
Các Tác nhân AI tự động đang thúc đẩy làn sóng đổi mới AI tiếp theo. Các tác nhân này thường phải quản lý các tác vụ dài hạn sử dụng đồng thời nhiều kênh liên lạc và quy trình con nền để khám phá các tùy chọn, thử nghiệm giải pháp và tạo ra kết quả tối ưu. Điều này đặt ra yêu cầu cực độ đối với tính toán cục bộ.
NVIDIA DGX Spark cung cấp hiệu suất cần thiết cho các tác nhân tự trị để thực hiện các quy trình công việc phức tạp này một cách hiệu quả và cục bộ. Bây giờ với NVIDIA NemoClaw, một phần của Bộ công cụ tác nhân NVIDIA, nó cài đặt môi trường bảo mật NVIDIA OpenShell runtime—a để chạy các tác nhân tự trị và các mô hình nguồn mở như NVIDIA Nemotron.
Bài đăng này thảo luận về một số khía cạnh quan trọng của khả năng và hiệu suất hệ thống cần thiết để cung cấp năng lượng cho các tác nhân tự động luôn bật và giải thích lý do tại sao NVIDIA DGX Spark là nền tảng máy tính để bàn lý tưởng cho AI tự động.
Suy luận cho các tác nhân AI tự động
Các công cụ tác nhân thường cần xử lý các cửa sổ ngữ cảnh lớn. Ví dụ: OpenClaw là thời gian chạy tác nhân AI yêu cầu các cửa sổ ngữ cảnh lớn này để hiểu các yêu cầu và môi trường cũng như suy nghĩ về cách tiếp cận tốt nhất cho một vấn đề.
Thông lượng xử lý nhanh (prefill) có thể được coi là giai đoạn đọc hiểu của suy luận và có thể dễ dàng trở thành nút cổ chai với GPU chậm. Thông thường, người ta thường thấy các tác nhân tự trị dễ dàng sử dụng ngữ cảnh của mã thông báo 30K-120K (mã thông báo 100K tương đương với việc đọc Harry Potter và Hòn đá Phù thủy), với một số đại lý xử lý mã thông báo 250K cho các yêu cầu phức tạp.
Ad
Bảng 1 cho thấy cách một tác nhân tiềm năng hoặc tác nhân phụ hoạt động với một cửa sổ ngữ cảnh lớn, (128K/1K của ISL/OSL).
| Mô hình | Độ trễ từ đầu đến cuối (s) |
Độ trễ xử lý nhanh chóng (s) |
Thông lượng xử lý nhanh chóng (tok/s) |
Thông lượng tạo token (tok/s) |
| NVIDIA Nemotron 3 Super 120B NVFP4 với TensorRT LLM | 99 | 44 | 2.855 | 18 |
| Qwen3.5 35B A3B FP8 với vLLM | 73 | 41 | 3.080 | 35,75 |
| Qwen3 Coder Next 80B FP8 với vLLM | 89 | 54 | 2.390 | 28,95 |
Bảng 1. Đại diện hiệu suất của 128k tokens input prompts và phản hồi của 1K tokens, ở batch size 1
Khi chuyển từ single subagent sang multiple subagents, khối lượng công việc đồng thời phải mở rộng quy mô mà không ảnh hưởng đáng kể đến hiệu suất. NVIDIA DGX Spark xử lý hiệu quả tính đồng thời cao trong kịch bản này.
Nhờ sức mạnh của các Siêu chip NVIDIA Grace Blackwell, GPU có thể song song hóa nhiều tác nhân phụ. Hai, bốn hoặc thậm chí tám tác nhân phụ hoạt động đồng thời thông qua các yêu cầu có thể tận dụng khả năng đồng thời mạnh mẽ trong DGX Spark.
