
Trí tuệ nhân tạo đã bước vào giai đoạn công nghiệp.
Những hệ thống ban đầu chỉ thực hiện việc huấn luyện mô hình AI riêng lẻ và suy luận hướng đến con người, nay đã phát triển thành các nhà máy AI (AI Factory) hoạt động liên tục, không ngừng chuyển đổi năng lượng, phần cứng và dữ liệu thành trí tuệ ở quy mô lớn. Những nhà máy này hiện đang là nền tảng cho các ứng dụng tạo ra kế hoạch kinh doanh, phân tích thị trường, tiến hành nghiên cứu chuyên sâu và suy luận dựa trên khối lượng kiến thức khổng lồ.
Để cung cấp những khả năng này trên quy mô lớn, các nhà máy AI thế hệ tiếp theo phải xử lý hàng trăm nghìn token đầu vào để cung cấp ngữ cảnh dài cần thiết cho suy luận tác nhân, quy trình làm việc phức tạp và các đường dẫn đa phương thức, đồng thời duy trì suy luận thời gian thực trong điều kiện hạn chế về năng lượng, độ tin cậy, bảo mật, tốc độ triển khai và chi phí.
Nền tảng NVIDIA Vera Rubin được thiết kế đặc biệt cho thực tế mới này.
Thiết kế đồng bộ tối ưu là nền tảng của nền tảng Vera Rubin. GPU, CPU, mạng, bảo mật, phần mềm, cấp nguồn và làm mát được thiết kế cùng nhau như một hệ thống duy nhất thay vì được tối ưu hóa riêng lẻ. Bằng cách đó, nền tảng Vera Rubin coi trung tâm dữ liệu, chứ không phải một máy chủ GPU đơn lẻ, là đơn vị tính toán. Cách tiếp cận này thiết lập một nền tảng mới để tạo ra trí tuệ một cách hiệu quả, an toàn và có thể dự đoán được ở quy mô lớn. Nó đảm bảo hiệu suất và hiệu quả được duy trì trong các triển khai thực tế, chứ không chỉ trong các bài kiểm tra hiệu năng của từng thành phần riêng lẻ.
Ad
Bài phân tích kỹ thuật chuyên sâu này giải thích lý do tại sao các nhà máy AI cần một cách tiếp cận kiến trúc mới; cách NVIDIA Vera Rubin NVL72 hoạt động như một kiến trúc quy mô rack; và cách phần cứng, phần mềm và hệ thống của nền tảng Vera Rubin mang lại hiệu suất ổn định và chi phí thấp hơn trên mỗi token ở quy mô lớn.
Blog được tổ chức như sau:
- Vì sao các nhà máy AI cần một nền tảng mới : Sự chuyển đổi sang AI hoạt động liên tục, dựa trên lý luận và những hạn chế hiện đang xác định quy mô: sức mạnh, độ tin cậy, bảo mật và tốc độ triển khai.
- Hãy cùng tìm hiểu nền tảng NVIDIA Vera Rubin : Luận điểm về nền tảng quy mô rack và những đột phá cốt lõi cho phép sản xuất trí tuệ nhân tạo bền vững.
- Sáu chip mới, một siêu máy tính AI : Kiến trúc sáu chip và cách GPU, CPU, mạng và cơ sở hạ tầng hoạt động như một hệ thống tích hợp chặt chẽ.
- Từ chip đến hệ thống: Từ siêu chip NVIDIA Vera Rubin đến DGX SuperPOD : Cách Vera Rubin mở rộng quy mô từ siêu chip đến các cụm máy chủ và triển khai nhà máy AI quy mô NVIDIA DGX SuperPOD.
- Trải nghiệm phần mềm và nhà phát triển : Bộ phần mềm cho phép lập trình quy mô rack, từ NVIDIA CUDA và NVIDIA CUDA-X đến các framework huấn luyện và suy luận.
- Vận hành ở quy mô nhà máy AI : Các nền tảng sản xuất: vận hành, độ tin cậy, bảo mật, hiệu quả năng lượng và sự sẵn sàng của hệ sinh thái.
- Hiệu năng và hiệu quả ở quy mô lớn : Cách Vera Rubin chuyển đổi kiến trúc thành những lợi ích thực sự ở quy mô lớn, bao gồm giảm một phần tư số GPU cần thiết để huấn luyện, tăng thông lượng suy luận lên 10 lần và giảm chi phí trên mỗi token xuống 10 lần.
- Vì sao Vera Rubin là nền tảng nhà máy AI : Cách thiết kế đồng bộ tối ưu mang lại hiệu suất, chi phí và khả năng mở rộng có thể dự đoán được trong các triển khai thực tế.
1. Tại sao các nhà máy AI cần một nền tảng mới?
Các nhà máy AI khác biệt về cơ bản so với các trung tâm dữ liệu truyền thống. Thay vì phục vụ các yêu cầu gián đoạn do con người thực hiện, chúng hoạt động như các hệ thống sản xuất trí tuệ liên tục, nơi hiệu quả trong suy luận, xử lý ngữ cảnh và di chuyển dữ liệu, chứ không chỉ là khả năng tính toán tối đa của máy chủ, quyết định hiệu suất.
Các tác vụ AI hiện đại ngày càng dựa nhiều vào các mô hình suy luận và tác nhân thực hiện suy luận nhiều bước trên các ngữ cảnh cực kỳ dài. Những tác vụ này đồng thời gây áp lực lên mọi lớp của nền tảng: hiệu năng tính toán, giao tiếp giữa các GPU, độ trễ kết nối, băng thông và dung lượng bộ nhớ, hiệu quả sử dụng và cung cấp điện năng. Ngay cả những sự thiếu hiệu quả nhỏ, khi được nhân lên trên hàng nghìn tỷ token, cũng làm suy yếu chi phí tối ưu, thông lượng và khả năng cạnh tranh.
Sự năng động này được thể hiện qua ba quy luật tỷ lệ thúc đẩy sự tiến bộ của trí tuệ nhân tạo:
- Mở rộng quy mô trước khi huấn luyện: nơi các mô hình học được kiến thức vốn có của chúng.
- Mở rộng quy mô sau huấn luyện: nơi các mô hình học cách tư duy thông qua tinh chỉnh và củng cố.
- Mở rộng quy mô trong quá trình kiểm thử: nơi các mô hình suy luận bằng cách tạo ra nhiều token hơn trong quá trình suy luận.
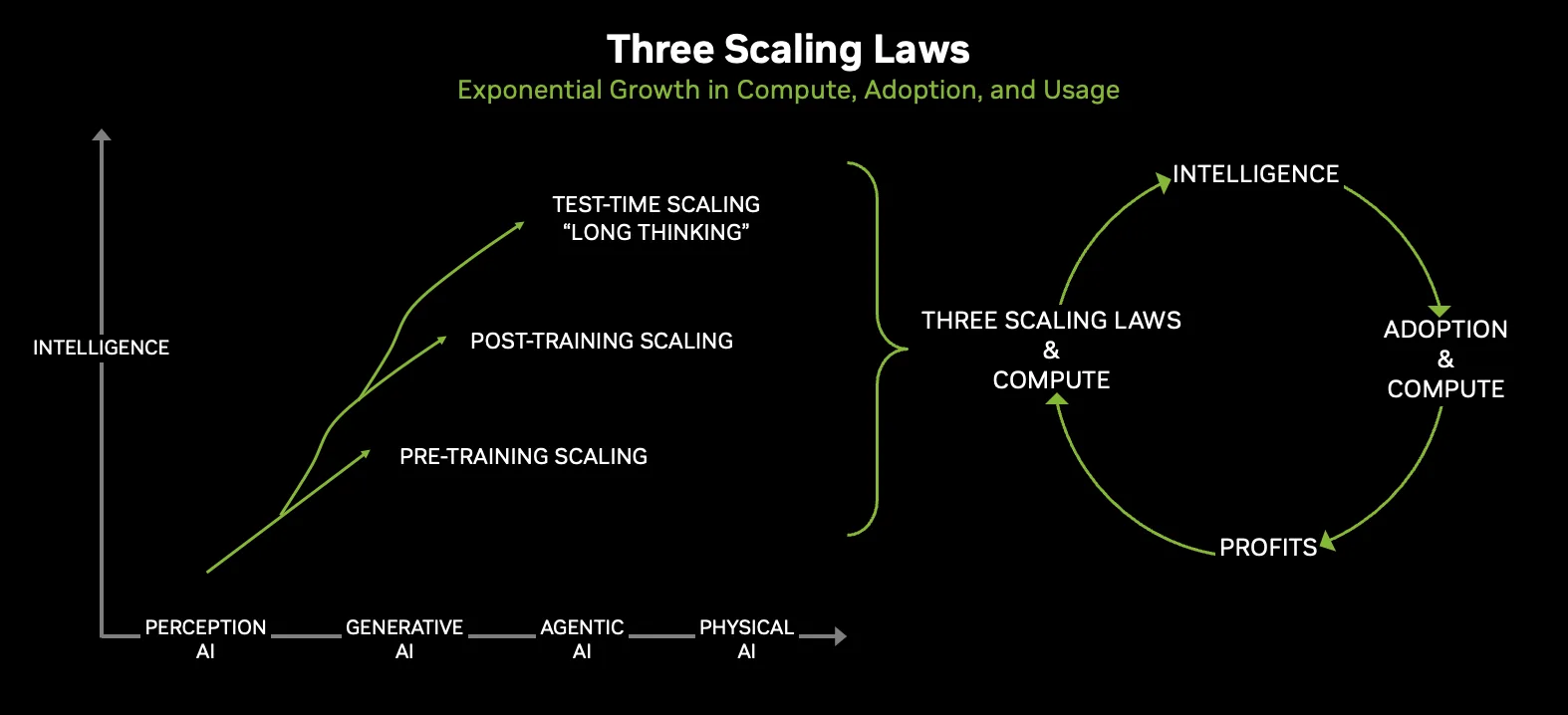
Khi các quy luật mở rộng này kết hợp với nhau, yêu cầu về cơ sở hạ tầng cũng tăng lên. NVIDIA Blackwell NVL72 là kiến trúc quy mô rack đầu tiên, giải phóng GPU, CPU và các kết nối khỏi những giới hạn của ranh giới máy chủ truyền thống và nâng tầm rack thành đơn vị tích hợp chính. Sự thay đổi này đã tạo ra những tiến bộ lớn về băng thông, hiệu quả và khả năng triển khai khi mở rộng quy mô, và là nền tảng cho nhiều triển khai AI lớn nhất hiện nay.
Khi các nhà máy sản xuất AI được thúc đẩy để cung cấp nhiều trí thông minh hơn, chi phí mỗi token thấp hơn và tác động kinh doanh lớn hơn, nhu cầu mở rộng hiệu năng ở quy mô rack trong khi vẫn duy trì tính ổn định ở quy mô trung tâm dữ liệu trong giới hạn điện năng và làm mát nghiêm ngặt ngày càng tăng cao.
2. Giới thiệu nền tảng NVIDIA Vera Rubin
Nền tảng NVIDIA Vera Rubin được thiết kế để đáp ứng sự thay đổi trong cách thức sản xuất trí tuệ nhân tạo ở quy mô lớn, áp dụng thiết kế đồng bộ tối ưu trên các khía cạnh điện toán, mạng lưới, cung cấp điện, làm mát và kiến trúc hệ thống nhằm cho phép sản xuất trí tuệ nhân tạo bền vững ở quy mô nhà máy AI.
Ở cấp độ nền tảng, Vera Rubin mang đến năm đột phá mang tính thế hệ:

Nhờ sự kết hợp các khả năng này, các hệ thống dựa trên Rubin có thể hoạt động như những đơn vị sản xuất thông tin tình báo có thể dự đoán được, an toàn và luôn sẵn sàng, thay vì là tập hợp các thành phần độc lập.
Sản phẩm chủ lực của nền tảng Vera Rubin là hệ thống Vera Rubin NVL72 dạng rack-scale, được thiết kế để toàn bộ rack hoạt động như một bộ tăng tốc rack-scale duy nhất trong một nhà máy AI lớn hơn. Hệ thống NVL72 được tối ưu hóa không chỉ cho hiệu suất cao nhất mà còn cho việc sản xuất trí tuệ liên tục: độ trễ có thể dự đoán được, mức sử dụng cao trên các giai đoạn thực thi khác nhau và chuyển đổi năng lượng hiệu quả thành trí tuệ hữu ích.

Để giúp hình dung cách thức nền tảng Vera Rubin hoạt động như một hệ thống thống nhất, video sau đây cung cấp tổng quan về kiến trúc quy mô rack và vai trò của từng thành phần chính trong việc sản xuất thông tin tình báo liên tục.
Tổng quan cấp hệ thống này đặt nền tảng cho việc hiểu cách các chip của nền tảng Vera Rubin được thiết kế để hoạt động như một siêu máy tính AI duy nhất.
3. Bảy con chip mới, một siêu máy tính AI
Sự phối hợp thiết kế ở mức độ cao nhất được thể hiện rõ ràng nhất ở cấp độ chip.
Nền tảng Vera Rubin được xây dựng từ bảy con chip mới, mỗi chip được thiết kế cho một vai trò cụ thể trong nhà máy AI và được thiết kế ngay từ đầu để hoạt động như một phần của hệ thống thống nhất quy mô cấp độ rack (rack-scale). Thay vì coi khối tính toán (compute), mạng (network) và cơ sở hạ tầng (infra) là các lớp liên kết lỏng lẻo, Vera Rubin tích hợp chúng trực tiếp vào kiến trúc. Điều này đảm bảo cho việc giao tiếp, phối hợp, bảo mật và tính hiệu quả là những yếu tố thiết kế hàng đầu.

Bảy con chip mới đó là:
- CPU NVIDIA Vera : 88 lõi Olympus do NVIDIA tự thiết kế, được tối ưu hóa cho thế hệ nhà máy AI tiếp theo với khả năng tương thích hoàn toàn với kiến trúc Arm.
- GPU NVIDIA Rubin : Tính toán AI hiệu năng cao với HBM4 và công nghệ NVIDIA Transformer Engine mới.
- Bộ chuyển mạch NVIDIA NVLink 6 : Kiến trúc mạng mở rộng thế hệ thứ sáu cung cấp băng thông GPU-to-GPU lên đến 3,6 TB/giây.
- NVIDIA ConnectX-9 : Giao diện mạng có thông lượng cao, độ trễ thấp tại điểm cuối dành cho AI mở rộng quy mô.
- Bộ xử lý dữ liệu (DPU) NVIDIA BlueField-4 : Một gói chip kép kết hợp:
- CPU NVIDIA Grace 64 nhân dành cho việc giảm tải cơ sở hạ tầng và bảo mật.
- Chip mạng tốc độ cao NVIDIA ConnectX-9 tích hợp giúp truyền tải dữ liệu một cách liền mạch.
- Bộ chuyển mạch Ethernet NVIDIA Spectrum-6 : Khả năng kết nối mở rộng bằng cách sử dụng các module quang tích hợp để đạt hiệu quả và độ tin cậy cao.
- Và Groq 3 LPX: Bộ tăng tốc suy luận độ trễ thấp dành cho nền tảng NVIDIA Vera Rubin. Con chip thứ 7 vừa được cập nhật vào ngày 16 tháng 3 năm 2026.
Cùng với nhau, các chip này tạo thành một kiến trúc đồng bộ, trong đó GPU thực hiện các tác vụ của kỷ nguyên Transformer, CPU điều phối dữ liệu và kiểm soát luồng, các kiến trúc mở rộng quy mô (scale-up và scale-out) di chuyển token và trạng thái một cách hiệu quả, và các bộ xử lý cơ sở hạ tầng chuyên dụng vận hành và bảo mật chính nhà máy AI.
Trong các phần tiếp theo, chúng ta sẽ xem xét chi tiết từng khối cấu tạo này, bắt đầu với CPU Vera, bộ phận điều phối việc di chuyển dữ liệu, bộ nhớ và luồng điều khiển để duy trì việc sử dụng GPU ở quy mô nhà máy AI.
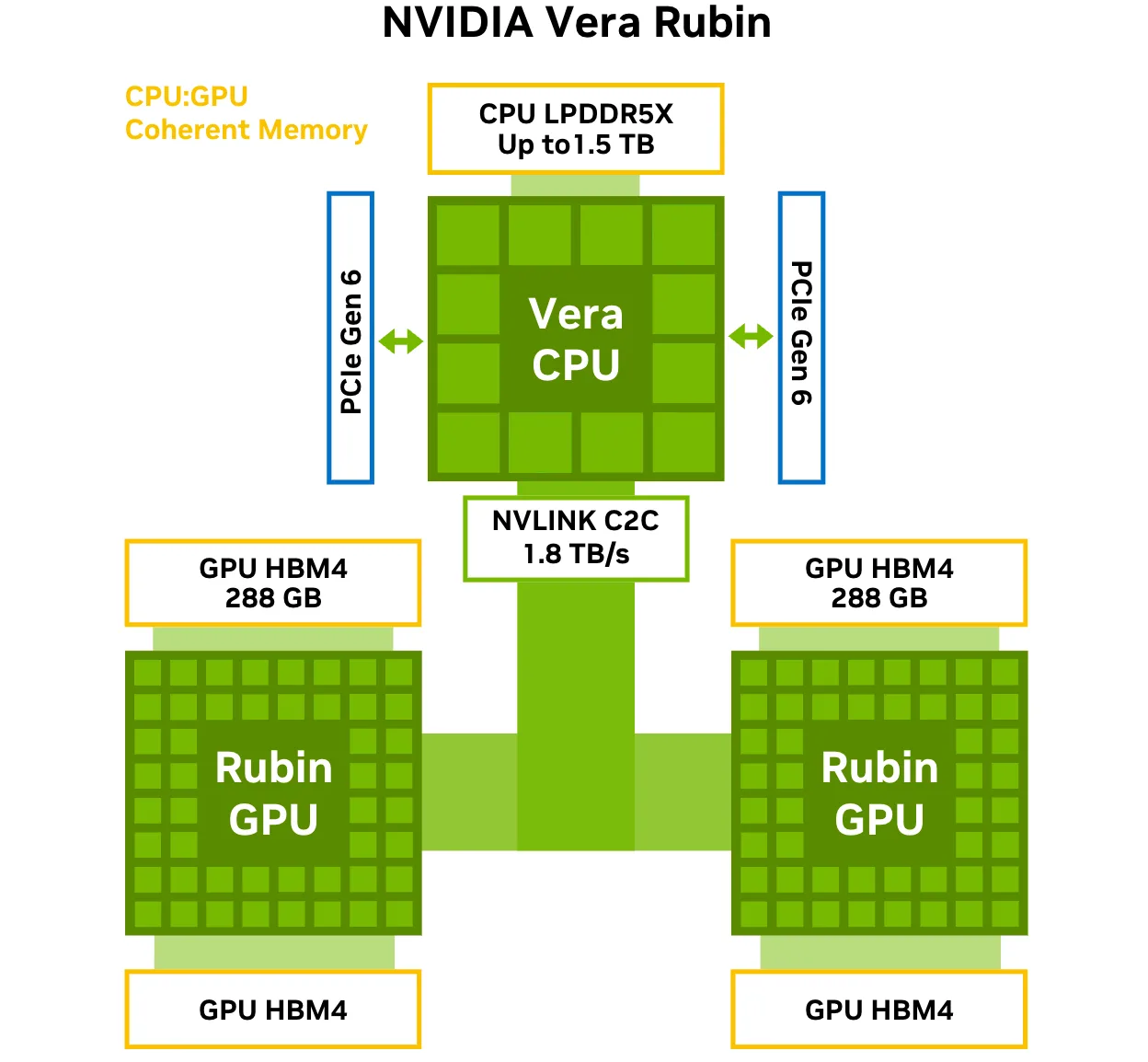
Vera CPU: Được thiết kế chuyên dụng cho các nhà máy AI.
Khi các nhà máy AI mở rộng quy mô, hiệu năng GPU đơn thuần không còn đủ để duy trì thông lượng. Việc sử dụng hiệu quả hàng nghìn GPU phụ thuộc vào việc dữ liệu, bộ nhớ và luồng điều khiển được truyền tải hiệu quả như thế nào trong hệ thống. CPU Vera được thiết kế đặc biệt cho vai trò này, hoạt động như một công cụ truyền tải dữ liệu băng thông cao, độ trễ thấp, giúp các nhà máy AI hoạt động hiệu quả ở quy mô lớn.
Thay vì hoạt động như một máy chủ đa năng truyền thống, Vera được tối ưu hóa cho việc điều phối, di chuyển dữ liệu và truy cập bộ nhớ nhất quán trên toàn bộ hệ thống. Khi được kết hợp với GPU Rubin làm CPU máy chủ, hoặc được triển khai như một nền tảng độc lập cho xử lý tác nhân, Vera cho phép sử dụng liên tục hiệu năng cao hơn bằng cách loại bỏ các nút thắt cổ chai phía CPU thường xuất hiện trong môi trường huấn luyện và suy luận.

