
Trong hành trình phát triển của Trí tuệ Nhân tạo (AI), chúng ta thường nghe nhiều về việc “nhồi nhét” dữ liệu cho máy móc để chúng học cách nhận diện hình ảnh hay dịch thuật. Tuy nhiên, khi đối mặt với những bài toán đòi hỏi sự suy luận liên tục, ra quyết định theo chuỗi và thích nghi với môi trường biến đổi, các phương pháp truyền thống bắt đầu bộc lộ hạn chế.
Đó là lúc Reinforcement Learning (Học Tăng Cường – RL) bước ra ánh sáng.
Nếu bạn đã từng tò mò về cách AI đánh bại nhà vô địch cờ vây thế giới, hay cách robot học cách nhào lộn điêu luyện, thì bài viết này chính là câu trả lời dành cho bạn.
Bối cảnh và Lý do ra đời của Reinforcement Learning
Nút thắt của các phương pháp học máy truyền thống
Trong Machine Learning (Học máy), hai phương pháp phổ biến nhất là:
-
Supervised Learning (Học có giám sát): Máy tính học từ dữ liệu đã được con người dán nhãn sẵn. (Ví dụ: Đưa cho AI 10.000 bức ảnh con mèo và bảo “Đây là con mèo”).
-
Unsupervised Learning (Học không giám sát): Máy tính tự tìm ra quy luật từ dữ liệu thô, không có nhãn.
Hạn chế: Cả hai phương pháp này đều bị phụ thuộc nặng nề vào bộ dữ liệu tĩnh. Chúng không thể giúp một AI biết cách tự lái xe an toàn trên một đường phố hỗn loạn hay chơi một trò chơi điện tử phức tạp, vì chúng ta không thể “dán nhãn” mọi tình huống có thể xảy ra trong thực tế.
Cảm hứng từ tâm lý học hành vi
Các nhà khoa học máy tính đã tìm về một nguyên lý cơ bản nhất của tự nhiên: Học qua thử và sai (Trial and Error).
Ý tưởng này bắt nguồn từ các thí nghiệm tâm lý học hành vi (như con chó của Pavlov hay chiếc hộp của Skinner). Một sinh vật sẽ có xu hướng lặp lại những hành động mang lại cho chúng phần thưởng, và tránh xa những hành động dẫn đến hình phạt. Reinforcement Learning ra đời dựa trên chính triết lý này, biến AI thành một “tác nhân” có khả năng tự tương tác với thế giới xung quanh để rút ra bài học.
Reinforcement Learning hoạt động như thế nào?
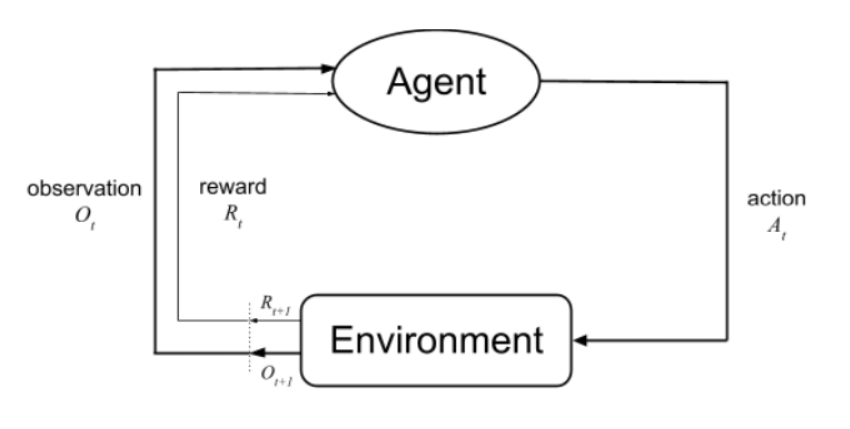
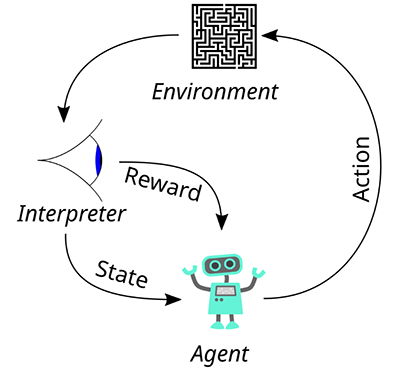
Bạn có thể hình dung việc huấn luyện RL giống như cách bạn dạy một chú cún con nhặt bóng. Cấu trúc cốt lõi của quá trình này bao gồm 5 yếu tố chính:
-
Agent (Tác tử/Tác nhân): Là mô hình AI đang cần được học (chú cún).
