
Bạn có bao giờ nhận được một file PDF dài vài chục trang — báo cáo thường niên, paper nghiên cứu, tài liệu nội bộ công ty — rồi tự nhủ “để hôm nào đọc”, và cái “hôm nào” đó không bao giờ đến?
Bạn không đơn độc. Thực tế là rất nhiều tri thức giá trị đang bị “chôn vùi” trong những file PDF mà không ai muốn ngồi đọc hết. Không phải vì nội dung không hay, mà vì định dạng không phù hợp với nhịp sống hiện tại. Người ta nghe podcast khi lái xe, nghe audiobook khi tập gym, nghe bản tin khi nấu ăn — nhưng rất ít ai mở một file PDF 80 trang trong lúc đó.
NVIDIA nhìn thấy khoảng trống này và tạo ra một thứ khá thú vị: PDF-to-Podcast Blueprint — một hệ thống AI mã nguồn mở có khả năng đọc hiểu tài liệu PDF, viết kịch bản podcast, rồi “đọc” kịch bản đó bằng giọng nói tự nhiên. Kết quả cuối cùng? Một file MP3 nghe giống hệt một podcast thật, có người dẫn chương trình, có khách mời, có hỏi đáp qua lại.
Trong bài viết này, mình sẽ bóc tách cách hệ thống này hoạt động, tại sao nó khác biệt so với việc đơn giản “đọc to” một file PDF, và nó mở ra những khả năng gì cho doanh nghiệp, content creator hay bất kỳ ai muốn biến tài liệu thành audio.
Đây không phải “đọc PDF bằng giọng máy”
Trước khi đi sâu, cần phân biệt rõ một điều: PDF-to-Podcast hoàn toàn khác với text-to-speech thông thường.
Nếu bạn copy nội dung một báo cáo tài chính rồi paste vào Google Translate để nghe, bạn sẽ được một “bài giảng” dài, đều đều, không có nhấn nhá, không có giải thích, và chắc chắn không ai muốn nghe quá 2 phút. Đó là text-to-speech — chuyển chữ thành âm thanh, vậy thôi.
PDF-to-Podcast làm nhiều hơn thế rất nhiều. Nó biên tập lại nội dung. Hãy tưởng tượng bạn đưa một bản báo cáo dài cho một nhà sản xuất podcast giỏi. Người đó sẽ:
- Đọc hết tài liệu, hiểu các ý chính
- Quyết định phần nào quan trọng, phần nào nên lược bỏ
- Viết kịch bản: ai nói gì, theo thứ tự nào, giải thích thế nào cho dễ hiểu
- Sau đó mới thu âm
PDF-to-Podcast làm đúng quy trình đó — chỉ là mọi bước đều do AI đảm nhiệm.
Hai phong cách podcast
Hệ thống hỗ trợ hai chế độ, phục vụ hai mục đích khác nhau:
Chế độ đối thoại — giống một podcast thật với 2 người. Một người đóng vai host (người dẫn), hỏi các câu hỏi. Một người đóng vai guest (chuyên gia), giải thích nội dung. Họ trao đổi qua lại, đặt câu hỏi, phản bác, đồng tình — nghe tự nhiên như một cuộc trò chuyện thật.
Chế độ độc thoại — giống bản tin tài chính hoặc executive briefing. Một người trình bày ngắn gọn, rõ ràng, đi thẳng vào trọng tâm. Phù hợp khi bạn cần nắm nhanh nội dung mà không cần phần thảo luận.
Ví dụ: Bạn có bản báo cáo thường niên của một công ty. Ở chế độ đối thoại, bạn sẽ được nghe host hỏi “Vậy doanh thu năm nay so với năm ngoái thay đổi thế nào?” và guest trả lời chi tiết. Ở chế độ độc thoại, bạn nghe một bản tóm tắt 2 phút đi thẳng vào các con số chính.
Bên trong “nhà máy” sản xuất podcast
Để dễ hình dung, bạn có thể nghĩ hệ thống này như một dây chuyền nhà máy gồm 4 công đoạn, mỗi công đoạn do một “nhân viên AI” chuyên trách:
📄 Công đoạn 1: “Nhân viên đánh máy” — Đọc PDF ra chữ
Bước đầu tiên nghe có vẻ đơn giản nhưng lại rất quan trọng: trích xuất nội dung từ file PDF thành văn bản thuần.