Từ NVIDIA Grace đến Vera — mở rộng quy mô CPU cho các nhà máy AI
NVIDIA Grace đã thiết lập phương pháp tiếp cận của NVIDIA đối với thiết kế CPU hiệu suất cao, tiết kiệm năng lượng. Vera mở rộng nền tảng đó với mật độ lõi tăng lên, băng thông bộ nhớ cao hơn đáng kể, khả năng đồng bộ hóa được mở rộng và hỗ trợ đầy đủ điện toán bảo mật, tất cả đều được thiết kế riêng cho các tác vụ nhà máy AI.
Như bảng bên dưới cho thấy, Vera cung cấp băng thông bộ nhớ cao hơn 2,4 lần và dung lượng bộ nhớ lớn hơn 3 lần để hỗ trợ các khối lượng công việc đòi hỏi nhiều dữ liệu, đồng thời tăng gấp đôi băng thông NVLink-C2C nhằm duy trì hoạt động CPU-GPU đồng bộ ở quy mô rack. Nhờ đó, những cải tiến này nâng tầm CPU từ vai trò hỗ trợ lên vai trò then chốt thúc đẩy hiệu quả GPU thế hệ tiếp theo trong các nhà máy AI.
| Tính năng | CPU Grace | CPU Vera |
| Lõi | 72 lõi Neoverse V2 | 88 lõi NVIDIA Custom Olympus |
| Các sợi chỉ | 72 | 176 Luồng đa nhiệm không gian |
| Bộ nhớ đệm L2 trên mỗi lõi | 1 MB | 2 MB |
| Bộ nhớ đệm L3 thống nhất | 114 MB | 164 MB |
| Băng thông bộ nhớ (BW) | Tốc độ lên đến 512GB/giây | Tốc độ lên đến 1,2TB/giây |
| Dung lượng bộ nhớ | Bộ nhớ LPDDR5X lên đến 480GB | Bộ nhớ LPDDR5X lên đến 1.5TB |
| SIMD | 4x 128b SVE2 | 6x 128b SVE2 FP8 |
| NVLINK-C2C | 900 GB/giây | 1,8 TB/giây |
| PCIe/CXL | Gen5 | Gen6/CXL 3.1 |
| Máy tính bí mật | NA | Được hỗ trợ |
Bộ xử lý NVIDIA Olympus với công nghệ đa luồng không gian (Spatial Multithreading)
Cốt lõi của CPU Vera là 88 lõi Olympus tùy chỉnh của NVIDIA, được thiết kế cho hiệu năng đơn luồng cao và tiết kiệm năng lượng với khả năng tương thích hoàn toàn với kiến trúc Arm. Các lõi này sử dụng kiến trúc vi xử lý rộng và sâu với khả năng dự đoán nhánh, tìm nạp trước và hiệu năng tải-lưu trữ được cải thiện, tối ưu hóa cho các tác vụ đòi hỏi nhiều thao tác điều khiển và di chuyển dữ liệu.
Vera giới thiệu Spatial Multithreading, một loại đa luồng mới chạy hai luồng phần cứng trên mỗi lõi bằng cách phân vùng tài nguyên vật lý thay vì chia nhỏ thời gian, cho phép cân bằng giữa hiệu suất và hiệu quả trong quá trình vận hành. Cách tiếp cận này giúp tăng thông lượng và mật độ CPU ảo trong khi vẫn duy trì hiệu suất ổn định và khả năng cách ly mạnh mẽ, một yêu cầu quan trọng đối với các nhà máy AI đa người dùng.
Kiến trúc liên kết mở rộng — di chuyển dữ liệu xác định
Công nghệ NVIDIA Scalable Coherency Fabric (SCF) thế hệ thứ hai kết nối tất cả 88 lõi Olympus với bộ nhớ đệm L3 và hệ thống con bộ nhớ dùng chung trên một chip xử lý nguyên khối duy nhất. Bằng cách tránh các ranh giới giữa các chiplet, SCF mang lại độ trễ ổn định và duy trì hơn 90% băng thông bộ nhớ tối đa khi hoạt động, loại bỏ các điểm nghẽn giữa các lõi và bộ điều khiển bộ nhớ.
Bằng cách cung cấp khả năng di chuyển dữ liệu có tính xác định và thông lượng cao trên toàn bộ CPU, SCF đảm bảo rằng khối lượng công việc điều phối và xử lý dữ liệu sẽ mở rộng tuyến tính khi số lượng lõi tăng lên. Điều này rất cần thiết để duy trì nguồn dữ liệu và lệnh cho GPU ở quy mô nhà máy AI.
Băng thông bộ nhớ và thực thi nhất quán
Vera kết hợp SCF với hệ thống bộ nhớ con LPDDR5X lên đến 1,5TB, cung cấp băng thông lên đến 1,2 TB/giây với công suất thấp. Các mô-đun bộ nhớ nén kích thước nhỏ (SOCAMM) với LPDDR5X cải thiện khả năng bảo trì và cách ly lỗi, đáp ứng tốt hơn yêu cầu về thời gian hoạt động của nhà máy AI.
Công nghệ NVLink-C2C thế hệ thứ hai cung cấp băng thông đồng bộ 1,8 TB/giây giữa CPU Vera và GPU Rubin, cho phép không gian địa chỉ thống nhất trên bộ nhớ CPU và GPU. Các ứng dụng có thể coi LPDDR5X và HBM4 như một vùng nhớ đồng bộ duy nhất, giảm chi phí di chuyển dữ liệu và cho phép các kỹ thuật như giảm tải bộ nhớ đệm KV và thực thi đa mô hình hiệu quả.
Khả năng tương thích phần mềm và hoạt động an toàn
Vera hỗ trợ kiến trúc Arm v9.2 và tích hợp liền mạch với hệ sinh thái phần mềm Arm. Các bản phân phối Linux chính, khung phần mềm AI và nền tảng điều phối hoạt động mà không cần sửa đổi, cho phép phần mềm cơ sở hạ tầng hiện có mở rộng quy mô trên các hệ thống dựa trên Vera mà không gây gián đoạn.
Tính năng tính toán bảo mật được hỗ trợ nguyên bản, cho phép thực thi an toàn trên các ranh giới CPU-GPU và trên các cấu hình đa socket trong khi vẫn duy trì hiệu năng.
Công cụ xử lý dữ liệu cho các nhà máy AI
Vera là một CPU được thiết kế chuyên dụng để tận dụng tối đa sức mạnh của GPU bằng cách di chuyển, xử lý và điều phối dữ liệu một cách hiệu quả ở quy mô nhà máy AI. Thay vì hoạt động như một máy chủ thụ động, Vera đóng vai trò là một công cụ dữ liệu giúp tăng tốc các quy trình điều khiển và giao tiếp phức tạp, bao gồm chuẩn bị dữ liệu, lập lịch, điều phối và các quy trình làm việc dựa trên tác nhân. Nó cũng mang lại hiệu năng độc lập vượt trội cho các dịch vụ phân tích, điện toán đám mây, lưu trữ và cơ sở hạ tầng.
Bằng cách kết hợp các lõi CPU Olympus, SCF thế hệ thứ hai, bộ nhớ LPDDR5X băng thông cao và kết nối NVLink-C2C đồng bộ, Vera đảm bảo GPU Rubin duy trì hiệu suất cao trong suốt quá trình huấn luyện, xử lý sau huấn luyện và suy luận, ngay cả khi quá trình thực thi chuyển đổi giữa các giai đoạn chủ yếu là tính toán, bộ nhớ và truyền thông.
Trong phần tiếp theo, chúng ta sẽ xem xét GPU Rubin, công cụ thực thi giúp chuyển đổi nền tảng tăng tốc quy mô rack này thành hiệu năng huấn luyện và suy luận ổn định.
GPU Rubin: Công cụ thực thi cho trí tuệ nhân tạo kỷ nguyên Transformer
Với CPU Vera cung cấp nền tảng điều phối và di chuyển dữ liệu, GPU Rubin đóng vai trò là công cụ thực thi, biến khả năng xử lý quy mô rack thành trí tuệ nhân tạo. Nó được thiết kế cho việc huấn luyện liên tục, xử lý hậu huấn luyện và suy luận trong các nhà máy AI hoạt động liên tục.
Các tác vụ AI hiện đại—bao gồm suy luận, mô hình kết hợp chuyên gia (MoE), suy luận ngữ cảnh dài và học tăng cường—không chỉ bị giới hạn bởi số phép toán dấu phẩy động (FLOPS) tối đa. Chúng bị hạn chế bởi khả năng duy trì hiệu quả thực thi trên toàn bộ hệ thống tính toán, bộ nhớ và truyền thông. GPU Rubin được thiết kế đặc biệt cho thực tế này, tối ưu hóa toàn bộ đường dẫn thực thi, biến năng lượng, băng thông và bộ nhớ thành các token ở quy mô lớn.
Để duy trì hiệu suất trong những điều kiện này, GPU Rubin cải tiến kiến trúc của mình trên ba khía cạnh liên kết chặt chẽ: mật độ tính toán, băng thông bộ nhớ và khả năng giao tiếp ở quy mô rack.

Ở cấp độ silicon, Rubin được xây dựng dựa trên nền tảng GPU đã được chứng minh của NVIDIA đồng thời mở rộng quy mô mọi hệ thống con quan trọng cho các khối lượng công việc kỷ nguyên Transformer. GPU tích hợp 224 bộ xử lý đa luồng (SM) được trang bị lõi Tensor thế hệ thứ năm được tối ưu hóa cho việc thực thi NVFP4 và FP8 độ chính xác thấp. Các lõi Tensor này được kết nối chặt chẽ với các đơn vị chức năng đặc biệt (SFU) mở rộng và các đường dẫn thực thi được thiết kế để tăng tốc các đường dẫn tính toán chú ý, kích hoạt và tính toán thưa thớt thường thấy trong các mô hình AI hiện đại.
Dựa trên nền tảng NVIDIA Blackwell, Rubin mở rộng thiết kế đồng bộ phần cứng-phần mềm tiên tiến của NVIDIA để mang lại thông lượng ổn định cao hơn và chi phí trên mỗi token thấp hơn trong các tác vụ huấn luyện, hậu huấn luyện và suy luận. Việc cải thiện hỗ trợ NVFP4 giúp tăng mật độ và hiệu quả tính toán, cho phép thực hiện nhiều phép tính hữu ích hơn trên mỗi watt trong khi vẫn duy trì độ chính xác của mô hình. Bằng cách tích hợp sâu việc thực thi độ chính xác thấp vào cả kiến trúc và ngăn xếp phần mềm, Rubin chuyển đổi những tiến bộ trong định dạng số trực tiếp thành những lợi ích thực tế về thông lượng, khả năng sử dụng và hiệu quả kinh tế của nhà máy AI.
Trên toàn bộ thiết bị, Rubin mang lại sự gia tăng vượt bậc về thông lượng ổn định trong các giai đoạn trước huấn luyện, sau huấn luyện và suy luận. Bằng cách tăng băng thông mở rộng quy mô, cải thiện hiệu quả tổng thể và duy trì mức sử dụng cao hơn trong quá trình thực thi nặng về giao tiếp, Rubin nâng cao hiệu suất tối đa cho việc huấn luyện quy mô lớn đồng thời mang lại những lợi ích đáng kể trong quy trình làm việc sau huấn luyện và suy luận.
Khả năng tính toán và thực thi được duy trì ở mức cao.
Rubin kết hợp khả năng tính toán, hỗ trợ Transformer Engine và cân bằng thực thi để tránh tình trạng quá tải gây hạn chế thông lượng thực tế.
Bảng dưới đây nêu bật sự phát triển của các đặc tính tính toán cốt lõi kể từ thời Blackwell. Thông số kỹ thuật tính toán bổ sung của Rubin có thể được tìm thấy trên trang sản phẩm Vera Rubin NVL72 .
| Tính năng | Blackwell | Rubin |
| Transistor (toàn chip) | 208B | 336B |
| Máy tính chết | 2 | 2 |
| Suy luận NVFP4 (PFLOPS) | 10 | 50* |
| Đào tạo NVFP4 (PFLOPS) | 10 | 35** |
| Tăng tốc Softmax (SFU EX2 Ops/Clk/SM cho FP32 | FP16) |
16 | 32 | 64 |
* Tính toán bằng Transformer Engine
** Tính toán mật độ cao
Sự hội tụ giữa trí tuệ nhân tạo và điện toán khoa học
Việc ra mắt nền tảng NVIDIA Vera Rubin đánh dấu một giai đoạn mới trong điện toán khoa học, nơi trí tuệ nhân tạo (AI) và mô phỏng ngày càng hỗ trợ lẫn nhau. Trong nhiều môi trường siêu máy tính hiện nay, mô phỏng được coi là điểm cuối – các lần chạy tính toán chuyên sâu tạo ra một kết quả duy nhất. Ngày càng nhiều, các mô phỏng có độ chính xác cao cũng được sử dụng như công cụ tạo tập dữ liệu, tạo ra dữ liệu huấn luyện cho các mô hình AI nhằm bổ sung cho các thuật toán giải truyền thống.
Các mô hình AI này có thể hoạt động như các bộ tiền xử lý thông minh, tăng tốc độ hội tụ hoặc đóng vai trò là các mô hình thay thế nhanh trong các quy trình làm việc lặp đi lặp lại. Mặc dù các mô hình thay thế AI có thể mang lại tốc độ tăng đáng kể—đôi khi với độ chính xác giảm—mô phỏng cổ điển vẫn rất cần thiết để thiết lập dữ liệu tham chiếu và xác thực cuối cùng. Kết quả là một hồ sơ khối lượng công việc hội tụ đòi hỏi hiệu năng mạnh mẽ trên cả AI và tính toán khoa học.
Bảng dưới đây so sánh khả năng tính toán FP32 và FP64 của các GPU NVIDIA Hopper, Blackwell và Rubin.
| Tính năng | GPU Hopper | GPU Blackwell | GPU Rubin |
| Vector FP32 (TFLOPS) | 67 | 80 | 130 |
| Ma trận FP32 (TFLOPS) | 67 | 227* | 400* |
| Vector FP64 (TFLOPS) | 34 | 40 | 33 |
| Ma trận FP64 (TFLOPS) | 67 | 150* | 200* |
Hiệu năng ma trận được thể hiện ở trên đạt được nhờ sự kết hợp giữa các cải tiến kiến trúc và kỹ thuật phần mềm, mang lại thông lượng hiệu quả cao hơn so với các thế hệ trước. Điều này phản ánh sự tập trung liên tục của NVIDIA vào hiệu năng ở cấp độ ứng dụng thay vì các chỉ số hiệu năng đỉnh riêng lẻ.
Trong cả lĩnh vực trí tuệ nhân tạo (AI) và tính toán khoa học, triết lý thiết kế đồng bộ cực đoan của NVIDIA ưu tiên hiệu năng ổn định trên các khối lượng công việc thực tế. Phân tích mã mô phỏng sản xuất cho thấy hiệu năng FP64 ổn định cao nhất thường đến từ các nhân phép nhân ma trận. Hopper đã sử dụng phần cứng chuyên dụng để tăng tốc các đường dẫn này. Với Blackwell và giờ là Rubin, NVIDIA đã phát triển chiến lược này, đạt được thông lượng ma trận FP64 cao thông qua nhiều lần xử lý trên các lõi tensor có độ chính xác thấp hơn trong khi vẫn duy trì tính linh hoạt kiến trúc cho các khối lượng công việc hội tụ. Thông tin chi tiết hơn về cách mô phỏng Ozaki FP64 là một cách hiệu quả để đạt được độ chính xác cấp FP64 thực sự trên phần cứng AI có độ chính xác thấp đồng thời mang lại hiệu năng ấn tượng có thể được tìm thấy trong bài viết trên blog của chúng tôi về “Mở khóa hiệu năng lõi Tensor bằng mô phỏng dấu phẩy động trong cuBLAS” .
Đồng thời, hiệu năng xử lý vector FP64 chuyên dụng vẫn rất quan trọng đối với các ứng dụng khoa học không bị chi phối bởi các nhân ma trận. Trong những trường hợp này, hiệu năng bị hạn chế bởi việc di chuyển dữ liệu qua các thanh ghi, bộ nhớ đệm và bộ nhớ băng thông cao (HBM) chứ không phải bởi khả năng tính toán thô. Do đó, một thiết kế GPU cân bằng cần cung cấp đủ tài nguyên FP64 để tận dụng tối đa băng thông bộ nhớ khả dụng, tránh việc phân bổ quá mức năng lực tính toán mà không thể sử dụng hiệu quả.
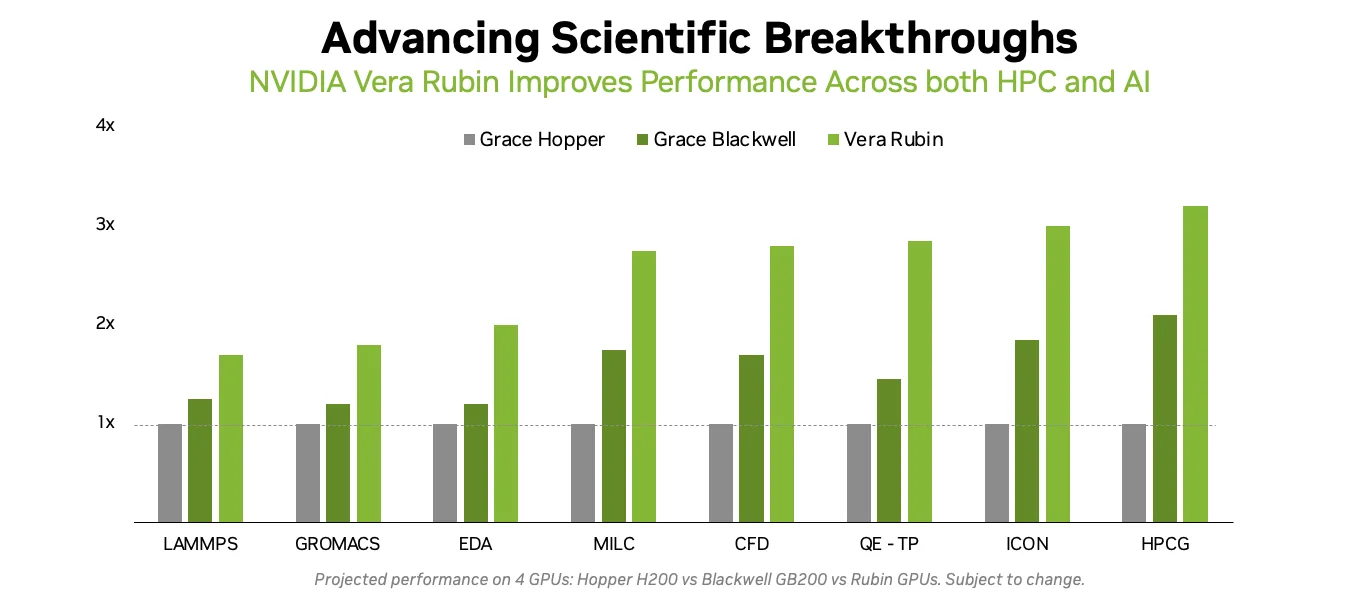
Với nền tảng Vera Rubin, hiệu năng ứng dụng thực tế tiếp tục được cải thiện qua từng thế hệ. Hình dưới đây cho thấy những cải tiến dự kiến trên các mã mô phỏng điện toán hiệu năng cao (HPC) tiêu biểu, được thúc đẩy bởi những cải tiến về kiến trúc và hệ thống chứ không phải do sự gia tăng về thông lượng vector FP64 thô.
Transformer Engine
Công nghệ NVIDIA Transformer Engine thế hệ thứ ba được xây dựng dựa trên những cải tiến trước đó với khả năng nén thích ứng tăng tốc phần cứng mới, được thiết kế để nâng cao hiệu năng NVFP4 trong khi vẫn duy trì độ chính xác. Khả năng này cho phép đạt hiệu năng lên đến 50 PetaFLOPS cho suy luận NVFP4.
Hoàn toàn tương thích với GPU Blackwell, Transformer Engine mới giữ nguyên mô hình lập trình hiện có, cho phép mã đã được tối ưu hóa trước đó chuyển đổi liền mạch sang Rubin đồng thời tự động hưởng lợi từ mật độ tính toán cao hơn và hiệu quả thực thi được cải thiện.
Hiệu quả bộ nhớ và giải mã
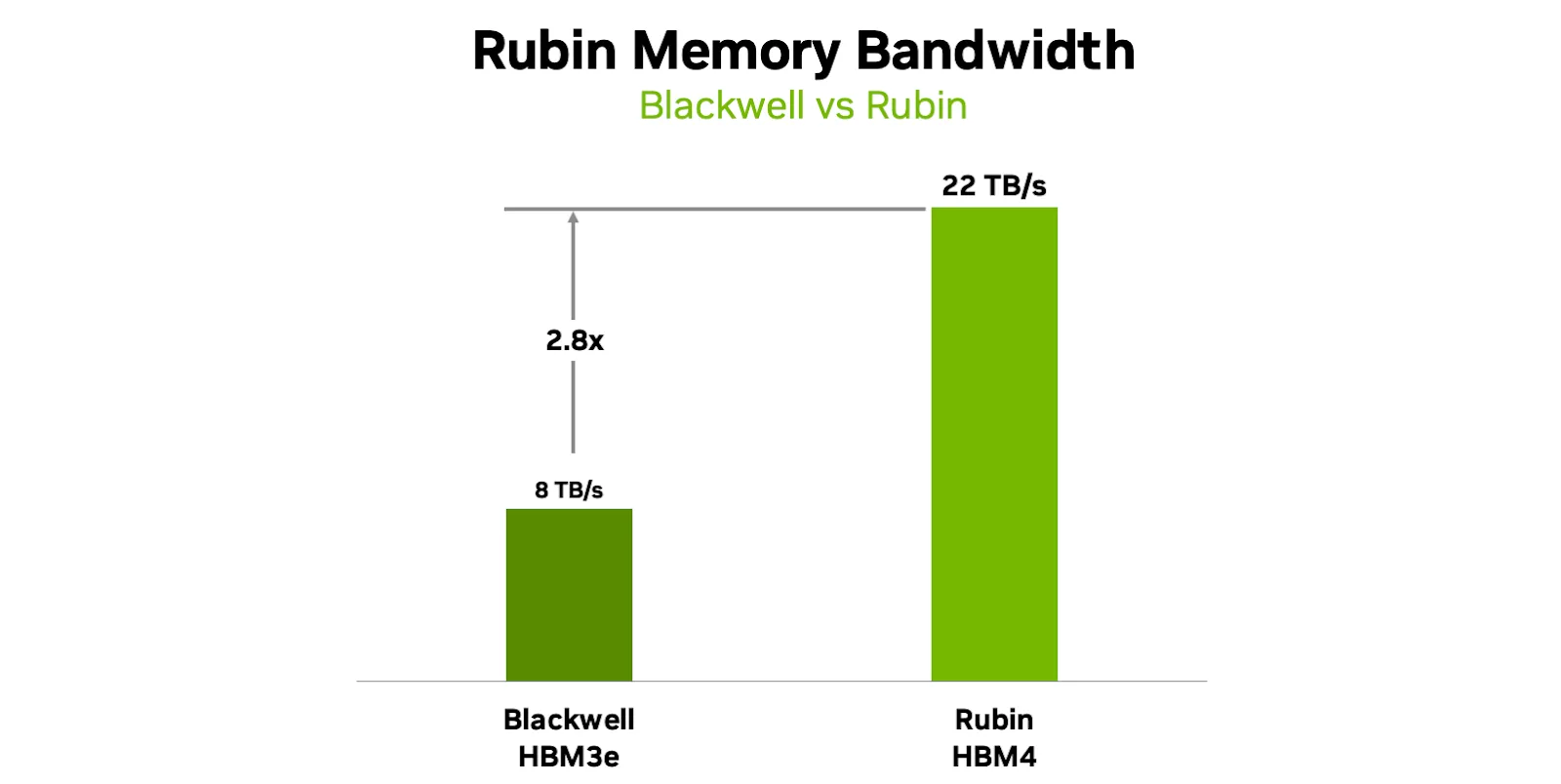
Khi độ dài ngữ cảnh tăng lên và quá trình suy luận trở nên tương tác hơn, hiệu năng bộ nhớ đạt được trở thành yếu tố chi phối hiệu quả tổng thể. GPU Rubin tích hợp thế hệ bộ nhớ băng thông cao mới, HBM4, giúp tăng gấp đôi độ rộng giao diện so với HBM3e.
Nhờ các bộ điều khiển bộ nhớ mới, sự hợp tác chặt chẽ trong thiết kế với hệ sinh thái bộ nhớ và sự tích hợp chặt chẽ hơn giữa bộ nhớ và khả năng tính toán, GPU Rubin gần như tăng gấp ba lần băng thông bộ nhớ so với Blackwell.
Các đặc điểm chính bao gồm:
- Tối đa 288 GB HBM4 cho mỗi GPU
- Tổng băng thông lên đến 22 TB/s
- Cải thiện hiệu quả giải mã và giao diện người dùng để duy trì hoạt động của các đường dẫn thực thi ngay cả khi chịu tải.
Nhờ sự kết hợp của những tiến bộ này, GPU Rubin có thể duy trì khả năng suy luận ngữ cảnh dài, thực thi MoE với khối lượng xử lý lớn và suy luận tương tác mà không làm giảm tính song song hoặc hiệu suất sử dụng.
Hệ thống kết nối mở rộng quy mô—được xây dựng cho trí tuệ nhân tạo (AI) chủ yếu dựa trên giao tiếp.
Nền tảng Vera Rubin hỗ trợ NVIDIA NVLink thế hệ thứ sáu (NVLink 6) để giao tiếp giữa các GPU trong hệ thống, NVIDIA NVLink-C2C (chip-to-chip) để kết nối CPU-GPU đồng bộ với CPU Vera và PCIe Gen6 để tích hợp với máy chủ và thiết bị.
NVIDIA NVLink 6 cung cấp băng thông hai chiều 3,6 TB/giây giữa các GPU, gấp đôi băng thông mở rộng so với thế hệ trước. Trong hệ thống NVL72, điều này cho phép giao tiếp toàn diện giữa 72 GPU với độ trễ có thể dự đoán được, một yêu cầu quan trọng đối với định tuyến MoE, các tác vụ tập thể và các đường dẫn suy luận đòi hỏi đồng bộ hóa cao.
Bằng cách loại bỏ các nút thắt cổ chai khi mở rộng quy mô, GPU Rubin đảm bảo rằng khả năng giao tiếp không giới hạn mức độ sử dụng khi kích thước mô hình, số lượng chuyên gia và độ sâu suy luận tăng lên.
Bảng dưới đây so sánh băng thông kết nối GPU giữa các dòng máy Blackwell và Rubin.
| Kết nối | Blackwell | Rubin |
| NVLink (GPU-GPU) (GB/s, hai chiều) | 1.800 | 3.600 |
| NVLink-C2C (CPU-GPU) (GB/s, hai chiều) | 900 | 1.800 |
| Giao diện PCIe (GB/s, hai chiều) | 256 (Sáng thế ký 6) | 256 (Sáng thế ký 6) |
Được thiết kế cho khối lượng công việc của nhà máy AI.
GPU NVIDIA Rubin được tối ưu hóa cho các khối lượng công việc đặc trưng của các nhà máy AI hiện đại, nơi hiệu năng không chỉ phụ thuộc vào khả năng tính toán đỉnh điểm mà còn vào hiệu quả bền vững trên toàn bộ quá trình tính toán, bộ nhớ và truyền thông. Các khối lượng công việc này bao gồm các mô hình MoE (Moor-Equity Exchange) với đặc điểm là giao tiếp động toàn diện, các quy trình xử lý tác nhân kết hợp suy luận với việc sử dụng công cụ, và các quy trình huấn luyện và hậu huấn luyện kéo dài cần duy trì mức sử dụng cao trong thời gian dài.
Bằng cách kết hợp khả năng thực thi thích ứng với băng thông mở rộng quy mô lớn, nền tảng Vera Rubin giúp GPU hoạt động hiệu quả trong tất cả các giai đoạn thực thi, bao gồm các nhân tính toán nặng, cơ chế chú ý tốn nhiều bộ nhớ và cơ chế điều phối chuyên gia ràng buộc bởi giao tiếp, thay vì chỉ tối ưu hóa cho các phép toán ma trận phức tạp. Đây không phải là một bản nâng cấp nhỏ so với các thế hệ trước. Nền tảng Vera Rubin cân bằng lại kiến trúc GPU để hoạt động liên tục ở quy mô lớn, phối hợp với CPU Vera, khả năng mở rộng NVLink 6 và phần mềm nền tảng để chuyển đổi hiệu quả năng lượng và silicon thành trí thông minh hữu ích trên toàn hệ thống.
Trong phần tiếp theo, chúng ta sẽ xem xét hệ thống chuyển mạch NVLink 6, kiến trúc mạng quy mô rack cho phép 72 GPU hoạt động như một hệ thống duy nhất, liên kết chặt chẽ.
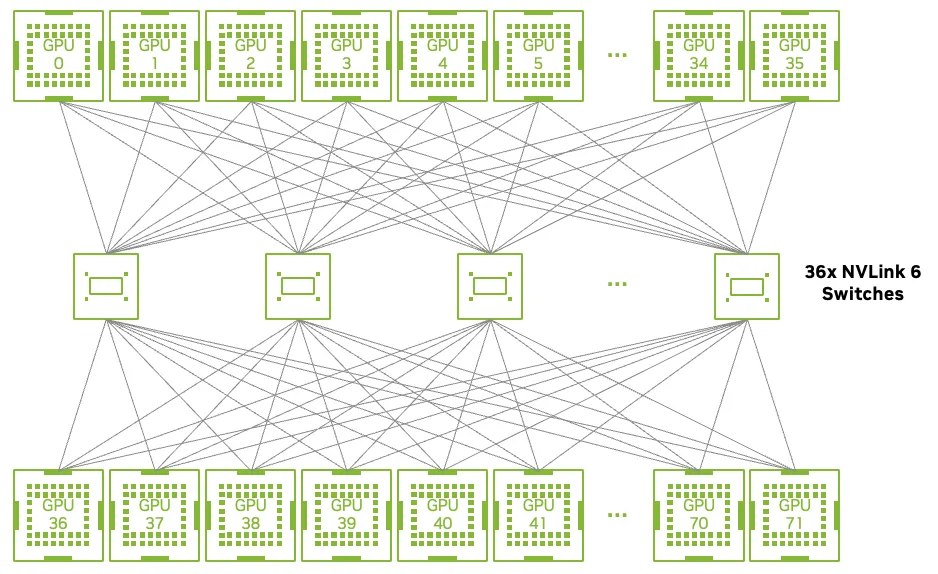
Bộ chuyển mạch NVLink 6: Kiến trúc mở rộng quy mô tủ rack
Ở quy mô nhà máy AI, giao tiếp là yếu tố then chốt quyết định hiệu suất. Định tuyến MoE, các hoạt động tập thể, huấn luyện đòi hỏi đồng bộ hóa cao và suy luận đều phụ thuộc vào việc truyền dữ liệu nhanh chóng, có thể dự đoán được giữa tất cả các thiết bị. Khi băng thông mở rộng không đủ, GPU sẽ ở trạng thái nh闲 rỗi và chi phí trên mỗi token tăng lên.
NVLink 6 được thiết kế để loại bỏ điểm nghẽn này. Nó là nền tảng mở rộng quy mô của Vera Rubin, cho phép 72 GPU Rubin trong một hệ thống NVL72 hoạt động như một bộ tăng tốc duy nhất, được kết nối chặt chẽ với độ trễ đồng nhất và băng thông ổn định trong các tác vụ đòi hỏi nhiều giao tiếp.

