Các nhà khoa học dữ liệu dành rất nhiều thời gian để làm sạch và chuẩn bị các tập dữ liệu lớn, không có cấu trúc trước khi bắt đầu phân tích, thường đòi hỏi kiến thức lập trình và thống kê vững chắc. Việc quản lý kỹ thuật đặc trưng, tinh chỉnh mô hình và tính nhất quán trong các quy trình làm việc rất phức tạp và dễ xảy ra lỗi. Những thách thức này càng trở nên trầm trọng hơn do tính chất chậm chạp và tuần tự của các quy trình học máy dựa trên CPU, khiến cho việc thử nghiệm và lặp lại trở nên kém hiệu quả.
Tăng tốc khoa học dữ liệu ML agent
Chúng tôi đã tạo nguyên mẫu một tác nhân khoa học dữ liệu có khả năng diễn giải ý định của người dùng và điều phối các tác vụ lặp đi lặp lại trong quy trình làm việc học máy để đơn giản hóa khoa học dữ liệu và thử nghiệm học máy. Với khả năng tăng tốc GPU, tác nhân này có thể xử lý các tập dữ liệu với hàng triệu mẫu bằng cách sử dụng thư viện Khoa học dữ liệu NVIDIA CUDA-X. Nó thể hiện NVIDIA Nemotron Nano-9B-v2 , một mô hình ngôn ngữ mã nguồn mở nhỏ gọn, mạnh mẽ được thiết kế để dịch ý định của nhà khoa học dữ liệu thành một quy trình làm việc được tối ưu hóa.
Với thiết lập này, các nhà phát triển có thể khám phá các tập dữ liệu lớn, huấn luyện mô hình và đánh giá kết quả chỉ bằng cách trò chuyện với trợ lý ảo. Nó thu hẹp khoảng cách giữa ngôn ngữ tự nhiên và điện toán hiệu năng cao, cho phép người dùng chuyển từ dữ liệu thô sang thông tin chi tiết kinh doanh chỉ trong vài phút. Chúng tôi khuyến khích bạn sử dụng đây như một điểm khởi đầu để xây dựng trợ lý ảo của riêng mình với các mô hình ngôn ngữ thứ cấp (LLM), công cụ và giải pháp lưu trữ khác nhau phù hợp với nhu cầu cụ thể của bạn. Khám phá các tập lệnh Python cho trợ lý ảo này trên GitHub .
Điều phối tác nhân khoa học dữ liệu
Kiến trúc của tác nhân được thiết kế theo hướng mô đun hóa, khả năng mở rộng và tăng tốc GPU. Nó được tổ chức thành năm lớp cốt lõi và một kho dữ liệu tạm thời hoạt động cùng nhau để dịch các lời nhắc bằng ngôn ngữ tự nhiên thành các quy trình làm việc có thể thực thi, xử lý dữ liệu và học máy. Hình 1 minh họa quy trình làm việc cấp cao về cách mỗi lớp tương tác với nhau.
 Hình 1. Sơ đồ kiến trúc của tác nhân khoa học dữ liệu
Hình 1. Sơ đồ kiến trúc của tác nhân khoa học dữ liệu
Hãy cùng xem xét kỹ hơn cách các lớp hoạt động cùng nhau.
Layer 1: Giao diện người dùng
Giao diện người dùng được phát triển bằng chatbot đàm thoại dựa trên Streamlit, cho phép người dùng tương tác với trợ lý ảo bằng tiếng Anh thông thường.
Layer 2: Bộ điều phối tác nhân
Đây là bộ điều khiển trung tâm phối hợp với tất cả các lớp. Nó diễn giải các yêu cầu của người dùng, ủy quyền thực thi cho LLM để hiểu ý định, gọi các hàm tăng tốc GPU phù hợp từ Lớp Công cụ và phản hồi bằng ngôn ngữ tự nhiên. Mỗi phương thức điều phối là một lớp bao bọc nhẹ xung quanh một hàm GPU; ví dụ, _describe_data trong truy vấn người dùng, các lệnh gọi basic_eda(), trong khi _optimize_ridgeở truy vấn người dùng, các lệnh gọi optimize_ridge_regression().