Tại sao cần bước này? Vì file PDF không phải là một văn bản đơn thuần — nó là một “bức tranh” gồm chữ, bảng biểu, hình ảnh, header, footer, watermark xếp chồng lên nhau. AI không thể “nhìn” file PDF như mắt người, nên cần một bước chuyển đổi để rút ra phần chữ có ý nghĩa.
Bước này quyết định rất nhiều đến chất lượng cuối cùng. Nếu “nhân viên đánh máy” gõ sai — bỏ sót tiêu đề, lẫn lộn thứ tự đoạn văn, hoặc không đọc được bảng số liệu — thì “nhà biên kịch” ở bước sau sẽ phải làm việc với dữ liệu sai, và podcast cuối cùng cũng sẽ sai theo.
Hạn chế cần biết: Hệ thống hiện tại xử lý tốt PDF có chữ rõ ràng (kiểu bạn tạo file từ Word, Google Docs). Nhưng với PDF scan (ảnh chụp tài liệu), PDF có nhiều biểu đồ phức tạp, hoặc công thức toán học, chất lượng trích xuất sẽ giảm đáng kể. Giống như khi bạn đưa một bản photocopy mờ cho ai đó đánh máy lại — kết quả khó mà hoàn hảo được.
🎭 Công đoạn 2: “Nhà biên kịch” — Viết kịch bản podcast
Đây là bước thú vị nhất và cũng là nơi AI thể hiện sức mạnh thật sự.
Sau khi có văn bản từ bước 1, AI không đơn giản “đọc lại” nội dung. Nó thực sự biên tập lại toàn bộ, tương tự như cách một nhà sản xuất podcast chuyên nghiệp sẽ làm:
Bước 1 — Đọc hiểu và tóm tắt: AI đọc toàn bộ tài liệu, nắm bắt các ý chính, giống như bạn đọc xong một bài dài rồi kể lại cho bạn bè nghe trong 5 phút.
Bước 2 — Lên dàn ý: Từ bản tóm tắt, AI sắp xếp nội dung thành cấu trúc podcast: mở đầu nói gì, phần giữa có mấy chủ đề, mỗi chủ đề nói bao lâu, kết thúc ra sao. Giống như mục lục của một cuốn sách, nhưng cho podcast.
Bước 3 — Viết nội dung chi tiết từng phần: Mỗi phần trong dàn ý được triển khai đầy đủ, có trích dẫn số liệu, có ví dụ minh hoạ, có giải thích thuật ngữ.
Bước 4 — Biến thành đối thoại: Nội dung “cứng” được chuyển thành cuộc trò chuyện tự nhiên. Host đặt câu hỏi như “Vậy con số này có ý nghĩa gì với ngành?”, Guest trả lời. AI thậm chí thêm cả những yếu tố tự nhiên như “Well, that’s a great question…”, “Hmm, let me think about that…” để podcast nghe sinh động hơn.
Bước 5 — Ghép nối mượt mà: Các đoạn hội thoại riêng lẻ được ghép lại thành một bài hoàn chỉnh. AI đảm bảo chuyển đổi giữa các chủ đề tự nhiên, không bị “nhảy cóc”.
Bước 6 — Xuất kịch bản: Kịch bản cuối cùng được format thành danh sách rõ ràng: ai nói câu nào, theo thứ tự nào. Tất cả số liệu được chuyển sang dạng đọc được — “fifty percent” thay vì “50%”, “one billion dollars” thay vì “$1B” — để giọng đọc nghe tự nhiên.
Điểm hay ở đây: AI không viết kịch bản bằng một lần duy nhất. Nó chia thành nhiều bước nhỏ, mỗi bước có mục tiêu rõ ràng. Cách làm này giống như khi bạn viết một bài luận: phác thảo trước, viết chi tiết sau, rồi đọc lại chỉnh sửa — thay vì viết một mạch từ đầu đến cuối rồi hy vọng nó ổn.
🎙️ Công đoạn 3: “Diễn viên lồng tiếng” — Đọc kịch bản thành giọng nói
Khi kịch bản hoàn chỉnh, từng câu thoại được gửi đến dịch vụ tạo giọng nói AI (ElevenLabs). Mỗi “nhân vật” trong podcast có giọng riêng — nghe phân biệt rõ ràng giữa host và guest.