Mỗi GPU Rubin kết nối với NVLink 6 với băng thông hai chiều 3,6 TB/s, tăng gấp đôi băng thông mở rộng trên mỗi GPU so với thế hệ trước. Các khay chuyển mạch NVLink 6 tạo thành một cấu trúc liên kết duy nhất từ đầu đến cuối trên toàn bộ giá đỡ, cho phép bất kỳ GPU nào cũng có thể giao tiếp với bất kỳ GPU nào khác với độ trễ và băng thông ổn định.
Cấu trúc đồng nhất này loại bỏ các điểm nghẽn phân cấp và hành vi phụ thuộc vào số bước nhảy. Từ góc độ phần mềm, giá đỡ hoạt động như một bộ tăng tốc lớn duy nhất, đơn giản hóa việc mở rộng quy mô cho các mô hình đòi hỏi nhiều giao tiếp.
Mở rộng quy mô toàn diện cho MoE và lý luận
Quá trình huấn luyện và suy luận MoE nhanh chóng sử dụng song song chuyên gia (EP), dựa trên việc định tuyến động, chi tiết các token giữa các chuyên gia có thể nằm trên các GPU khác nhau. Các mô hình này tạo ra sự giao tiếp thường xuyên, đột ngột, làm quá tải các kiến trúc phân cấp hoặc kết nối một phần.
NVLink 6 được triển khai như một kiến trúc kết nối toàn diện trên toàn hệ thống NVL72. Khả năng định tuyến, đồng bộ hóa và xử lý tập thể chuyên nghiệp được tối ưu hóa để mở rộng quy mô trên tất cả 72 GPU mà không làm quá tải các liên kết hoặc gây ra độ trễ không thể dự đoán được.
Đối với suy luận MoE quy mô lớn, NVLink 6 mang lại thông lượng cao hơn gấp 2 lần so với thế hệ trước cho các hoạt động kết nối toàn diện.
Tính toán trong mạng cho các hoạt động tập thể
NVLink 6 tích hợp giao thức SHARP (NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol) để tăng tốc các hoạt động tập thể trực tiếp bên trong kiến trúc mạng. Một phần của các tác vụ all-reduce, reduce-scatter và all-gather được thực thi bên trong bộ chuyển mạch, giảm thiểu việc di chuyển dữ liệu dư thừa và chi phí đồng bộ hóa GPU.
Mỗi khay chuyển mạch NVLink 6 cung cấp 14,4 TFLOPS tính toán FP8 trong mạng, cho phép thực thi các giai đoạn nặng về tính toán tập thể với độ trễ thấp hơn và hiệu quả cao hơn. Bằng cách chuyển các phép tính giảm tập thể vào mạng, SHARP có thể giảm lưu lượng truyền thông giảm tổng thể lên đến 50% và cải thiện thời gian thực thi song song tensor lên đến 20% trong các khối lượng công việc AI quy mô lớn.
Việc chuyển tải này giúp tăng hiệu quả sử dụng GPU và cải thiện hiệu suất mở rộng khi kích thước cụm tăng lên. Kết quả phụ thuộc vào kiến trúc mô hình, chiến lược song song hóa, số lượng người tham gia và cấu hình NCCL.
Khả năng vận hành ở quy mô nhà máy AI
Việc mở rộng mạng lưới phải đảm bảo tính ổn định, chứ không chỉ tốc độ nhanh. Khay chuyển mạch NVLink 6 tích hợp các tính năng mới về khả năng phục hồi và bảo trì, bao gồm khay có thể thay thế nóng, hoạt động liên tục ngay cả khi tủ rack chỉ được sử dụng một phần, và định tuyến lại lưu lượng truy cập động khi một switch ngoại tuyến. Nó cũng hỗ trợ cập nhật phần mềm trong khi hoạt động và truyền dữ liệu đo từ xa chi tiết về liên kết thông qua các giao diện chuyển mạch để giám sát theo thời gian thực.
Nhờ sự kết hợp giữa định tuyến dựa trên phần mềm, dữ liệu đo từ xa chi tiết và các khay chuyển mạch có thể bảo trì, lưu lượng truy cập có thể được định tuyến lại một cách linh hoạt xung quanh các sự cố hoặc sự kiện bảo trì mà không làm cạn kiệt tài nguyên của tủ rack hoặc làm gián đoạn khối lượng công việc đang hoạt động. Những khả năng này cho phép NVLink 6 đáp ứng được kỳ vọng về thời gian ngừng hoạt động bằng không của các nhà máy AI trong sản xuất.
Bằng cách tăng gấp đôi băng thông trên mỗi GPU, cho phép kết nối đồng nhất giữa tất cả các thiết bị và tăng tốc các tác vụ tập thể trực tiếp bên trong kiến trúc mạng, NVLink 6 cho phép các khối lượng công việc đòi hỏi nhiều giao tiếp có thể mở rộng một cách có thể dự đoán được ở quy mô tủ rack.
Trong phần tiếp theo, chúng ta sẽ xem xét ConnectX-9, thiết bị cung cấp giao diện điểm cuối giúp mở rộng hiệu năng này ra ngoài phạm vi tủ rack bằng cách kết nối GPU với kiến trúc mạng Ethernet Spectrum-X.
ConnectX-9: Vượt qua giới hạn về băng thông mở rộng của AI
ConnectX-9 đóng vai trò là các điểm cuối thông minh của kiến trúc Ethernet Spectrum-X, mang lại hiệu suất mở rộng có thể dự đoán được đồng thời đảm bảo cách ly lưu lượng và hoạt động an toàn khi các nhà máy AI phát triển.

Trong kiến trúc rack-scale Vera Rubin NVL72, mỗi khay tính toán chứa bốn bo mạch ConnectX-9 SuperNIC, cung cấp băng thông mạng 1,6Tb/s cho mỗi GPU Rubin. Mỗi bo mạch ConnectX-9 SuperNIC kết nối với mỗi CPU Vera. Điều này đảm bảo các GPU có thể tham gia đầy đủ vào việc điều phối chuyên gia, các hoạt động tập thể và đồng bộ hóa mà không bị tắc nghẽn ở rìa mạng.
Kiểm soát điểm cuối cho lưu lượng truy cập AI đột biến
Các tác vụ AI như suy luận và huấn luyện MoE tạo ra các mô hình lưu lượng truy cập có độ tương quan cao. Số lượng lớn GPU thường cố gắng đưa dữ liệu vào mạng cùng lúc, tạo ra các đỉnh tắc nghẽn lưu lượng tạm thời mà các card mạng truyền thống không được thiết kế để xử lý.
ConnectX-9 giải quyết thách thức này bằng cách thực thi kiểm soát tắc nghẽn có thể lập trình, định hình lưu lượng và lập lịch gói trực tiếp tại điểm cuối. Hoạt động phối hợp với các bộ chuyển mạch Spectrum-6, ConnectX-9 ngăn chặn tắc nghẽn hình thành ngay từ đầu thay vì phản ứng sau khi hàng đợi tích tụ.
Hành vi phối hợp từ điểm cuối đến hệ thống mạng này:
- Làm mượt quá trình truyền tải lưu lượng truy cập trong các giai đoạn kết nối toàn mạng.
- Giảm tình trạng tắc nghẽn đầu hàng và lưu lượng người bị ảnh hưởng.
- Duy trì băng thông hiệu quả cao ngay cả khi chịu tải.
Phân tách hiệu năng cho các nhà máy AI đa người dùng
Khi các nhà máy AI hợp nhất khối lượng công việc, việc cách ly trở nên quan trọng không kém gì thông lượng. Các tác vụ đột biến hoặc cấu hình sai không được làm giảm hiệu suất toàn cụm.
ConnectX-9 đảm bảo tính công bằng và sự cô lập tại điểm cuối, đảm bảo rằng mỗi tác vụ hoặc người dùng nhận được hành vi mạng có thể dự đoán được bất kể hoạt động của những người dùng khác. Khả năng này rất quan trọng đối với cơ sở hạ tầng AI dùng chung, nơi các tác vụ suy luận, huấn luyện và hậu huấn luyện thường chạy đồng thời trên cùng một mạng lưới.
Bằng cách chuyển việc thực thi sang điểm cuối, nền tảng này tránh chỉ dựa vào các cơ chế ở cấp độ thiết bị chuyển mạch, giúp cải thiện khả năng mở rộng và giảm độ phức tạp trong vận hành.
Các điểm cuối bảo mật cho cơ sở hạ tầng AI
ConnectX-9 cũng đóng vai trò trung tâm trong việc bảo mật mạng lưới nhà máy AI. Các công cụ mã hóa tích hợp hỗ trợ mã hóa thông lượng cao cho dữ liệu đang truyền tải và dữ liệu đang lưu trữ, cho phép hoạt động an toàn mà không làm giảm hiệu suất.
Các tính năng bảo mật chính bao gồm:
- Tăng tốc mã hóa dữ liệu trong quá trình truyền tải cho IP Security (IPsec) và Platform Security Protocol (PSP) để bảo mật giao tiếp giữa các GPU.
- Tăng tốc mã hóa dữ liệu khi lưu trữ để bảo mật nền tảng lưu trữ
- Khởi động an toàn, xác thực phần mềm và chứng thực thiết bị
Các tính năng này cho phép các nhà máy AI hoạt động an toàn trong môi trường dùng chung, đám mây hoặc được quản lý chặt chẽ, đồng thời duy trì hiệu suất mạng gần như tương đương với mạng gốc.
Từ kiểm soát điểm cuối đến giảm tải cơ sở hạ tầng
ConnectX-9 hoàn thiện kiến trúc mở rộng mạng Ethernet Spectrum-X bằng cách kiểm soát cách thức lưu lượng truy cập đi vào mạng. Bằng cách định hình, lập lịch, cách ly và bảo mật thông tin liên lạc tại điểm cuối, nó đảm bảo rằng mạng lưới nhà máy AI hoạt động một cách dễ dự đoán dưới tải trọng thực tế.
Với hành vi ở cấp độ mạng được xác định bởi Spectrum-6 và hành vi ở cấp độ thiết bị đầu cuối được thực thi bởi ConnectX-9, thách thức còn lại là làm thế nào để vận hành, bảo mật và quản lý cơ sở hạ tầng này ở quy mô lớn mà không tiêu tốn tài nguyên CPU và GPU quý giá.
Trách nhiệm đó chuyển sang các DPU BlueField-4, cung cấp lớp cơ sở hạ tầng được định nghĩa bằng phần mềm để vận hành chính nhà máy AI. Trong phần tiếp theo, chúng ta sẽ xem xét cách BlueField-4 hỗ trợ các dịch vụ mạng, lưu trữ, bảo mật và điều khiển trên toàn bộ nền tảng Vera Rubin.
Bộ xử lý dữ liệu BlueField-4 DPU: Cung cấp năng lượng cho hệ điều hành của nhà máy AI.
Khi cơ sở hạ tầng AI phát triển lên đến hàng nghìn GPU và petabyte dữ liệu, các nhà máy AI cần được vận hành với sự chặt chẽ, tự động hóa và kiểm soát của cơ sở hạ tầng đám mây hiện đại. Thách thức không chỉ dừng lại ở việc kết nối GPU mà còn ở việc điều phối các hệ thống phân tán cao có khả năng mở rộng, bảo mật và vận hành hiệu quả các khối lượng công việc AI. Áp dụng các nguyên tắc quy mô đám mây vào cơ sở hạ tầng AI đòi hỏi tự động hóa, tính linh hoạt và bảo mật đầu cuối phải là nền tảng ngay từ đầu.
Để đáp ứng những yêu cầu này, cần có một bộ xử lý dữ liệu chuyên dụng dành riêng cho lớp cơ sở hạ tầng. NVIDIA BlueField-4 đảm nhiệm vai trò này bằng cách xử lý việc điều khiển, bảo mật, di chuyển dữ liệu và điều phối một cách độc lập với quá trình tính toán AI. Trên thực tế, BlueField-4 là bộ xử lý cung cấp năng lượng cho hệ điều hành của nhà máy AI, được thiết kế để kết nối, bảo mật và quản lý cơ sở hạ tầng hỗ trợ AI ở quy mô lớn.
Trong nền tảng Rubin, BlueField-4 hoạt động như một mặt phẳng điều khiển được định nghĩa bằng phần mềm cho nhà máy AI, đảm bảo an ninh, sự cô lập và tính xác định hoạt động một cách độc lập với CPU và GPU của máy chủ. Bằng cách chuyển tải và tăng tốc các dịch vụ cơ sở hạ tầng lên một lớp xử lý chuyên dụng, BlueField-4 cho phép các nhà máy AI mở rộng quy mô trong khi vẫn duy trì hiệu suất ổn định, khả năng cô lập mạnh mẽ và hoạt động hiệu quả.