Với sự hỗ trợ từ các framework xử lý tốt concurrency (chẳng hạn như NVIDIA TensorRT LLM, vLLM và SGLang), khối lượng công việc đa tác nhân chạy trơn tru trên NVIDIA DGX Spark. Đối với các tác vụ có 32K ISL của 1K OSL, việc hoàn thành số lượng tác vụ gấp bốn lần chỉ cần thêm 2,6 lần thời gian, trong khi thông lượng xử lý nhanh chóng tăng khoảng 3 lần (Bảng 2).
NVIDIA DGX Spark là một nền tảng lý tưởng để phát triển OpenClaw. Với NVIDIA OpenShell, bạn có thể chạy các tác nhân tự động, tự phát triển một cách an toàn hơn. Bắt đầu chạy OpenClaw cục bộ trên NVIDIA DGX Spark.
| Đồng thời (# của các tác vụ đồng thời) |
Độ trễ từ đầu đến cuối (s) |
TTFT trung bình (s) |
Thông lượng xử lý nhanh chóng (tok/s) |
Thông lượng tạo token (tok/s) |
| Thấp hơn là tốt hơn | Cao hơn là tốt hơn | |||
| 1 | 35 | 9 | 3.261 | 38 |
| 2 | 54 | 12 | 5.363 | 47 |
| 4 | 91 | 15 | 9.616 | 53 |
Bảng 2. Đại diện hiệu suất của Qwen3 Coder Next trong FP8 trong vLLM cho 32K tokens input prompts và phản hồi của 1k tokens ở các mức đồng thời khác nhau
Suy luận tỷ lệ và tinh chỉnh trên tối đa bốn nút NVIDIA DGX Spark
Các mô hình lớn hơn và nhiều tác nhân con yêu cầu nhiều bộ nhớ hơn để tải và thực thi. Cho đến nay, NVIDIA DGX Spark đã hỗ trợ mở rộng quy mô lên tới hai node, tăng bộ nhớ khả dụng từ 128 GB trên một nút lên 256 GB trên hai nút. Khả năng này hiện đã được tăng lên tới bốn nút DGX Spark.
DGX Spark hiện cũng hỗ trợ một số cấu trúc liên kết thực thi, mỗi cấu trúc liên kết được điều chỉnh cho các mục tiêu khác nhau thông qua độ trễ thấp của giao tiếp RoCE được kích hoạt bởi NIC ConnectX-7.
- Một nút DGX Spark: Lý tưởng cho độ trễ thấp, suy luận kích thước ngữ cảnh lớn, tinh chỉnh các tham số lên tới 120B và khối lượng công việc tác nhân cục bộ
- Hai nút DGX Spark: Cân bằng tỷ lệ cho tinh chỉnh nhanh hơn và các mô hình lớn hơn, cũng như hỗ trợ cho lên đến 400B-tham số
- Ba nút DGX Spark trong một vòng: Lý tưởng để tinh chỉnh các mô hình lớn hơn hoặc các công việc đào tạo nhanh
- Bốn nút DGX Spark có switch RoCE 200 GbE: Máy chủ suy luận cục bộ lý tưởng cho các mô hình hiện đại lên đến 700B tham số, khối lượng công việc chuyên sâu về truyền thông và hoạt động của nhà máy AI cục bộ.
Suy luận có thể mở rộng quy mô tuyến tính trên DGX Spark khi giao tiếp giữa các nút ở mức tối thiểu. Khi công việc phần lớn độc lập trên mỗi GPU, kết quả sẽ được tổng hợp một lần vào cuối thay vì liên tục. Trong trường hợp này, các nút DGX Spark có thể chạy song song với chi phí đồng bộ hóa thấp.
Ví dụ: khối lượng công việc học tăng cường (RL) trong Phòng thí nghiệm NVIDIA Isaac có thể chạy nhiều mô phỏng độc lập trên mỗi node. Kết quả được thu thập trong một bước duy nhất, mang lại tỷ lệ gần như tuyến tính trên nhiều nút DGX Spark.