Các đoạn audio sau đó được ghép lại thành một file MP3 hoàn chỉnh, sẵn sàng để nghe.
Nghe có vẻ đơn giản, nhưng bước này có vài thách thức đáng kể:
-
Số lượng lớn: Một podcast 10 phút có thể chứa hàng chục đến hàng trăm lượt thoại, mỗi lượt là một lần gọi dịch vụ tạo giọng nói. Nếu xử lý tuần tự (câu 1 xong mới đến câu 2), thời gian chờ sẽ rất lâu. Vì vậy hệ thống xử lý song song nhiều câu cùng lúc, nhưng phải kiểm soát để không bị quá tải.
-
Ghép nối tự nhiên: Khi ghép các đoạn audio lại, cần đảm bảo âm lượng đều, khoảng nghỉ giữa lượt thoại hợp lý, và tổng thể nghe mượt mà — không bị cảm giác “cắt dán”.
-
Xử lý lỗi thông minh: Nếu 1 câu trong 100 câu bị lỗi khi tạo giọng nói, hệ thống chỉ cần tạo lại câu đó thay vì làm lại toàn bộ podcast từ đầu. Điều này tiết kiệm cả thời gian lẫn chi phí.
🎬 Công đoạn 4: “Quản lý sản xuất” — Điều phối mọi thứ
Cuối cùng, có một “quản lý tổng” đứng giám sát cả 3 công đoạn trên. Nhiệm vụ của nó:
- Biết khi nào bước nào xong, tự động chuyển sang bước tiếp theo
- Lưu trữ tất cả kết quả: PDF gốc, kịch bản, file audio
- Thông báo tiến độ cho người dùng theo thời gian thực (bạn có thể theo dõi trên giao diện web)
- Xử lý khi có lỗi: thử lại, bỏ qua, hoặc báo cho người dùng
Toàn bộ quy trình, từ lúc upload PDF đến khi nhận file MP3, thường mất vài phút tuỳ độ dài tài liệu.
Tại sao cách làm này khác biệt?
AI ở đây là “biên tập viên”, không phải “máy đọc”
Điểm khác biệt lớn nhất của PDF-to-Podcast so với text-to-speech thông thường là AI đóng vai biên tập viên, không chỉ là công cụ chuyển đổi.
Hãy nghĩ thế này: một tài liệu viết tốt chưa chắc đã nghe tốt nếu đọc nguyên văn. Khi đọc, bạn có thể dừng lại xem biểu đồ, lướt ngược lên xem mục lục, đối chiếu số liệu. Khi nghe, bạn không có những “đặc quyền” đó — thông tin chỉ đi qua một lần. Vì vậy, nội dung cần được tái cấu trúc cho phù hợp với trải nghiệm nghe.
AI trong hệ thống này phải trả lời nhiều câu hỏi: Phần nào là bối cảnh cần giải thích trước? Phần nào là luận điểm chính cần nhấn mạnh? Phần nào nên diễn giải bằng ví dụ? Phần nào nên lược bỏ để giữ nhịp?
Trong chế độ đối thoại, host đóng vai “người đại diện cho người nghe” — hỏi những câu mà người nghe sẽ thắc mắc, yêu cầu giải thích thuật ngữ, tóm lại ý chính sau mỗi đoạn dài. Guest là “chuyên gia” giải thích nội dung, nhưng phải bám sát tài liệu gốc thay vì bịa thêm.
Chia nhỏ để kiểm soát chất lượng
Một điểm thiết kế thông minh: hệ thống không nhồi toàn bộ tài liệu vào AI rồi yêu cầu “viết podcast đi”. Thay vào đó, nó chia thành nhiều bước nhỏ, mỗi bước có nhiệm vụ cụ thể.
Tại sao điều này quan trọng? Vì khi bạn yêu cầu AI làm quá nhiều việc cùng lúc, kết quả thường kém hơn so với khi chia nhỏ ra. Giống như khi bạn nhờ ai đó “đọc cuốn sách này rồi viết kịch bản phim đi” — kết quả sẽ tốt hơn nhiều nếu bạn nhờ họ “đọc xong tóm tắt trước, rồi lên dàn ý, rồi mới viết kịch bản”.
