Mục Tiêu Vấn Đề
Doanh nghiệp đối mặt với khối lượng dữ liệu văn bản khổng lồ nhưng thiếu khả năng xử lý hiệu quả:- Tiêu tốn thời gian con người - nhân sự dành hàng giờ tóm tắt thủ công
- Thiếu nhất quán - chất lượng phụ thuộc từng cá nhân, dễ sai sót
- Không mở rộng - không thể xử lý hàng triệu tài liệu
- Chi phí cao - cần đội ngũ lớn, overhead nhân sự lớn
- Mất cơ hội - thông tin quan trọng bị bỏ sót hoặc chậm trễ
Giải Pháp: NVIDIA RAG Blueprint
NVIDIA cung cấp NVIDIA RAG Blueprint - giải pháp hoàn chỉnh cho tóm tắt tài liệu tự động với Generative AI, được tối ưu hoàn toàn trên GPU NVIDIA. Thành phần chính:- NVIDIA NIM Microservices - Cung cấp mô hình AI tối ưu
- NVIDIA NeMo Retriever - Truy xuất và nhúng văn bản (embeddings)
- Large Language Models (LLMs) - Llama 3.3/3.1, Mistral
- Vector Databases - Tìm kiếm với GPU acceleration
- NVIDIA Guardrails - Đảm bảo an toàn nội dung
Kiến Trúc Chi Tiết: Thành Phần & Kết Quả
1. Data Ingestion & Extraction (Nhập Liệu)
| Thành Phần | Chi Tiết | Kết Quả |
| Input | PDF, Word, PowerPoint, Email, HTML, v.v. | Tài liệu đa định dạng |
| NeMo Retriever Extraction | Trích xuất text, bảng biểu, hình ảnh, metadata | Nội dung sạch sẽ, có cấu trúc |
| Chunking | Chia tài liệu lớn thành chunks (512-1024 tokens) | Khối dữ liệu tối ưu cho xử lý |
2. Embedding & Indexing (Nhúng & Lập Chỉ Mục)
| Thành Phần | Chi Tiết | Kết Quả |
| NeMo Retriever Embedding NIM | Mô hình: llama-3_2-nv-embedqa-1b-v2 (1B parameters) | Embeddings (vector hóa text) |
| Xuất | Chuyển văn bản thành vectors trong không gian 384D | Vectors có thể tìm kiếm |
| Vector Database | Milvus/Elasticsearch + GPU cuVS acceleration | Index với search < 50ms |
3. Retrieval Pipeline (Truy Xuất)
| Bước | Chi Tiết | Kết Quả |
| Query Embedding | Chuyển yêu cầu người dùng thành embedding | Query vector |
| Similarity Search | Tìm kiếm K documents/passages liên quan nhất | Top-K candidates |
| Reranking (NeMo Reranker) | Mô hình: llama-3_2-nv-rerankqa-1b-v2 | Danh sách xếp hạng chính xác |
4. Summarization & LLM Generation (Tóm Tắt & Sinh)
| Model LLM | Parameters | Output Tóm Tắt | Sử Dụng |
| Mistral | 7B | Tóm tắt đơn, tốc độ cao | Demo/Testing |
| Llama 3.3 Nemotron | 49B | Tóm tắt cân bằng chất lượng-tốc độ | Production Startup |
| Llama 3.1 | 70B-405B | Tóm tắt cao cấp, đa ngôn ngữ | Enterprise |
- Tóm tắt rõ ràng, súc tích (abstractive summary)
- Citations - tham chiếu đến tài liệu gốc
- Metadata - độ tin cậy, timestamp, v.v.
