Mục tiêu của vấn đề
Nhu cầu về trợ lý ảo giọng nói tương tác đang tăng mạnh mẽ trên toàn thế giới, với thị trường dự kiến đạt $33.74 tỷ USD vào năm 2030, tốc độ tăng trưởng 26.5% hàng năm. Doanh nghiệp cần giải pháp xử lý hoàn toàn local (on-device) để đạt được:
-
Độ trễ siêu thấp (<200ms end-to-end) – phản hồi tức thời như Siri, Alexa
-
Riêng tư tuyệt đối – không gửi audio lên cloud
-
Hoạt động offline 24/7 – không phụ thuộc internet
-
Tuỳ chỉnh thương hiệu – wake word riêng, phong cách hội thoại độc đáo
-
Tiết kiệm chi phí – không phí API cloud hàng tháng
Giới thiệu Giải pháp: NVIDIA Voice Agent Blueprint (Pipecat Framework)
NVIDIA cung cấp giải pháp trợ lý giọng nói hoàn chỉnh thông qua NVIDIA Voice Agent Blueprint, được xây dựng trên framework mã nguồn mở Pipecat và tích hợp với NVIDIA NIM (Neural Inference Microservices). Pipecat là framework agentic được sử dụng rộng rãi nhất hiện nay cho các ứng dụng voice AI và conversational AI thời gian thực.Thành phần giải pháp:
| Thành phần | Mô tả | Mô hình | Hiệu suất |
|---|---|---|---|
| NVIDIA Riva Parakeet ASR NIM | Nhận diện giọng nói real-time | Parakeet-RNNT-1.1B | 40–80ms latency |
| NVIDIA LLM NIM | Xử lý AI, hiểu ý định, tạo phản hồi | Llama 3.3 70B Instruct hoặc tuỳ chọn | 20–50ms token generation |
| NVIDIA Riva FastPitch-HifiGAN TTS NIM | Tổng hợp giọng nói tự nhiên | Parakeet FastPitch + HiFiGAN | 28–70ms latency |
| Pipecat Framework | Orchestration, xử lý frame, quản lý context | Open-source, vendor-neutral | Hỗ trợ 60+ AI models & services |
| (Optional) NVIDIA RAG | Tích hợp cơ sở tri thức nội bộ | Foundational RAG | Giảm hallucination, tăng độ chính xác |
Đặc Điểm Chính
-
Voice-only, không 3D animation – gọn nhẹ, nhanh, dễ triển khai
-
Orchestration via Pipecat framework – mã nguồn mở, hỗ trợ 60+ AI models
-
NIM microservices – triển khai bằng 1 câu lệnh docker, API OpenAI-compatible
-
Production-ready – đã được thử nghiệm ở quy mô doanh nghiệp
-
Dễ tuỳ chỉnh, scalable – từ PoC tới production không đổi phần cứng/phần mềm
Giải thích Chi tiết Các Thành phần Giải pháp
1. Nhận Diện Giọng Nói (Speech-to-Text)