BlueField-4 tích hợp CPU Grace 64 lõi và bộ nhớ LPDDR5X băng thông cao cùng với mạng ConnectX-9, cung cấp kết nối Ethernet hoặc InfiniBand độ trễ cực thấp lên đến 800 Gb/s trong khi chạy các dịch vụ cơ sở hạ tầng trực tiếp trên DPU.
Bảng dưới đây nêu bật những cải tiến quan trọng trong BlueField-4 so với BlueField-3 về băng thông, khả năng tính toán và bộ nhớ. Những cải tiến này cho phép các nhà máy AI mở rộng quy mô các cụm máy chủ và dịch vụ mà không bị hạn chế bởi cơ sở hạ tầng.
| Tính năng | BlueField-3 | BlueField-4 |
| Băng thông | 400 Gb/s | 800 Gb/s |
| Tính toán | 16 lõi ARM A78 | Hiệu năng tính toán 6x của Arm Neoverse V2 64 |
| Băng thông bộ nhớ | 75 GB/s | 250 GB/giây |
| Dung lượng bộ nhớ | 32GB | 128GB |
| Mạng đám mây | 32.000 máy chủ | 128.000 máy chủ |
| Mã hóa dữ liệu trong quá trình truyền tải | 400Gb/s | 800Gb/s |
| Phân tách bộ nhớ NVMe | 10 triệu IOPs ở độ phân giải 4K | 20 triệu IOP ở độ phân giải 4K |
Sự gia tăng theo thế hệ này cho phép các nhà máy AI mở rộng quy mô các mô-đun, dịch vụ và người dùng, đồng thời thúc đẩy hoạt động cơ sở hạ tầng, hiệu quả và an ninh mạng.
Tăng tốc phát triển cơ sở hạ tầng ở quy mô nhà máy AI
Trong các hệ thống truyền thống, các dịch vụ cơ sở hạ tầng chạy trên CPU của máy chủ, dẫn đến sự biến đổi, xung đột và rủi ro bảo mật khi khối lượng công việc tăng lên. BlueField-4 loại bỏ sự phụ thuộc này bằng cách thực hiện các dịch vụ mạng, lưu trữ, đo lường từ xa và bảo mật hoàn toàn bên ngoài máy chủ. Sự tách biệt này mang lại:
- Hành vi cơ sở hạ tầng mang tính xác định, độc lập với sự kết hợp khối lượng công việc.
- Tăng cường sử dụng GPU và CPU cho việc thực thi AI.
- Cải thiện khả năng cách ly lỗi và khả năng phục hồi hoạt động.
NVIDIA DOCA cung cấp nền tảng phần mềm nhất quán trên các thế hệ BlueField, cho phép tái sử dụng các dịch vụ cơ sở hạ tầng đồng thời cho phép đổi mới nhanh chóng mà không làm gián đoạn khối lượng công việc ứng dụng. DOCA là một khung phần mềm và SDK toàn diện cho phép các nhà phát triển xây dựng, triển khai và tăng tốc các dịch vụ trung tâm dữ liệu được định nghĩa bằng phần mềm an toàn trên các DPU BlueField và thiết bị ConnectX bằng cách sử dụng API mở và khả năng giảm tải phần cứng.
Được thiết kế để vận hành an toàn cho nhiều người dùng.
Khi các nhà máy AI ngày càng áp dụng mô hình triển khai phần cứng vật lý và đa người dùng, việc duy trì khả năng kiểm soát và cách ly cơ sở hạ tầng mạnh mẽ trở nên thiết yếu, đặc biệt đối với các môi trường xử lý dữ liệu độc quyền, nội dung được quy định và các mô hình có giá trị cao.
Là một phần của nền tảng Vera Rubin, BlueField-4 giới thiệu Kiến trúc Tài nguyên Tin cậy Bảo mật Nâng cao (ASTRA), một kiến trúc tin cậy cấp hệ thống thiết lập miền tin cậy trong khay tính toán. ASTRA cung cấp cho các nhà xây dựng cơ sở hạ tầng AI một điểm kiểm soát đáng tin cậy duy nhất để cung cấp, cách ly và vận hành môi trường AI quy mô lớn một cách an toàn mà không ảnh hưởng đến hiệu suất.
Bằng cách tách biệt các lớp điều khiển, dữ liệu và quản lý khỏi khối lượng công việc của người dùng, BlueField ASTRA cho phép vận hành phần cứng trần an toàn, khả năng cách ly đa người dùng mạnh mẽ và kiểm soát cơ sở hạ tầng đáng tin cậy hoạt động độc lập với phần mềm máy chủ.
Bộ nhớ lưu trữ ngữ cảnh suy luận NVIDIA — Cơ sở hạ tầng lưu trữ gốc AI
Nền tảng Vera Rubin giới thiệu NVIDIA Inference Context Memory Storage (ICMS) , một tầng cơ sở hạ tầng gốc AI được thiết kế cho kỷ nguyên tác nhân, nơi trạng thái suy luận thường tồn tại lâu hơn một cửa sổ thực thi GPU đơn lẻ. Khi khối lượng công việc ngữ cảnh dài, nhiều lượt và nhiều tác nhân tiến tới hàng triệu token, dung lượng bộ nhớ cache KV tăng nhanh, buộc trạng thái đó phải được lưu trữ trong bộ nhớ HBM GPU khan hiếm hoặc bộ nhớ lưu trữ doanh nghiệp được tối ưu hóa độ bền, điều này làm tăng độ trễ, điện năng và chi phí trên mỗi token.
ICMS, được hỗ trợ bởi NVIDIA BlueField-4, thu hẹp khoảng cách giữa các tầng bộ nhớ GPU và bộ nhớ lưu trữ dùng chung. ICMS thiết lập một lớp bộ nhớ ngữ cảnh “G3.5” ở cấp độ pod, một tầng dựa trên bộ nhớ flash được kết nối Ethernet, được tối ưu hóa đặc biệt cho bộ nhớ đệm KV tạm thời, nhạy cảm với độ trễ, có kích thước cho dung lượng dùng chung petabyte trên mỗi pod GPU và được xây dựng để thường xuyên chuẩn bị trước dữ liệu trở lại bộ nhớ máy chủ và GPU nhằm tránh tình trạng tắc nghẽn khi giải mã.
Ở quy mô lớn, ICMS biến bộ nhớ đệm KV có thể tái sử dụng thành tài nguyên dùng chung của pod thay vì là gánh nặng riêng cho từng node, giúp cải thiện hiệu quả sử dụng và giảm thiểu việc tính toán lại dư thừa. NVIDIA báo cáo tốc độ xử lý token mỗi giây cao hơn tới 5 lần và hiệu quả năng lượng tốt hơn tới 5 lần so với các phương pháp lưu trữ truyền thống nhờ khả năng cung cấp và chuẩn bị trước KV một cách đáng tin cậy từ tầng chuyên dụng này.
- Tầng G3.5: Bộ nhớ flash gắn Ethernet được thiết kế chuyên dụng cho bộ nhớ đệm KV, nằm giữa các tầng cục bộ (HBM, DRAM, SSD cục bộ) và bộ nhớ dùng chung bền vững, đảm bảo ngữ cảnh luôn ở gần đủ để có thể tái sử dụng mà không phải trả “độ trễ G4”.
- Công nghệ BlueField-4: BlueField-4 vận hành mặt phẳng I/O KV và chấm dứt hiệu quả các giao thức NVMe-over-Fabrics và object/RDMA, giảm tải cho máy chủ trong khi vẫn đảm bảo việc truyền tải KV nhanh chóng, dễ dự đoán và an toàn.
- Kiến trúc Spectrum-X: Ethernet Spectrum-X cung cấp kết nối RDMA có độ trễ thấp, độ rung thấp và dễ dự đoán giữa các nút tính toán Rubin và các nút đích ICMS để truy cập KV dùng chung nhất quán trên toàn bộ cụm.
- Điều phối: NVIDIA Dynamo và NIXL phối hợp quản lý và chuẩn bị trước các khối KV trên toàn bộ hệ thống phân cấp, với DOCA cung cấp giao diện lưu trữ và truyền thông KV coi ngữ cảnh là một tài nguyên quan trọng hàng đầu.
Vận hành nhà máy AI như một hệ thống
BlueField-4 thiết lập cơ sở hạ tầng như một lớp kiến trúc hạng nhất của nhà máy AI. Bằng cách vận hành các lớp điều khiển, bảo mật, di chuyển dữ liệu và điều phối trên một lớp xử lý chuyên dụng, nó cho phép các nhà máy AI duy trì tính dự đoán được, an toàn và hiệu quả ở quy mô lớn.
Trong nền tảng Vera Rubin, NVLink định nghĩa hành vi mở rộng quy mô theo chiều dọc, các bộ chuyển mạch Ethernet ConnectX-9 và Spectrum-X điều khiển việc mở rộng quy mô theo chiều ngang và chiều rộng, còn BlueField-4 vận hành chính nhà máy AI.
Bộ chuyển mạch Ethernet Spectrum-6: Khả năng mở rộng theo chiều ngang và chiều dọc cho các nhà máy AI.
Các nhà máy AI cũng phải mở rộng quy mô vượt ra ngoài một hệ thống Vera Rubin NVL72 duy nhất và thường cần mở rộng trên các trung tâm dữ liệu phân tán về mặt địa lý. Hiệu suất khi đó không chỉ được quyết định bởi băng thông, mà còn bởi mức độ ổn định của mạng dưới lưu lượng AI đồng bộ và đột biến.
Để hỗ trợ cả việc triển khai nhà máy AI theo kiểu mở rộng quy mô và theo chiều ngang, nền tảng Vera Rubin giới thiệu NVIDIA Spectrum-X Ethernet Photonics, một thế hệ chuyển mạch Ethernet Spectrum-X mới dựa trên quang học đóng gói đồng thời, thúc đẩy kiến trúc Ethernet chuyên dụng của NVIDIA dành cho điện toán tăng tốc.

Spectrum-6 được thiết kế đặc biệt cho các tác vụ AI, nơi lưu lượng truy cập được đồng bộ hóa cao, có tính đột biến và không đối xứng. Spectrum-6 tăng gấp đôi băng thông trên mỗi chip chuyển mạch lên 102,4 Tb/s bằng cách sử dụng SerDes 200G PAM4, cho phép tạo ra các mạng có mật độ cổng cao, được tối ưu hóa cho các mô hình lưu lượng AI.
Băng thông hiệu dụng cao, khả năng đo lường chi tiết và khả năng cách ly hiệu năng được hỗ trợ bởi phần cứng cho phép hoạt động ổn định trong các hệ thống AI đa người dùng quy mô lớn, đồng thời vẫn hoàn toàn tuân thủ các tiêu chuẩn và tương thích với phần mềm mạng mở.
Mạng Ethernet Spectrum-X
Khác với Ethernet thông thường, Spectrum-X Ethernet cung cấp khả năng kết nối ổn định, độ trễ thấp và băng thông cao ở quy mô lớn thông qua kiểm soát tắc nghẽn tiên tiến, định tuyến thích ứng và hoạt động Ethernet không mất dữ liệu. Những khả năng này giúp giảm thiểu hiện tượng giật hình, độ trễ đuôi và mất gói dữ liệu dưới tải AI liên tục.
Được xây dựng trên nền tảng Spectrum-6, Spectrum-X Ethernet được thiết kế đồng bộ với nền tảng Vera Rubin để đảm bảo rằng hành vi định tuyến, kiểm soát tắc nghẽn và đo lường từ xa phản ánh các mô hình giao tiếp AI thực tế chứ không phải các giả định mạng doanh nghiệp truyền thống. Sự đồng bộ này cho phép hiệu năng mở rộng theo dõi hành vi ứng dụng, chứ không phải thông lượng tối đa lý thuyết.
Ethernet Spectrum-X cũng tích hợp công nghệ mở rộng quy mô Ethernet Spectrum-XGS, bổ sung khả năng kiểm soát tắc nghẽn dựa trên khoảng cách cho các triển khai AI quy mô lớn, phân tán về mặt địa lý. Khả năng đo từ xa đầu cuối và định tuyến xác định cho phép cân bằng tải hiệu quả giữa các địa điểm, giúp các nhà máy AI đa địa điểm hoạt động với hiệu suất cao.
Công nghệ quang tử Ethernet Spectrum-X: Định nghĩa lại hiệu quả mạng ở quy mô trí tuệ nhân tạo.
Công nghệ Spectrum-X Ethernet Photonics cải thiện đáng kể hiệu quả mạng bằng cách loại bỏ các bộ thu phát cắm rời và bộ định thời DSP. Công nghệ quang tử silicon tích hợp kết hợp với các mảng laser bên ngoài giúp giảm số lượng linh kiện và điểm lỗi so với các kiến trúc mạng dựa trên các bộ thu phát cắm rời truyền thống. Spectrum-X Ethernet Photonics mang lại:
- Hiệu suất năng lượng mạng tốt hơn ~5 lần
- Độ trễ đầu cuối thấp hơn
- Chất lượng tín hiệu được cải thiện đáng kể
Bằng cách giảm tổn hao quang học từ khoảng 22 dB xuống còn khoảng 4 dB, Spectrum-X Ethernet đạt được chất lượng tín hiệu tốt hơn tới 64 lần. Điều này cho phép thời gian hoạt động cao hơn, khả năng bảo trì đơn giản hơn với cáp MMC-12 mật độ cao và tổng chi phí sở hữu thấp hơn cho các cụm máy chủ huấn luyện và suy luận quy mô lớn.

Được xây dựng dựa trên các mô hình lưu lượng truy cập AI thực tế.
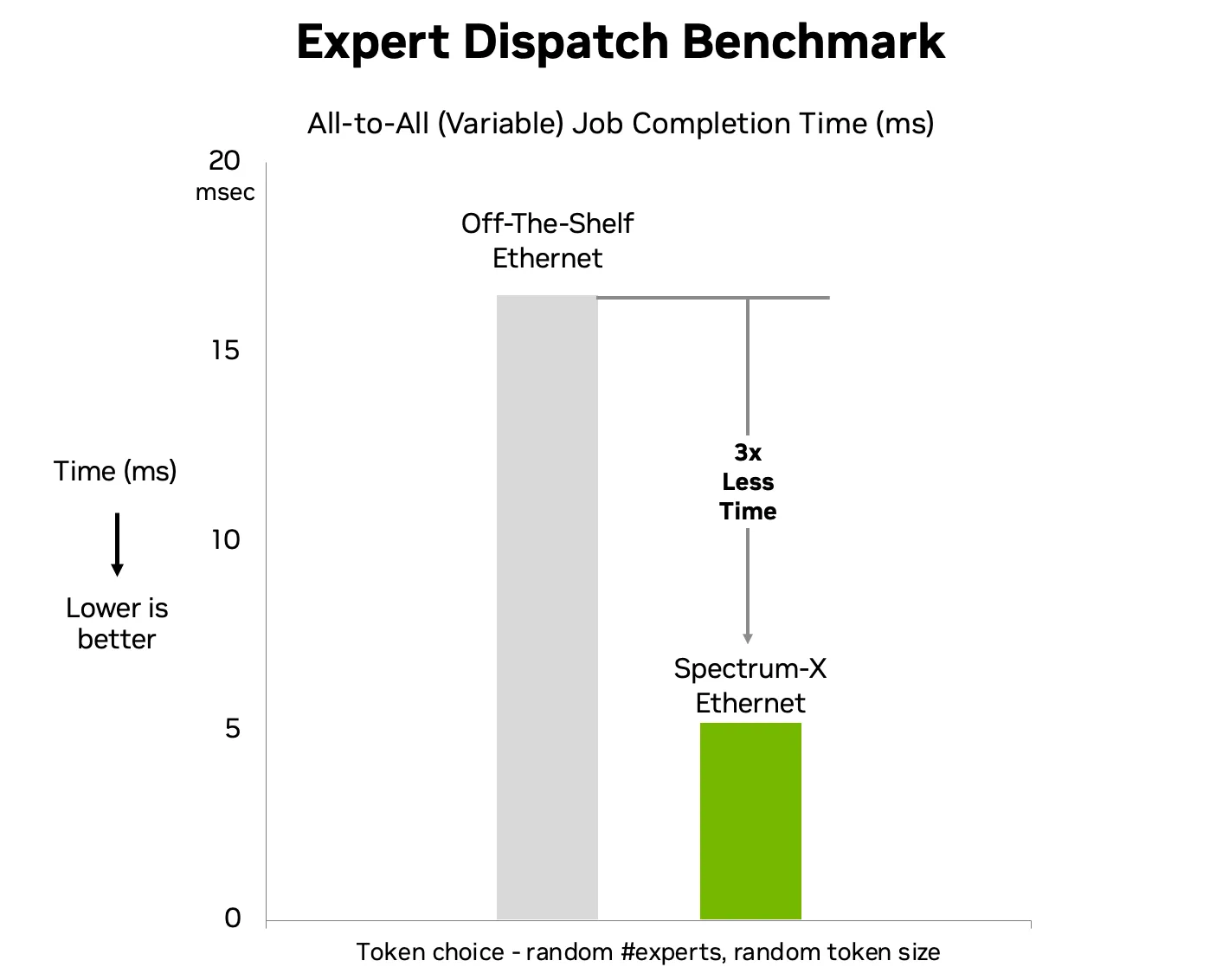
Quá trình huấn luyện và suy luận MoE hiện đại đưa vào một giai đoạn giao tiếp toàn diện biến đổi, được điều khiển bởi việc phân phối token chuyên gia ngẫu nhiên. Các khối lượng công việc này tạo ra lưu lượng truy cập đột biến cao, có thể làm quá tải các mạng Ethernet truyền thống, dẫn đến mất gói, tắc nghẽn và thời gian hoàn thành công việc bị suy giảm.
Công nghệ Spectrum-X Ethernet giải quyết vấn đề này ở cấp độ mạng thông qua việc kiểm soát tắc nghẽn phối hợp và định tuyến thích ứng trên các thiết bị chuyển mạch và điểm cuối. Kết quả là tốc độ hoàn thành công việc nhanh hơn đáng kể đối với việc điều phối chuyên gia và các hoạt động tập thể dưới tải trọng AI thực tế.
Nâng cấp chất lượng mạng mà không cần thiết kế lại toàn bộ hệ thống mạng.
Công nghệ Spectrum-X Ethernet phát triển qua từng thế hệ nhờ thiết kế đồng bộ từ đầu đến cuối, bao gồm chip chuyển mạch, quang học, SuperNIC và phần mềm hệ thống. Điều này mang lại những cải tiến đồng bộ về băng thông, tín hiệu và khả năng mở rộng mà không cần thiết kế lại cấu trúc mạng cơ bản, cho phép khách hàng mở rộng các cụm AI một cách có thể dự đoán được khi yêu cầu về hiệu năng tăng lên.
| Tính năng | Grace Blackwell | Vera Rubin | ||
| Thành phần chính | Dòng Spectrum-X SN5000 | ConnectX-8 SuperNIC | Dòng Spectrum-X SN6000 | ConnectX-9 SuperNIC |
| Chip | Spectrum-4 | ConnectX-8 | Spectrum-6 | ConnectX-9 |
| Băng thông tối đa | 51,2 Tb/s mỗi chip chuyển mạch (64 x 800 Gb/s) | 800 Gb/s (2 x 400G) mỗi GPU | 102,4 Tb/s mỗi chip chuyển mạch (128 x 800 Gb/s) | 1600 Gb/s (2 x 800 GB/s) trên mỗi GPU |
| SerDes | 100G PAM4 | 100/200G PAM4 | 200G PAM4 | 200G PAM4 |
| Giao thức | Ethernet | Ethernet, InfiniBand | Ethernet | Ethernet, InfiniBand |
| Kết nối | OSFP | OSFP, QSFP112 | OSFP | OSFP, QSFP112 |
Để tìm hiểu thêm về Spectrum-X Ethernet Photonics, hãy xem bài đăng trên blog này .
4. Từ chip đến hệ thống: Từ siêu chip NVIDIA Vera Rubin đến DGX SuperPOD
Hiệu năng của nhà máy AI không được quyết định bởi từng con chip riêng lẻ, mà bởi cách các chip đó được kết hợp thành các hệ thống có thể triển khai, vận hành và mở rộng một cách đáng tin cậy. Nền tảng Vera Rubin được thiết kế với tiến trình này trong tâm trí, tiến dần từ sự đổi mới ở cấp độ silicon đến các hệ thống quy mô rack và cuối cùng là triển khai nhà máy AI hoàn chỉnh.
Phần này theo dõi quá trình phát triển đó, bắt đầu từ siêu chip Vera Rubin như khối xây dựng điện toán nền tảng, sau đó mở rộng thông qua kiến trúc giá đỡ NVL72 và các kiến trúc mạng tích hợp của nó, và đỉnh điểm là NVIDIA DGX SuperPOD như đơn vị quy mô triển khai của một nhà máy AI. Ở mỗi bước, mục tiêu đều giống nhau: Bảo toàn hiệu quả và lợi ích sử dụng đạt được ở cấp độ chip khi hệ thống mở rộng ra ngoài.
Siêu chip NVIDIA Vera Rubin
Cốt lõi của nền tảng Rubin là siêu chip NVIDIA Vera Rubin, khối xây dựng điện toán nền tảng tích hợp chặt chẽ việc thực thi AI với việc truyền tải và điều phối dữ liệu băng thông cao. Mỗi siêu chip kết hợp hai GPU Rubin với một CPU Vera thông qua kết nối NVLink-C2C nhất quán bộ nhớ, xóa bỏ ranh giới CPU-GPU truyền thống thành một miền thực thi thống nhất, quy mô toàn rack.
Cách tiếp cận này không phải là mới đối với NVIDIA. Bắt đầu từ NVIDIA Grace Hopper và tiếp tục qua các thế hệ tiếp theo, sự tích hợp chặt chẽ giữa CPU và GPU luôn là nguyên tắc thiết kế cốt lõi để tối ưu hóa đồng thời khả năng tính toán, bộ nhớ và kết nối nhằm duy trì hiệu suất hoạt động trong các tác vụ huấn luyện và suy luận thực tế.
Trong siêu chip Vera Rubin, CPU hoạt động như một công cụ xử lý dữ liệu được kết nối chặt chẽ với quá trình thực thi GPU. Sự kết nối này cho phép phối hợp độ trễ thấp, truy cập bộ nhớ dùng chung và điều phối hiệu quả các tác vụ huấn luyện, hậu huấn luyện và suy luận. Thay vì hoạt động như một máy chủ bên ngoài, CPU Vera tham gia trực tiếp vào quá trình thực thi, xử lý việc di chuyển dữ liệu, lập lịch, đồng bộ hóa và luồng thực thi mà không gây ra tắc nghẽn.
Bằng cách tích hợp khả năng tính toán GPU với bộ xử lý dữ liệu CPU băng thông cao trên một bo mạch chủ duy nhất, siêu chip này cải thiện khả năng truy cập dữ liệu cục bộ, giảm chi phí phần mềm và duy trì hiệu suất cao hơn trong các giai đoạn thực thi khác nhau. Nó đóng vai trò là cầu nối kiến trúc giữa sự đổi mới ở cấp độ chip và trí thông minh ở quy mô rack.

Khay đựng dụng cụ Vera Rubin NVL72
Khay tính toán chuyển đổi siêu chip Vera Rubin thành một đơn vị có thể triển khai và bảo trì được, được thiết kế cho quy mô nhà máy AI. Mỗi khay tích hợp hai siêu chip, hệ thống cấp nguồn, làm mát, kết nối mạng và quản lý vào một cụm mô-đun không dây, được tối ưu hóa về mật độ, độ tin cậy và dễ vận hành.
Hệ thống phân phối chất lỏng bên trong được thiết kế lại và các khớp nối nhanh đa năng hỗ trợ tốc độ dòng chảy cao hơn đáng kể so với các thế hệ trước, cho phép hiệu suất ổn định dưới tải trọng công suất cao liên tục. Khay xử lý dạng mô-đun sử dụng các khoang trước và sau độc lập để đơn giản hóa việc lắp ráp và bảo trì. Mặc dù khay xử lý phải được ngắt kết nối trong quá trình bảo trì, thiết kế không dây dạng mô-đun giúp giảm thời gian bảo trì lên đến 18 lần. Việc lắp ráp trước đây mất hơn 1,5 giờ đối với Blackwell nay chỉ mất khoảng 5 phút với Vera Rubin.

Các SuperNIC ConnectX-9 cung cấp khả năng kết nối mở rộng băng thông cao (1,6 Tb/s mỗi GPU), trong khi các DPU BlueField-4 giảm tải các dịch vụ mạng, lưu trữ và bảo mật, cho phép CPU và GPU tập trung vào việc thực thi AI.

Khay chuyển mạch Vera Rubin NVL72 NVLink
Để biến nhiều khay điện toán thành một bộ tăng tốc quy mô rack duy nhất, Vera Rubin giới thiệu khay chuyển mạch NVLink 6.
Mỗi khay chuyển mạch tích hợp bốn chip chuyển mạch NVLink 6, giúp tăng gấp đôi băng thông mở rộng trên mỗi GPU cũng như khả năng tính toán trong mạng để tăng tốc các hoạt động tập thể trực tiếp bên trong kiến trúc mạng. Điều này rất quan trọng đối với định tuyến MoE, suy luận đòi hỏi đồng bộ hóa cao và các giai đoạn huấn luyện đòi hỏi nhiều giao tiếp, nơi hiệu quả mở rộng quy mô quyết định trực tiếp chi phí và độ trễ.
Bằng cách tích hợp khả năng mở rộng mạng như một thành phần quan trọng của giá đỡ, khay chuyển mạch NVLink đảm bảo hiệu suất có thể dự đoán được khi số lượng mô hình, kích thước lô và độ sâu suy luận tiếp tục tăng lên.

Thiết bị chuyển mạch Ethernet Spectrum-X dành cho các nhà máy AI mở rộng quy mô.
NVLink 6 cho phép 72 GPU hoạt động như một bộ tăng tốc duy nhất trong tủ rack. Spectrum-X Ethernet mở rộng khả năng đó ra ngoài phạm vi tủ rack, cho phép kết nối mở rộng quy mô với thông lượng cao và ổn định giữa các hàng và trung tâm dữ liệu, mà không gặp phải sự biến động thường thấy ở Ethernet truyền thống khi xử lý lưu lượng AI đồng bộ.
Mô hình giao tiếp trong nhà máy AI khác biệt về cơ bản so với khối lượng công việc của doanh nghiệp. Việc điều phối MoE, các hoạt động tập thể và các giai đoạn đồng bộ hóa nặng nề tạo ra các luồng dữ liệu đột biến, bất đối xứng và có độ tương quan cao, có thể khuếch đại tình trạng tắc nghẽn, độ trễ đuôi và sự dao động hiệu suất ở quy mô lớn. Ethernet Spectrum-X được thiết kế đặc biệt cho các mô hình này thông qua kiểm soát tắc nghẽn phối hợp, định tuyến thích ứng và đo lường từ đầu đến cuối, giúp duy trì băng thông hiệu quả cao và hiệu suất ổn định dưới tải trọng.
Trong nền tảng Vera Rubin NVL72, Spectrum-X được hiện thực hóa thông qua sự kết hợp giữa các bộ chuyển mạch Spectrum-6 và các thiết bị đầu cuối ConnectX-9 SuperNIC được tích hợp trong các nút tính toán. Cùng nhau, chúng tạo thành một hệ thống mở rộng được thiết kế chặt chẽ, nơi mà mạng lưới và các thiết bị đầu cuối hợp tác để định hình lưu lượng truy cập, phân lập khối lượng công việc và ngăn ngừa các điểm nóng, cho phép sử dụng hiệu quả cao trong các nhà máy AI đa nhiệm, đa người dùng.

