
Việc phát hành MiniMax M2.7 bổ sung các cải tiến cho mô hình MiniMax M2.5 phổ biến, được xây dựng cho dây nịt tác nhân và các trường hợp sử dụng phức tạp khác trong các lĩnh vực như lý luận, quy trình nghiên cứu ML, phần mềm, kỹ thuật và công việc văn phòng. Bản phát hành trọng số mở của MiniMax M2.7 hiện có sẵn thông qua NVIDIA và trên hệ sinh thái suy luận nguồn mở.
Dòng MiniMax M2 rất thưa thớt mixture of experts (MoE) dòng mô hình được thiết kế để mang lại hiệu quả và năng lực. Thiết kế MoE giữ chi phí suy luận thấp trong khi vẫn giữ được toàn bộ dung lượng của mô hình tham số 230B. Nó sử dụng khả năng tự chú ý nhân quả nhiều đầu được tăng cường bằng Nhúng vị trí quay (RoPE) và Chuẩn hóa bình phương trung bình gốc khóa truy vấn (QK RMSNorm) để đào tạo ổn định trên quy mô lớn. Cơ chế định tuyến chuyên gia top-k đảm bảo rằng chỉ những chuyên gia có liên quan nhất mới kích hoạt cho bất kỳ đầu vào nhất định nào, giữ chi phí suy luận thấp mặc dù tổng số tham số lớn của mô hình. Kết quả là một kiến trúc được điều chỉnh để vượt trội trong các thách thức mã hóa và các nhiệm vụ tác nhân phức tạp.
| MiniMax M2.7 | |
| Phương thức | Ngôn ngữ |
| Tổng số tham số | 230B |
| Tham số hoạt động | 10B |
| Tỷ lệ kích hoạt | 4,3% |
| Độ dài ngữ cảnh đầu vào | 200K |
| Thông tin cấu hình bổ sung | |
| Chuyên gia | 256 Local experts |
| Các chuyên gia đã kích hoạt mỗi token | 8 |
| Lớp | 62 |
Bảng 1. MiniMax M2.7, một mô hình MoE văn bản với các tham số 230B, 10B hoạt động trên mỗi mã thông báo, 256 chuyên gia và độ dài ngữ cảnh 200K
Xây dựng các đại lý hoạt động lâu dài với NVIDIA NemoClaw
NVIDIA NemoClaw là một ngăn xếp tham chiếu nguồn mở giúp đơn giản hóa việc chạy các trợ lý luôn bật OpenClaw an toàn hơn, với một lệnh duy nhất. Nó cài đặt các NVIDIA OpenShell runtime, một môi trường an toàn để chạy các tác nhân tự trị với các điểm cuối hoặc các mô hình mở như M2.7. Các nhà phát triển có thể bắt đầu ngay hôm nay với điều này có thể khởi chạy bằng một cú nhấp chuột để cung cấp một môi trường với OpenClaw và OpenShell trên NVIDIA Brev nền tảng GPU Cloud AI.
environment with OpenClaw and OpenShell on the NVIDIA Brev cloud AI GPU platform.
Video 1. Hướng dẫn từng bước để chạy MiniMax M2.7 với NVIDIA NemoClaw trên điểm cuối đám mây
Tối ưu hóa suy luận với các open source frameworks
Để tối đa hóa hiệu suất cho loạt mô hình MiniMax M2, NVIDIA đã hợp tác với cộng đồng Open source để tích hợp các hạt nhân hiệu suất cao vào vLLM và SGLang. Những tối ưu hóa này đặc biệt nhắm đến nhu cầu kiến trúc của các mô hình MoE quy mô lớn:
- QK RMS Norm Kernel: Tối ưu hóa này kết hợp các hoạt động tính toán và truyền thông thành một hạt nhân duy nhất để chuẩn hóa truy vấn và khóa cùng nhau. Hạt nhân có thể chồng chéo tốt hơn trong tính toán và giao tiếp, giảm chi phí khởi chạy hạt nhân và đọc/ghi bộ nhớ, đồng thời cải thiện hiệu suất suy luận.
- FP8 MoE: Tích hợp hạt nhân mô-đun NVIDIA TensorRT-LLM FP8 MoE. Hạt nhân được tối ưu hóa tốt này đặc biệt nhắm mục tiêu vào các mô hình MoE, thúc đẩy hiệu suất tổng thể từ đầu đến cuối.
Sau đây là kết quả vLLM trên thiết lập GPU NVIDIA Blackwell Ultra với bộ dữ liệu ISL/OSL 1K/1K. Hai tối ưu hóa đã mang lại sự cải thiện thông lượng lên tới 2,5 lần trong 1 tháng.