NVIDIA Riva Parakeet ASR NIM
-
Mô hình: Parakeet-RNNT-1.1B (1.1 tỷ parameters)
-
Chức năng: Chuyển giọng nói thành văn bản real-time
-
Độ trễ: 40–80ms (first token) trên A100
-
Độ chính xác: WER 1.46% (tốt hơn Whisper-base)
-
Đầu vào: Audio 16kHz mono
-
Đầu ra: Văn bản viết thường
-
Xử lý tốt: Tiếng ồn nền, giọng địa phương, accent
-
Hỗ trợ ngôn ngữ: Tiếng Anh, có thể fine-tune tiếng Việt
Ví dụ:
-
Input: Đặt báo thức 7 giờ sáng mai
-
Output: đặt báo thức 7 giờ sáng mai
2. Xử Lý Ý Định & Tạo Phản Hồi (Language Understanding)
NVIDIA LLM NIM Microservice (NVIDIA Llama 3.3 70B Instruct hoặc mô hình tuỳ chọn)
-
Mô hình mặc định: NVIDIA Llama 3.3 70B Instruct
-
Chức năng chính: Hiểu ngữ cảnh hội thoại, phân loại intent, trích xuất entity, gọi API nội bộ
-
Độ trễ: 20–50ms token generation
-
Tốc độ: Nhanh hơn LLM 8B ~50%
-
Tối ưu Edge: Quantized INT8/FP8, fit vào 8–16GB VRAM
-
Ngôn ngữ: Tiếng Anh, có thể fine-tune tiếng Việt
-
Khả năng:
-
Phân loại ý định (intent classification)
-
Trích xuất thực thể (entity extraction)
-
Gọi hàm (function calling) – gọi API, smart home, database queries
-
Quản lý context (context retention) – lưu lịch sử hội thoại
-
Hội thoại đa lượt (multi-turn conversations)
-
3. Tổng Hợp Giọng Nói (Text-to-Speech)
NVIDIA Riva FastPitch-HifiGAN TTS NIM
-
Chức năng: Chuyển văn bản phản hồi → âm thanh tự nhiên
-
Chất lượng: 22kHz hi-fi, MOS 4.2/5.0 (gần giọng người thật)
-
Độ trễ: 28–70ms time-to-first-audio
-
Voice options: Nam/nữ, tuỳ chỉnh prosody, cảm xúc
-
Tính năng: Zero-shot voice cloning, SSML support
-
Hiệu năng: 133–464 RTFX trên A100
Ví dụ:
-
Input: Đã đặt báo thức 7 giờ sáng mai
-
Output: Giọng nói tổng hợp tự nhiên, phát ra <200ms
4. Orchestration Framework (Pipecat)
Pipecat Framework – mã nguồn mở, vendor-neutral, xử lý tất cả công việc nặng:
-
Frame Processing: Xử lý các "frame" (gói dữ liệu) – audio frames, text frames, control frames
-
Pipeline Architecture: Kết nối các processor lại – STT → Context Manager → LLM → TTS → Output
-
Advanced Audio Processing: Xử lý tốt trong môi trường ồn ào (sân bay, văn phòng ồn)
-
Phrase Endpointing & Turn Detection: Phát hiện khi nào user kết thúc nói, cho phép interrupt tự nhiên