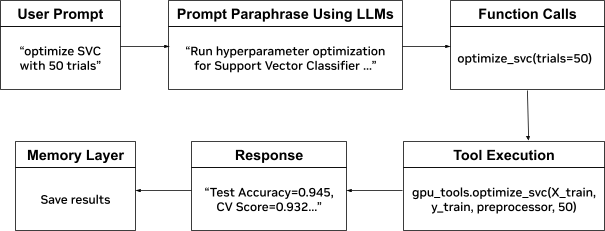
Hình 2. Luồng điều phối cho truy vấn ví dụ “tối ưu hóa SVC với 50 lần thử nghiệm”
Layer 3: Lớp LLM
Lớp LLM đóng vai trò là công cụ suy luận của tác nhân, khởi tạo máy khách mô hình ngôn ngữ để giao tiếp với Nemotron Nano 9B-v2 bằng API NVIDIA NIM. Lớp này cho phép tác nhân diễn giải các đầu vào ngôn ngữ tự nhiên và dịch chúng thành các hành động có cấu trúc, có thể thực thi thông qua bốn cơ chế chính: mô hình LLM, chiến lược thử lại để giao tiếp ổn định, gọi hàm để gọi công cụ có cấu trúc và cửa sổ gọi hàm.
- LLM Model
Kiến trúc lớp LLM không phụ thuộc vào LLM và có thể hoạt động với bất kỳ mô hình ngôn ngữ nào hỗ trợ gọi hàm. Đối với ứng dụng này, chúng tôi đã sử dụng Nemotron Nano-9B-v2, hỗ trợ cả gọi hàm và suy luận nâng cao. Hơn nữa, với kích thước nhỏ hơn, mô hình này cung cấp sự cân bằng tối ưu giữa hiệu quả và khả năng, và có thể được triển khai trên một GPU duy nhất để suy luận. Nó mang lại thông lượng tạo token cao hơn tới 6 lần so với các mô hình hàng đầu khác trong cùng phân khúc kích thước, trong khi tính năng ngân sách suy nghĩ cho phép các nhà phát triển kiểm soát số lượng token “suy nghĩ” được sử dụng, giảm chi phí suy luận lên đến 60%. Sự kết hợp giữa hiệu suất vượt trội và hiệu quả chi phí này cho phép các quy trình làm việc hội thoại thời gian thực khả thi về mặt kinh tế để triển khai trong môi trường sản xuất. - Chiến lược thử lại để đảm bảo giao tiếp ổn định
Máy khách LLM triển khai cơ chế thử lại lùi thời gian theo cấp số nhân để xử lý các sự cố mạng tạm thời và giới hạn tốc độ API, đảm bảo giao tiếp đáng tin cậy ngay cả trong điều kiện mạng bất lợi hoặc tải API cao. - Gọi hàm để thực thi công cụ có cấu trúc
Gọi hàm là cầu nối giữa ngôn ngữ tự nhiên và thực thi mã bằng cách cho phép LLM dịch ý định của người dùng thành các lệnh gọi công cụ có cấu trúc trong Agent Orchestrator. Agent định nghĩa các công cụ có sẵn bằng cách sử dụng các lược đồ hàm tương thích với OpenAI, trong đó chỉ định tên, mục đích, tham số và ràng buộc của từng công cụ. - Cửa sổ gọi hàm
Chức năng gọi hàm biến đổi LLM từ một trình tạo văn bản thành một công cụ suy luận có khả năng điều phối API. Mô hình, cụ thể là Nemotron Nano-9B-v2, được cung cấp một “đặc tả API” có cấu trúc về các công cụ có sẵn, sử dụng đặc tả này để cố gắng hiểu ý định của người dùng, chọn các hàm phù hợp, trích xuất các tham số với kiểu dữ liệu chính xác và phối hợp xử lý dữ liệu nhiều bước và hoạt động học máy. Tất cả điều này được thực hiện thông qua ngôn ngữ tự nhiên, loại bỏ nhu cầu người dùng phải hiểu cú pháp API hoặc viết mã.Luồng gọi hàm hoàn chỉnh được hiển thị trong Hình 3 cho thấy cách ngôn ngữ tự nhiên được chuyển đổi thành mã có thể thực thi. Tham khảochat_agent.pycácllm.pytập lệnh trong mã GitHub để biết các thao tác được liệt kê trong Hình 3.