Tỷ lệ suy luận nhỏ hơn tuyến tính khi khối lượng công việc yêu cầu giao tiếp thường xuyên, chi tiết giữa các nút. Trong quá trình suy luận LLM, việc thực thi mô hình xảy ra theo từng lớp, với yêu cầu đồng bộ hóa liên tục trên các nút. Một phần kết quả từ các nút DGX Spark khác nhau phải được trao đổi và hợp nhất nhiều lần, điều này gây ra chi phí liên lạc đáng kể. Khi các nút bổ sung được thêm vào, chi phí này ngày càng chiếm ưu thế, hạn chế hiệu quả mở rộng quy mô.
Tính song song cho các tác nhân AI: Suy luận ở quy mô lớn
Tính song song của tensor cho phép chia sẻ suy luận hiệu quả trên nhiều nút để phù hợp với mô hình đồng thời giảm thiểu chi phí liên lạc. Mở rộng từ hai đến bốn nút DGX Spark cung cấp khả năng song song tuyệt vời. Điều này là nhờ các NIC ConnectX-7 có độ trễ thấp, mở rộng quy mô thời gian cho mỗi mã thông báo đầu ra (TPOT) gần như tuyến tính với ~ 2x với TP2 (hai nút) và ~ 4x với TP4 (4 nút) trong các trường hợp sử dụng suy luận.
Bảng 3 cho thấy cách một tác nhân thực hiện công việc suy luận được chia sẻ trên nhiều nút.
| 1 nút Spark DGX TP1 (ms) |
2 nút Spark DGX TP2 (ms) |
4 nút Spark DGX TP4 (ms) |
|
| TTFT (thấp hơn là tốt hơn) | 33.415 | 21.384 | 15.552 |
| TPOT (thấp hơn là tốt hơn) | 269 | 133 | 72 |
Bảng 3. Chia tỷ lệ Llama 3.3 70B Hướng dẫn NVFP4 trên TensorRT LLM với một, hai và bốn nút DGX Spark (đầu vào 32K, đầu ra 1K, kích thước lô 1)
Một số mô hình phổ biến trong bối cảnh OpenClaw—bao gồm Qwen3.5 397B, GLM 5 và MiniMax M2.5 230B—có thể hưởng lợi từ việc xếp chồng nhiều đơn vị DGX Spark, tăng bộ nhớ khả dụng.
Tinh chỉnh gần tuyến tính
Việc tinh chỉnh và khối lượng công việc tương tự có thể được song song đáng kể với việc mở rộng hiệu suất gần tuyến tính khi phiên bản mô hình có thể vừa với một GPU. Điều này làm giảm chi phí liên lạc xuống chỉ còn đồng bộ hóa độ dốc ở cuối mỗi bước.
Khối lượng công việc RL trong NVIDIA Isaac Lab hoặc Nanochat có thể được hưởng lợi từ việc mở rộng hiệu suất này. Isaac Lab có thể chứa một số bản sao của mỗi môi trường trên mỗi DGX Spark. Đối với mỗi bước, Isaac Lab giao tiếp với các nút khác để đồng bộ hóa quá trình đào tạo, đạt được tốc độ tuyến tính thông qua phân cụm.
| 1 nút Spark DGX TP1 |
2 nút Spark DGX TP2 |
4 nút Spark DGX TP4 |
|
| Thời gian thu thập | 12.1 s | 11,4 s | 10,4 s |
| Thời gian học | 40,9 s | 41,4 s | 42,3 s |
| # môi trường | 1.024 | 1.024 | 1.024 |
| FPS | 630 | 1241 | 2.520 |
Bảng 4. Mở rộng hiệu suất học tăng cường của Isaac Lab trên một, hai và bốn nút DGX Spark
| Cấu hình HW | Tổng thông lượng token (tok/s) |
Tăng tốc so với 1 nút DGX Spark |
| 1 nút Spark DGX | ~18.400 | 1 |
| 2 nút Spark DGX | ~35.900 | 2 |
| 4 nút Spark DGX | ~74.600 | 4 |
Bảng 5. Mở rộng hiệu suất tinh chỉnh Nanochat từ một lên bốn nút DGX Spark (độ sâu mô hình 20 lớp, kích thước lô 32 mỗi nút, chú ý toàn bộ ngữ cảnh)
Khi sử dụng song song dữ liệu phân tán (DDP), việc tinh chỉnh cũng có thể được hưởng lợi tương tự từ chi phí liên lạc thấp. Trong trường hợp này, mỗi nút có thể lưu trữ đầy đủ một bản sao của mô hình và giao tiếp với các nút khác một lần trong mỗi bước.
