
Hội nghị Công nghệ GPU của NVIDIA đã trở lại San Jose năm nay với nguồn năng lượng của một công ty nhận thức rõ mình đang ở trung tâm của một trong những sự chuyển đổi công nghệ lớn nhất trong lịch sử. Jensen Huang đã lên sân khấu để trình bày mọi thứ từ kiến trúc chip và kinh tế suy luận đến các khung phần mềm mã nguồn mở và robot vật lý — một phạm vi rất rộng cho một bài phát biểu quan trọng.
Tại NTC, chúng tôi luôn theo dõi sát sao GTC mỗi năm vì những thông báo của NVIDIA sẽ trực tiếp định hình cơ sở hạ tầng AI mà khách hàng của chúng tôi đang xây dựng. Bản tóm tắt này sẽ phân tích những điểm nổi bật và ý nghĩa của chúng đối với các tổ chức đang đầu tư vào AI hiện nay.
CUDA tròn 20 tuổi. Nền tảng đằng sau hệ sinh thái của NVIDIA.
CUDA, nền tảng điện toán song song của NVIDIA, đã tròn 20 tuổi trong năm nay. Jensen đã sử dụng dịp kỷ niệm này như một bộ khung cho phần còn lại của bài phát biểu, hầu hết những gì NVIDIA đã xây dựng và tiếp tục xây dựng đều bắt nguồn từ nền tảng này.
Một vài điều đáng chú ý về tình hình hiện tại của CUDA:
- Số lượng hiện có: Hàng trăm triệu GPU hỗ trợ CUDA đang được triển khai trên mọi nhà cung cấp dịch vụ đám mây lớn, nhà sản xuất thiết bị gốc (OEM) và các ngành dọc khác nhau.
- Khả năng tương thích ngược: NVIDIA tiếp tục tối ưu hóa bộ phần mềm của mình trên các kiến trúc cũ hơn, có nghĩa là phần cứng đã triển khai sẽ được cải thiện hiệu năng theo thời gian mà không cần thay thế.
- Quy mô hệ sinh thái: Hàng ngàn thư viện, framework và công cụ được xây dựng trên nền tảng CUDA, với hàng trăm ngàn dự án công cộng phụ thuộc vào nó.
- Số lượt tải xuống thư viện đang tăng nhanh hơn bao giờ hết, phản ánh phạm vi công việc ngày càng mở rộng mà CUDA hiện hỗ trợ, từ điện toán hiệu năng cao truyền thống đến huấn luyện AI, suy luận và xử lý dữ liệu.
Điểm mấu chốt mà Jensen nhấn mạnh là giá trị của nền tảng NVIDIA không chỉ nằm ở phần cứng, mà còn ở hiệu ứng tích lũy của hai thập kỷ phần mềm, công cụ và sự chấp nhận của nhà phát triển được xây dựng trên nền tảng đó. Chính nền tảng vững chắc này là lý do tại sao các tác vụ chạy trên phần cứng NVIDIA cũ hơn, như Ampere, vẫn đang chứng kiến giá dịch vụ đám mây tăng cao mặc dù đã lỗi thời nhiều thế hệ.
Cột mốc với điện toán suy luận
Trong phần lớn lịch sử của NVIDIA, việc huấn luyện mô hình là trọng tâm và chiếm ưu thế trong khối lượng công việc AI. Tuy nhiên, gần đây điều đó đã thay đổi. Jensen lập luận rằng suy luận hiện là động lực chính thúc đẩy nhu cầu tính toán và nền kinh tế của các doanh nghiệp AI ngày càng được định hình bởi hiệu quả tạo ra token. Càng nhiều token được lưu trữ trong bộ nhớ, bạn càng xử lý các token này nhanh hơn, và càng tạo ra token nhanh hơn, thì AI càng thông minh hơn.
Ba diễn biến trong hai năm qua đã thúc đẩy sự thay đổi này:
- Trí tuệ nhân tạo tạo sinh (2022–2023): Các mô hình chuyển từ nhận thức và phân loại sang tạo nội dung, làm thay đổi căn bản cách thức sử dụng sức mạnh tính toán.