NVIDIA DGX SuperPOD: đơn vị triển khai nhà máy AI
DGX SuperPOD đại diện cho bản thiết kế để hiện thực hóa nền tảng Vera Rubin ở quy mô triển khai. Được xây dựng từ tám hệ thống DGX Vera Rubin NVL72, nó xác định đơn vị tối thiểu mà tại đó hiệu quả kinh tế, độ tin cậy và hiệu suất của nhà máy AI hội tụ trong môi trường sản xuất.
Không giống như các cụm máy tính truyền thống được lắp ráp từ các thành phần riêng lẻ, DGX SuperPOD được thiết kế như một hệ thống hoàn chỉnh. Mỗi lớp, từ silicon và các kết nối đến điều phối và vận hành, đều được đồng thiết kế và kiểm định để mang lại khả năng sử dụng liên tục, độ trễ có thể dự đoán được và chuyển đổi năng lượng thành token hiệu quả ở quy mô lớn.
Trong mỗi hệ thống NVIDIA DGX Vera Rubin NVL72, 72 GPU Rubin hoạt động như một bộ tăng tốc quy mô rack thông qua NVLink 6. Spectrum-X Ethernet mở rộng nền tảng ra ngoài phạm vi rack với khả năng kết nối mở rộng quy mô tốc độ cao, cho phép nhiều hệ thống DGX Vera Rubin NVL72 được kết hợp thành một DGX SuperPOD. Được tích hợp với phần mềm NVIDIA Mission Control và bộ nhớ được chứng nhận, các yếu tố này tạo nên một khối xây dựng nhà máy AI đã được kiểm chứng, sẵn sàng cho sản xuất, có khả năng mở rộng lên đến hàng chục nghìn GPU.
Thiết kế này cho phép DGX SuperPOD cung cấp các khả năng thực sự của một nhà máy AI: hoạt động liên tục, khả năng bảo trì với thời gian hoạt động cao và hiệu suất ổn định trên các khối lượng công việc huấn luyện, sau huấn luyện và suy luận thời gian thực.

5. Kinh nghiệm về phần mềm và nhà phát triển
Vera Rubin cũng được thiết kế để thúc đẩy đổi mới mà không buộc các nhà phát triển phải thiết kế lại phần mềm của họ. Về cơ bản, nền tảng này duy trì khả năng tương thích ngược hoàn toàn với CUDA trên các thế hệ phần cứng, đảm bảo các mô hình, khung và quy trình làm việc hiện có hoạt động trơn tru đồng thời tự động hưởng lợi từ những cải tiến về khả năng tính toán, bộ nhớ và kết nối giữa các thế hệ.
Thư viện CUDA-X — nền tảng hiệu năng
Nền tảng CUDA bao gồm mô hình lập trình, thư viện cốt lõi và các ngăn xếp giao tiếp giúp tăng tốc ứng dụng và khai thác tối đa khả năng phân tán của hệ thống quy mô rack. Các nhà phát triển có thể lập trình GPU Rubin như các thiết bị riêng lẻ hoặc như một phần của miền NVLink 72 GPU duy nhất bằng cách sử dụng nccl" target="_self" rel="follow" data-wpel-link="internal">Thư viện Truyền thông Tập thể NVIDIA (NCCL) , Thư viện Truyền tải Suy luận NVIDIA (NIXL) và các tập thể nhận biết NVLink. Thiết kế này cho phép các mô hình mở rộng trên toàn bộ rack mà không cần phân vùng tùy chỉnh, các giải pháp thay thế dựa trên cấu trúc liên kết hoặc điều phối thủ công.

Ở lớp nhân và thư viện, NVIDIA cung cấp các khối xây dựng được tối ưu hóa cao cho các tác vụ AI đòi hỏi khắt khe nhất. Các thư viện như cudnn" target="_self" rel="follow" data-wpel-link="internal">NVIDIA cuDNN , cutlass/latest/" target="_self" rel="follow" data-wpel-link="internal">NVIDIA CUTLASS , FlashInfer và Transformer Engine mới mang lại hiệu quả tối ưu cho việc xử lý sự chú ý, kích hoạt và thực thi độ chính xác hẹp. Các thành phần này được kết nối chặt chẽ với Tensor Cores của Rubin, hệ thống con bộ nhớ HBM4 và kết nối NVLink 6, cho phép duy trì hiệu suất ổn định trên các tác vụ dày đặc, thưa thớt và đòi hỏi nhiều giao tiếp.
Nhờ sự kết hợp của các thư viện này, các nhà phát triển có thể tập trung vào hành vi của mô hình thay vì tinh chỉnh phần cứng cụ thể, đồng thời vẫn khai thác được hiệu năng tối đa từ nền tảng cơ bản.
Đào tạo quy mô lớn—từ nghiên cứu đến sản xuất với NVIDIA NeMo
Các framework cấp cao hơn được xây dựng trực tiếp trên nền tảng Vera Rubin để tối đa hóa năng suất và khả năng mở rộng của nhà phát triển. Các framework PyTorch và JAX được tích hợp sẵn khả năng tăng tốc NVIDIA, cho phép các quy trình huấn luyện, hậu huấn luyện và suy luận có thể mở rộng trên nhiều rack với những thay đổi mã tối thiểu.
Cốt lõi của bộ công cụ huấn luyện và tùy chỉnh của NVIDIA là NVIDIA NeMo Framework , cung cấp quy trình làm việc toàn diện để xây dựng, điều chỉnh, căn chỉnh và triển khai các mô hình lớn ở quy mô nhà máy AI. NeMo hợp nhất việc quản lý dữ liệu, huấn luyện phân tán quy mô lớn, căn chỉnh và tùy chỉnh tham số hiệu quả vào một khung duy nhất, hướng đến sản xuất. Thông qua NVIDIA NeMo Run , các nhà phát triển có thể cấu hình, khởi chạy và quản lý các thử nghiệm một cách nhất quán trên các môi trường cục bộ, cụm SLURM và các nhà máy AI dựa trên Kubernetes.
Đối với việc huấn luyện quy mô cực lớn, NeMo tích hợp chặt chẽ với NVIDIA Megatron Core , cung cấp công cụ huấn luyện phân tán cơ bản. Megatron Core cung cấp các chiến lược song song hóa tiên tiến, trình tải dữ liệu được tối ưu hóa và hỗ trợ các kiến trúc mô hình hiện đại bao gồm LLM dày đặc, MoE, mô hình không gian trạng thái và mạng đa phương thức. Sự tích hợp này cho phép NeMo mở rộng quy mô huấn luyện trên hàng nghìn GPU đồng thời trừu tượng hóa sự phức tạp của song song hóa và giao tiếp khỏi người dùng.
NeMo cũng hỗ trợ các quy trình hậu huấn luyện nâng cao, bao gồm học tăng cường và các kỹ thuật căn chỉnh như học tăng cường với phản hồi của con người (RLHF), tối ưu hóa ưu tiên trực tiếp (DPO), tối ưu hóa chính sách gần (PPO) và tinh chỉnh có giám sát. Những khả năng này cho phép các nhà phát triển chuyển đổi liền mạch từ giai đoạn tiền huấn luyện sang căn chỉnh và tùy chỉnh trong một khung duy nhất—mà không cần phải thiết kế lại các quy trình.
Để liên kết các quy trình làm việc trong hệ sinh thái, NVIDIA NeMo Megatron Bridge cho phép chuyển đổi và xác minh điểm kiểm tra hai chiều giữa định dạng Hugging Face và Megatron. Công cụ này cho phép các mô hình di chuyển một cách đáng tin cậy giữa các công cụ cộng đồng, huấn luyện dựa trên NeMo, học tăng cường và triển khai suy luận được tối ưu hóa, đồng thời bảo toàn tính chính xác và khả năng tái tạo.
Các khuôn khổ suy luận và tối ưu hóa—phục vụ trí tuệ thời gian thực
Nền tảng Vera Rubin được thiết kế để mang lại những lợi ích đáng kể cho các tác vụ suy luận hiện đại, ngày càng được định nghĩa bởi độ trễ thấp, khả năng xử lý đồng thời cao và thực thi đòi hỏi nhiều giao tiếp. Nền tảng này tích hợp với các khung suy luận mã nguồn mở và của NVIDIA được sử dụng rộng rãi—bao gồm SGLang, NVIDIA TensorRT-LLM, vLLM và NVIDIA Dynamo—để cho phép thực thi hiệu quả các tác vụ có ngữ cảnh dài, MoE và tác nhân khi phần mềm hỗ trợ được kích hoạt cùng với sự sẵn có của nền tảng.
NVIDIA Model Optimizer mở rộng hiệu năng suy luận thông qua lượng tử hóa, cắt tỉa, chưng cất và giải mã dự đoán, đồng thời chuyển đổi trực tiếp những tiến bộ về kiến trúc thành độ trễ thấp hơn và chi phí trên mỗi token thấp hơn. Ở lớp phục vụ, giao tiếp hỗ trợ NVLink, suy luận phân tách, định tuyến nhận biết LLM, chuyển tải bộ nhớ đệm KV sang bộ nhớ lưu trữ và khả năng tự động mở rộng quy mô của Kubernetes được cung cấp thông qua Dynamo – cho phép phục vụ quy mô lớn các khối lượng công việc đòi hỏi nhiều giao tiếp như suy luận MoE và các đường dẫn đa tác nhân.
Một nền tảng có thể lập trình, kích thước tủ rack, sẵn sàng cho nhà phát triển.
Kiến trúc của NVIDIA được thiết kế từ đầu để tối đa hóa hiệu năng phần mềm nền tảng và khả năng sử dụng cho nhà phát triển ở quy mô tủ rack. Bằng cách tích hợp trực tiếp phần mềm nền tảng và trải nghiệm nhà phát triển vào kiến trúc, nền tảng Vera Rubin không chỉ mạnh mẽ mà còn thiết thực trong việc triển khai và lập trình. Các nhà phát triển có thể tập trung vào các mô hình, tác nhân và dịch vụ thay vì sự phức tạp của cơ sở hạ tầng, trong khi người vận hành vẫn giữ quyền kiểm soát hiệu năng, độ tin cậy và hiệu quả ở quy mô nhà máy AI.
6. Vận hành ở quy mô nhà máy AI
Việc vận hành một nhà máy AI quy mô lớn đòi hỏi nhiều hơn là hiệu năng thô. Nó cần các hệ thống có thể hoạt động liên tục, an toàn, hiệu quả và có thể dự đoán được trong môi trường trung tâm dữ liệu thực tế. Nền tảng Vera Rubin được thiết kế không chỉ để cung cấp khả năng tính toán đột phá mà còn để duy trì khả năng đó theo thời gian thông qua độ tin cậy thông minh, bảo mật toàn diện, thiết kế tiết kiệm năng lượng và hệ sinh thái giá đỡ hoàn thiện. Cùng nhau, những khả năng này đảm bảo rằng các nhà máy AI được xây dựng trên nền tảng Vera Rubin có thể mở rộng nhanh chóng, hoạt động với sự gián đoạn tối thiểu và chuyển đổi năng lượng, cơ sở hạ tầng và phần cứng thành trí tuệ hữu ích ở quy mô công nghiệp.
Triển khai và vận hành
NVIDIA Mission Control tăng tốc mọi khía cạnh hoạt động của nhà máy AI, từ cấu hình triển khai Vera Rubin NVL72 đến tích hợp với các cơ sở vật chất và quản lý cụm máy chủ cũng như khối lượng công việc. Được hỗ trợ bởi phần mềm thông minh, tích hợp, các doanh nghiệp có được khả năng kiểm soát tốt hơn đối với các sự cố làm mát và nguồn điện, đồng thời định nghĩa lại khả năng phục hồi của cơ sở hạ tầng. Mission Control cho phép phản hồi nhanh hơn với khả năng phát hiện rò rỉ nhanh chóng, mở khóa quyền truy cập vào các cải tiến hiệu quả mới nhất của NVIDIA và tối đa hóa năng suất nhà máy AI với khả năng phục hồi tự động.

Mission Control cung cấp giải pháp đã được kiểm chứng giúp các doanh nghiệp đơn giản hóa và mở rộng quy mô triển khai và vận hành các nhà máy AI trong suốt vòng đời của cụm máy chủ:
- Quản lý khối lượng công việc liền mạch: Tăng cường khả năng quản lý khối lượng công việc cho người xây dựng mô hình với chức năng NVIDIA Run:ai giúp họ dễ dàng và đơn giản hóa quá trình này.
- Tối ưu hóa điện năng: Cân bằng yêu cầu điện năng và điều chỉnh hiệu năng GPU cho các loại khối lượng công việc khác nhau với các tùy chọn do nhà phát triển lựa chọn.
- Công cụ phục hồi tự động: Xác định, cô lập và khắc phục sự cố mà không cần can thiệp thủ công, đảm bảo năng suất tối đa và khả năng phục hồi của cơ sở hạ tầng.
- Bảng điều khiển tùy chỉnh: Theo dõi các chỉ số hiệu suất chính với quyền truy cập vào dữ liệu đo từ xa quan trọng về cụm máy chủ của bạn và các bảng điều khiển dễ thiết lập.
- Kiểm tra sức khỏe liên tục: Xác thực hiệu năng phần cứng và cụm máy chủ trong suốt vòng đời của cơ sở hạ tầng.
Phần mềm doanh nghiệp và hỗ trợ vòng đời sản phẩm
NVIDIA AI Enterprise cung cấp nền tảng phần mềm cấp doanh nghiệp cần thiết để vận hành các nhà máy AI quy mô lớn. Nó cung cấp một bộ phần mềm được kiểm chứng và hỗ trợ, bao gồm các thư viện phát triển ứng dụng, khung phần mềm và dịch vụ vi mô, cũng như phần mềm cơ sở hạ tầng để quản lý GPU. Điều này cho phép hiệu suất, bảo mật và tính ổn định có thể dự đoán được cho các triển khai AI trong môi trường sản xuất.
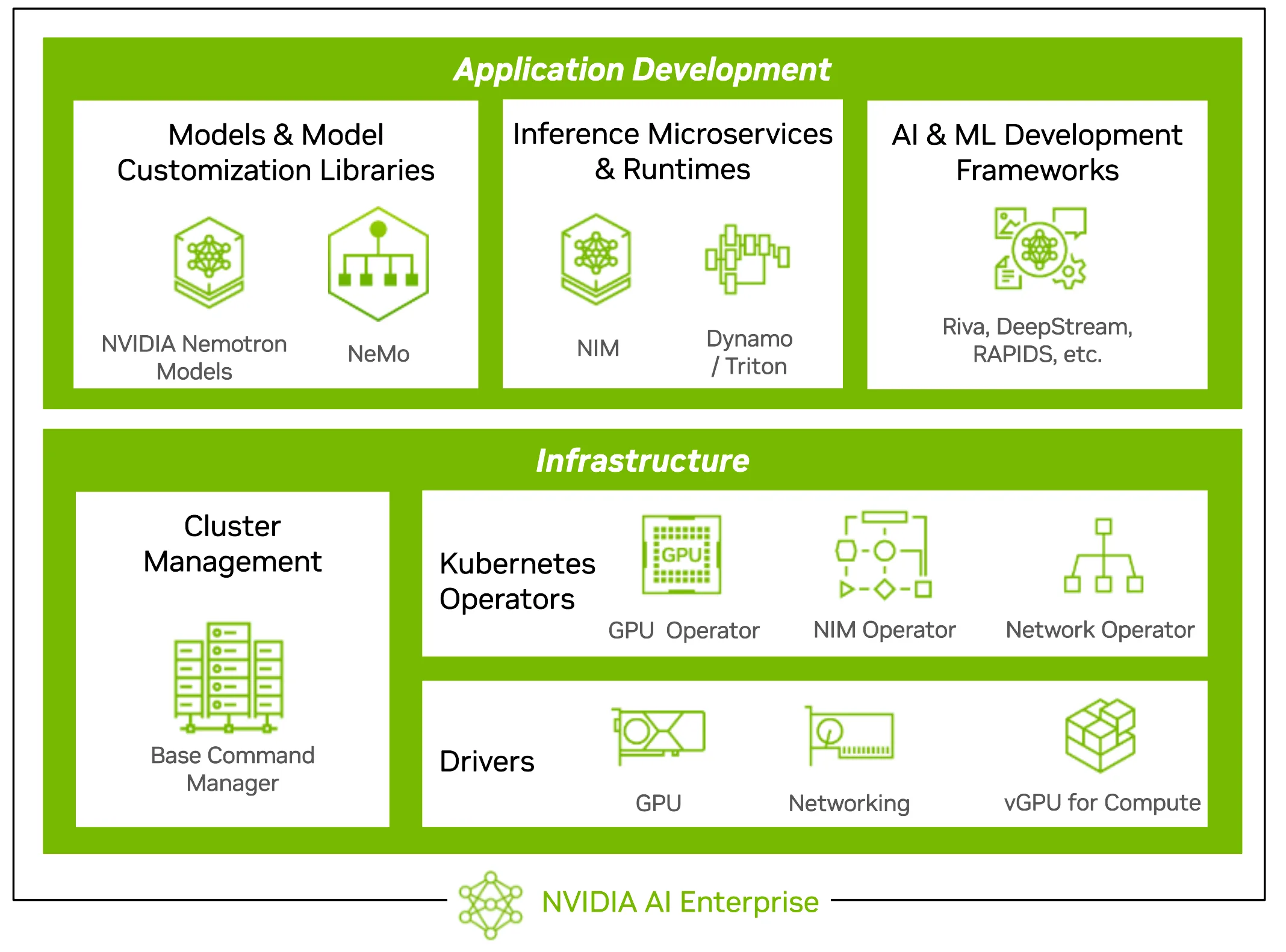
Đối với việc phát triển AI dạng tác nhân, NVIDIA AI Enterprise bao gồm NVIDIA NIM, NeMo và các thư viện cũng như dịch vụ vi mô được đóng gói trong container khác, cho phép tối ưu hóa suy luận, huấn luyện mô hình và tùy chỉnh thông qua các API tiêu chuẩn. Với sự hỗ trợ cho các mô hình AI của NVIDIA, đối tác và cộng đồng, các dịch vụ vi mô NIM cho phép các doanh nghiệp triển khai khả năng AI dạng tác nhân nhanh hơn.
Ngoài ra, các bộ công cụ phát triển ứng dụng (SDK), khung phần mềm và thư viện giúp chuyển đổi khả năng kiến trúc của nền tảng Vera Rubin thành những cải tiến về hiệu năng. CUDA, Transformer Engine, cuDNN và các thư viện liên quan được xác nhận là một hệ thống tăng tốc, đảm bảo rằng những tiến bộ về phần cứng được tự động hiện thực hóa bởi các khung phần mềm và dịch vụ cấp cao hơn.
Đối với quản lý cơ sở hạ tầng, NVIDIA AI Enterprise tích hợp với Kubernetes thông qua các operator được thiết kế chuyên dụng và các trình điều khiển GPU, mạng và ảo hóa đã được kiểm chứng. Các thành phần này cho phép vận hành đa người dùng an toàn, điều phối khối lượng công việc và khả năng quan sát trên toàn cụm, đồng thời cho phép người vận hành tối đa hóa việc sử dụng trong khi vẫn duy trì độ tin cậy và tuân thủ các quy định.
Được cung cấp kèm theo hỗ trợ dài hạn, cập nhật bảo mật thường xuyên và xác thực khả năng tương thích trên nhiều thế hệ phần cứng, NVIDIA AI Enterprise đóng vai trò là xương sống phần mềm của các nhà máy AI của NVIDIA. Nó biến các hệ thống quy mô rack thành một nền tảng sản xuất có thể lập trình, bảo mật và vận hành được trên các môi trường trung tâm dữ liệu, đám mây và biên.
NVIDIA AI Enterprise được hỗ trợ bởi một hệ sinh thái đối tác rộng lớn, bao gồm các nhà tích hợp giải pháp, nền tảng dữ liệu và doanh nghiệp, nhà cung cấp đám mây lai và đa đám mây, và các giải pháp AIOps. Nó tích hợp liền mạch với các hệ thống phần mềm doanh nghiệp hiện có để cho phép triển khai AI ở cấp độ sản xuất và đẩy nhanh thời gian đưa sản phẩm ra thị trường.
Độ tin cậy, tính sẵn có và khả năng bảo trì
Các nhà máy AI không còn là các hệ thống xử lý theo lô có thể dành thời gian bảo trì. Chúng là các môi trường hoạt động liên tục, thực hiện huấn luyện, suy luận thời gian thực, truy xuất và phân tích. Vera Rubin NVL72 được thiết kế cho thực tế này, giới thiệu kiến trúc RAS quy mô rack được thiết kế để tối đa hóa thời gian hoạt động, cải thiện hiệu suất, lượng công việc AI hữu ích thực sự được hoàn thành theo thời gian và đảm bảo hoàn thành có thể dự đoán được các khối lượng công việc AI dài hạn.
Trong ngữ cảnh này, goodput phản ánh hiệu quả chuyển đổi thời gian hoạt động của hệ thống thành các bước huấn luyện hoàn chỉnh, các yêu cầu suy luận đã hoàn thành và các token được cung cấp, mà không bị mất mát do khởi động lại công việc, hoàn tác điểm kiểm tra, các tác vụ chậm trễ hoặc suy giảm hiệu suất do lỗi thành phần. Ngay cả những gián đoạn ngắn hoặc lỗi cục bộ cũng có thể làm giảm đáng kể goodput khi khối lượng công việc trải rộng trên hàng nghìn GPU và chạy trong nhiều ngày hoặc nhiều tuần.
Khả năng phục hồi trong nền tảng Vera Rubin được thiết kế toàn diện, bao gồm cả chip bán dẫn, kết nối và kiến trúc hệ thống vật lý. Kết quả là một phương pháp tiếp cận thống nhất, thông minh về độ tin cậy, cho phép hệ thống cô lập lỗi, định tuyến lại lưu lượng truy cập và tiếp tục thực hiện khối lượng công việc mà không bị gián đoạn, đảm bảo không có thời gian ngừng hoạt động theo kế hoạch ở quy mô tủ rack trong khi vẫn duy trì thông lượng ổn định và khả năng hoàn thành công việc có thể dự đoán được.
Khả năng phục hồi quy mô tủ rack: Được thiết kế từ đầu.
Vera Rubin NVL72 được xây dựng trên thiết kế giá đỡ NVIDIA MGX thế hệ thứ ba, coi độ tin cậy và khả năng bảo trì là những yêu cầu kiến trúc hàng đầu. Các khay xử lý, khay chuyển mạch NVLink và cơ sở hạ tầng nguồn điện và làm mát đều được thiết kế dạng mô-đun, có thể thay thế nóng và được thiết kế để thay thế tại chỗ mà không cần xả hết tài nguyên trong giá đỡ hoặc làm gián đoạn khối lượng công việc đang hoạt động.
Như minh họa trong hình động bên dưới, kiến trúc khay điện toán không dây, không ống dẫn, không quạt giúp loại bỏ nhiều kết nối PCIe, mạng và quản lý thủ công bên trong khay, giảm thiểu sự phức tạp thường gặp trong quá trình lắp ráp và bảo trì ở các thiết kế khay có dây trước đây. Việc đơn giản hóa về mặt cơ khí này cho phép lắp ráp nhanh hơn tới 18 lần so với các kiến trúc khay thế hệ trước và giảm đáng kể thời gian bảo trì tại chỗ, rút ngắn thời gian triển khai và chi phí vận hành liên tục.
Hệ sinh thái hoàn thiện với hơn 80 đối tác MGX đảm bảo khả năng sản xuất toàn cầu, sự sẵn sàng về dịch vụ và triển khai có thể mở rộng, cho phép các nhà máy AI nhanh chóng tăng tốc trong khi vẫn duy trì độ tin cậy ổn định ở quy mô lớn.