5. Content Safety (Đảm Bảo An Toàn)
| Bước | Công Cụ | Kết Quả |
| Content Filtering | Llama 3.1 NemoGuard 8B | Lọc nội dung không an toàn |
| Compliance Check | Topic Control NemoGuard | Kiểm soát chủ đề |
| Output Validation | Safety Guardrails | Tóm tắt tuân thủ quy định |
Luồng Triển Khai Thực Tế
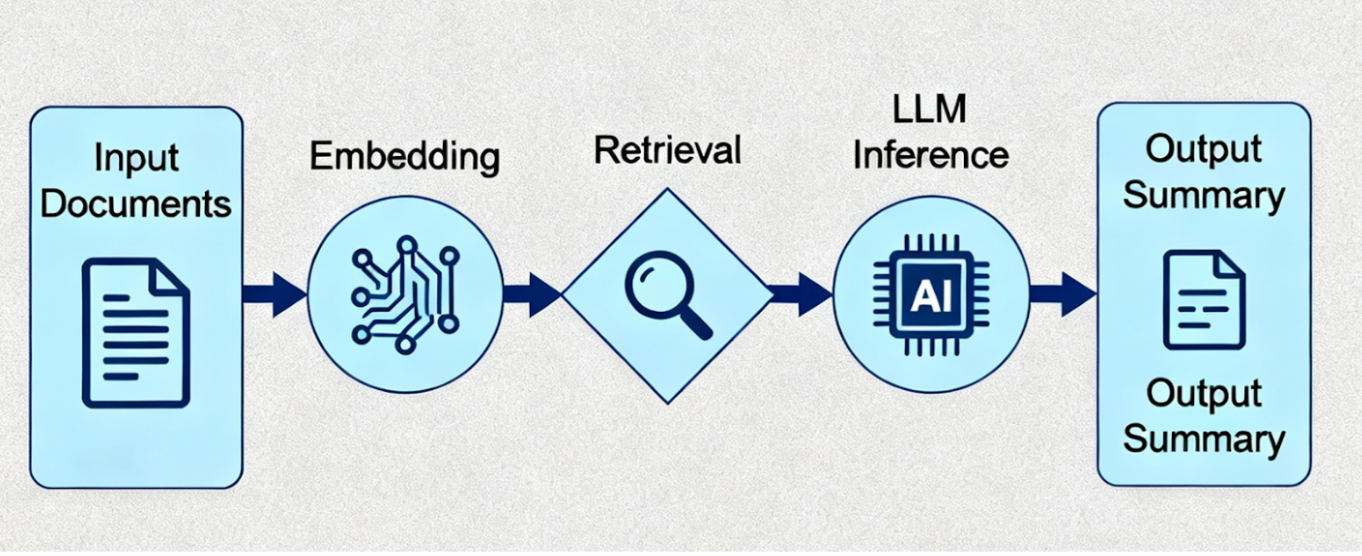
Giai Đoạn 1: Chuẩn Bị Dữ Liệu
- Thu thập tài liệu từ nhiều nguồn
- Trích xuất bằng NeMo Retriever Extraction
- Làm sạch, chuẩn hóa text, loại bỏ lỗi
- Chia thành chunks tối ưu (512-1024 tokens)
Giai Đoạn 2: Xây Dựng Indexes
- Sinh embeddings cho mỗi chunk (NeMo Retriever Embedding)
- Lưu vào Vector Database (Milvus) với GPU indexing
- Tạo indexes nhanh (< 50ms cho triệu tài liệu)
Giai Đoạn 3: Triển Khai Dịch Vụ
- Khởi động NVIDIA NIM microservices
- Cấu hình REST API endpoints
- Setup monitoring, logging, observability
- Tích hợp với ứng dụng hiện có
Giai Đoạn 4: Xử Lý Request Tóm Tắt
Người dùng gửi tài liệu
↓
Embedding query
↓
Retrieval (Vector DB search)
↓
Reranking (xác định tài liệu phù hợp nhất)
↓
LLM Summarization (tạo tóm tắt)
↓
Content Safety Check
↓
Trả về tóm tắt + citations
Bắt đầu dự án tóm tắt tự động bằng Generative AI của bạn với siêu máy tính AI cá nhân
DGX Spark — siêu máy tính AI trên bàn làm việc tích hợp chip Grace Blackwell (GB10), bộ nhớ hợp nhất 128 GB, hiệu năng ~1 petaFLOP / 1000 AI TOPS (FP4) — là nền tảng lý tưởng để xây dựng hệ thống tóm tắt tài liệu tự động với Generative AI cho doanh nghiệp, tổ chức và quản lý tri thức.
Khả năng nổi bật của RAG Summarization AI trên DGX Spark
-
Tóm tắt tự động, chính xác: Xử lý PDF, Word, PowerPoint, Email qua NVIDIA NeMo Retriever, sinh tóm tắt rõ ràng với citations tham chiếu tài liệu gốc.
-
Tìm kiếm nhanh: NeMo Retriever Embedding chuyển văn bản thành vectors, Vector Database tìm kiếm < 50ms cho hàng triệu tài liệu.
-
Xử lý hàng loạt: Từ demo tóm tắt 1 tài liệu đến xử lý hàng triệu documents/ngày, mở rộng từ DGX Spark tới cluster H100.