Hình 3. Gọi hàm theo 4 bước
Layer 4: Lớp bộ nhớ
Lớp bộ nhớ (ExperimentStore) lưu trữ siêu dữ liệu của thí nghiệm, bao gồm cấu hình mô hình, số liệu hiệu suất và kết quả đánh giá, chẳng hạn như độ chính xác và điểm F1. Siêu dữ liệu này được lưu ở định dạng JSONL chuẩn trong một tệp dành riêng cho phiên, cho phép theo dõi và truy xuất trong phiên thông qua các hàm như get_recent_experiments()và show_history().
Layer 5: Lưu trữ dữ liệu tạm thời
Lớp lưu trữ dữ liệu tạm thời lưu trữ các tệp đầu ra dành riêng cho phiên (best_model.joblib và predictions.csv) trong thư mục tạm thời của hệ thống cũng như giao diện người dùng để tải xuống và sử dụng ngay lập tức. Các tệp này sẽ tự động bị xóa khi tác nhân tắt.
Layer 6: Lớp công cụ
Lớp công cụ là lõi tính toán của tác nhân, chịu trách nhiệm thực hiện các chức năng khoa học dữ liệu như tải dữ liệu, phân tích dữ liệu thăm dò (EDA), huấn luyện và đánh giá mô hình, và tối ưu hóa siêu tham số (HPO). Chức năng được chọn để thực thi dựa trên truy vấn của người dùng. Nhiều chiến lược tối ưu hóa khác nhau được sử dụng, bao gồm:
- Tính nhất quán và khả năng lặp lại
Hệ thống sử dụng các phương pháp trừu tượng khác nhau từ scikit-learn (một thư viện mã nguồn mở phổ biến) để đảm bảo quá trình tiền xử lý dữ liệu và huấn luyện mô hình nhất quán trên các môi trường huấn luyện, kiểm thử và sản xuất. Thiết kế này ngăn ngừa các lỗi thường gặp trong học máy như rò rỉ dữ liệu và tiền xử lý không nhất quán bằng cách tự động áp dụng chính xác các phép biến đổi giống nhau (giá trị điền khuyết, tham số tỷ lệ và ánh xạ mã hóa) đã học được trong quá trình huấn luyện cho tất cả dữ liệu suy luận. - Quản lý bộ nhớ
Để xử lý các tập dữ liệu lớn, chúng tôi sử dụng các chiến lược tối ưu hóa bộ nhớ.Float32Việc chuyển đổi giúp giảm mức sử dụng bộ nhớ, quản lý bộ nhớ GPU giải phóng bộ nhớ cache đang hoạt động của GPU, và cấu hình đầu ra dày đặc nhanh hơn trên GPU so với các định dạng thưa thớt. - Thực thi chức năng
Công cụ thực thi sử dụng các thư viện khoa học dữ liệu CUDA-X như cuDF và cuML để cung cấp hiệu năng tăng tốc GPU trong khi vẫn duy trì cú pháp tương tự như pandas và scikit-learn. Khả năng tăng tốc không cần thay đổi mã này đạt được thông qua cơ chế tải trước mô-đun của Python, cho phép các nhà phát triển chạy mã CPU hiện có trên GPU mà không cần viết lại mã. Bộcudf.pandastăng tốc thay thế các thao tác của pandas bằng các thao tác tương đương trên GPU, đồng thờicuml.acceltự động thay thế các mô hình scikit-learn bằng các triển khai GPU của cuML.