Cách tiếp cận nhiều bước cũng giúp dễ phát hiện lỗi hơn. Nếu bản tóm tắt ở bước 1 đã sai, bạn có thể sửa ngay thay vì phải chờ đến khi nghe podcast cuối cùng mới phát hiện.
Vấn đề “nghe tự nhiên nhưng nội dung sai”
Đây là điều mà bất kỳ ai dùng AI tạo nội dung đều cần biết: AI có thể tự tin nói những điều không đúng.
Trong thế giới text, bạn có thể dừng lại kiểm tra từng câu. Nhưng khi nghe podcast, thông tin đi qua liên tục — người nghe ít có xu hướng tạm dừng để fact-check. Một nhận định sai, nếu được đọc bằng giọng nói tự nhiên và tự tin, có thể nghe đáng tin hơn mức nó xứng đáng.
Hệ thống có một cơ chế gọi là prompt tracker — ghi lại toàn bộ quá trình AI đã “suy nghĩ” như thế nào: nó nhận lệnh gì, tạo ra nội dung gì, ở bước nào. Điều này giúp người kiểm duyệt có thể truy ngược từ một câu thoại trong podcast về đoạn văn gốc trong PDF.
Tuy nhiên, với tài liệu quan trọng — đặc biệt trong lĩnh vực tài chính, pháp lý hay y tế — lời khuyên vẫn là: nên xem kịch bản trước khi xuất bản podcast. Dùng AI để tạo bản nháp nhanh, dùng con người để kiểm tra lần cuối.
Ai nên quan tâm đến hệ thống này?
Content creator và podcaster
Nếu bạn đang sản xuất podcast và thường xuyên cần nghiên cứu tài liệu trước mỗi tập, hệ thống này có thể tạo bản nháp đầu tiên cực nhanh. Thay vì ngồi đọc 50 trang rồi tự viết script, bạn để AI tạo bản nháp, rồi chỉnh sửa theo phong cách của mình.
Dân tài chính và nghiên cứu
Biến báo cáo thường niên, phân tích ngành, paper nghiên cứu thành audio để nghe khi di chuyển. Thay vì 80 trang đọc mỏi mắt, bạn có podcast 15 phút tóm tắt những điều quan trọng nhất.
Doanh nghiệp
- Chuyển tài liệu đào tạo nội bộ thành audio cho nhân viên
- Biến báo cáo tuần thành bản tin audio gửi cho team
- Tạo executive briefing nhanh từ các tài liệu dài
Developer và startup
Đây là mã nguồn mở — bạn có thể clone về, tùy biến, và xây dựng sản phẩm riêng trên nền tảng này. Một startup có thể biến nó thành sản phẩm tạo podcast giáo dục từ giáo trình, hoặc dịch vụ audio briefing cho ngành tài chính.
Bạn có thể tùy biến những gì?
Vì là mã nguồn mở, hệ thống cho phép tùy chỉnh ở nhiều điểm:
🔄 Đổi “bộ não” AI
Mặc định, hệ thống dùng model Nemotron 49B của NVIDIA. Nhưng bạn có thể đổi sang các model khác — mạnh hơn cho chất lượng tốt hơn, hoặc nhẹ hơn để tiết kiệm chi phí. Chỉ cần chỉnh một file cấu hình.
Tuy nhiên, đổi model không đơn giản như đổi tên. Model mới cần được kiểm tra: nó có viết kịch bản tốt không? Có giữ đúng cấu trúc đầu ra không? Có hay “bịa” thêm thông tin không? Có nhanh đủ không? Đôi khi, một model “nghe có vẻ thông minh hơn” nhưng lại chậm hơn hoặc hay lỗi hơn, khiến tổng chi phí tăng lên.
🎤 Đổi giọng nói
ElevenLabs có hàng trăm giọng nói khác nhau — nam, nữ, các accent khác nhau. Bạn thậm chí có thể clone giọng riêng để podcast nghe như chính bạn đang nói.
