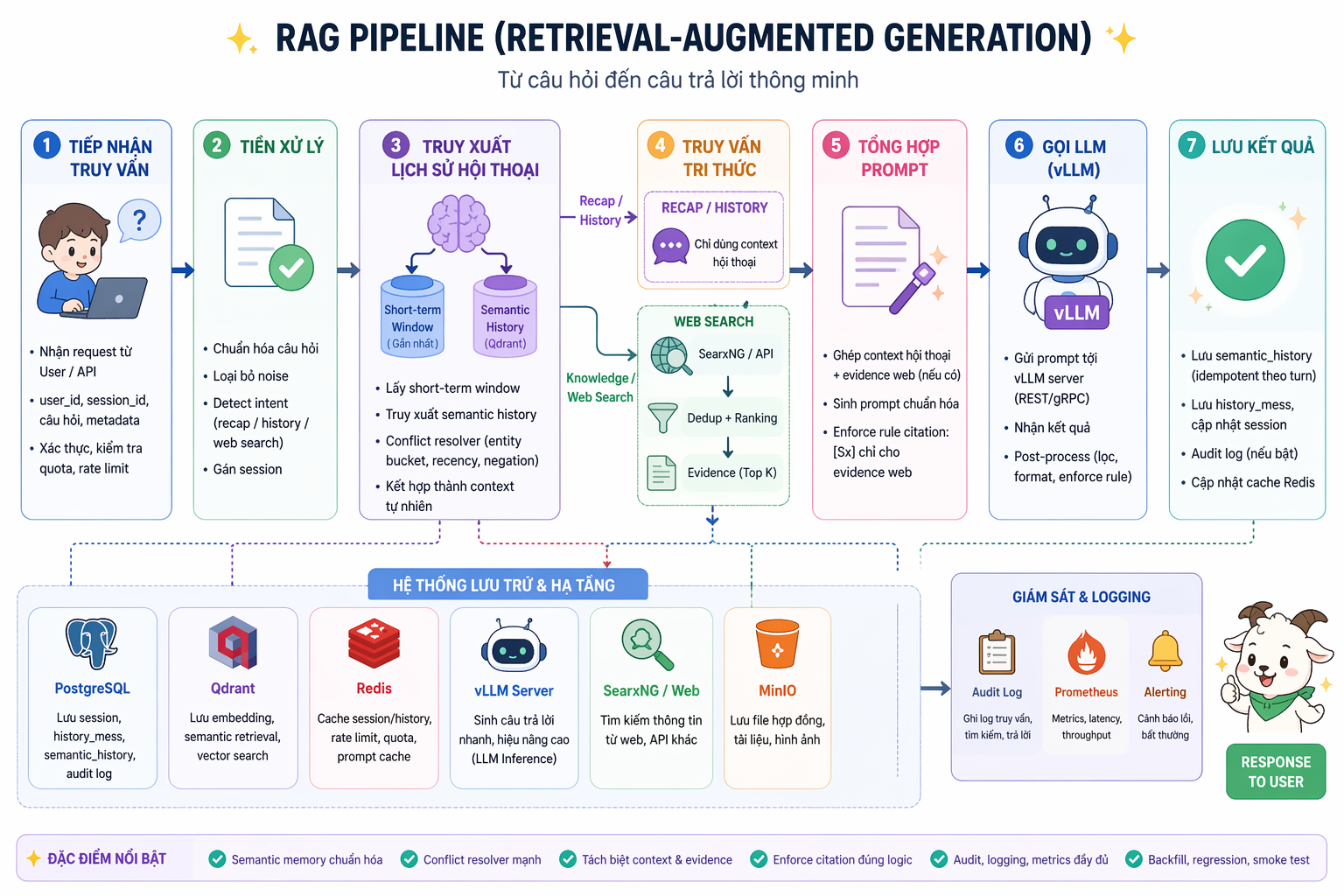
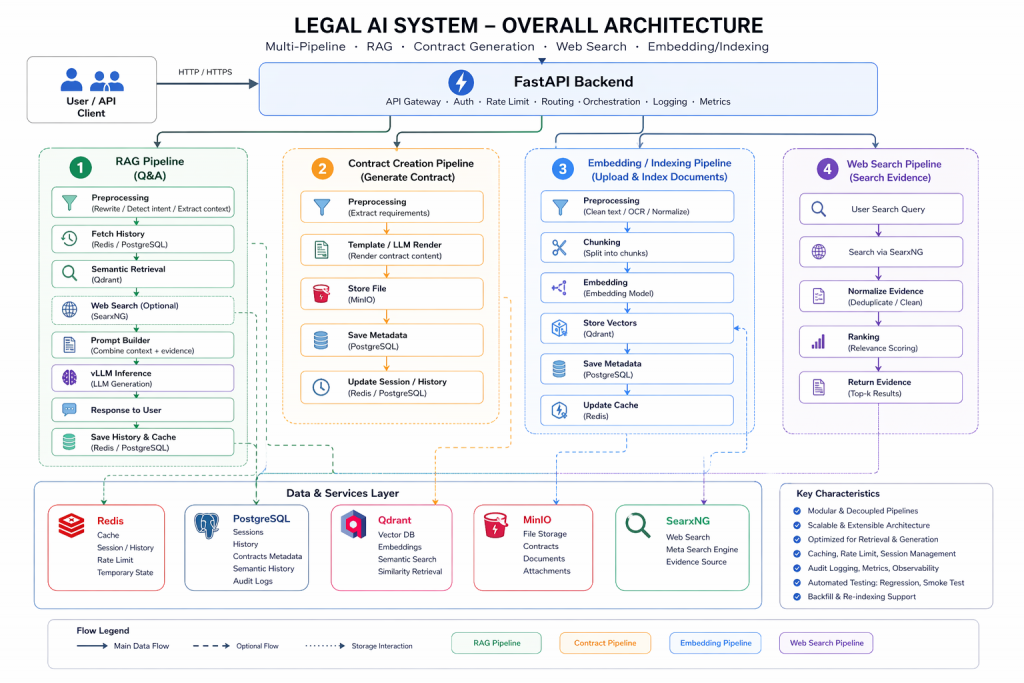
Bên dưới chatbot là một pipeline được thiết kế cho production
Ở lớp backend, hệ thống dùng FastAPI để tiếp nhận request, điều phối luồng xử lý và streaming kết quả. Redis được dùng cho cache, short-term history và các dữ liệu cần truy xuất nhanh. Qdrant đảm nhiệm phần vector database để tìm kiếm ngữ nghĩa trên tài liệu đã được embedding từ trước.
Phần sinh câu trả lời được phục vụ bằng vLLM, giúp triển khai mô hình ngôn ngữ mã nguồn mở trong môi trường local/on-premise. PostgreSQL kết hợp PgBouncer được dùng cho lịch sử, metadata, audit log và các thao tác lưu trữ bền vững. MinIO dùng để lưu file, tài liệu, hợp đồng hoặc tài nguyên liên quan.
Điểm quan trọng là hệ thống không dồn tất cả công việc vào lúc người dùng đặt câu hỏi. Các bước nặng như xử lý tài liệu, chunking, embedding