- Mô hình suy luận (2024): Các mô hình như o1 và o3 của OpenAI đã giới thiệu quá trình xử lý chuỗi suy nghĩ — mô hình “suy nghĩ” trước khi phản hồi, điều này làm tăng đáng kể việc sử dụng cả token đầu vào và đầu ra cho mỗi truy vấn.
- Trí tuệ nhân tạo tác động (2024–2025): Các công cụ như Claude Code cho phép các mô hình tự động đọc tệp, viết và kiểm thử mã, cũng như lặp lại các tác vụ. Điều này đã chuyển AI từ việc trả lời câu hỏi sang hoàn thành các công việc nhiều bước, làm tăng thêm nhu cầu tính toán.
Nguồn: NVIDIA
Hiệu ứng tích lũy: Jensen ước tính rằng nhu cầu tính toán cho mỗi khối lượng công việc AI đã tăng khoảng 10.000 lần trong hai năm, trong khi mức sử dụng tổng thể đã tăng khoảng 100 lần. Điều này ngụ ý rằng tổng nhu cầu tính toán lớn hơn khoảng 1 triệu lần so với hai năm trước.
Jensen đã diễn giải sự thay đổi này bằng một khái niệm đáng để hiểu: trung tâm dữ liệu AI như một nhà máy sản xuất token.
- Mỗi trung tâm dữ liệu đều có một mức công suất tối đa cố định; một khi đã được xây dựng, giới hạn đó sẽ không thay đổi.
- Do đó, chỉ số quan trọng đối với người vận hành AI là số token trên mỗi watt , hay nói cách khác là lượng đầu ra AI hữu ích mà bạn có thể tạo ra từ ngân sách năng lượng hiện có.
- Yếu tố thứ hai cũng quan trọng không kém: tốc độ xử lý token (độ trễ trên mỗi lần suy luận), yếu tố này quyết định bạn có thể cung cấp những cấp độ dịch vụ nào và ở mức giá nào.
- Tốc độ xử lý token cao hơn cho phép tạo ra các mô hình lớn hơn, cửa sổ ngữ cảnh dài hơn và khả năng suy luận đa dạng hơn, tất cả những điều này đều dẫn đến mức giá cao hơn.
Cách tiếp cận này có tác động trực tiếp đến các quyết định về cơ sở hạ tầng. Kiến trúc bạn triển khai sẽ quyết định thông lượng và tốc độ xử lý token ở mức công suất cố định, điều này liên quan trực tiếp đến tiềm năng doanh thu. Quan điểm của Jensen là đây là cách đánh giá lợi tức đầu tư (ROI) của cơ sở hạ tầng AI trong tương lai, chứ không chỉ dựa trên thông số kỹ thuật tính toán thô.
Vera Rubin: Nền tảng AI thế hệ tiếp theo của NVIDIA
Blackwell hiện đang được sản xuất và vận chuyển với số lượng lớn, nhưng NVIDIA đã sử dụng GTC để chính thức giới thiệu Vera Rubin, nền tảng thế hệ tiếp theo được thiết kế dựa trên nhu cầu của các tác vụ AI dựa trên tác nhân. Hệ thống Vera Rubin đầu tiên đã đi vào hoạt động tại Microsoft Azure.

NVIDIA Vera Rubin NVL72
Vera Rubin được thiết kế như một nền tảng hệ thống hoàn chỉnh, chứ không chỉ là một GPU mới. Thông số kỹ thuật chính:
- 3,6 exaflops tính toán mỗi rack
- Băng thông NVLink toàn diện 260 TB/s
- 72 GPU được kết nối thông qua NVLink thế hệ thứ sáu.
- Hệ thống làm mát hoàn toàn bằng chất lỏng, bao gồm cả cơ sở hạ tầng chuyển mạch NVLink.
- Làm mát bằng nước nóng ở 45°C, giảm chi phí làm mát trung tâm dữ liệu.
NVIDIA Groq 3 LPX
Một trong những thông báo quan trọng hơn cả là việc NVIDIA mua lại nhóm phát triển chip Groq và tích hợp Groq 3 LPX vào nền tảng Vera Rubin. Hai chip này đảm nhiệm những vai trò hoàn toàn khác nhau:
- GPU Vera Rubin: Dung lượng bộ nhớ cao (288GB mỗi chip), được tối ưu hóa cho các tác vụ đòi hỏi thông lượng cao và bộ nhớ đệm KV.