Một điểm đáng chú ý: với podcast tiếng Việt, cần thêm bước xử lý trước khi tạo giọng nói. Ví dụ, AI cần biết đọc “VN-Index” là “Vi En Index”, đọc “FDI” là “Ép Đi Ai”, đọc “15,3%” là “mười lăm phẩy ba phần trăm”. Bước xử lý nhỏ này lại ảnh hưởng rất nhiều đến chất lượng nghe cuối cùng.
✍️ Đổi phong cách
Muốn podcast giọng nghiêm túc kiểu BBC? Hay giọng thân thiện kiểu Morning Brew? Hay giọng hài hước kiểu podcast giải trí? Tất cả phụ thuộc vào cách bạn “dặn dò” AI (thay đổi các prompt). Đây là nơi sản phẩm có thể tạo ra sự khác biệt thật sự.
Hình dung: cùng một bản báo cáo tài chính, hệ thống có thể tạo ra bản briefing 5 phút cho giám đốc, bản hướng dẫn 20 phút cho nhân viên mới, hoặc bản phân tích sâu 45 phút cho đội chuyên môn. Tất cả phụ thuộc vào cách bạn cấu hình.
🌐 Đổi ngôn ngữ
Chỉnh prompt sang tiếng Việt → podcast tiếng Việt. ElevenLabs đã hỗ trợ nhiều ngôn ngữ, bao gồm tiếng Việt.
⏱️ Đổi thời lượng
Podcast 5 phút hay 30 phút? Chỉ cần thay một con số.
Những hạn chế cần biết
Mình muốn trung thực với bạn về những điều hệ thống này chưa làm tốt:
1. Phụ thuộc vào chất lượng PDF đầu vào. PDF sạch (tạo từ Word, Google Docs) → kết quả tốt. PDF scan, PDF nhiều hình ảnh, bảng biểu phức tạp → kết quả giảm rõ rệt. Nguyên tắc: “rác vào thì rác ra” — nếu AI đọc sai tài liệu, podcast cũng sẽ sai.
2. AI có thể “bịa” thông tin. Đây là vấn đề chung của tất cả hệ thống AI hiện nay (gọi là “hallucination”). AI có thể viết rất mượt nhưng thêm những nhận định không hề có trong tài liệu gốc. Với tài liệu quan trọng, luôn review kịch bản trước khi xuất bản.
3. Tốn chi phí API. Mỗi lần tạo podcast, hệ thống gọi API của NVIDIA (cho AI viết kịch bản) và ElevenLabs (cho tạo giọng nói). Podcast càng dài, chi phí càng cao. Đây không phải dịch vụ miễn phí — bạn cần API key và credit.
4. Thời gian xử lý. Một tài liệu dài có thể mất vài phút để xử lý. Đây không phải trải nghiệm “click là xong ngay” — cần kiên nhẫn chờ qua các công đoạn.
5. Bảo mật dữ liệu. Tài liệu được gửi qua các API bên ngoài để xử lý. Với tài liệu mật hoặc nhạy cảm, cần cân nhắc kỹ hoặc tự host model trên máy chủ riêng.
Nếu muốn nghiêm túc hơn: những bài toán cần giải
Phần này dành cho bạn nào muốn đưa hệ thống từ “thử chơi cho biết” lên mức “vận hành thật sự”, đặc biệt trong môi trường doanh nghiệp.
Xử lý nhiều tài liệu cùng lúc
Khi chỉ một người dùng upload một file, mọi thứ chạy ổn. Nhưng khi 50 người cùng upload 50 file? AI sẽ trở thành “nút thắt cổ chai” — giống như một đầu bếp giỏi nhưng chỉ có thể nấu từng món một, khi quán đông thì khách phải chờ rất lâu.
Giải pháp là tăng “số đầu bếp” lên (chạy nhiều bản sao AI song song), nhưng cần cân đối giữa tốc độ và chi phí. Một model nhanh nhưng hay sai format thì phải chạy lại, có khi tốn kém hơn model chậm nhưng ổn định.
Đảm bảo nội dung đáng tin cậy
Trong môi trường doanh nghiệp — đặc biệt tài chính, pháp lý, y tế — mỗi con số, mỗi nhận định đều cần chính xác. Hệ thống cần lưu vết: câu thoại này lấy từ trang nào, đoạn nào trong PDF gốc. Nếu podcast nói “doanh thu tăng 25%”, phải truy ngược được nguồn để kiểm chứng.