-
Context Management: Theo dõi lịch sử hội thoại, correlated audio/text timestamps
-
Multi-transport Support: Hỗ trợ WebRTC, Telephony (PSTN/SIP), WebSockets, HTTP
-
Platform Integrations: Pipecat có sẵn client SDKs cho JavaScript, React, iOS, Android, C++, Python
-
LLM Flexibility: Thay đổi LLM bằng 1 dòng code – hỗ trợ tất cả NVIDIA NIM LLMs
Luồng Triển khai Toàn bộ Pipeline
Luồng triển khai Trợ lý Giọng nói AI (Voice-Only) với NVIDIA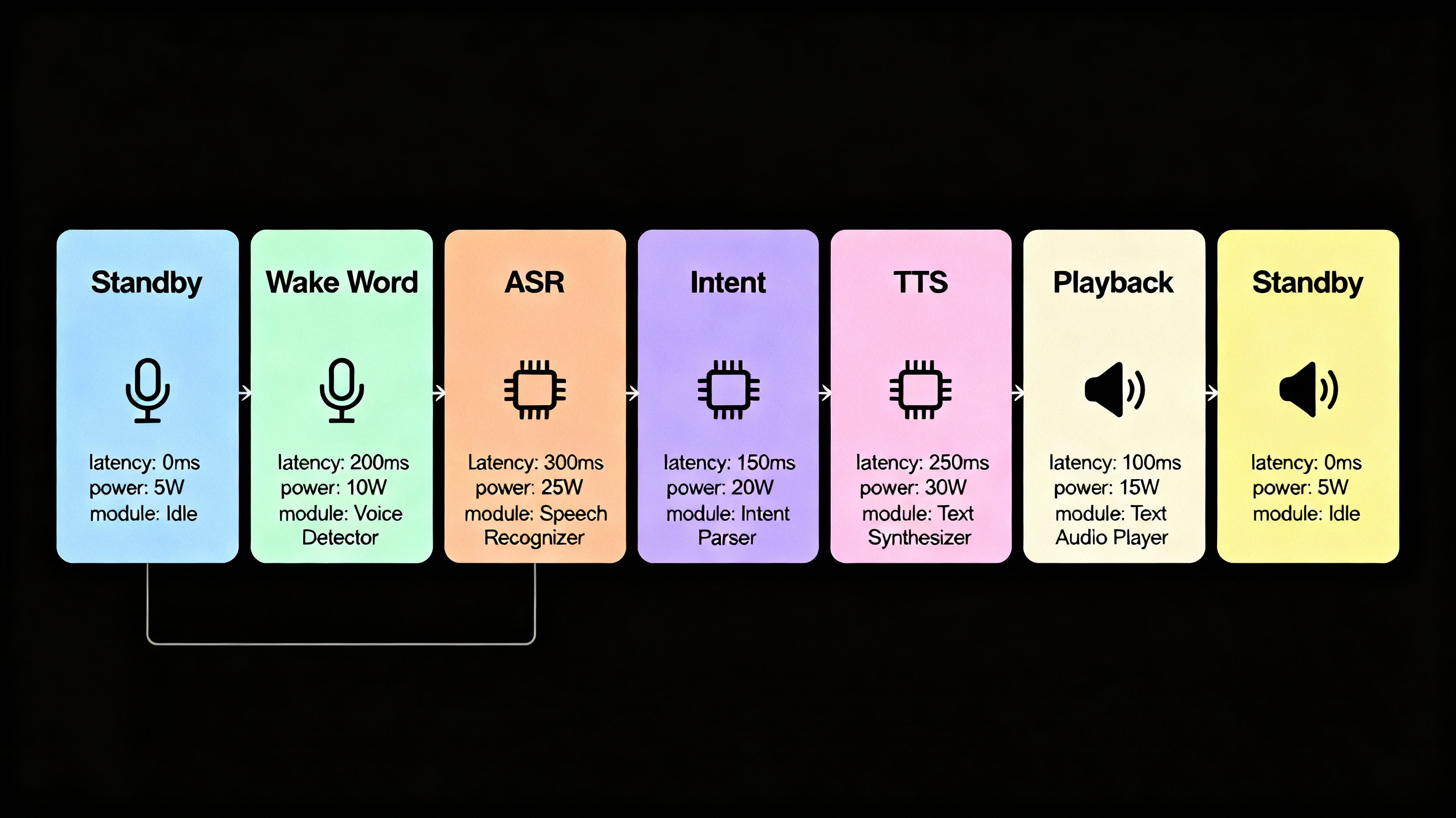
Giai đoạn Triển khai Chi tiết:
Giai Đoạn 1: Standby (Always-On, Low-Power)
-
Thành phần: OpenWakeWord chạy liên tục trên CPU/DSP
-
Cơ chế: Circular buffer ghi 2–3 giây âm thanh gần nhất
-
Tiêu thụ điện: <0.7mW (chế độ sleep)
-
GPU: Ở chế độ sleep, chờ tín hiệu kích hoạt
-
Nhiệm vụ: Giám sát âm thanh, phát hiện wake word
Giai Đoạn 2: Wake Word Detected
-
Sự kiện: Phát hiện wake word (ví dụ: Hey Brand) với độ tin cậy >99%
-
Hành động:
-
GPU "thức dậy" từ chế độ low-power
-
Tải các module: Riva ASR, LLM NIM, Riva TTS vào VRAM (~15–20GB tổng)
-
Pre-roll buffer (2 giây audio trước wake word) được chuẩn bị gửi cho ASR
-
Giai Đoạn 3: Speech Recognition (ASR)
-
Xử lý: Âm thanh người dùng → Riva Parakeet ASR (RNNT-1.1B)
-
Đầu ra: Văn bản real-time
-
Latency: 40–80ms (first token)
-
Độ chính xác: WER 1.46%
Giai Đoạn 4: Intent Processing & Context Management
-
Bộ xử lý: NVIDIA LLM NIM (Llama 3.3 70B Instruct)
-
Chức năng:
-
Hiểu ngữ cảnh hội thoại
-
Phân loại intent, trích xuất entity
-
Gọi API nội bộ nếu cần
-
(Tuỳ chọn) Kết nối RAG Pipeline để truy vấn dữ liệu doanh nghiệp
-
-
Latency: 20–50ms
Giai Đoạn 5: Response Generation & Speech Synthesis (TTS)
-
Module: Riva FastPitch + HiFiGAN
-
Chức năng: Chuyển văn bản phản hồi → âm thanh tự nhiên
-
Latency: 28–70ms
-
MOS: 4.2/5.0 (gần giọng người thật)
-
Hỗ trợ: Prosody control, voice cloning, SSML
Giai Đoạn 6: Playback & User Feedback
-
Âm thanh: Phát ra qua loa
-
Tổng latency end-to-end: ASR (40–80ms) + LLM (20–50ms) + TTS (28–70ms) = 90–200ms
-
Trải nghiệm: Phản hồi tức thì, tự nhiên, tương tác 2 chiều liên tục
Giai Đoạn 7: Return to Standby