- Groq 3 LPX: Bộ nhớ SRAM khổng lồ tích hợp trên chip, được biên dịch tĩnh, luồng dữ liệu xác định được tối ưu hóa cho việc tạo (giải mã) mã thông báo độ trễ thấp.
Phần mềm điều phối suy luận của NVIDIA, Dynamo, phân chia khối lượng công việc giữa chúng: Vera Rubin xử lý phần điền trước và chú ý của quá trình suy luận, trong khi Groq xử lý giai đoạn tạo mã thông báo (giải mã truyền tiến). Kết quả là hiệu suất trên mỗi megawatt cao hơn gấp 35 lần so với chỉ chạy Vera Rubin đối với các khối lượng công việc nhạy cảm về độ trễ.
NVIDIA Rubin Ultra
Ngoài cấu hình Vera Rubin tiêu chuẩn, NVIDIA cũng đã công bố Rubin Ultra, một biến thể có mật độ cao hơn sử dụng thiết kế giá đỡ mới có tên Kyber:
- Kết nối 144 GPU trong một miền NVLink duy nhất (so với 72 trong Vera Rubin tiêu chuẩn)
- Các nút tính toán được lắp đặt theo chiều dọc và kết nối với nhau thông qua một bảng mạch trung gian thay vì cáp đồng.
- Cho phép mở rộng quy mô NVLink vượt xa khả năng của các kết nối bằng đồng.
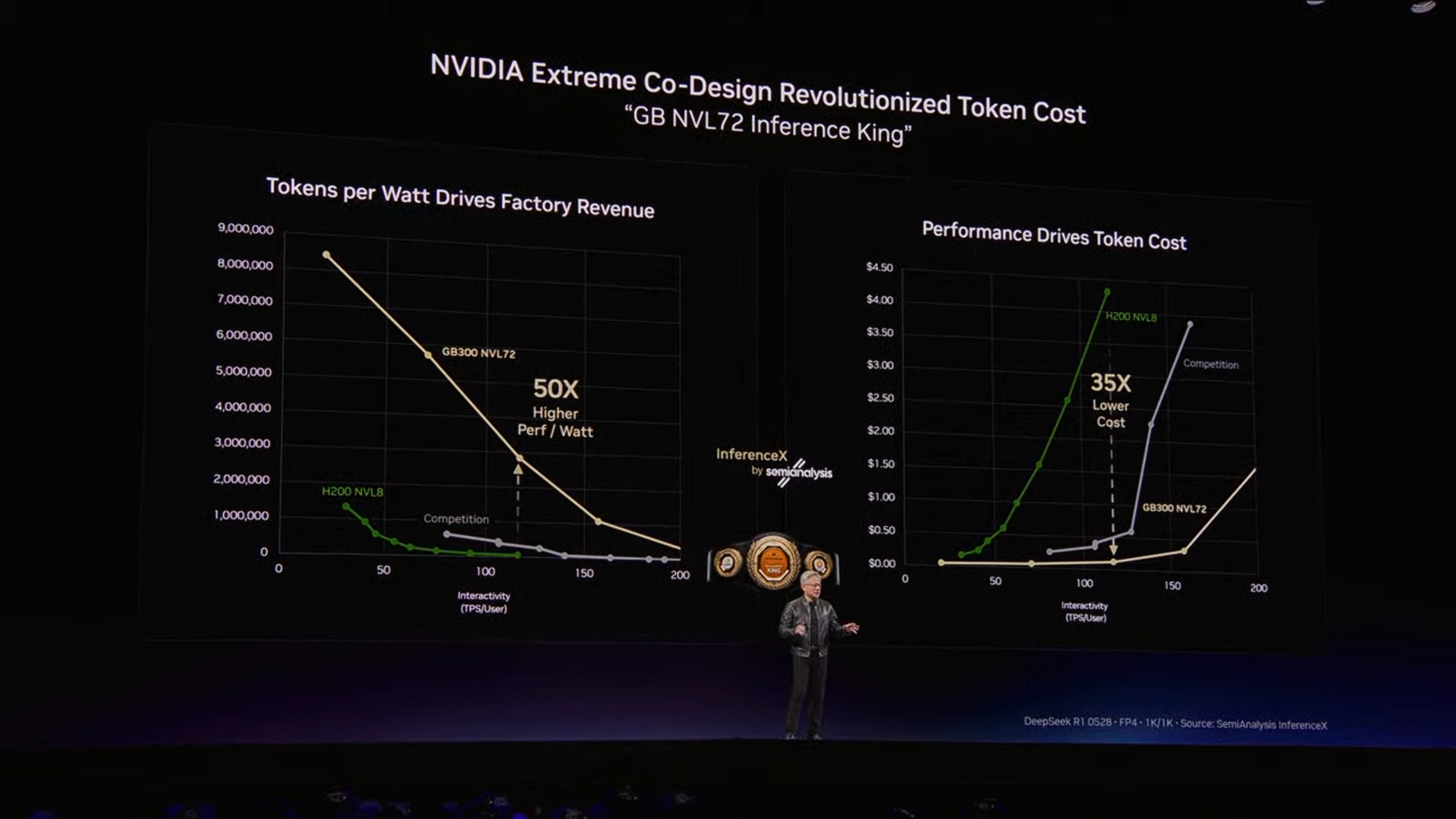
Hai chỉ số này, thông lượng và tốc độ token, phản ánh trực tiếp tiềm năng doanh thu của một hệ thống cơ sở hạ tầng cụ thể. NVIDIA đã trình bày các so sánh giữa các thế hệ với mức công suất cố định 1 gigawatt:
- Blackwell đã mang lại sự cải tiến đáng kể so với Hopper, và Vera Rubin được dự đoán sẽ mang lại tiềm năng doanh thu trên mỗi gigawatt cao hơn khoảng 5 lần so với Blackwell.