-
An toàn và tuân thủ: Llama 3.1 NemoGuard lọc nội dung không an toàn, kiểm soát chủ đề, đảm bảo compliance.
NVIDIA AI Software Stack sẵn có
Thiết bị được cài sẵn NIM Microservices, NeMo Retriever, LLMs (Llama 3.3 Nemotron 49B, Llama 3.1 70B), Vector Databases, Guardrails — hỗ trợ trích xuất, nhúng, truy xuất, tóm tắt và kiểm chứng nội dung từ PoC đến production.
Tích hợp và mở rộng linh hoạt
-
Xử lý đa định dạng: NeMo Retriever trích xuất từ bảng biểu, hình ảnh, text, metadata từ mọi loại tài liệu.
-
Embedding GPU-accelerated: Chuyển hàng triệu chunks thành vectors 384D nhanh chóng, index với Milvus + cuVS acceleration.
-
LLM linh hoạt: Mistral 7B cho demo, Llama 3.3 49B cho startup, Llama 3.1 70B-405B cho enterprise.
-
API production-ready: REST/gRPC endpoints, multi-model serving, dynamic batching, monitoring tích hợp.
Hỗ trợ từ NTC AI
NTC AI hỗ trợ tư vấn phần cứng, triển khai DGX Spark và hỗ trợ kết nối phần mềm AI (NIM, NeMo Retriever, LLMs, Guardrails) cho các ứng dụng tóm tắt tài liệu, RAG, xử lý văn bản và các bài toán Generative AI khác theo yêu cầu doanh nghiệp.
NTC AI đảm bảo tối ưu hiệu năng, bảo mật dữ liệu on-premise, mở rộng từ prototype tới production, và hỗ trợ monitoring, compliance cho dự án AI text-based.
Khởi đầu ngay hôm nay với DGX Spark — giải pháp tóm tắt tài liệu thông minh, tiết kiệm 70-80% chi phí nhân sự, nâng cao hiệu quả quản lý tri thức cho doanh nghiệp.
Lựa Chọn Model LLM Cho Tóm Tắt Văn Bản
| Model | Params | Tiêu Chí | Hardware Min. | Sử Dụng |
| Mistral | 7B | Tốc độ cao, tóm tắt đơn | L4 × 1 / DGX Spark | Demo |
| Llama 3.3 Nemotron | 49B | Cân bằng chất lượng-tốc độ | L4 × 2 / DGX Spark | Production Startup |
| Llama 3.1 | 70B | Chất lượng cao | H100 × 1-2 | Production Standard |
| Llama 3.1 | 405B | Tốt nhất, đa ngôn ngữ | H100 × 4+ (Tensor Parallel) | Enterprise |
- Demo/Testing → Mistral 7B hoặc Llama 3.3 49B trên DGX Spark
- Production Startup → Llama 3.3 49B trên L4 servers
- Production Enterprise → Llama 3.1 70B-405B trên H100 cluster
Lợi Ích Tổng Quát
- Tự đông hóa Hoàn Toàn - Loại bỏ công cụ tắt
- Khả năng mở rộng - Từ demo laptop → triệu tài liệu/ngày
- Độ chính xác Cao - LLM hiện đại + tối ưu hóa truy xuất
- Sẵn sàng cho doanh nghiệp - Tích hợp an toàn, tuân thủ, giám sát
- Tiết kiệm chi phí - Tiết kiệm 70-80% chi phí nhân sự
- Linh hoạt - DGX Spark (demo) → Sản xuất (L4/H100)
Tóm lại
Giải pháp NVIDIA RAG Blueprint cho Summarization trên DGX Spark cung cấp:
-
Tóm tắt tự động: NeMo Retriever trích xuất, LLMs (Mistral, Llama 3.3/3.1) sinh tóm tắt với citations, giảm 70-80% chi phí nhân sự.
-
Truy xuất nhanh: Embedding vectors, Vector Database search < 50ms, xử lý hàng triệu tài liệu, reranking chính xác.
-
An toàn: Llama 3.1 NemoGuard lọc nội dung, kiểm soát chủ đề, compliance tự động.
-
Linh hoạt mở rộng: DGX Spark cho demo/startup, L4/H100 cho production, API microservices ready.
Biến dữ liệu văn bản khổng lồ thành tri thức hữu dụng — tóm tắt tự động, chính xác, tiết kiệm thời gian con người.
Bạn muốn khám phá khả năng ứng dụng Generative AI RAG vào doanh nghiệp của bạn?
Liên hệ tư vấn