-
Environment (Môi trường): Thế giới mà Agent tương tác (sân vườn, quả bóng, và bạn).
-
State (S – Trạng thái): Tình huống hiện tại của môi trường (bóng đang nằm ở xa).
-
Action (A – Hành động): Những gì Agent có thể làm (chạy đi gặm bóng, nằm yên, sủa).
-
Reward (R – Phần thưởng/Hình phạt): Phản hồi từ môi trường (Nếu nhặt bóng về: được thưởng xúc xích. Nếu cắn rách bóng: bị mắng).
Vòng lặp học tập (The RL Loop)
Hệ thống sẽ vận hành theo một vòng lặp liên tục:
-
Agent quan sát State hiện tại của Environment.
-
Dựa trên “chính sách” (π – Policy) hiện có, Agent quyết định thực hiện một Action.
-
Environment chuyển sang một trạng thái mới và trả về một Reward (dương, âm, hoặc bằng không).
-
Agent cập nhật lại hiểu biết của mình, tối ưu hóa để tổng phần thưởng nhận được trong tương lai là cao nhất.
Thuật toán không nói cho Agent biết phải làm gì, mà để Agent tự khám phá xem hành động nào mang lại chuỗi phần thưởng lớn nhất dài hạn.
Ý nghĩa và Ứng dụng thực tiễn

Reinforcement Learning không chỉ là lý thuyết trong phòng thí nghiệm. Nó đã tạo ra những đột phá thay đổi bộ mặt của AI hiện đại:
-
Chinh phục các trò chơi trí tuệ: Cột mốc vĩ đại nhất là năm 2016, khi hệ thống AlphaGo của DeepMind đánh bại Lee Sedol (nhà vô địch cờ vây thế giới). Không có thuật toán dán nhãn nào đủ sức giải quyết cờ vây, AlphaGo đã học bằng cách đấu hàng triệu ván với chính nó thông qua RL.
-
Tối ưu hóa Mô hình Ngôn ngữ Lớn (LLMs): Các chatbot như ChatGPT hay Gemini trở nên tự nhiên, an toàn và hữu ích là nhờ kỹ thuật RLHF (Reinforcement Learning from Human Feedback). AI ban đầu tạo ra nhiều câu trả lời, con người xếp hạng chúng, và AI dùng RL để học cách đưa ra câu trả lời vừa lòng con người nhất.
-
Robotics (Robot tự hành): Các công ty như Boston Dynamics sử dụng RL để dạy robot cách giữ thăng bằng, nhảy múa, hoặc đi qua các địa hình gồ ghề mà không cần lập trình thủ công từng chuyển động.
-
Xe tự lái & Quản lý giao thông: RL giúp hệ thống xe tự lái ra quyết định theo thời gian thực (vượt xe, phanh gấp) dựa trên việc quan sát các xe xung quanh như một môi trường động.
-
Tài chính: Thuật toán giao dịch tự động (Algorithmic trading) sử dụng RL để tối đa hóa lợi nhuận đầu tư trong một thị trường chứng khoán luôn biến động.