Lệnh sau khởi chạy giao diện Streamlit với tính năng tăng tốc GPU được bật cho cả xử lý dữ liệu và các thành phần học máy:
python -m cudf.pandas -m cuml.accel -m streamlit run user_interface.py |
Tăng tốc, tính mô đun và khả năng mở rộng của ML Agent
Hệ thống được xây dựng theo thiết kế mô-đun, dễ dàng mở rộng thông qua các lệnh gọi hàm mới, kho lưu trữ thử nghiệm, tích hợp LLM và các cải tiến khác. Kiến trúc phân lớp của nó hỗ trợ việc tích hợp thêm các khả năng theo thời gian. Ngay từ khi cài đặt, nó đã hỗ trợ các thuật toán học máy phổ biến, phân tích dữ liệu khám phá (EDA) và tối ưu hóa siêu tham số (HPO).
Sử dụng thư viện khoa học dữ liệu CUDA-X, tác nhân này tăng tốc quá trình xử lý dữ liệu và quy trình học máy từ đầu đến cuối. Khả năng tăng tốc dựa trên GPU này mang lại hiệu suất tăng từ 3x đến 43x, tùy thuộc vào thao tác cụ thể. Bảng 1 nêu bật tốc độ tăng hiệu suất đạt được trên một số tác vụ chính, bao gồm các thao tác học máy, xử lý dữ liệu và HPO.
| Nhiệm vụ của agent | CPU (giây) | GPU (giây) | Tăng tốc | Chi tiết |
| Nhiệm vụ phân loại ML | 21.410 | 6.886 | ~3 lần | Sử dụng hồi quy logistic, phân loại rừng ngẫu nhiên và phân loại vectơ hỗ trợ tuyến tính với 1 triệu mẫu. |
| Nhiệm vụ ML hồi quy | 57.040 | 8.947 | ~6 lần | Sử dụng hồi quy Ridge, hồi quy rừng ngẫu nhiên và hồi quy vectơ hỗ trợ tuyến tính với 1 triệu mẫu. |
| Tối ưu hóa siêu tham số cho thuật toán học máy | 18.447 | 906 | ~20 lần | Các phép toán ma trận được tăng tốc bằng cuBLAS (phân tích QR, SVD) chiếm ưu thế; đường dẫn điều chỉnh được tính toán song song và được sử dụng. |
Bảng 1: Tốc độ tăng tốc từ đầu đến cuối đạt được bởi tác nhân sử dụng thư viện Khoa học Dữ liệu CUDA-X
Hãy bắt đầu với các mô hình Nemotron và thư viện Khoa học Dữ liệu CUDA-X.
Hãy bắt đầu với các mô hình Nemotron và thư viện Khoa học Dữ liệu CUDA-X. Công cụ khoa học dữ liệu mã nguồn mở này có sẵn trên GitHub và sẵn sàng tích hợp với các tập dữ liệu của bạn để thực hiện thử nghiệm học máy từ đầu đến cuối. Tải xuống công cụ này và cho chúng tôi biết bạn đã thử nghiệm với những tập dữ liệu nào, tốc độ tăng lên bao nhiêu và những tùy chỉnh bạn đã thực hiện.
Tìm hiểu thêm:
- Loạt mô hình Nemotron và các ứng dụng tác nhân
- Các thư viện Khoa học Dữ liệu CUDA-X: cuML không cần thay đổi mã và sổ tay cộng đồng RAPIDS.ai
- Google Colab và các thư viện xử lý dữ liệu và học máy mới nhất với khả năng không cần thay đổi mã.
- Lộ trình học tập của DLI về khoa học dữ liệu với các khóa học tự học và có giảng viên hướng dẫn.