- Kiến trúc hệ thống bạn triển khai sẽ quyết định công suất đầu ra của bạn ở mức công suất cố định, từ đó đặt ra giới hạn tối đa cho lượng điện bạn có thể tạo ra từ mức công suất 1 gigawatt đó.
Tăng tốc quá trình huấn luyện AI trên NVIDIA DGX B300
Việc huấn luyện các mô hình AI trên các tập dữ liệu khổng lồ có thể được tăng tốc theo cấp số nhân với một hệ thống phù hợp. Đó không chỉ là một máy tính hiệu năng cao, mà còn là một công cụ để thúc đẩy và tăng tốc nghiên cứu của bạn. Triển khai nhiều node NVIDIA DGX để tăng khả năng mở rộng. DGX B300 hiện đã sẵn sàng để đặt hàng bởi Nhất Tiến Chung!


Vera Rubin (đương nhiệm/nhiệm kỳ ngắn hạn)
Sẽ có hai cấu hình khác nhau:
- Vera Rubin tiêu chuẩn (Kyber rack): NVLink 144 với cáp đồng, có khả năng mở rộng.
- Vera Rubin hợp tác với Oberon: NVLink 72 cộng với khả năng mở rộng quang học, có thể nâng cấp lên NVLink 576 thông qua các module quang học đóng gói sẵn và bộ chuyển mạch Spectrum 6.
Cả hai đều đang trong quá trình sản xuất. NVIDIA cũng lưu ý rằng CPU Vera hiện đang được bán như một sản phẩm độc lập và nhận được sự quan tâm rất lớn.
Rubin Ultra (thế hệ tiếp theo)
- Thiết kế giá đỡ Kyber mới hỗ trợ 144 GPU trong một miền NVLink duy nhất.
- Giới thiệu chip Groq LP 35, tích hợp cấu trúc tính toán MVRP của NVIDIA để mang lại hiệu năng cao hơn.
- Các module quang học được đóng gói chung, phù hợp cho cả mạng mở rộng theo chiều dọc (Scale-up) và chiều ngang (Scale-out).
Feynman (thế hệ tương lai)
- Kiến trúc GPU mới kết hợp với Groq LP 40
- CPU mới có tên Rosa (Rosalind), kết hợp với BlueField 5 và ConnectX-10.