| Các nút | Mẫu/bước | Kích thước hàng loạt | Mẫu/s | Tăng tốc |
| 1 nút Spark DGX | 15,73 | 32 | 2.03 | – |
| 3 nút Spark DGX | 15,69 | 96 | 6.12 | 3x |
Bảng 6. Chia tỷ lệ một DGX Spark thành ba nút DGX Spark, mỗi nút có mô hình đầy đủ của Qwen3 4B (kích thước lô của bốn mẫu cho mỗi thiết bị, lượng tử hóa BF16)
Phát triển trên DGX Spark, triển khai lên đám mây: Quy trình làm việc đa kiến trúc
Các giải pháp đám mây được yêu cầu khi chuyển từ tạo mẫu sang triển khai sản xuất quy mô lớn. Phần này giải thích cách khối lượng công việc được phát triển trên DGX Spark có thể được triển khai trên đám mây.
Ngói IR và cuTile Python cho phép di chuyển hạt nhân liền mạch từ môi trường phát triển DGX Spark đến triển khai đám mây trên NVIDIA Blackwell GPU trung tâm dữ liệu, với thay đổi mã tối thiểu. Sử dụng TileGym, nhà phát triển có thể:
- Viết kernel một lần bằng cuTile Python DSL
- Kiểm tra và xác nhận trên DGX Spark
- Triển khai tới NVIDIA Blackwell B300/B200, NVIDIA Hopper hoặc NVIDIA Ampere với những thay đổi mã tối thiểu
- Tận dụng hạt nhân máy biến áp được tối ưu hóa trước TileGym để thay thế thả vào
Hiệu suất suy luận đầu cuối
Ngoài phân tích cấp độ hạt nhân, chúng tôi đã so sánh suy luận Qwen2 7B hoàn chỉnh bằng cách sử dụng hạt nhân cuTile trên cả hai nền tảng để chứng minh tính di động hiệu suất kiến trúc chéo. Bảng 7 hiển thị cấu hình; Bảng 8 hiển thị thông số kỹ thuật của nền tảng.
| Tham số | Giá trị |
| Mô hình | Qwen2 7B |
| Chiều dài đầu vào | 2.189 mã thông báo |
| Chiều dài đầu ra | 128 token |
| Kích thước hàng loạt | 1,2,4,8,16,32,64,128 |
Bảng 7. Thông số kỹ thuật mô hình và tham số hiển thị mức sử dụng Tile IR
| Đặc điểm kỹ thuật | NVIDIA DGX Spark (Dev) | NVIDIA Blackwell B200 (Đám mây) |
| Khả năng tính toán | SM 12.1 | SM 10,0 |
| Số SM | 48 | 148 |
| Tần số SM | 2,14 GHz | ~1,0 GHz |
| Loại bộ nh | LPDDR5X (Hợp nhất) | HBM3e |
| Băng thông bộ nhớ | 273 GB/giây | ~8 TB/s |
Bảng 8. Thông số kỹ thuật nền tảng của NVIDIA DGX Spark và NVIDIA B200 làm ví dụ cục bộ và đám mây
Cấu hình dành riêng cho nền tảng
Mặc dù mã nguồn kernel vẫn giống hệt nhau trên các nền tảng, nhưng hiệu suất tối ưu đạt được thông qua các cấu hình dành riêng cho nền tảng (Tile và Occupancy). Đối với ví dụ hạt nhân FMHA, Bảng 9 cho thấy các cấu hình này thích ứng như thế nào với các đặc tính phần cứng khác nhau. Tile IR biên dịch sang PTX/SASS dành riêng cho kiến trúc tại JIT, tự động tận dụng các tính năng dành riêng cho nền tảng như Bộ tăng tốc bộ nhớ Tensor (TMA) bằng cách sử dụng cấu hình thích hợp.