Khả năng phục hồi thông minh trên toàn bộ hệ thống liên kết.
Ở cấp độ hệ thống, NVIDIA NVLink Intelligent Resiliency cho phép các rack vẫn hoạt động đầy đủ trong quá trình bảo trì, lắp đặt một phần thiết bị hoặc thay thế linh kiện. Sử dụng định tuyến dựa trên phần mềm và khả năng chuyển đổi dự phòng thông minh, lưu lượng truy cập được định tuyến lại một cách linh hoạt xung quanh các lỗi mà không làm gián đoạn các tác vụ huấn luyện hoặc suy luận đang hoạt động.
Khả năng này rất quan trọng khi các nhà máy AI mở rộng quy mô lên đến hàng nghìn GPU. Thay vì coi các sự cố gián đoạn như những sự kiện làm dừng toàn bộ hệ thống, hệ thống sẽ thích ứng trong thời gian thực, duy trì mức độ sử dụng cao và hiệu suất có thể dự đoán được ngay cả khi các thành phần được bảo trì hoặc thay thế để cải thiện hiệu suất.
Giám sát tình trạng hoạt động ở cấp độ silicon với thời gian ngừng hoạt động bằng không.
Cốt lõi của kiến trúc này là Công cụ Độ tin cậy, Khả dụng và Khả năng mở rộng (RAS) thế hệ thứ hai của GPU Rubin, cung cấp khả năng giám sát tình trạng hoạt động liên tục trong hệ thống mà không cần tắt GPU. Việc kiểm tra tình trạng hoạt động được thực hiện trong các khoảng thời gian thực thi nhàn rỗi, cho phép chẩn đoán đầy đủ mà không ảnh hưởng đến khối lượng công việc đang chạy.
Công cụ RAS hỗ trợ sửa chữa SRAM tại chỗ và tự kiểm tra không gián đoạn trong quá trình thực thi, giúp tăng thời gian trung bình hiệu quả giữa các lần lỗi và cải thiện năng suất hệ thống tổng thể. Khả năng này đặc biệt quan trọng đối với các tác vụ huấn luyện kéo dài và các dịch vụ suy luận liên tục, nơi các gián đoạn ngoài kế hoạch có thể gây tốn kém hoặc không thể chấp nhận được.
CPU Vera bổ sung khả năng phục hồi ở cấp độ GPU bằng cách xác thực lõi CPU trong hệ thống, giảm thời gian chẩn đoán và bộ nhớ SOCAMM LPDDR5X được thiết kế để cải thiện khả năng bảo trì và phân lập lỗi.
Vận hành dự đoán ở quy mô nhà máy AI
Các khả năng phần cứng này được kết hợp với khả năng quản lý dự đoán dựa trên trí tuệ nhân tạo của NVIDIA, phân tích hàng ngàn tín hiệu đo từ xa phần cứng và phần mềm trên toàn bộ hệ thống. Các vấn đề tiềm ẩn được xác định sớm, định vị chính xác và giải quyết chủ động. Người vận hành có thể cân bằng lại khối lượng công việc, điều chỉnh chiến lược điểm kiểm tra, kích hoạt dung lượng dự phòng hoặc lên lịch bảo trì mà không ảnh hưởng đến mục tiêu mức độ dịch vụ.
Nhờ sự kết hợp các khả năng này, RAS chuyển đổi từ một quy trình phản ứng thành một hệ thống thông minh, có khả năng dự đoán, giúp giảm thiểu thời gian ngừng hoạt động, giảm độ phức tạp trong vận hành và đảm bảo các tác vụ AI hoàn thành đúng tiến độ.
Với Vera Rubin NVL72, độ tin cậy không còn là yếu tố hạn chế khả năng mở rộng. Từ chip bán dẫn đến hệ thống, nền tảng này được thiết kế để duy trì hoạt động liên tục, hiệu quả và ổn định của các nhà máy AI ở quy mô chưa từng có.
Điện toán bảo mật toàn diện
Khi các nhà máy AI đi vào sản xuất, các yêu cầu bảo mật mở rộng từ việc bảo vệ các thiết bị riêng lẻ sang bảo vệ toàn bộ hệ thống hoạt động liên tục ở quy mô lớn. Các tác vụ AI hiện đại thường xuyên xử lý dữ liệu huấn luyện độc quyền, nội dung được kiểm soát và các mô hình có giá trị cao, thường trong môi trường chia sẻ hoặc đám mây, nơi cơ sở hạ tầng không thể được tin tưởng một cách tuyệt đối. Đáp ứng các yêu cầu này đòi hỏi bảo mật bao trùm toàn bộ phần cứng, kết nối và phần mềm hệ thống, mà không gây ra suy giảm hiệu năng hoặc ma sát trong vận hành.
Vera Rubin NVL72 được thiết kế với khả năng điện toán bảo mật toàn diện làm nền tảng, mở rộng sự tin cậy từ các thành phần riêng lẻ đến toàn bộ giá đỡ thiết bị.
Điện toán bảo mật thế hệ thứ ba: bảo mật cấp độ tủ rack
Như hình minh họa bên dưới, Vera Rubin NVL72 mở rộng khả năng tính toán bảo mật vượt ra ngoài các thiết bị riêng lẻ để tạo ra một môi trường thực thi đáng tin cậy thống nhất, quy mô tủ rack, bao gồm CPU, GPU và các kết nối liên mạng. Thiết kế này cho phép các tác vụ AI nhạy cảm chạy an toàn ở quy mô lớn với hiệu năng gần như hiệu năng gốc, ngay cả trong môi trường chia sẻ hoặc điện toán đám mây.
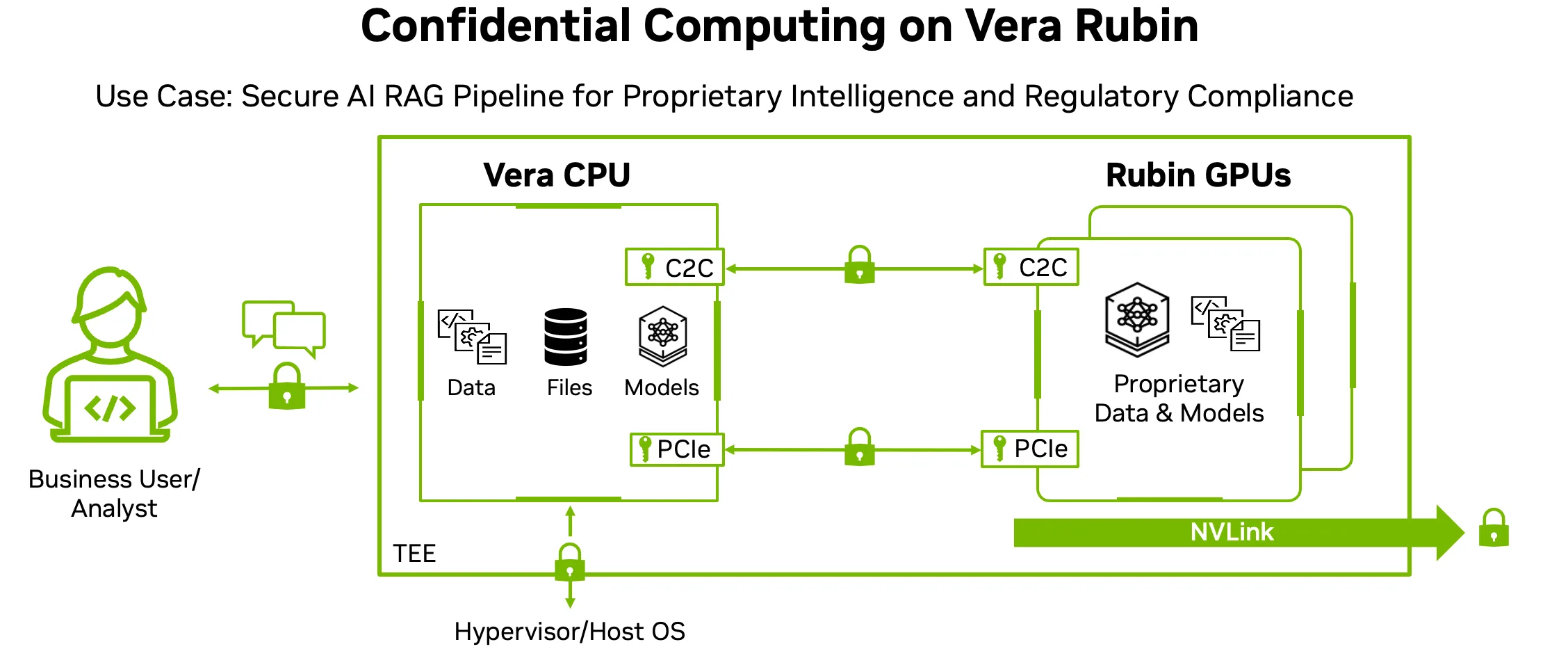
Các nhà máy AI ngày càng xử lý dữ liệu độc quyền, nội dung được kiểm soát chặt chẽ và các mô hình quan trọng không thể bị lộ, ngay cả với cơ sở hạ tầng mà chúng đang vận hành. Vera Rubin NVL72 đáp ứng yêu cầu này bằng cách cung cấp mã hóa đầu cuối trên các đường dẫn CPU-GPU, GPU-GPU và I/O thiết bị, cho phép các doanh nghiệp triển khai các quy trình đào tạo, suy luận, truy xuất và phân tích an toàn mà không làm giảm thông lượng hoặc độ trễ.
Từ bảo mật cấp độ thiết bị đến sự tin cậy ở quy mô tủ rack
NVIDIA đã nâng cao bảo mật GPU qua nhiều thế hệ. Hopper giới thiệu khả năng tính toán bảo mật hiệu năng cao cho GPU. Blackwell mở rộng các khả năng này, loại bỏ sự đánh đổi truyền thống giữa bảo mật và hiệu năng. Vera Rubin NVL72 hoàn thiện quá trình này bằng cách hợp nhất bảo mật CPU và GPU vào một miền tin cậy duy nhất trên toàn bộ hệ thống rack.
Cách tiếp cận ở cấp độ rack này đảm bảo rằng các mô hình độc quyền, dữ liệu huấn luyện, các embedding và các gợi ý suy luận được bảo vệ không chỉ khỏi các người dùng khác mà còn khỏi chính cơ sở hạ tầng của nhà cung cấp dịch vụ đám mây.
Chứng thực mật mã và sự tuân thủ có thể kiểm chứng
Vera Rubin NVL72 tích hợp với dịch vụ xác thực từ xa của NVIDIA (NRAS) để cung cấp bằng chứng mật mã về tính toàn vẹn của hệ thống. Các tổ chức có thể xác minh rằng CPU, GPU, NIC, firmware, trình điều khiển và khối lượng công việc đang chạy phù hợp với các phép đo tham chiếu tốt đã được NVIDIA cung cấp, đạt được kiến trúc không tin cậy (zero trust) ở quy mô tủ rack.
Nền tảng này hỗ trợ cả xác thực theo yêu cầu thông qua các dịch vụ NVIDIA Attestation Cloud và các mô hình triển khai yêu cầu kết quả được lưu vào bộ nhớ đệm hoặc hoạt động hoàn toàn tách biệt khỏi mạng. Tính linh hoạt này cho phép các doanh nghiệp đáp ứng các yêu cầu nghiêm ngặt về quy định, tuân thủ và chủ quyền dữ liệu trong khi vẫn duy trì hiệu quả hoạt động.
Bảo mật thống nhất trên toàn bộ giá đỡ thiết bị.
Vera Rubin NVL72 thiết lập một miền bảo mật thống nhất bằng cách kết hợp các tiêu chuẩn ngành và công nghệ của NVIDIA, bao gồm:
- Giao thức bảo mật giao diện thiết bị TEE (TDISP) để đảm bảo độ tin cậy ở cấp độ thiết bị.
- Tính toàn vẹn PCIe và mã hóa dữ liệu (IDE) cho I/O an toàn
- Mã hóa NVLink-C2C để bảo vệ giao tiếp giữa CPU và GPU, cũng như giữa các CPU với nhau.
- Mã hóa NVLink đảm bảo truyền dữ liệu an toàn giữa các GPU ở quy mô lớn.
Nhờ sự kết hợp các khả năng này, Vera Rubin NVL72 tạo ra một môi trường thực thi đáng tin cậy, thống nhất và được mã hóa hoàn toàn, được thiết kế để mở rộng quy mô đáp ứng các mô hình AI lớn nhất thế giới và các khối lượng công việc doanh nghiệp đòi hỏi khắt khe nhất. Từ thiết bị của người dùng đến các nhà máy AI quy mô đám mây, Vera Rubin NVL72 cung cấp khả năng điện toán bảo mật toàn diện, bảo vệ mọi loại dữ liệu, ngay cả những khối lượng công việc nhạy cảm nhất, bất kể nó được chạy ở đâu.
Năng lượng cho các token: đổi mới về nhiệt và điện năng
Các nhà máy AI có thể tiêu thụ hàng trăm megawatt điện năng. Tuy nhiên, khi điện năng đến được các GPU thực hiện công việc, khoảng 30% bị thất thoát do chuyển đổi, phân phối và làm mát. Năng lượng này bị tiêu thụ bởi các hệ thống hỗ trợ tính toán nhưng không trực tiếp tạo ra token, đơn vị cơ bản của đầu ra AI. Được gọi là năng lượng ký sinh, nó đại diện cho hàng tỷ đô la doanh thu tiềm năng bị lãng phí ở quy mô lớn.