- Cả đồng và quang học đóng gói đồng đều hỗ trợ mở rộng quy mô.
- Tiếp tục chu kỳ thiết kế kiến trúc hàng năm mà NVIDIA đã cam kết.
Các linh kiện chính được vận chuyển qua nhiều thế hệ.
- CPU Vera: Được thiết kế cho hiệu năng đơn luồng cao và các tác vụ xử lý dữ liệu, sử dụng bộ nhớ LPDDR5 để đạt hiệu quả tối ưu. Hướng đến các tác vụ điều phối hệ thống và sử dụng công cụ.
- BlueField 4: DPU lưu trữ và mạng mới, với 100% các nhà cung cấp thiết bị lưu trữ lớn cam kết sử dụng nền tảng này.
- Spectrum X với module quang tích hợp: Bộ chuyển mạch Ethernet CPO đầu tiên trên thế giới, đang được sản xuất hàng loạt.
- ConnectX 9: Hệ thống mạng được nâng cấp kết hợp với CPU Vera.
Quan điểm tổng quát hơn của NVIDIA về lộ trình phát triển là nền tảng này được thiết kế để đảm bảo tính liên tục. Mỗi thế hệ đều duy trì khả năng tương thích ngược, và quá trình chuyển đổi từ kết nối đồng sang kết nối quang sẽ diễn ra dần dần trên cả mô hình Scale-up và Scale-out chứ không phải là một sự chuyển đổi đột ngột.
Các nhà máy AI và việc ứng dụng trong công nghiệp
Một chủ đề xuyên suốt bài phát biểu chính là sự mở rộng của NVIDIA vượt ra ngoài lĩnh vực chip và hệ thống, tiến vào lớp cơ sở hạ tầng bao quanh chúng. Hai lĩnh vực phản ánh điều này rõ ràng nhất là: các công cụ mà NVIDIA đã xây dựng để thiết kế và vận hành các nhà máy AI, và phạm vi rộng lớn của các ngành công nghiệp hiện đang xây dựng trên nền tảng của NVIDIA.
NVIDIA DSX: Nền tảng mô hình song sinh kỹ thuật số cho các nhà máy trí tuệ nhân tạo
Khi các nhà máy AI ngày càng phát triển về quy mô và độ phức tạp, NVIDIA đã giới thiệu DSX, một nền tảng mô phỏng kỹ thuật số dựa trên Omniverse được xây dựng để thiết kế, vận hành thử và vận hành cơ sở hạ tầng AI quy mô lớn. Ý tưởng cốt lõi là các nhà cung cấp công nghệ khác nhau tham gia vào việc xây dựng trung tâm dữ liệu, hệ thống làm mát, điện năng, mạng lưới, điện toán, cần một môi trường chung để cùng thiết kế trước khi bất cứ thứ gì được xây dựng về mặt vật lý.
DSX bao quát toàn bộ vòng đời của cơ sở:
- Thiết kế và mô phỏng: Mô phỏng nhiệt, điện, cơ khí và mạng bằng các công cụ từ các đối tác bao gồm Siemens, Cadence và Dassault Systemes.
- Vận hành thử nghiệm ảo: Các công trình có thể được kiểm định kỹ thuật số thông qua Procore trước khi bắt đầu xây dựng, giảm thiểu sự chậm trễ.
- Vận hành thực tế: Khi một cơ sở đi vào hoạt động, mô hình kỹ thuật số song sinh trở thành công cụ vận hành. Các tác nhân AI giám sát hệ thống làm mát, hệ thống điện và tín hiệu lưới điện trong thời gian thực, cung cấp dữ liệu cho hệ thống Max-Q của NVIDIA, hệ thống này tự động điều chỉnh khối lượng công việc tính toán để tối đa hóa thông lượng token trong giới hạn năng lượng cho phép.
Lý lẽ cơ bản là ở quy mô gigawatt, sự thiếu hiệu quả trong thiết kế và vận hành một cơ sở sẽ trực tiếp dẫn đến mất sản lượng token và doanh thu. NVIDIA ước tính rằng hiệu quả có thể phục hồi được giảm khoảng một nửa trong một hệ thống nhà máy AI điển hình.