| Nền tảng | TILE_M | TILE_N | Chiếm | Cơ sở lý luận |
| NVIDIA DGX Spark (SM 12.1) | 64 | 64 | 2 | Tiles nhỏ hơn 48 SM, bộ nhớ hợp nhất |
| NVIDIA B200 (SM 10.0) | 256 | 128 | 1 | Tiles lớn tối đa hóa thông lượng HBM3e |
| NVIDIA B200 (alt) | 128 | 128 | 2 | Công suất sử dụng cao hơn, tính song song cân bằng |
Bảng 9. Cấu hình cuTile dành riêng cho nền tảng trên NVIDIA DGX Spark và NVIDIA B200
Phân tích đường mái và so sánh hiệu suất hạt nhân Tile IR
Phân tích đường mái trong Điện toán NVIDIA Nsight là một khung hiệu suất trực quan mạnh mẽ được sử dụng để xác định mức độ ứng dụng đang sử dụng các khả năng phần cứng. Với tư cách là nhà phát triển, phân tích đường mái giúp bạn tìm hiểu xem mã của bạn có phải là “slow” hay không và cho biết lý do tại sao mã đó có thể đạt đến mức trần hiệu suất.
Phân tích mô hình đường mái cho thấy rằng hạt nhân có quy mô hiệu quả so với đường mái tương ứng, chứng tỏ rằng Tile IR là một lựa chọn khả thi để mở rộng khối lượng công việc. Hạt nhân được xem xét là hạt nhân giải mã sự chú ý và hạt nhân được tối ưu hóa bằng Tile IR.
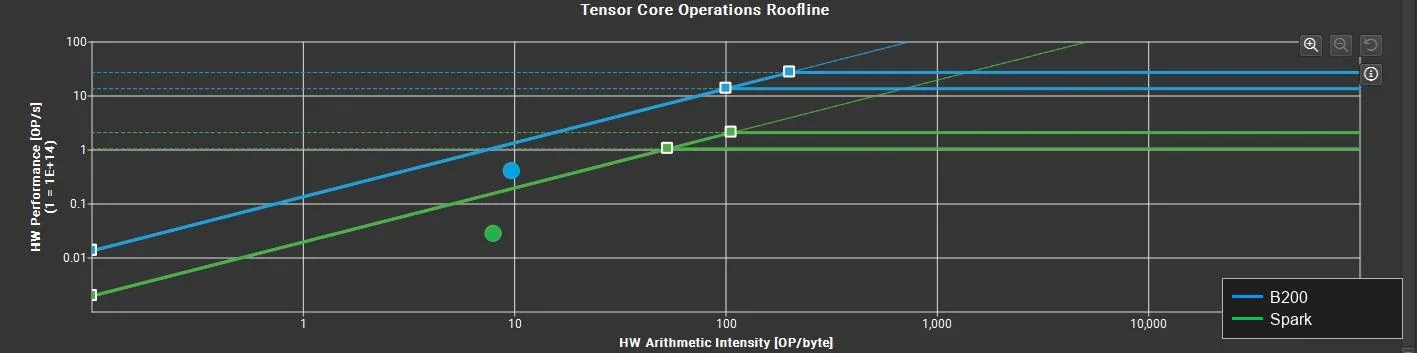
Hiệu suất mở rộng và tối ưu hóa khoảng không
Trong Hình 1, vị trí thẳng đứng của các điểm dữ liệu trên trục y xác nhận rằng hạt nhân đạt được mức sử dụng phần cứng cao hơn trên NVIDIA B200. Cụ thể, khoảng cách dọc của chấm xanh với đường mái bộ nhớ GPU NVIDIA B200 lớn hơn khoảng cách dọc của chấm xanh với đường mái Spark.