và lưu metadata được đưa sang pipeline offline/asynchronous. Khi người dùng hỏi, runtime chỉ tập trung vào truy xuất context phù hợp, dựng prompt, gọi mô hình và trả lời.
Nói bằng số liệu, không nói bằng cảm giác
Trong thử nghiệm kỹ thuật của dự án, cụm vLLM cho thấy thời gian sinh token đầu tiên trung bình khoảng 45.78 ms ở bài benchmark raw LLM. Tốc độ sinh chữ đạt khoảng >60 tokens/giây với một người dùng, và tổng thông lượng đạt khoảng 810.05 tokens/giây khi đẩy tải đồng thời 10 users.
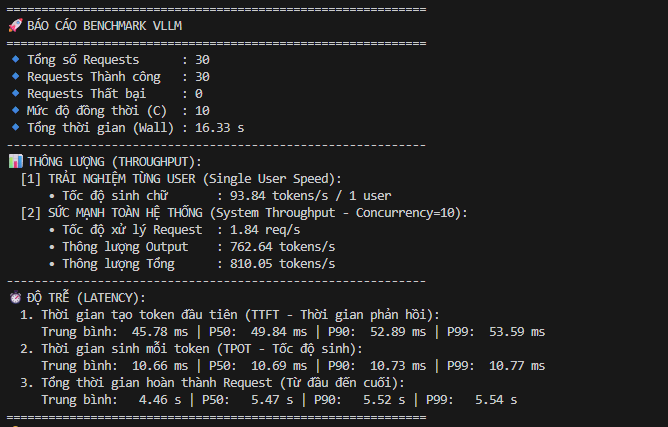
Khi ghép thành pipeline RAG hoàn chỉnh, bao gồm tiếp nhận request, truy xuất qua Qdrant, dựng prompt, sinh câu trả lời và lưu lịch sử, hệ thống đã được bắn thử 300 requests với mức đồng thời 10 users. Kết quả ghi nhận 300/300 requests thành công, không có request thất bại, thời gian trung bình toàn trình khoảng 17.85 giây.