Các ngành dọc
Jensen đã đề cập đến nhiều ngành công nghiệp hiện đang xây dựng trên cơ sở hạ tầng của NVIDIA, mỗi ngành đều dựa vào thư viện Cuda-X chuyên dụng thay vì chỉ dựa vào khả năng tính toán đa năng:
- Dịch vụ tài chính: Ngành có số lượng đại diện tham gia lớn nhất tại GTC năm nay. Giao dịch thuật toán đang chuyển từ các phương pháp định lượng truyền thống sang các mô hình học sâu có khả năng phát hiện các mẫu trên các tập dữ liệu lớn mà không cần đến sự can thiệp của con người.
- Chăm sóc sức khỏe: Khám phá thuốc, các tác nhân AI chẩn đoán và robot AI vật lý cho môi trường lâm sàng. NVIDIA cho rằng đây là “thời điểm ChatGPT” của họ về tốc độ áp dụng.
- Ngành ô tô: Các nền tảng xe tự lái và robotaxi, được trình bày chi tiết hơn trong phần robot bên dưới.
- Viễn thông: Nền tảng Aerial của NVIDIA cho phép AI-RAN, chuyển đổi các trạm gốc truyền thống thành cơ sở hạ tầng suy luận AI ở vùng biên. Quan hệ đối tác tích cực với Nokia và T-Mobile.
- Công nghiệp và sản xuất: Triển khai robot dựa trên mô phỏng cho tự động hóa nhà máy, tích hợp với các nhà cung cấp tự động hóa công nghiệp hàng đầu.
- Truyền thông và giải trí: Trí tuệ nhân tạo thời gian thực dành cho phát sóng, phiên dịch trực tiếp và trò chơi, được xây dựng trên nền tảng Holoscan của NVIDIA.
- Ngành bán lẻ và hàng tiêu dùng nhanh: Tối ưu hóa chuỗi cung ứng và ứng dụng trí tuệ nhân tạo (AI) hỗ trợ khách hàng trong ngành công nghiệp trị giá 35 nghìn tỷ đô la.
- Điện toán lượng tử: 35 công ty tại GTC đang xây dựng các hệ thống GPU-lượng tử lai sử dụng nền tảng cuQuantum của NVIDIA.
Sự đa dạng này phản ánh một mô hình nhất quán trong cách NVIDIA tiếp cận các lĩnh vực chuyên biệt. Thay vì định vị GPU như các bộ tăng tốc đa năng, mỗi lĩnh vực đều có các thư viện chuyên dụng, Cuda-X, để giải quyết các vấn đề thuật toán cụ thể trong lĩnh vực đó. Jensen mô tả các thư viện này là cốt lõi tạo nên sự khác biệt lâu dài của nền tảng NVIDIA.
OpenClaw và Bộ khung Trí tuệ Nhân tạo Tác nhân
Một trong những thông báo quan trọng nhất tại GTC là việc NVIDIA hỗ trợ OpenClaw, một khung phần mềm trí tuệ nhân tạo (AI) mã nguồn mở đã được áp dụng nhanh chóng một cách bất thường kể từ khi ra mắt. Jensen mô tả đây là dự án mã nguồn mở được áp dụng nhanh nhất trong lịch sử, vượt qua số lượng người dùng Linux trong 30 năm chỉ trong vài tuần.
OpenClaw là gì?
OpenClaw hoạt động như một hệ điều hành dành cho các tác nhân trí tuệ nhân tạo (AI Agent). Các thành phần của nó tương tự như những gì một hệ điều hành truyền thống cung cấp:
- Quản lý tài nguyên trên các hệ thống tệp, công cụ và mô hình ngôn ngữ.
- Lập lịch tác vụ và thực thi tác vụ định kỳ (cron job).
- Phân tích vấn đề: chia nhỏ yêu cầu thành các bước tuần tự.
- Tạo tác nhân phụ cho các luồng công việc song song
- Đầu vào/đầu ra đa phương thức bao gồm văn bản, giọng nói và tin nhắn
Kết quả thực tiễn là bất kỳ ai cũng có thể khởi tạo một tác nhân AI hoạt động bằng cách chạy một lệnh duy nhất. Tác nhân này kết nối với mô hình ngôn ngữ, nhận nhiệm vụ và thực hiện nó một cách tự động trên các công cụ và hệ thống khác nhau.