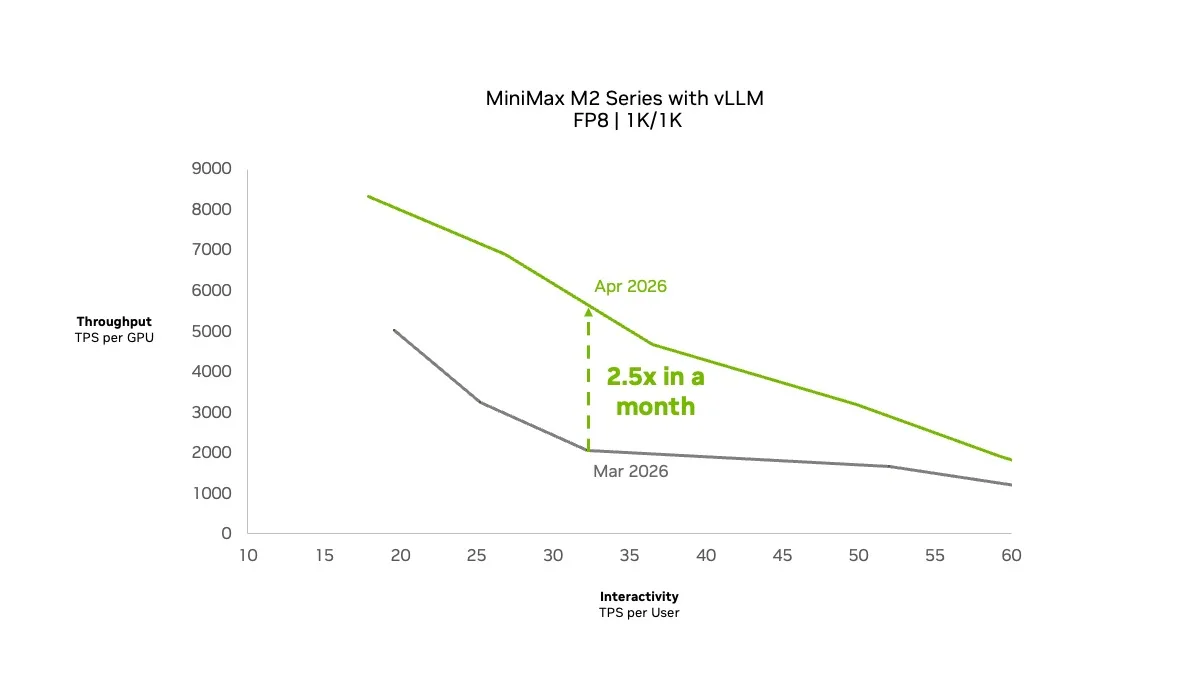 Hình 1. Đường cong Pareto tương tác thông lượng cho dòng MiniMax M2 với vLLM
Hình 1. Đường cong Pareto tương tác thông lượng cho dòng MiniMax M2 với vLLM
Hình 2 cho thấy kết quả SGLang trên GPU NVIDIA Blackwell Ultra, sử dụng bộ dữ liệu ISL/OSL 1K/1K. Hai tối ưu hóa đã mang lại sự cải thiện thông lượng lên tới 2,7 lần trong 1 tháng.
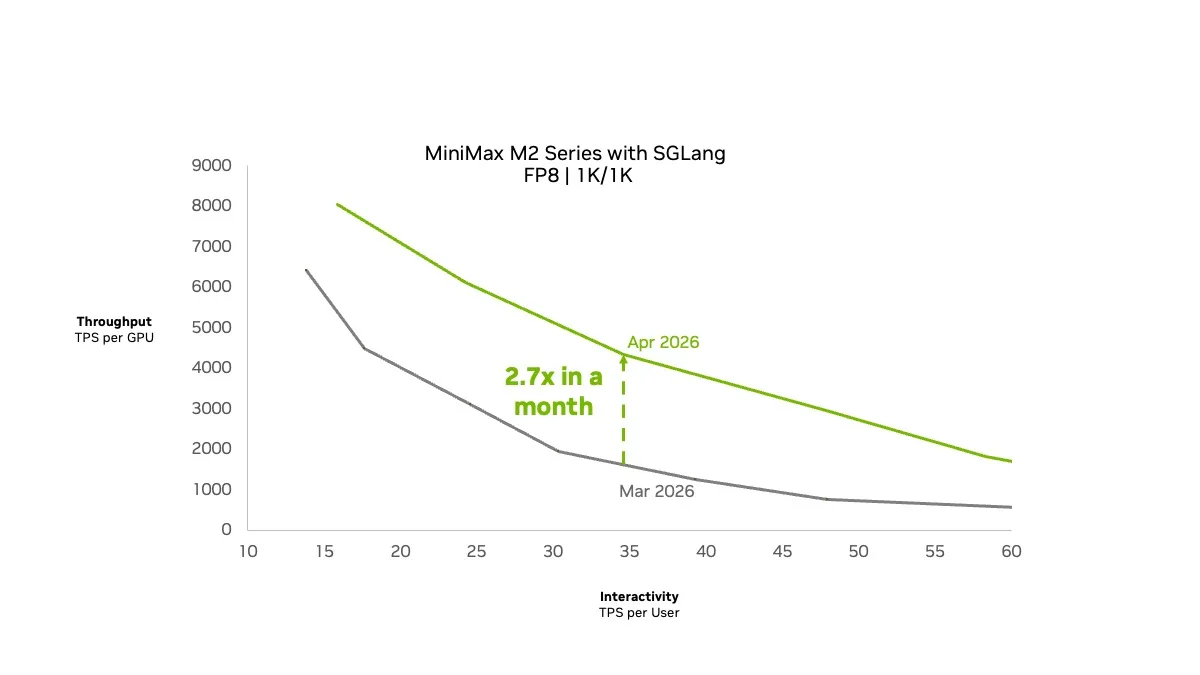 Hình 2. Đường cong Pareto tương tác thông lượng cho dòng MiniMax M2 với SGLang
Hình 2. Đường cong Pareto tương tác thông lượng cho dòng MiniMax M2 với SGLang
Triển khai với vLLM
Khi triển khai các mô hình với khung phục vụ vLLM, hãy sử dụng các hướng dẫn sau. Để biết thêm thông tin, xem các hướng dẫn vLLM.