Phân tích đường mái này cho thấy các cơ hội bổ sung để tối ưu hóa và việc tối ưu hóa thuật toán hoặc bộ nhớ của NVIDIA DGX Spark cũng sẽ mang lại lợi ích cho GPU NVIDIA B200.
Sử dụng bộ đệm và cường độ số học
Phân tích trục x cho thấy chấm xanh được đặt ở bên phải chấm xanh, biểu thị rằng B200 đạt được Cường độ số học phần cứng vượt trội.
- Hiệu quả bộ nhớ đệm: Mặc dù dung lượng bộ nhớ đệm lớn hơn của GPU NVIDIA B200 cung cấp nền tảng lý thuyết để giảm lưu lượng DRAM nhưng chỉ riêng phần cứng là không đủ. Phần mềm phải được kiến trúc để khai thác các tài nguyên này.
- Tính di động của hạt nhân: Sự dịch chuyển sang phải chỉ ra rằng các hạt nhân Tile IR đã tận dụng thành công hệ thống phân cấp bộ đệm mở rộng NVIDIA B200 khi di chuyển.
Các hoạt động tối ưu hóa nhân Tile IR trong tương lai nhằm tăng cường độ số học trên Spark—di chuyển điểm dữ liệu xa hơn dọc theo trục x—vốn sẽ mang lại lợi ích hiệu suất tổng hợp khi chạy trên nhiều GPU đám mây khác nhau.
Tự động điều chỉnh đa nền tảng tự động
Hiện tại, các cấu hình tối ưu được lựa chọn dựa trên các đặc điểm của nền tảng. Các bản phát hành cuTile trong tương lai sẽ hỗ trợ tự động điều chỉnh đa nền tảng hoàn toàn tự động. Trình tự động điều chỉnh sẽ tự động khám phá kích thước ô tối ưu và cài đặt chiếm chỗ cho từng kiến trúc mục tiêu, cho phép tính di động hiệu suất trong suốt mà không cần bất kỳ cấu hình thủ công nào.
Bắt đầu với NVIDIA DGX Spark
Khi các hệ thống AI trở nên tinh vi hơn, NVIDIA DGX Spark cung cấp môi trường thực thi đa đối tượng linh hoạt cần thiết để triển khai chúng một cách hiệu quả. Từ suy luận đa tác nhân đến phục vụ hàng nghìn tỷ tham số, từ tinh chỉnh đến đường ống xuyên đám mây Tile IR, DGX Spark mang lại cả khả năng mở rộng và hiệu quả.
Kết quả là một nền tảng thống nhất nơi các doanh nghiệp có thể triển khai và mở rộng quy mô khối lượng công việc AI mà không cần viết lại cơ sở hạ tầng cho mọi mô hình hoặc thời gian chạy.
Bắt đầu xây dựng trên NVIDIA DGX Spark.
Bài viết liên quan
- Xây dựng chatbot AI nội bộ cho doanh nghiệp: Nhanh hơn, đúng ngữ cảnh hơn, kiểm soát tốt hơn
- NVIDIA Blackwell lập kỷ lục STAC-AI về suy luận LLM trong lĩnh vực tài chính
- NVIDIA Riva giải pháp Voice RAG: tối ưu luồng dữ liệu âm thanh và đồng bộ Avatar 3D
- NVIDIA Dynamo Snapshot: Khởi động nhanh cho workload suy luận trên Kubernetes
- Triển khai kiến trúc Multi-Agent Intelligent Warehouse cho việc vận hành kho hàng hiện đại
- Triển khai hệ thống Voice RAG bằng NVIDIA Riva framework trên hạ tầng cục bộ