Khả năng giúp OpenClaw trở nên hữu ích cũng tạo ra rủi ro bảo mật trong môi trường doanh nghiệp. Một hệ thống tác nhân có quyền truy cập vào cơ sở hạ tầng nội bộ có thể đọc dữ liệu nhạy cảm, thực thi mã và giao tiếp với bên ngoài. NVIDIA đã hợp tác với tác giả của OpenClaw để giải quyết vấn đề này bằng một thiết kế tham chiếu sẵn sàng cho doanh nghiệp có tên NeMo Claw, bổ sung thêm:
- Một công cụ quản lý chính sách để điều chỉnh hành vi của tác nhân.
- Các rào chắn an toàn mạng.
- Bộ định tuyến bảo mật nhằm ngăn chặn việc rò rỉ dữ liệu trái phép.
- Các điểm kết nối tích hợp cho các hệ thống chính sách SaaS doanh nghiệp hiện có.
NeMoClaw có sẵn để tải xuống và triển khai, được thiết kế để kết nối với các công cụ quản lý chính sách mà các nhà cung cấp phần mềm doanh nghiệp hiện đang duy trì.
Theo Jensen, OpenClaw đại diện cho một bước ngoặt tương tự đối với phần mềm doanh nghiệp như Linux, HTML và Kubernetes đã từng đại diện trong các kỷ nguyên điện toán trước đây. Luận điểm rất đơn giản: cũng giống như mọi công ty cuối cùng đều cần một chiến lược Linux, một chiến lược web và một chiến lược điện toán đám mây, giờ đây mọi công ty đều cần một chiến lược trí tuệ nhân tạo (AI) mang tính tác nhân.
Mô hình biên giới mở cho mọi ngành công nghiệp
Cùng với các thông báo về phần cứng và cơ sở hạ tầng, NVIDIA đã nêu rõ vị thế của mình với tư cách là nhà đóng góp cho các mô hình AI mở. Thay vì một mô hình đa năng duy nhất, NVIDIA đang phát triển và phát hành sáu dòng mô hình chuyên biệt, mỗi dòng nhắm đến một lĩnh vực khác nhau.
- Nemotron: Mô hình ngôn ngữ bao gồm khả năng suy luận, hiểu biết hình ảnh, tạo lập tăng cường truy xuất, an toàn và giọng nói. Nemotron-3 Ultra được định vị là mô hình cơ bản để tinh chỉnh và triển khai AI độc lập. Nemotron-4 đang được phát triển tích cực.
- Cosmos: Mô hình nền tảng thế giới cho trí tuệ nhân tạo vật lý, tập trung vào việc tạo ra và hiểu các môi trường tổng hợp để huấn luyện robot và hệ thống tự hành.
- Alpamayo: Được mô tả là trí tuệ nhân tạo (AI) đầu tiên trên thế giới có khả năng suy luận dành cho xe tự lái. Nó xử lý việc ra quyết định trong thời gian thực, tường thuật các hành động lái xe và tuân theo chỉ dẫn.
- Groot: Mô hình nền tảng cho robot hình người đa năng và robot công nghiệp, bao gồm điều khiển toàn thân, thao tác và tạo chính sách.
- BioNeMo: Mô hình mở cho sinh học, hóa học và thiết kế phân tử, hướng đến khám phá thuốc và nghiên cứu khoa học sự sống.
- Earth2: Mô hình dự báo thời tiết và khí hậu dựa trên mô phỏng vật lý bằng trí tuệ nhân tạo.
Mỗi dòng sản phẩm đều được duy trì và cập nhật liên tục. NVIDIA coi việc đầu tư liên tục vào các mô hình này, chứ không phải bản thân các mô hình, là giá trị cốt lõi dành cho các tổ chức đang xây dựng hệ thống dựa trên chúng.