Những thách thức hiện tại của RL
Dù rất mạnh mẽ, RL không phải là “viên đạn bạc” giải quyết mọi vấn đề. Kỹ thuật này vẫn đang đối mặt với nhiều rào cản:
-
Sự kém hiệu quả về dữ liệu (Sample Inefficiency): Một Agent có thể phải thực hiện hàng triệu, thậm chí hàng tỷ lần thử-sai để học được một kỹ năng cơ bản. Quá trình này tiêu tốn lượng tài nguyên điện toán khổng lồ.
-
Exploration vs. Exploitation (Khám phá và Khai thác): Agent luôn đứng trước ngã ba đường: Nên chọn hành động đã biết là có phần thưởng (Khai thác), hay thử một hành động mới chưa từng làm với hy vọng phần thưởng lớn hơn (Khám phá)? Cân bằng hai yếu tố này là bài toán cực khó.
-
Thiết kế hàm phần thưởng (Reward Shaping): Nếu bạn định nghĩa sai phần thưởng, AI sẽ tìm ra những “lỗ hổng” để gian lận. (Ví dụ: Mục tiêu là đua xe nhanh nhất, AI có thể học cách lái xe vòng tròn tại vạch đích để liên tục ghi điểm thay vì đua hết chặng).
Xu hướng tương lai: RL và Dữ liệu Tổng hợp (Synthetic Data)
Nhìn về phía trước, Reinforcement Learning đang tiến hóa với tốc độ chóng mặt, và xu hướng nổi bật nhất chính là sự kết hợp với Dữ liệu tổng hợp (Synthetic Data) và Môi trường giả lập (Simulation).
Bởi vì việc học thử-sai trong thế giới thực là quá đắt đỏ và nguy hiểm (bạn không thể cho một chiếc xe tự lái đâm vào tường nghìn lần để học), các nhà nghiên cứu đang tạo ra các môi trường ảo, sinh ra bằng dữ liệu tổng hợp.
-
Sim-to-Real (Từ giả lập ra thực tế): AI sẽ được huấn luyện hàng tỷ vòng lặp trong một “Ma trận” (Matrix) ảo với các tình huống vật lý được mô phỏng y hệt thực tế. Khi đã thuần thục, mô hình này mới được tải xuống robot hoặc xe tự lái ngoài đời thực.
-
Offline RL: Cho phép Agent học từ các bản ghi lịch sử tương tác cũ có sẵn thay vì phải tương tác trực tiếp với môi trường từ con số 0, giúp tiết kiệm chi phí tính toán đáng kể.
-
Multi-Agent RL (Học tăng cường đa tác tử): Nhiều Agent cùng học cách hợp tác hoặc cạnh tranh với nhau trong cùng một môi trường, mở ra cơ hội giải quyết các bài toán vĩ mô như mô phỏng nền kinh tế hay logistics toàn cầu.
Tóm lại
Reinforcement Learning là một trong những nhánh hấp dẫn và mang tính nền tảng nhất hướng tới Trí tuệ Nhân tạo Tổng quát (AGI – Artificial General Intelligence). Thay vì chỉ nhận diện khuôn mẫu, RL dạy máy móc cách suy nghĩ dài hạn, lập kế hoạch và sinh tồn trong một thế giới đầy biến động. Khi sức mạnh tính toán tăng lên và các môi trường giả lập ngày càng chân thực, RL hứa hẹn sẽ mang đến những hệ thống AI tự chủ vượt ngoài sức tưởng tượng của chúng ta.
Bài viết liên quan
- Khám phá Omniverse: 3 quy trình giúp cải thiện độ chính xác của Vision AI Agent với dữ liệu tổng hợp và fine-tuning
- NVIDIA Blueprint là gì?
- Tối hậu thư 34 tỷ USD: Vì sao Physical AI sẽ định đoạt ranh giới sinh tử của chuỗi cung ứng trong 24 tháng tới?
- Tại sao các thương hiệu xa xỉ đang rời bỏ Gen AI để chuyển sang Digital Twins?
- 90% nhà máy sẽ bị loại khỏi cuộc chơi: Physical AI đang thiết lập lại luật sản xuất toàn cầu