Quản lý dữ liệu
Mỗi lần tạo podcast, hệ thống sinh ra nhiều file: PDF gốc, bản text, kịch bản, các đoạn audio, file MP3 cuối cùng. Doanh nghiệp cần biết: lưu bao lâu? Ai được xem? Có mã hoá không? Người dùng có thể yêu cầu xoá không? Đây là những câu hỏi “nhàm chán” nhưng bắt buộc phải trả lời trước khi triển khai chính thức.
Đo lường để tối ưu
Nếu người dùng phản ánh “tạo podcast lâu quá”, đội kỹ thuật cần biết chính xác thời gian bị tiêu tốn ở đâu: đọc PDF mất bao lâu? AI viết kịch bản mất bao lâu? Tạo giọng nói mất bao lâu? Không có số liệu, mọi tối ưu đều là phỏng đoán. Blueprint có sẵn hệ thống theo dõi (Jaeger) giúp “soi” vào từng bước trong dây chuyền.
Bắt đầu thử như thế nào?
Nếu bạn muốn thử ngay, quy trình khá đơn giản:
- Clone mã nguồn từ GitHub về máy
- Tạo file cấu hình với 2 API key: một của NVIDIA (cho AI), một của ElevenLabs (cho giọng nói)
- Chạy 1 lệnh để khởi động toàn bộ hệ thống:
bash ./setup.sh --up - Mở trình duyệt, upload PDF, chọn chế độ (đối thoại hay độc thoại), bấm tạo podcast, chờ vài phút, tải file MP3
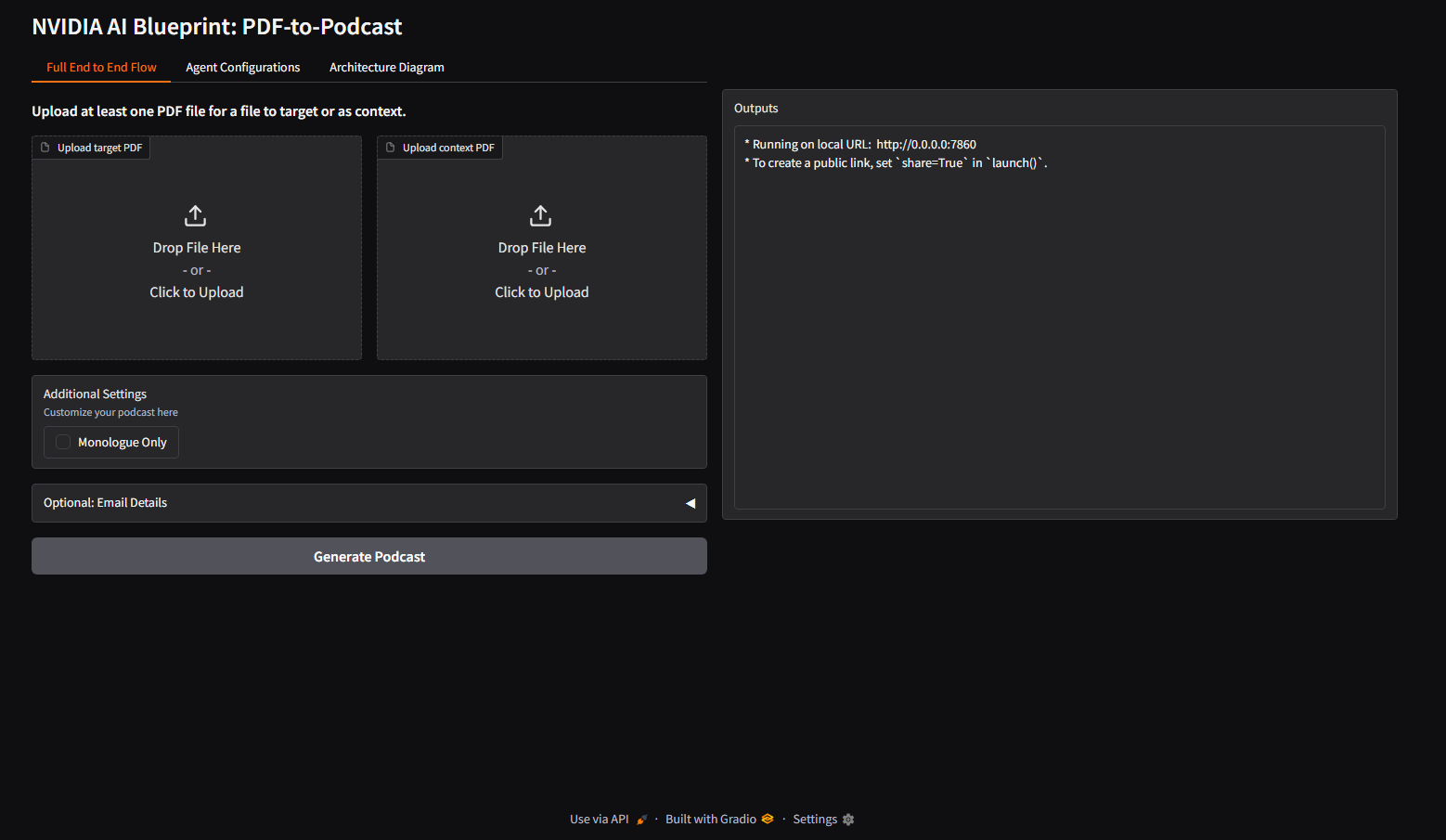
Lưu ý: Bạn không cần GPU khi chạy thử vì hệ thống đang dùng Cloud API. Tuy nhiên, đây chỉ là bản thử nghiệm nhanh. Để đưa vào vận hành thực tế (production), bạn bắt buộc phải có GPU để tự host model nhằm đảm bảo an toàn dữ liệu và tối ưu chi phí lâu dài.
Khi nhận file MP3, đừng chỉ nghe cho vui — hãy kiểm tra: nội dung có đúng với PDF gốc không? Số liệu có chính xác không? Có chỗ nào AI “bịa” thêm không? Chất lượng giọng nói thế nào? Đó mới là cách đánh giá hệ thống nghiêm túc.