Một chủ đề xuyên suốt phần này của bài phát biểu chính là trí tuệ nhân tạo tự chủ, khả năng cho phép các quốc gia và tổ chức riêng lẻ xây dựng và vận hành các mô hình của riêng mình thay vì phụ thuộc vào một số ít nhà cung cấp lớn bên ngoài. Sáng kiến mô hình mở của NVIDIA, kết hợp với các tùy chọn cơ sở hạ tầng tại chỗ, được định vị là nền tảng kỹ thuật cho khả năng đó.
Robot và Trí tuệ nhân tạo vật lý
Jensen đã dành một phần đáng kể bài phát biểu chính cho lĩnh vực robot, coi đó là biên giới quan trọng tiếp theo của trí tuệ nhân tạo sau ngôn ngữ và các mô hình suy luận. Luận điểm cốt lõi là những khả năng đã cho phép trí tuệ nhân tạo hoạt động độc lập trong phần mềm – nhận thức, suy luận và hành động – giờ đây cần được mở rộng sang các hệ thống hoạt động trong thế giới vật lý.

NVIDIA cung cấp ba loại máy tính khác nhau dành cho việc phát triển robot:
- Máy tính huấn luyện: Dùng để phát triển và huấn luyện các mô hình trí tuệ nhân tạo robot trên quy mô lớn thông qua DGX Rubin.
- Máy tính mô phỏng: Dùng để tạo dữ liệu tổng hợp bằng Isaac Lab, mô phỏng vật lý Newton và mô hình thế giới Cosmos thông qua MGX và RTX PRO.
- Máy tính biên: Hệ thống tính toán tích hợp chạy bên trong robot thông qua Jetson và Thor.
Lớp mô phỏng đặc biệt quan trọng vì việc thu thập dữ liệu thực tế thôi là chưa đủ để huấn luyện robot vượt qua toàn bộ các trường hợp ngoại lệ mà chúng sẽ gặp phải trong quá trình triển khai.
Lập kế hoạch cơ sở hạ tầng AI cho kỷ nguyên suy luận
Hội nghị GTC 2026 đã khẳng định rằng sự chuyển dịch từ huấn luyện sang suy luận như là khối lượng công việc AI chủ đạo có những tác động thực sự đến cách đánh giá cơ sở hạ tầng. Số token trên mỗi watt và tốc độ token ở mức công suất cố định ngày càng trở thành các chỉ số quyết định khả năng cung cấp của một hệ thống. Khung đánh giá này nên được sử dụng để định hướng các quyết định về phần cứng hiện nay.
NVIDIA Blackwell là nền tảng phù hợp để triển khai ngay bây giờ. Nó đang được sản xuất hàng loạt, bộ phần mềm đã hoàn thiện và hệ sinh thái đã được thiết lập tốt. Vera Rubin đang được thử nghiệm thành công và sẽ sớm được phát hành rộng rãi, và lộ trình từ Rubin Ultra đến Feynman cho thấy nhịp độ phát triển kiến trúc hàng năm của NVIDIA không hề chậm lại. Lập kế hoạch dựa trên nhịp độ đó, thay vì chờ đợi, là cách tiếp cận thực tế hơn đối với hầu hết các kế hoạch triển khai.
Là nhà tích hợp giải pháp hạ tầng AI và là đối tác NPN cấp Elite của NVIDIA, Nhất Tiến Chung hợp tác với các tổ chức trong việc đưa ra quyết định về cơ sở hạ tầng. Từ máy trạm và máy chủ GPU, đến các triển khai quy mô rack-scale đầy đủ, đội ngũ của chúng tôi có thể giúp xác định cấu hình phù hợp với khối lượng công việc và ngân sách của bạn.
Bài viết liên quan
- Bức tranh AI toàn cầu nửa đầu 2026: Bước vào “siêu chu kỳ” vận hành thực chiến
- NVIDIA Nemotron 3 Ultra 550B: Đột Phá Kiến Trúc AI Tại Computex 2026
- NVIDIA khơi dậy cuộc cách mạng công nghiệp tiếp theo trong công việc tri thức với nền tảng phát triển tác nhân mở
- Tối hậu thư 34 tỷ USD: Vì sao Physical AI sẽ định đoạt ranh giới sinh tử của chuỗi cung ứng trong 24 tháng tới?
- Tương lai của AI: Mở và Độc quyền