| $ vllm serve MiniMaxAI/MiniMax-M2.7 \ –tensor-parallel-size 4 \ –tool-call-parser minimax_m2 \ –reasoning-parser minimax_m2_append_think \ –enable-auto-tool-choice \ –trust-remote-code \ –enable-expert-parallel |
Triển khai với SGLang
Người dùng triển khai các mô hình với khung phục vụ SGLang có thể sử dụng các hướng dẫn sau. Xem các Tài liệu SGLang để biết thêm thông tin và tùy chọn cấu hình.
| $ sglang serve \ –model-path MiniMaxAI/MiniMax-M2.7 \ –tp-size 4 \ –trust-remote-code \ –disable-radix-cache \ –max-running-requests 512 \ –mem-fraction-static 0.85 \ –cuda-graph-max-bs 512 \ –kv-cache-dtype fp8_e4m3 \ –quantization fp8 \ –stream-interval 10 \ –reasoning-parser=minimax-append-think \ –dtype bfloat16 \ –moe-runner-backend flashinfer_trtllm_routed \ –fp8-gemm-backend flashinfer_trtllm \ –enable-flashinfer-allreduce-fusion \ –scheduler-recv-interval 10 |
Xây dựng với các điểm cuối NVIDIA
Bắt đầu Xây dựng với MiniMax M2.7 thông qua các điểm cuối được tăng tốc GPU‑ miễn phí được lưu trữ trên GPU NVIDIA. Nhanh chóng kiểm tra lời nhắc trong trình duyệt trên build.nvidia.com và đánh giá hiệu suất bằng dữ liệu của riêng bạn. Quy mô để sản xuất với NVIDIA NIM—được tối ưu hóa, chứa các dịch vụ vi mô suy luận, on‑prem có thể triển khai, trên đám mây hoặc kết hợp.
Đào tạo sau với NVIDIA NeMo Framework
Để tinh chỉnh MiniMax M2.7, hãy sử dụng NVIDIA nguồn mở Thư viện NeMo AutoModel, một phần của Khung NVIDIA NeMo, với Công thức M2.7 và tài liệu về các điểm kiểm tra mới nhất có sẵn trên Hugging Face. Người dùng có thể thực hiện học tăng cường trên MiniMax M2.7 bằng cách sử dụng dữ liệu mà họ lựa chọn và NeMo RL thư viện, với các công thức dựng sẵn ( 8K sequence, 16K sequence) và tài liệu tham khảo đường cong xác nhận độ chính xác“.
Bắt đầu với MiniMax M2.7
Từ việc triển khai trung tâm dữ liệu trên NVIDIA Blackwell đến dịch vụ vi mô NVIDIA NIM dành cho doanh nghiệp được quản lý hoàn toàn cho đến tinh chỉnh, NVIDIA cung cấp các giải pháp để bạn tích hợp MiniMax M2.7. Để bắt đầu, hãy xem trang MiniMax M2.7 trên HuggingFace hoặc trên build.nvidia.com“.
Bài viết liên quan
- Multi-Agent Intelligent Warehouse: Tương lai của ngành quản lý kho vận
- NVIDIA Agentic Commerce: Kiến trúc Microservices kết hợp Agentic Workflow
- NVIDIA Nemotron 3 Nano Omni hỗ trợ suy luận tác nhân đa phương thức trong một mô hình mở hiệu quả duy nhất.
- Ollama hay vLLM – Giải pháp nào phù hợp hơn với môi trường triển khai của bạn?
- NVIDIA Ising giới thiệu các quy trình làm việc hỗ trợ bởi AI để xây dựng hệ thống máy tính lượng tử có khả năng chịu lỗi