Nhìn xa hơn: tương lai của việc tiêu thụ tri thức
PDF-to-Podcast không chỉ là một project thú vị — nó là tín hiệu cho thấy cách chúng ta tiếp cận thông tin đang thay đổi.
Hãy tưởng tượng mỗi sáng thứ Hai, bạn nhận được một podcast 10 phút tóm tắt tất cả báo cáo, email quan trọng và tài liệu nội bộ trong tuần trước. Nghe trong lúc uống cà phê, nắm hết mọi thứ mà không cần mở laptop.
Hay tưởng tượng bạn là giảng viên đại học. Sinh viên của bạn không đọc giáo trình? Biến giáo trình thành podcast — đột nhiên tỷ lệ “đọc bài” tăng vọt, vì bây giờ họ “nghe bài” khi đi xe buýt.
NVIDIA đã mở cửa nền tảng này cho tất cả mọi người. Giá trị thật sự không nằm ở việc tạo được vài file MP3 demo hay ho, mà nằm ở khả năng biến lượng tri thức đang bị bỏ quên trong các file PDF thành trải nghiệm mà mọi người thật sự muốn tiêu thụ.
Cách tốt nhất để bắt đầu? Lấy một tài liệu mà bạn đang lười đọc, quẳng vào hệ thống, và nghe AI kể lại cho bạn.
👉 Trải nghiệm và tìm hiểu thêm tài liệu gốc tại: NVIDIA PDF-to-Podcast Blueprint
Bài viết liên quan
- NVIDIA Riva giải pháp Voice RAG: tối ưu luồng dữ liệu âm thanh và đồng bộ Avatar 3D
- NVIDIA Dynamo Snapshot: Khởi động nhanh cho workload suy luận trên Kubernetes
- Triển khai kiến trúc Multi-Agent Intelligent Warehouse cho việc vận hành kho hàng hiện đại
- Triển khai NVIDIA Retail Agentic Commerce Blueprint: Merchant-Controlled
- Triển khai hệ thống Voice RAG bằng NVIDIA Riva framework trên hạ tầng cục bộ
- Triển khai AI Agent sẵn sàng cho thực tế tại biên với hiệu quả sử dụng bộ nhớ cao trên NVIDIA JetPack 7.2