-
Điều kiện: Sau 5 giây không có âm thanh mới
-
Hành động: GPU quay về chế độ sleep
-
Wake word detector: Tiếp tục chạy trên CPU/DSP
-
Công suất: <0.7mW
Bắt đầu dự án Trợ lý giọng nói AI của bạn với Siêu máy tính AI cá nhân
DGX Spark – siêu máy tính AI trên bàn làm việc tích hợp chip Grace Blackwell (GB10), 128GB bộ nhớ hợp nhất, hiệu năng ~1 petaFLOP/1000 AI TOPS (FP4) – là nền tảng lý tưởng để xây dựng Trợ lý Ảo AI.
Khả năng:
-
Xây dựng trợ lý ảo hiểu giọng nói, trả lời câu hỏi, xử lý yêu cầu tự động qua hội thoại tự nhiên
-
Triển khai real-time trên điện thoại, loa thông minh, hệ thống doanh nghiệp
-
Hoạt động nhanh gấp 10–100 lần so với CPU truyền thống
-
Hỗ trợ đa ngôn ngữ bao gồm tiếng Việt
-
Thiết bị được cài sẵn NeMo, Triton, TensorRT, giúp huấn luyện, tinh chỉnh và triển khai
Tích hợp & Mở Rộng:
-
Tích hợp trực tiếp các blueprint sẵn
-
Mở rộng quy mô từ PoC tới production mà không cần thay đổi nền tảng phần cứng hay phần mềm
Hỗ trợ từ NTC AI
NTC AI hỗ trợ toàn bộ hành trình: tư vấn giải pháp, triển khai hạ tầng DGX Spark, tinh chỉnh mô hình, tối ưu hóa hiệu suất, đào tạo nhân sự.
Biến Trợ lý Ảo AI thành công cụ tự động hóa, nâng cao trải nghiệm khách hàng, giảm chi phí vận hành cho doanh nghiệp.
Kết luận
Giải pháp NVIDIA Voice Agent Blueprint (dựa trên Pipecat Framework + NVIDIA NIM) mang lại trợ lý giọng nói AI hoàn chỉnh với những ưu điểm:
- Latency siêu thấp (<200ms end-to-end) – phản hồi tức thì như Siri, Alexa
- Privacy 100% – xử lý hoàn toàn on-device, không gửi dữ liệu lên cloud
- Offline 24/7 – hoạt động độc lập, không phụ thuộc internet
- Tuỳ chỉnh thương hiệu – wake word riêng, phong cách hội thoại độc đáo
- Tiết kiệm chi phí – không phí API cloud, deploy một lần, scale vô hạn
- Production-ready – mã nguồn mở, hỗ trợ 60+ AI models & services
- Dễ mở rộng – từ PoC tới production không đổi phần cứng/phần mềm
DGX Spark cung cấp sức mạnh tính toán (1 petaFLOP), bộ nhớ hợp nhất (128GB), và toàn bộ NVIDIA AI Software Stack để bạn triển khai từ PoC tới production chỉ trong vài tuần.
Bạn muốn Khám phá khả năng ứng dụng trợ lý ảo giọng nói vào doanh nghiệp của bạn?