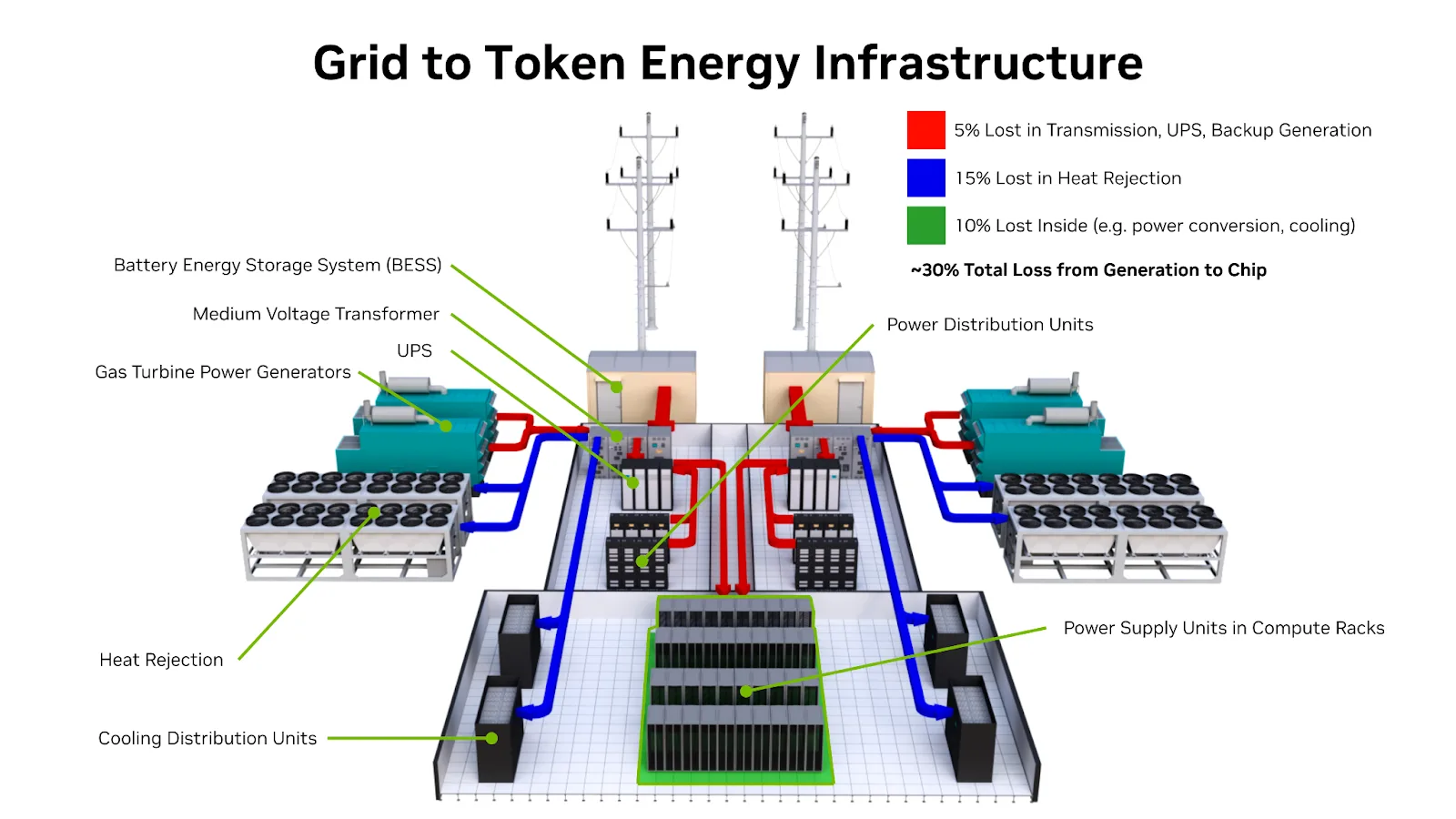
Mỗi watt bị lãng phí là một watt có thể được sử dụng để tạo ra token. Khi trí tuệ nhân tạo trở thành động lực chính trong việc tạo ra tri thức, việc cải thiện hiệu quả năng lượng sẽ trực tiếp dẫn đến thông lượng cao hơn, chi phí mỗi token thấp hơn và tính bền vững tốt hơn.
Việc cắt giảm năng lượng tiêu hao đồng nghĩa với việc cung cấp nhiều năng lượng hữu ích hơn cho GPU, những cỗ máy tạo ra token. Nền tảng Vera Rubin được thiết kế để giảm thiểu những chi phí ẩn này thông qua các đường dẫn năng lượng đơn giản hơn, hệ thống làm mát hiệu quả cao hơn và khả năng điều phối cấp hệ thống được thiết kế cho các nhà máy AI hoạt động liên tục.
Các trung tâm dữ liệu truyền thống phụ thuộc rất nhiều vào làm mát bằng không khí, điều này tiêu tốn một lượng năng lượng đáng kể để lưu thông và điều hòa không khí. Tương tự như Blackwell, hệ thống Vera Rubin NVL72 sử dụng làm mát bằng chất lỏng trực tiếp (DLC) một pha, sử dụng nước ấm với nhiệt độ cấp nước là 45 độ C. Làm mát bằng chất lỏng thu nhiệt hiệu quả hơn nhiều so với không khí, và bằng cách duy trì nhiệt độ làm mát 45 độ của Blackwell, các trung tâm dữ liệu có thể làm mát nước bằng không khí xung quanh. Điều này dẫn đến tiết kiệm đáng kể chi phí, độ phức tạp và năng lượng so với các giải pháp khác yêu cầu làm mát bằng chất lỏng ở nhiệt độ 35 độ.
Dựa trên thiết kế làm mát bằng chất lỏng của Blackwell, Vera Rubin tiếp tục nâng cao hiệu quả làm mát bằng cách tăng gần gấp đôi hiệu suất tản nhiệt trong cùng kích thước giá đỡ mà không làm tăng thêm độ phức tạp hoặc chi phí làm mát. Điều này đảm bảo khả năng tản nhiệt nhanh chóng dưới tải trọng công việc cực cao và liên tục, ngăn ngừa hiện tượng giảm hiệu năng do quá nhiệt và duy trì hiệu năng ổn định. Ít năng lượng tiêu hao cho việc làm mát đồng nghĩa với việc có nhiều năng lượng hơn dành cho tính toán và mức độ sử dụng bền vững cao hơn trong toàn bộ hệ thống AI.
Làm mịn điện năng ở cấp độ tủ rack và lưu trữ năng lượng ở cấp độ địa điểm
Khối lượng công việc của AI vốn dĩ rất năng động. Quá trình huấn luyện quy mô lớn tạo ra các giai đoạn giao tiếp đồng bộ giữa tất cả các thành phần với mức tiêu thụ điện năng khổng lồ, trong khi quá trình suy luận tạo ra các đợt tăng đột biến nhu cầu năng lượng mạnh mẽ và không ổn định.
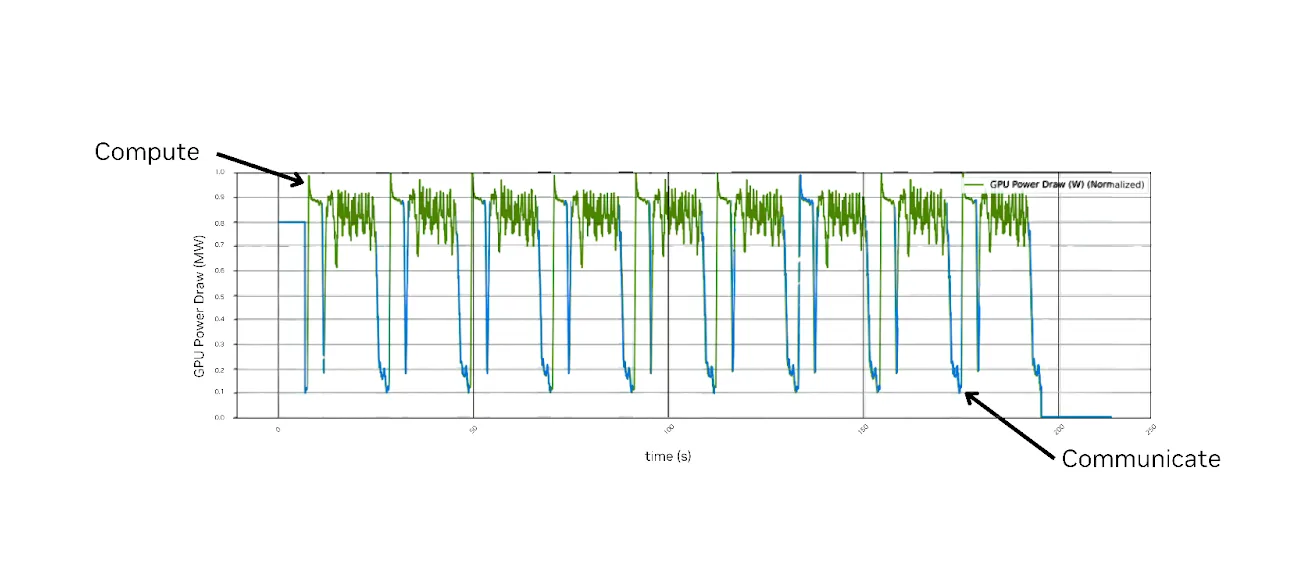
Nếu không có biện pháp giảm thiểu, những biến động này có thể gây áp lực lên mạng lưới phân phối điện, vi phạm các ràng buộc của lưới điện, hoặc buộc các nhà điều hành phải xây dựng cơ sở hạ tầng quá mức hoặc hạn chế hiệu năng của GPU, cả hai đều gây lãng phí năng lượng và hạn chế khả năng tính toán có thể triển khai.
Các nhà máy AI của Vera Rubin giải quyết thách thức này bằng một phương pháp tiếp cận đa tầng.
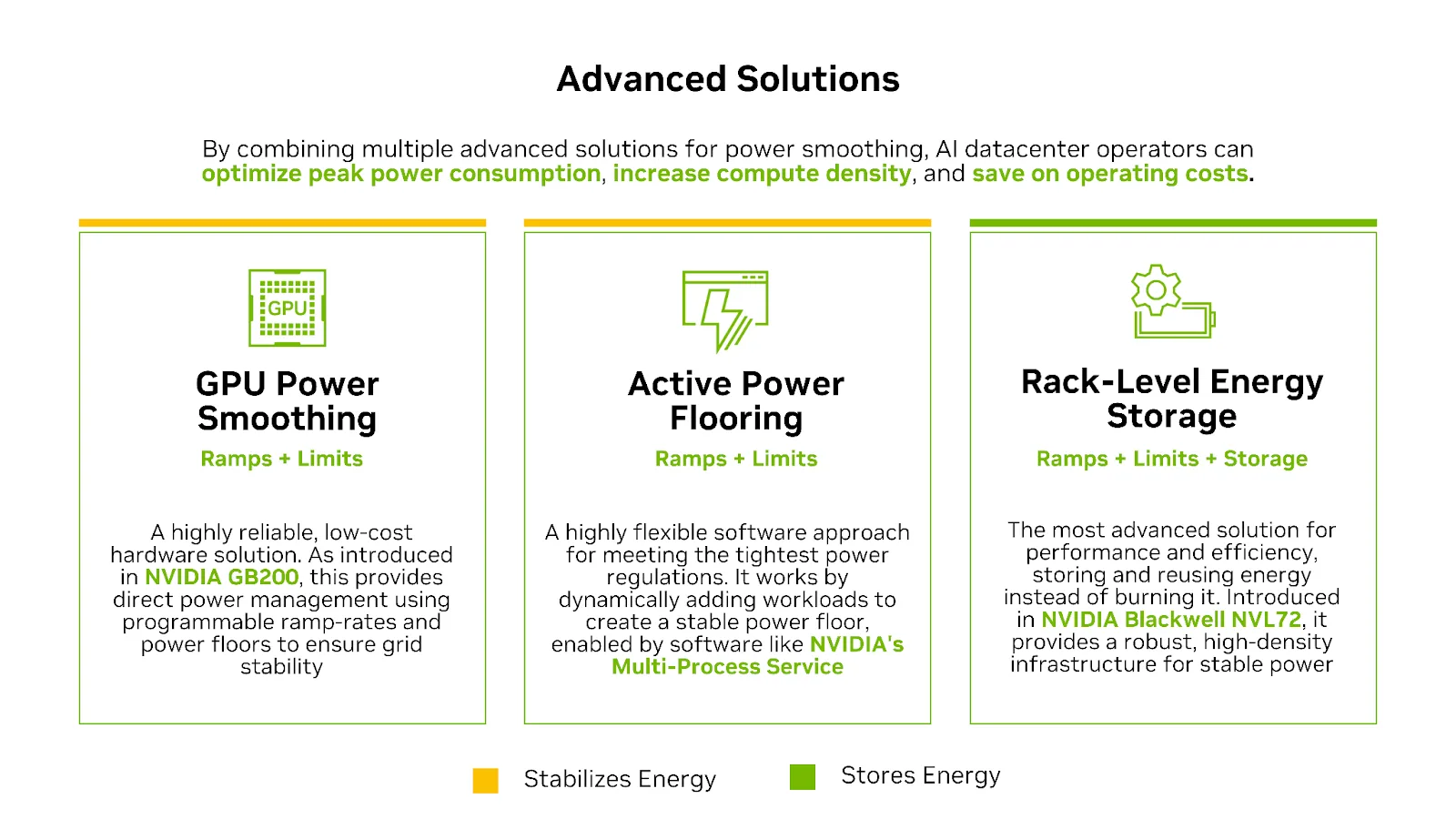
Ở cấp độ rack, Vera Rubin NVL72 làm giảm sự dao động điện năng bằng cách làm mịn điện năng và tích hợp bộ đệm năng lượng cục bộ nhiều hơn khoảng 6 lần so với Blackwell Ultra, hấp thụ các biến động điện năng nhanh chóng trực tiếp tại nguồn. Hình dưới đây cho thấy hiệu quả của việc làm mịn điện năng ở cấp độ rack trong hoạt động: sự dao động điện năng của khối lượng công việc AI được đồng bộ hóa được định hình lại thành các đường dốc được kiểm soát, giới hạn bởi mức điện năng trần và sàn ổn định, với bộ đệm năng lượng cục bộ hấp thụ các biến động nhanh chóng tại nguồn. Kết quả là một hồ sơ điện năng mượt mà hơn, dễ dự đoán hơn, giúp việc thực thi GPU phù hợp với các ràng buộc của trung tâm dữ liệu và lưới điện.
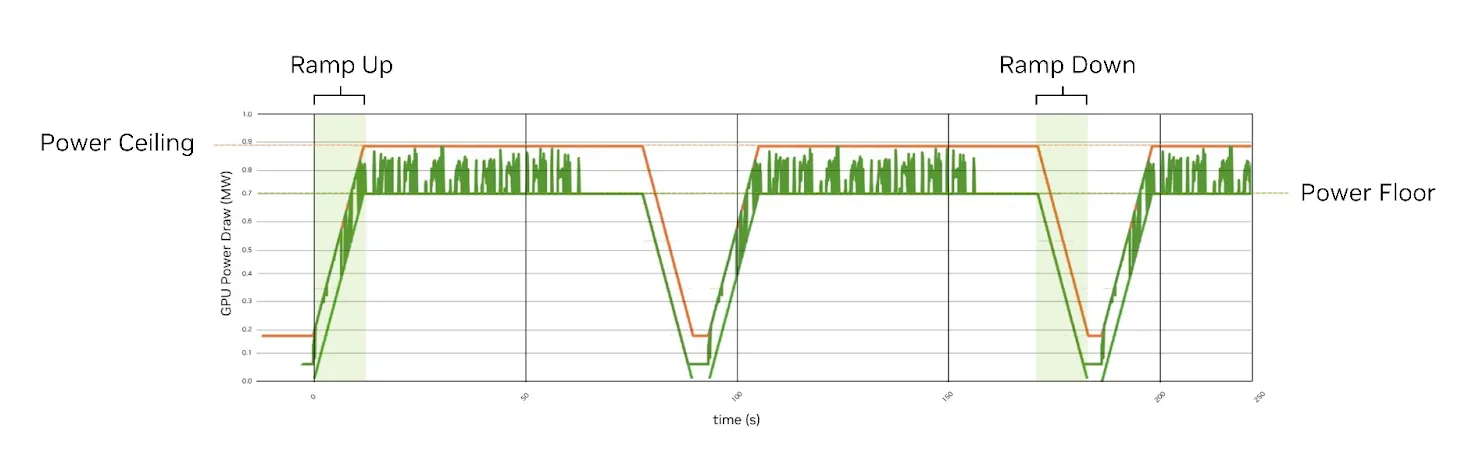
Hình dưới đây phân tích hành vi này thành ba cơ chế bổ sung cho nhau, tạo nên khả năng đó. Cùng nhau, việc kiểm soát quá trình tăng giảm công suất, giới hạn được thực thi và lưu trữ năng lượng cục bộ hoạt động như một hệ thống phối hợp, giảm nhu cầu tiêu thụ điện năng cao điểm, hạn chế vi phạm tốc độ tăng giảm công suất và ổn định việc cung cấp điện mà không làm giảm hiệu suất. Các cơ chế này cho phép các nhà máy AI lập kế hoạch dựa trên công suất ổn định thay vì các đỉnh điểm tiêu thụ điện năng tồi tệ nhất, trực tiếp tăng khả năng tính toán có thể triển khai trên mỗi megawatt.
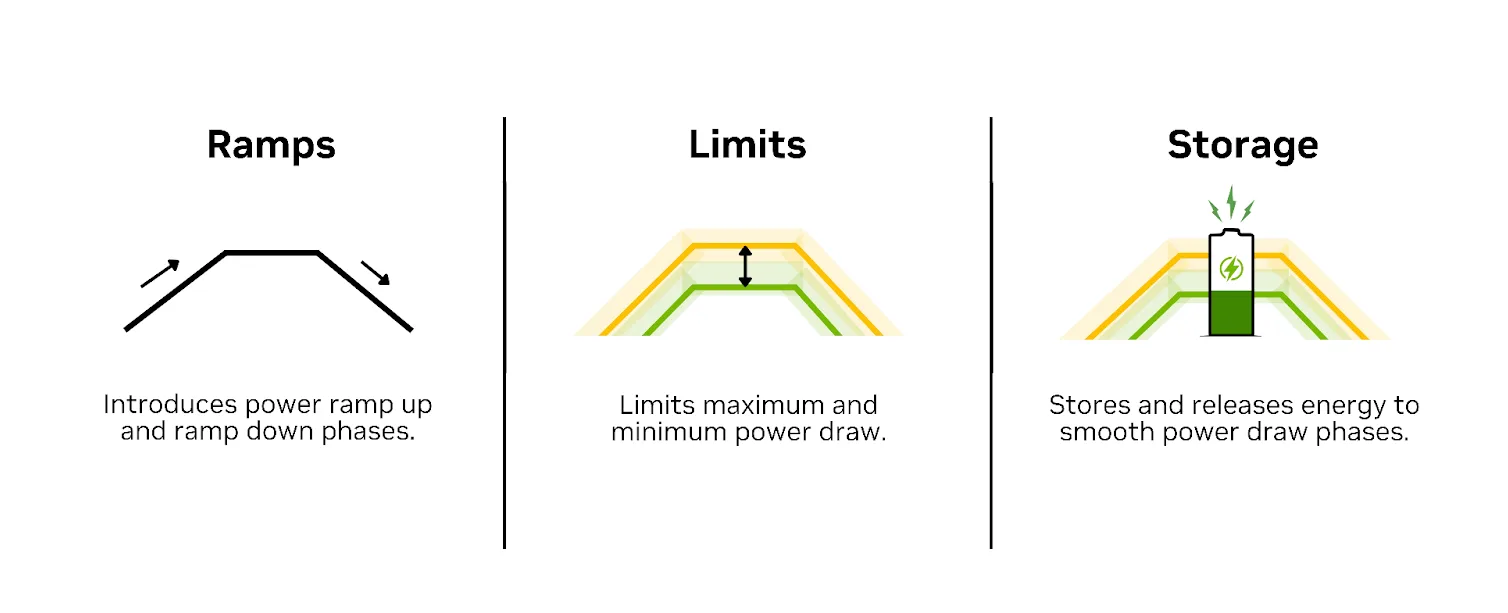
Hình 34. Các cơ chế làm mịn công suất: đường dốc, giới hạn và lưu trữ
Ở cấp độ transformer, hệ thống lưu trữ năng lượng pin (BESS) cung cấp khả năng phản ứng nhanh để xử lý các sự cố lưới điện và duy trì sự ổn định mà không làm gián đoạn khối lượng công việc.
Quản lý năng lượng cơ sở hạ tầng AI hoạt động bằng cách sử dụng Dịch vụ Năng lượng Miền NVIDIA (DPS) để cung cấp các điều khiển cấp miền năng lượng và cho phép Giải pháp Hồ sơ Năng lượng Khối lượng Công việc NVIDIA (WPPS) cho mỗi tác vụ nhằm tối ưu hóa hiệu suất trên mỗi watt cho các bộ lập lịch như SLURM và NVIDIA Mission Control. Mission Control cung cấp dữ liệu đo từ xa trên toàn cụm, các chính sách tiết kiệm năng lượng được phối hợp và tích hợp với các cơ sở (bao gồm hồ sơ năng lượng được tối ưu hóa và giao diện hệ thống quản lý tòa nhà) để vận hành quy mô lớn hiệu quả. Dữ liệu đo từ xa GPU cấp thấp, giới hạn công suất và kiểm soát tình trạng được xử lý thông qua Giao diện Quản lý Hệ thống NVIDIA (SMI) và API Quản lý GPU Trung tâm Dữ liệu NVIDIA (DCGM) .
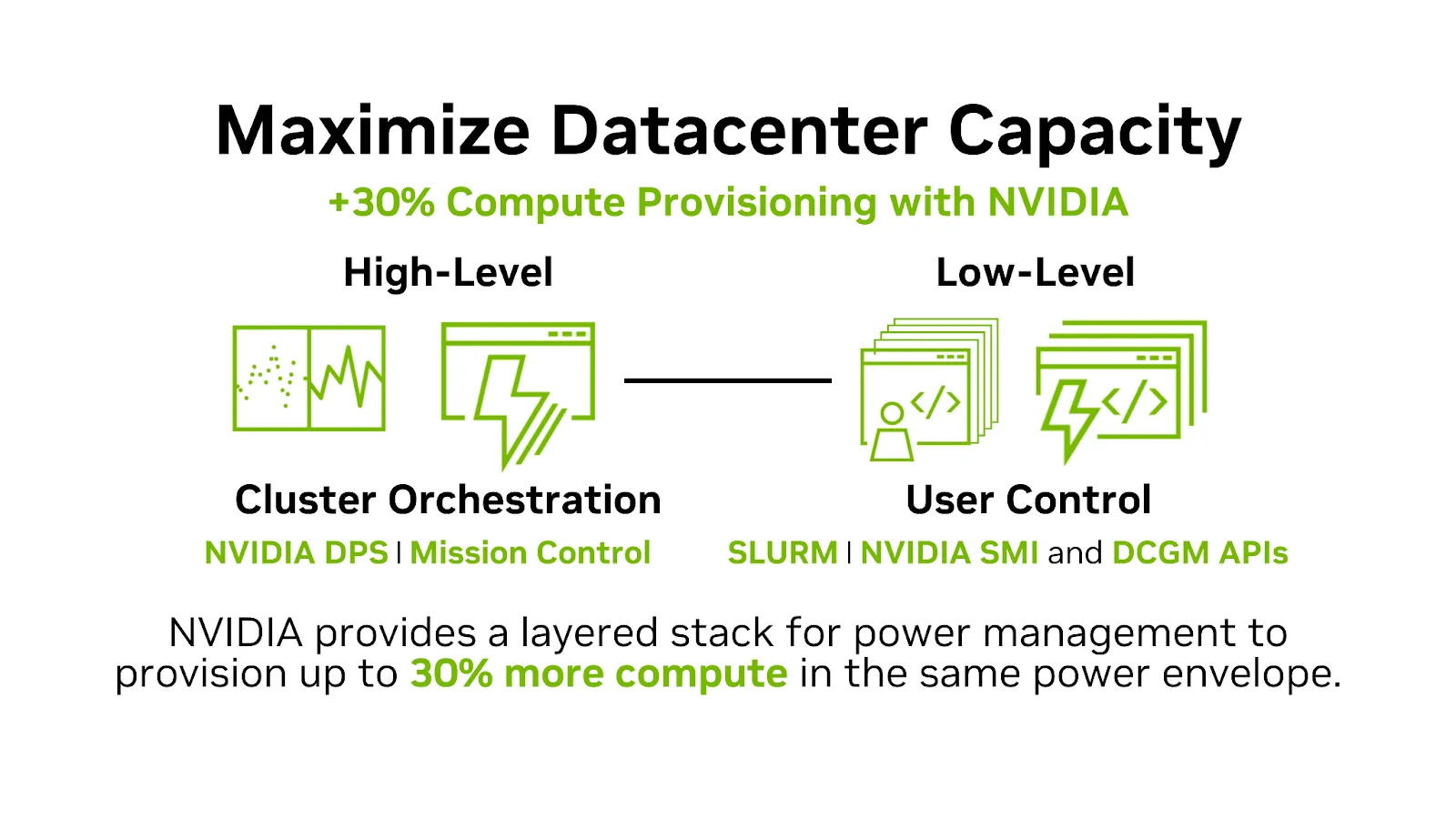
Bằng cách giảm tỷ lệ công suất đỉnh so với công suất trung bình, Vera Rubin NVL72 cho phép các nhà điều hành cung cấp nhiều GPU hơn trên mỗi megawatt công suất lưới điện khả dụng và lập kế hoạch dựa trên công suất ổn định thay vì các đỉnh công suất xấu nhất. Điều này cải thiện khả năng sử dụng, giảm chi phí cơ sở hạ tầng và trực tiếp tăng số lượng token được tạo ra trên mỗi đơn vị năng lượng.
Tối ưu hóa năng lượng và nhận biết lưới điện để xây dựng nhà máy AI quy mô lớn bền vững.
Các nhà máy AI không hoạt động độc lập. Chúng được kết nối chặt chẽ với lưới điện, điều này đặt ra các giới hạn về tốc độ tăng giảm công suất, nhu cầu cao điểm và sự ổn định hoạt động. Việc quản lý các ràng buộc này một cách thủ công là không khả thi ở quy mô lớn và có thể dẫn đến việc phải giảm công suất hoặc ngừng hoạt động đột ngột. NVIDIA đang xây dựng một trung tâm nghiên cứu nhà máy AI Vera Rubin NVL72 tại Manassas, Virginia , để tối ưu hóa và xác thực thiết kế tham chiếu cho các nhà máy AI có công suất từ 100 MW đến gigawatt. Thiết kế tham chiếu tích hợp các thiết kế giá đỡ Vera Rubin NVL72 ở quy mô lớn với cơ sở hạ tầng điện và làm mát, đồng thời triển khai các API để kết nối hệ thống điều khiển điện lưới với hệ thống đo từ xa và điều khiển của nhà máy AI.
Các nhà máy Vera Rubin NVL72 AI tích hợp thiết kế tham chiếu NVIDIA Omniverse DSX để điều khiển nguồn điện bằng phần mềm. DSX Flex chuyển đổi tín hiệu điện lưới thành các sự kiện nguồn điện cấp cụm có thể thực hiện được. DSX Boost đảm bảo tuân thủ tốc độ tăng giảm công suất và điều phối động ngân sách năng lượng cho khối lượng công việc trên toàn nhà máy.
Nhờ sự kết hợp các khả năng này, các nhà máy AI có thể tuân thủ các yêu cầu của lưới điện trong khi vẫn duy trì hoạt động ở mức sử dụng cao. Bằng cách điều phối hành vi điện năng trên các giá đỡ, các nút và các tác vụ, DSX cho phép các nhà máy AI Vera Rubin NVL72 cung cấp thêm tới 30% dung lượng GPU trong cùng mức tiêu thụ điện năng, trực tiếp làm tăng sản lượng token và tiềm năng doanh thu.
Một quá trình chuyển đổi liền mạch được thực hiện nhờ hệ sinh thái hoàn thiện.