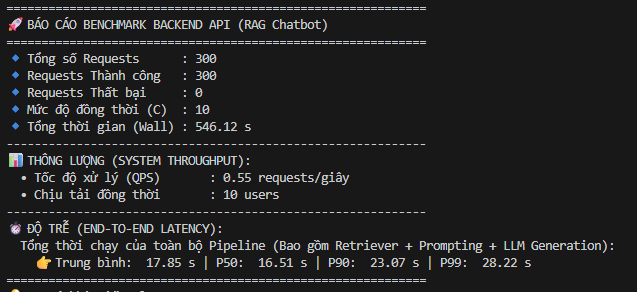
Con số này không được dùng để nói rằng mọi triển khai đều sẽ đạt đúng kết quả như vậy. Mỗi doanh nghiệp có dữ liệu, độ dài câu trả lời, phần cứng, model và yêu cầu bảo mật khác nhau. Nhưng benchmark cho thấy một điều quan trọng: hệ thống đã được đo đạc trên luồng thực tế, có số liệu để tối ưu, và không chỉ dừng ở mức demo.
Giới hạn của chatbot
Chatbot RAG không phải phép màu. Hệ thống không thể biến dữ liệu lộn xộn thành tri thức đáng tin cậy nếu không có bước chuẩn hóa, phân loại và kiểm thử. Hệ thống cũng không nên được hiểu là công cụ thay thế hoàn toàn chuyên gia pháp lý, nhân sự nghiệp vụ hoặc đội chăm sóc khách hàng.
Giá trị đúng của chatbot nằm ở chỗ khác: giúp người dùng truy cập thông tin nhanh hơn, giảm số câu hỏi lặp lại, hỗ trợ tra cứu tài liệu, tạo nền tảng để kiểm soát dữ liệu, và giúp đội vận hành có một hệ thống AI có thể quan sát được thay vì một hộp đen khó quản trị.
Phù hợp với những doanh nghiệp nào?
Dự án này đặc biệt phù hợp với các tổ chức đang có nhiều tài liệu nội bộ và nhu cầu hỏi đáp thường xuyên, ví dụ:
- Doanh nghiệp có nhiều hợp đồng, báo giá, hồ sơ dự án hoặc quy trình vận hành.
- Đội chăm sóc khách hàng cần tra cứu nhanh chính sách, hướng dẫn, điều kiện dịch vụ hoặc thông tin sản phẩm.
- Bộ phận pháp chế, kinh doanh, kỹ thuật hoặc vận hành cần tìm thông tin trong tài liệu dài.
- Doanh nghiệp muốn thử nghiệm AI nội bộ nhưng vẫn ưu tiên kiểm soát dữ liệu và hạ tầng.
Từ chatbot demo đến chatbot có thể vận hành
Điểm khó nhất của một dự án chatbot doanh nghiệp không phải là tạo ra câu trả lời đầu tiên. Điểm khó là làm sao để hệ thống trả lời ổn định hơn khi dữ liệu tăng lên, người dùng tăng lên, và yêu cầu kiểm soát trở nên nghiêm túc hơn.
Vì vậy, dự án chatbot RAG của NTC AI được xây dựng theo hướng có thể đo, có thể tối ưu và có thể mở rộng từng bước. Pipeline hiện tại đã có các lớp quan trọng: truy xuất ngữ nghĩa, lưu lịch sử hội thoại, cache, local inference, lưu trữ file, logging và benchmark.
Đây không phải là lời hứa rằng AI sẽ giải quyết mọi vấn đề trong doanh nghiệp. Đây là một bước đi thực tế hơn: đưa AI vào đúng nơi nó tạo giá trị rõ ràng nhất — hỗ trợ con người tìm, hiểu và sử dụng thông tin nội bộ nhanh hơn.
AI tốt cho doanh nghiệp phải bắt đầu từ sự kiểm soát
Một chatbot doanh nghiệp tốt không chỉ cần trả lời hay. Nó cần biết lấy thông tin từ đâu, chạy trên hạ tầng nào, lưu dữ liệu ra sao, đo độ trễ thế nào và cải tiến bằng cách nào.
Đó là hướng mà dự án chatbot RAG nội bộ của NTC AI đang theo đuổi: thực dụng, có số liệu, có kiến trúc rõ ràng và không đánh đổi quyền kiểm soát dữ liệu để lấy vài câu trả lời nghe có vẻ thông minh.
Nếu doanh nghiệp của bạn đang có một kho tài liệu nội bộ lớn và muốn biến nó thành một hệ thống hỏi đáp có kiểm soát, đây là thời điểm phù hợp để bắt đầu thử nghiệm trên chính dữ liệu thật của mình.
Trao đổi với NTC AI về chatbot nội bộ
Bài viết liên quan
- NVIDIA Blackwell lập kỷ lục STAC-AI về suy luận LLM trong lĩnh vực tài chính
- Triển khai kiến trúc Multi-Agent Intelligent Warehouse cho việc vận hành kho hàng hiện đại
- Triển khai hệ thống Voice RAG bằng NVIDIA Riva framework trên hạ tầng cục bộ
- NVIDIA nâng cấp các AI Agent cục bộ trên RTX PC và DGX Spark
- Blueprint: PDF-to-Podcast – Biến tài liệu PDF thành Podcast bằng AI