Vera Rubin NVL72 được xây dựng trên kiến trúc rack NVIDIA MGX thế hệ thứ ba, giữ nguyên kích thước rack vật lý trong khi nâng cao hiệu năng, độ tin cậy và khả năng bảo trì. Sự liên tục này là có chủ đích. Bằng cách phát triển nền tảng mà không cần thay đổi cơ sở hạ tầng gây gián đoạn, NVIDIA cho phép đạt được những bước tiến vượt bậc về khả năng AI trong khi vẫn duy trì mô hình triển khai hiệu quả và dễ dự đoán.
Với Vera Rubin NVL72 cung cấp khả năng tính toán suy luận AI lên đến 3,6 exaFLOPS mỗi rack, thách thức không còn chỉ là hiệu năng, mà là tốc độ triển khai hiệu năng đó trên quy mô lớn. Thiết kế MGX đảm bảo rằng nguồn điện, hệ thống làm mát, tích hợp cơ khí và quy trình dịch vụ đã được chứng minh, cho phép các đối tác và nhà điều hành tập trung vào việc đẩy nhanh thời gian đưa sản phẩm vào sản xuất thay vì thiết kế lại cơ sở hạ tầng.
Tính nhất quán này trực tiếp dẫn đến việc triển khai nhanh hơn. Vera Rubin được hỗ trợ bởi một hệ sinh thái vững mạnh gồm hơn 80 đối tác MGX, bao gồm các nhà sản xuất hệ thống, nhà tích hợp và nhà cung cấp giải pháp trung tâm dữ liệu, nhiều đối tác trong số đó đã và đang triển khai nền tảng này. Những đối tác này mang đến kinh nghiệm vận hành quý báu từ các thế hệ trước, giúp giảm thiểu rủi ro và đẩy nhanh quá trình triển khai toàn cầu.
Đối với các nhà điều hành trung tâm dữ liệu, điều này có nghĩa là quá trình chuyển đổi sang Vera Rubin diễn ra suôn sẻ với mức độ khó khăn tối thiểu. Các cơ sở hiện có có thể áp dụng thế hệ tiếp theo của cơ sở hạ tầng AI dựa trên tác nhân mà không cần phải thiết kế lại bố cục, đào tạo lại đội ngũ dịch vụ hoặc đánh giá lại các thiết kế giá đỡ cơ bản. Kết quả là triển khai nhanh hơn, hoạt động dễ dự đoán hơn và khả năng mở rộng nhanh chóng các nhà máy AI khi nhu cầu tăng lên.
Hệ sinh thái hoàn thiện của Vera Rubin đảm bảo rằng sự đổi mới nền tảng không làm ảnh hưởng đến tốc độ triển khai, cho phép các doanh nghiệp và nhà cung cấp dịch vụ đám mây chuyển từ giai đoạn đổi mới sang sản xuất với tốc độ chưa từng có.
Nơi vận hành gặp gỡ hiệu suất
Tóm lại, những khả năng này định nghĩa ý nghĩa của việc vận hành ở quy mô nhà máy AI. Vera Rubin NVL72 kết hợp độ tin cậy không gián đoạn, bảo mật toàn diện, thiết kế hệ thống tiết kiệm năng lượng và hệ sinh thái giá đỡ hoàn thiện để đảm bảo rằng những cải tiến về hiệu suất được chuyển hóa thành sản lượng thực sự, bền vững trong môi trường sản xuất. Bằng cách loại bỏ các nút thắt về vận hành, điện năng và triển khai, nền tảng này cho phép các nhà máy AI tập trung vào những gì quan trọng nhất: cung cấp nhiều trí thông minh hơn trên mỗi watt, mỗi giá đỡ và mỗi trung tâm dữ liệu. Với nền tảng này, phần tiếp theo sẽ xem xét cách Vera Rubin chuyển đổi những lợi thế ở cấp độ hệ thống này thành những cải tiến hiệu suất có thể đo lường được ở quy mô lớn.
7. Hiệu suất và hiệu quả ở quy mô lớn
Một cách hữu ích để hiểu tác động hiệu năng của Vera Rubin NVL72 là thông qua lăng kính tiến hóa mô hình. Ngành công nghiệp đang đồng thời hướng tới việc huấn luyện quy mô cực lớn, điển hình là các mô hình hỗn hợp chuyên gia (MoE) với 10 nghìn tỷ tham số, và hướng tới suy luận độ trễ thấp cần thiết cho các tác nhân lý luận và quy trình làm việc phức tạp. Ở quy mô này, thách thức không còn là thông lượng tối đa riêng lẻ, mà là làm thế nào toàn bộ nền tảng chuyển đổi cơ sở hạ tầng thành sự tiến bộ bền vững của mô hình một cách hiệu quả.
Khi ngành công nghiệp tiến bộ từ Hopper đến Blackwell và giờ là Rubin, hiệu suất được cải thiện ngày càng nhiều đến từ hiệu quả kiến trúc hơn là từ việc mở rộng quy mô bằng sức mạnh thô bạo. Vera Rubin NVL72 đã phá vỡ ranh giới hiệu suất ở cả hai khía cạnh, cung cấp mật độ kiến trúc cần thiết để huấn luyện các mô hình MoE khổng lồ mà không gây ra sự phân tán cụm máy tính khó quản lý, đồng thời cho phép duy trì hiệu quả thực thi cần thiết cho suy luận thời gian thực, khả năng suy luận cao.
Mở khóa kỷ nguyên 10T MoE thông qua thiết kế đồng bộ tối ưu
Việc đào tạo thế hệ mô hình tiên tiến tiếp theo đòi hỏi sự đồng thiết kế cực kỳ chặt chẽ. Khi số lượng tham số tiếp tục tăng lên, ngành công nghiệp đang nhanh chóng tiến đến điểm mà kiến trúc 10T MoE trở nên khả thi về mặt vận hành. Những mô hình này cung cấp dung lượng khổng lồ và khả năng suy luận hiệu quả hơn, nhưng chúng lại tạo ra gánh nặng giao tiếp đáng kể trong quá trình đào tạo do định tuyến chuyên gia động và trao đổi thông tin thường xuyên giữa tất cả các bên.
Nền tảng Vera Rubin được thiết kế để hấp thụ chi phí phát sinh này thông qua thiết kế đồng bộ chặt chẽ giữa điện toán, bộ nhớ và mạng. Mật độ điện toán cao hơn trên mỗi rack và các kết nối hiệu quả hơn giúp giảm chi phí đồng bộ hóa và giao tiếp giữa các chuyên gia, cho phép hiệu quả đào tạo tăng lên thay vì giảm xuống khi kích thước cụm tăng lên.
Hình dưới đây minh họa tác động của thiết kế đồng bộ này bằng cách sử dụng mục tiêu huấn luyện cố định. Để huấn luyện mô hình 10T MoE trên 100 nghìn tỷ token trong vòng một tháng, Vera Rubin NVL72 đạt được mục tiêu bằng cách sử dụng khoảng một phần tư số GPU cần thiết so với Grace Blackwell NVL72. Thay vì mở rộng quy mô lên các cụm máy tính ngày càng lớn để đáp ứng thời hạn gấp rút, Vera Rubin tập trung năng lực huấn luyện hiệu quả vào ít GPU hơn.
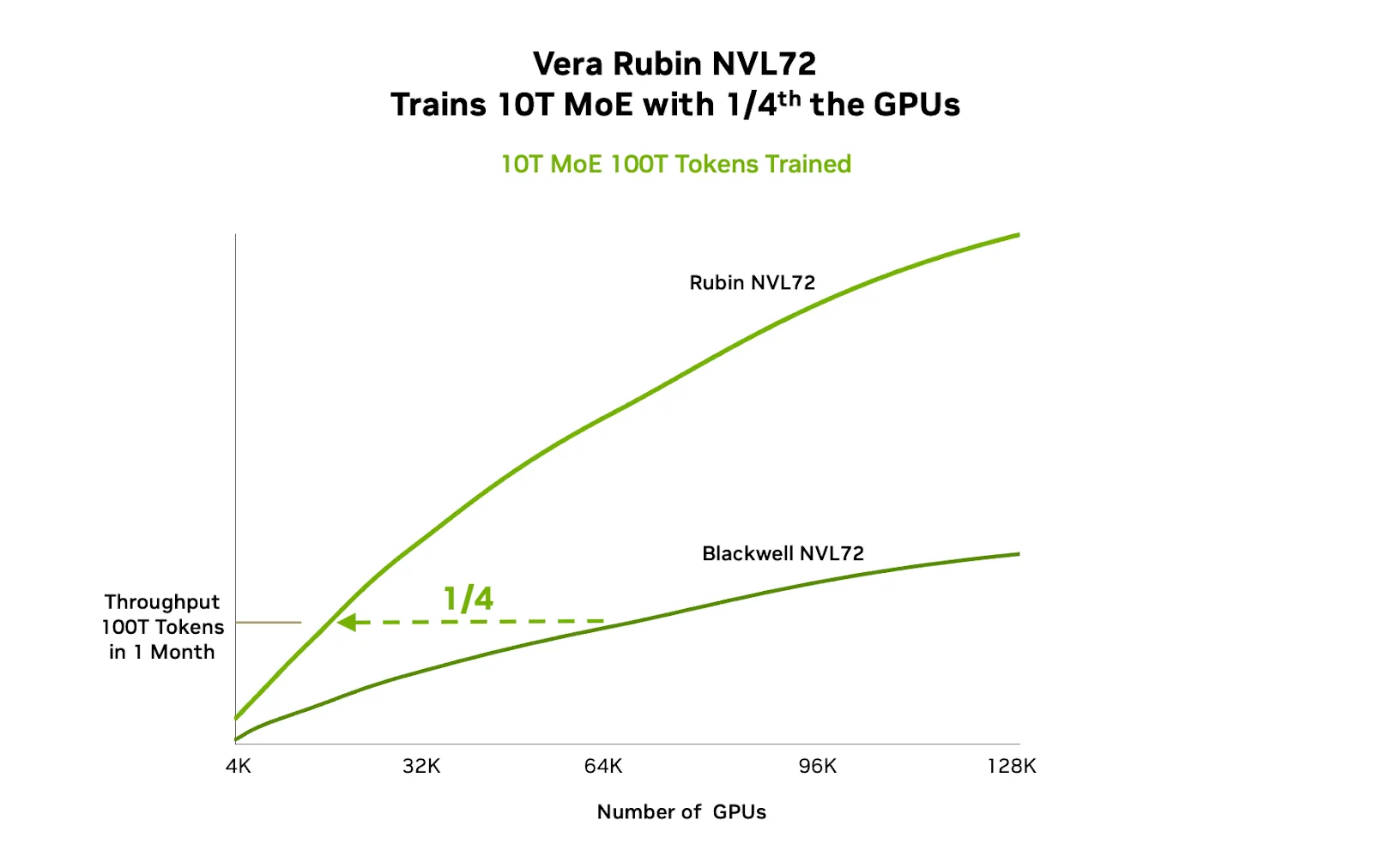
Việc giảm số lượng GPU cần thiết này thể hiện một sự thay đổi cấu trúc trong huấn luyện quy mô lớn. Bằng cách giảm thiểu sự phân tán cụm máy tính và chi phí truyền thông, Vera Rubin NVL72 loại bỏ phần lớn sự phức tạp vốn đã hạn chế khả năng mở rộng của MoE trong quá khứ. Hiệu quả kiến trúc, chứ không phải số lượng GPU thô, trở thành yếu tố chủ đạo giúp các mô hình lớp 10T trở nên khả thi ở quy mô lớn.
Suy luận thời gian thực trên quy mô lớn
Sự chuyển dịch sang các hệ thống AI đa tác nhân về cơ bản làm thay đổi hành vi suy luận. Thay vì các yêu cầu ngắn, không trạng thái, các tác nhân giờ đây hoạt động với ngữ cảnh liên tục, liên tục trao đổi trạng thái giữa các lượt và giữa các tác nhân. Mỗi yêu cầu có thể mang theo hàng chục nghìn token, bao gồm lịch sử hội thoại, định nghĩa công cụ, lược đồ API có cấu trúc, ngữ cảnh RAG được truy xuất và các đầu ra trung gian từ các tác nhân khác trong quy trình làm việc. Duy trì khả năng phản hồi dưới tải ngữ cảnh liên tục này đòi hỏi nhiều hơn là chỉ sức mạnh tính toán tối đa, nó đòi hỏi thông lượng cao liên tục trên cả khả năng tính toán, bộ nhớ và truyền thông.
Đồng thời, các mô hình “tư duy” hiện đại, chẳng hạn như Kimi-K2-Thinking của Moonshot AI, giới thiệu thêm một giai đoạn thực thi. Trước khi đưa ra phản hồi cuối cùng, các mô hình này tạo ra các chuỗi suy luận nội bộ dài, làm tăng đáng kể số lượng token đầu ra. Đối với các khối lượng công việc yêu cầu khoảng 8.000 token đầu ra, tốc độ suy luận thông thường của người dùng, khoảng 50 token mỗi giây mỗi người dùng, sẽ dẫn đến thời gian phản hồi kéo dài nhiều phút. Ở quy mô lớn, độ trễ này sẽ tích lũy trên nhiều người dùng đồng thời, làm giảm cả trải nghiệm người dùng và hiệu quả hệ thống.
Vera Rubin NVL72 được thiết kế để loại bỏ nút thắt cổ chai này. Bằng cách duy trì thông lượng cao ở mức độ tương tác cao, nền tảng này cho phép suy luận nặng về lý thuyết mà không làm giảm khả năng phản hồi. Hình dưới đây minh họa sự thay đổi thế hệ này. Trên khối lượng công việc Kimi-K2-Thinking, Vera Rubin NVL72 cung cấp thông lượng nhà máy token trên mỗi megawatt cao hơn tới 10 lần so với hệ thống NVIDIA Blackwell GB200 NVL72 ở mức độ tương tác người dùng tương đương. Trong khi các kiến trúc trước đây gặp phải sự sụt giảm thông lượng mạnh khi TPS trên mỗi người dùng tăng lên, Vera Rubin NVL72 duy trì hiệu quả trên toàn bộ phạm vi hoạt động cần thiết cho lý luận tương tác mượt mà. Điều này cho phép các mô hình MoE lớn với 1 nghìn tỷ tham số phục vụ khối lượng công việc tác nhân thời gian thực mà không bị ảnh hưởng bởi “thời gian chờ đợi suy nghĩ”.
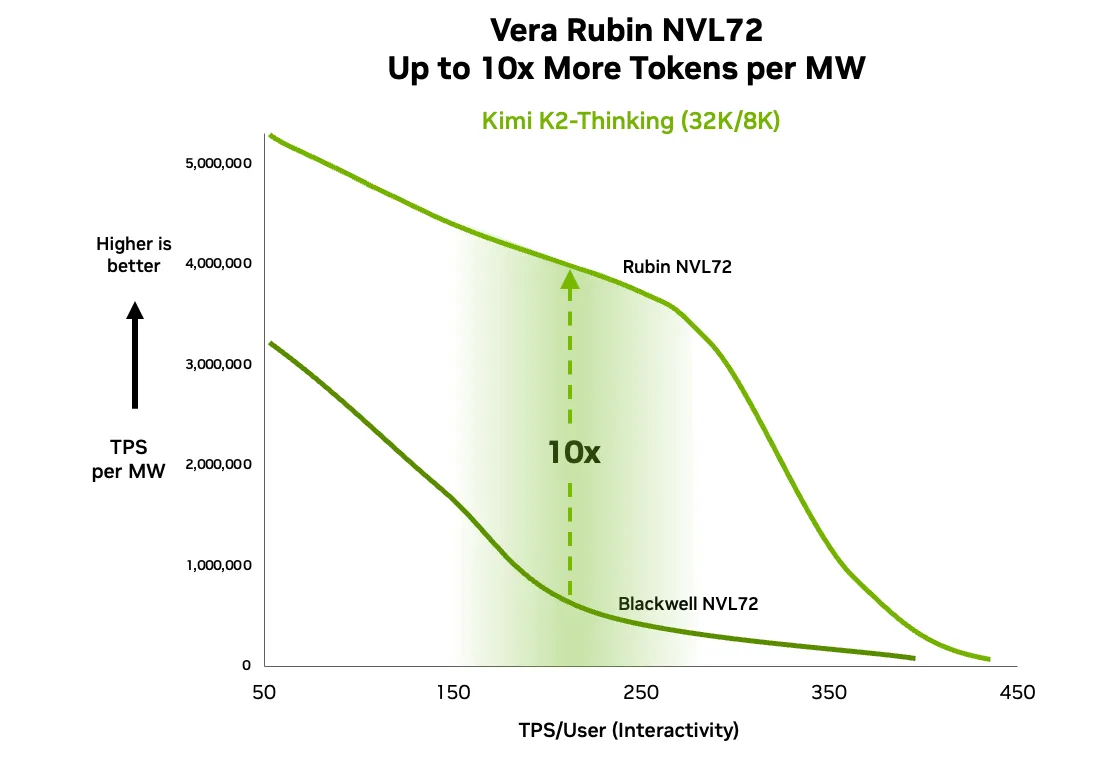
Ngoài thông lượng, Vera Rubin NVL72 còn thay đổi căn bản hiệu quả kinh tế của suy luận logic. Hình dưới đây cho thấy chi phí trên mỗi triệu token phụ thuộc vào độ trễ đầu ra cho cùng một khối lượng công việc. Đối với suy luận logic trong ngữ cảnh dài, Vera Rubin NVL72 mang lại chi phí trên mỗi triệu token thấp hơn tới 10 lần so với Blackwell NVL72.
Ưu điểm này thể hiện rõ nhất ở các cấp độ dịch vụ cần thiết cho các tác nhân tương tác, nơi các nền tảng trước đây có thể gặp phải rào cản về hiệu quả khi chi phí tăng cao để cải thiện khả năng phản hồi từng bước. Vera Rubin vẫn duy trì hiệu quả chi phí trong lĩnh vực này, chuyển đổi khả năng suy luận chuỗi dài từ một tính năng cao cấp thành một dịch vụ có thể mở rộng và sẵn sàng cho sản xuất.
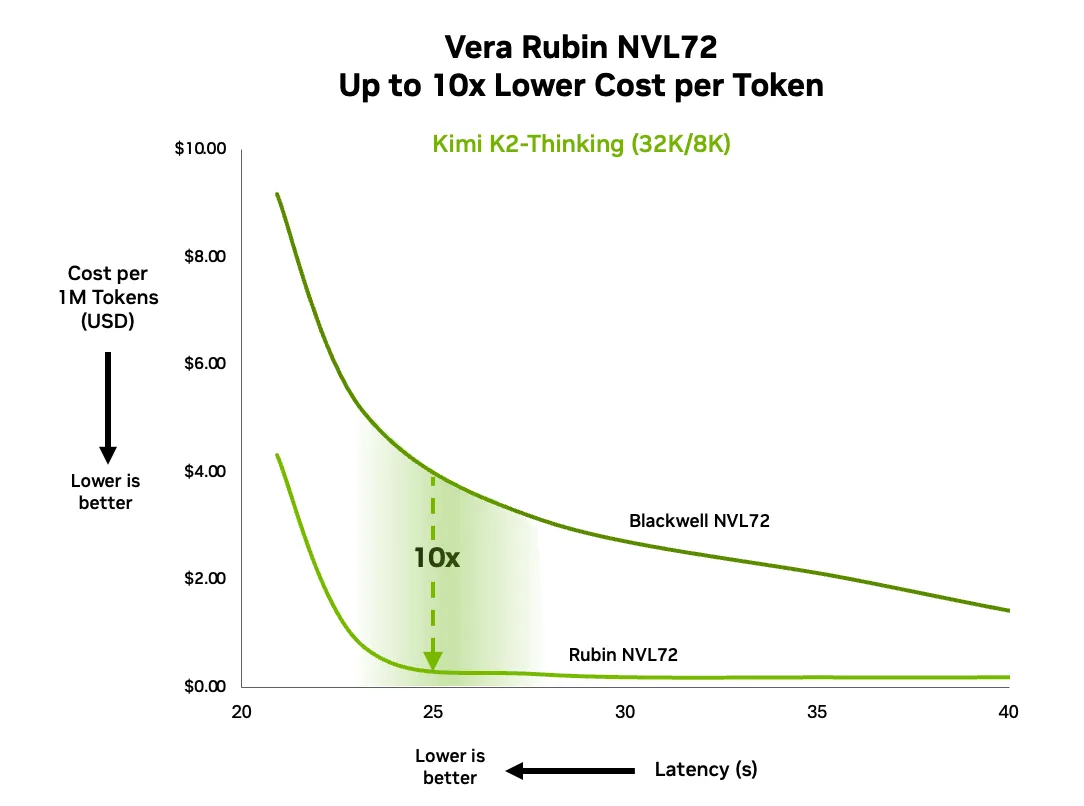
Định nghĩa lại đường biên Pareto
Nhìn chung, những kết quả này định nghĩa lại sự đánh đổi truyền thống giữa khả năng phản hồi và hiệu quả trong suy luận AI. Trong khi các nền tảng trước đây buộc người vận hành phải lựa chọn giữa độ trễ thấp và chi phí hợp lý, Vera Rubin NVL72 duy trì cả hai cùng lúc. Điều này cho phép các mô hình xử lý ngữ cảnh lớn, đòi hỏi nhiều suy luận hoạt động tương tác ở quy mô lớn, biến suy luận thông minh cao cấp từ một khả năng cao cấp thành một dịch vụ tiêu chuẩn trong sản xuất.
8. Vì sao Vera Rubin là nền tảng nhà máy AI
Cơ sở hạ tầng AI đã đạt đến một bước ngoặt. Khi các mô hình phát triển theo hướng suy luận ngữ cảnh dài hạn, thực thi độc lập và huấn luyện liên tục sau đào tạo, hiệu năng không còn được quyết định bởi bất kỳ thành phần đơn lẻ nào. Nó được quyết định bởi mức độ hiệu quả của toàn bộ hệ thống trong việc chuyển đổi năng lượng, phần cứng và luồng dữ liệu thành trí tuệ hữu ích trên quy mô lớn.
Vera Rubin được xây dựng dành riêng cho thực tế này.
Thay vì tối ưu hóa các chip riêng lẻ, nền tảng Vera Rubin coi trung tâm dữ liệu như một đơn vị tính toán duy nhất. Thông qua thiết kế đồng bộ tối ưu giữa GPU, CPU, mạng mở rộng quy mô, giảm tải cơ sở hạ tầng, cung cấp điện, làm mát, bảo mật và phần mềm hệ thống, Vera Rubin cho phép các nhà máy AI hoạt động như những hệ thống tích hợp chặt chẽ, có thể dự đoán được và luôn sẵn sàng hoạt động.
Ở lớp thực thi, GPU Rubin cung cấp thông lượng ổn định cho các khối lượng công việc chủ yếu liên quan đến tính toán, bộ nhớ và truyền thông. CPU Vera hoạt động như các công cụ dữ liệu băng thông cao, truyền dữ liệu hiệu quả đến GPU và tăng tốc điều phối cấp hệ thống mà không trở thành nút thắt cổ chai. NVLink 6 hợp nhất giá đỡ thành một miền NVLink duy nhất, cho phép hiệu suất có thể dự đoán được trên tất cả các GPU. BlueField-4 hoàn thiện hệ thống bằng cách tự vận hành nhà máy AI, giảm tải các dịch vụ cơ sở hạ tầng và thực thi bảo mật, cách ly và kiểm soát ở quy mô lớn. Sau đó, Spectrum-X Ethernet và ConnectX-9 mở rộng hành vi xác định này ra ngoài giá đỡ, cho phép các nhà máy AI hiệu quả, có khả năng mở rộng trên các triển khai nhiều giá đỡ.
Quan trọng hơn hết, những khả năng này không chỉ là lý thuyết. Chúng được cung cấp dưới dạng một nền tảng đã được kiểm chứng và sẵn sàng sản xuất thông qua DGX SuperPOD, được hỗ trợ bởi NVIDIA Mission Control, phần mềm doanh nghiệp và hệ sinh thái MGX hoàn thiện. Thiết kế này cho phép các tổ chức triển khai các nhà máy AI an toàn nhanh hơn, vận hành chúng đáng tin cậy hơn và mở rộng quy mô hiệu quả hơn khi nhu cầu tăng lên.
Kết quả là một sự thay đổi cơ bản trong kinh tế AI. Bằng cách tối đa hóa việc sử dụng, giảm ma sát vận hành và giảm thiểu lãng phí năng lượng, nền tảng Vera Rubin làm giảm chi phí trên mỗi token đồng thời tăng số token trên mỗi watt và số token trên mỗi rack. Những gì trước đây đòi hỏi các cụm máy chủ cồng kềnh, dễ hỏng giờ đây có thể được cung cấp với mật độ cao hơn, độ tin cậy cao hơn và hiệu suất có thể dự đoán được.
Nền tảng Vera Rubin không chỉ là thế hệ tiếp theo của điện toán tăng tốc. Đó là nền tảng cho phép các nhà máy AI chuyển từ giai đoạn thử nghiệm sang sản xuất trí tuệ nhân tạo quy mô công nghiệp.
9. Tìm hiểu thêm
Khám phá nền tảng Vera Rubin , CPU Vera, Vera Rubin NVL72 , bộ chuyển mạch NVIDIA NVLink 6 , SuperNIC NVIDIA ConnectX-9 , DPU NVIDIA BlueField-4, bộ chuyển mạch Ethernet NVIDIA Spectrum-6 , cấu hình DGX SuperPOD và các tùy chọn triển khai khác tại nvidia.com . Và đọc thông cáo báo chí CES.
Lời cảm ơn
Xin cảm ơn Alex Sandu, Amr Elmeleegy, Ashraf Eassa, Brian Sparks, Casey Dugas, Chris Hoge, Chris Porter, Dave Salvator, Eduardo Alvarez, Erik Pounds, Farshad Ghodsian, Fred Oh, Gilad Shainer, Harry Petty, Ian Buck, Itay Ozery, Ivan Goldwasser, Jamie Li, Jesse Clayton, Joe DeLaere, Jonah Alben, Kirthi Devleker, Laura Martinez, Nate Dwarika, Praveen Menon, Rohil Bhargava, Ronil Prasad, Santosh Bhavani, Scot Schultz, Shar Narasimhan, Shruti Koparkar, Stephanie Perez, Taylor Allison và Traci Psaila—cùng với nhiều nhà lãnh đạo sản phẩm, kỹ sư, kiến trúc sư và đối tác khác của NVIDIA đã đóng góp cho bài viết này.
Xem bài gốc tại NVIDIA Developer Blog
Bài viết liên quan
- CPU NVIDIA Vera tăng cường thông lượng của AI Factory để đẩy nhanh các workload Agentic AI
- Xây dựng chatbot AI nội bộ cho doanh nghiệp: Nhanh hơn, đúng ngữ cảnh hơn, kiểm soát tốt hơn
- Kỷ nguyên của Agentic AI: Hạ tầng Blackwell thiết lập tiêu chuẩn hiệu năng mới với Benchmark AgentPerf
- Cách nền tảng NVIDIA Vera Rubin giải quyết bài toán mở rộng quy mô (Scale-Up) của Agentic AI
- Tái định nghĩa AI TCO: Tại sao “Chi phí trên mỗi Token” mới là thước đo chủ đạo cho Hạ tầng AI?