
Khi các mô hình AI ngày càng lớn hơn và kiến trúc trở nên phức tạp hơn, các nhà nghiên cứu và kỹ sư liên tục tìm ra các kỹ thuật mới để tối ưu hóa hiệu suất và chi phí tổng thể khi đưa các hệ thống AI vào sản xuất.
Tối ưu mô hình là một nhóm các kỹ thuật tập trung vào việc nâng cao hiệu quả dịch vụ suy luận. Những kỹ thuật này mang lại hiệu quả chi phí cao nhất, cải thiện trải nghiệm người dùng và khả năng mở rộng. Các kỹ thuật này bao gồm từ các phương pháp nhanh chóng và hiệu quả như lượng tử hóa mô hình đến các quy trình nhiều bước mạnh mẽ như cắt tỉa và chưng cất.
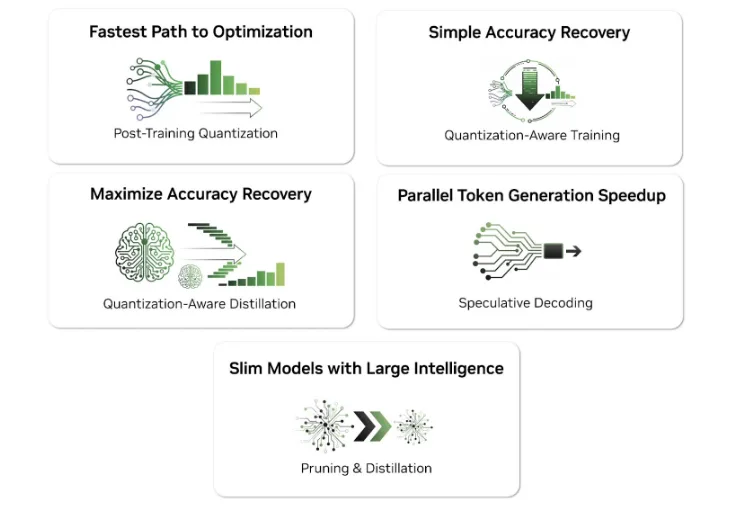
Bài viết này sẽ đề cập đến năm kỹ thuật tối ưu hóa mô hình hàng đầu được hỗ trợ bởi NVIDIA Model Optimizer và cách mỗi kỹ thuật góp phần cải thiện hiệu năng, tổng chi phí sở hữu (TCO) và khả năng mở rộng của các triển khai trên GPU NVIDIA.
Những kỹ thuật này là những công cụ mạnh mẽ và có khả năng mở rộng nhất hiện có trong Model Optimizer mà các nhóm có thể áp dụng ngay lập tức để giảm chi phí trên mỗi token, cải thiện thông lượng và tăng tốc suy luận ở quy mô lớn.
1. Lượng tử hóa sau huấn luyện
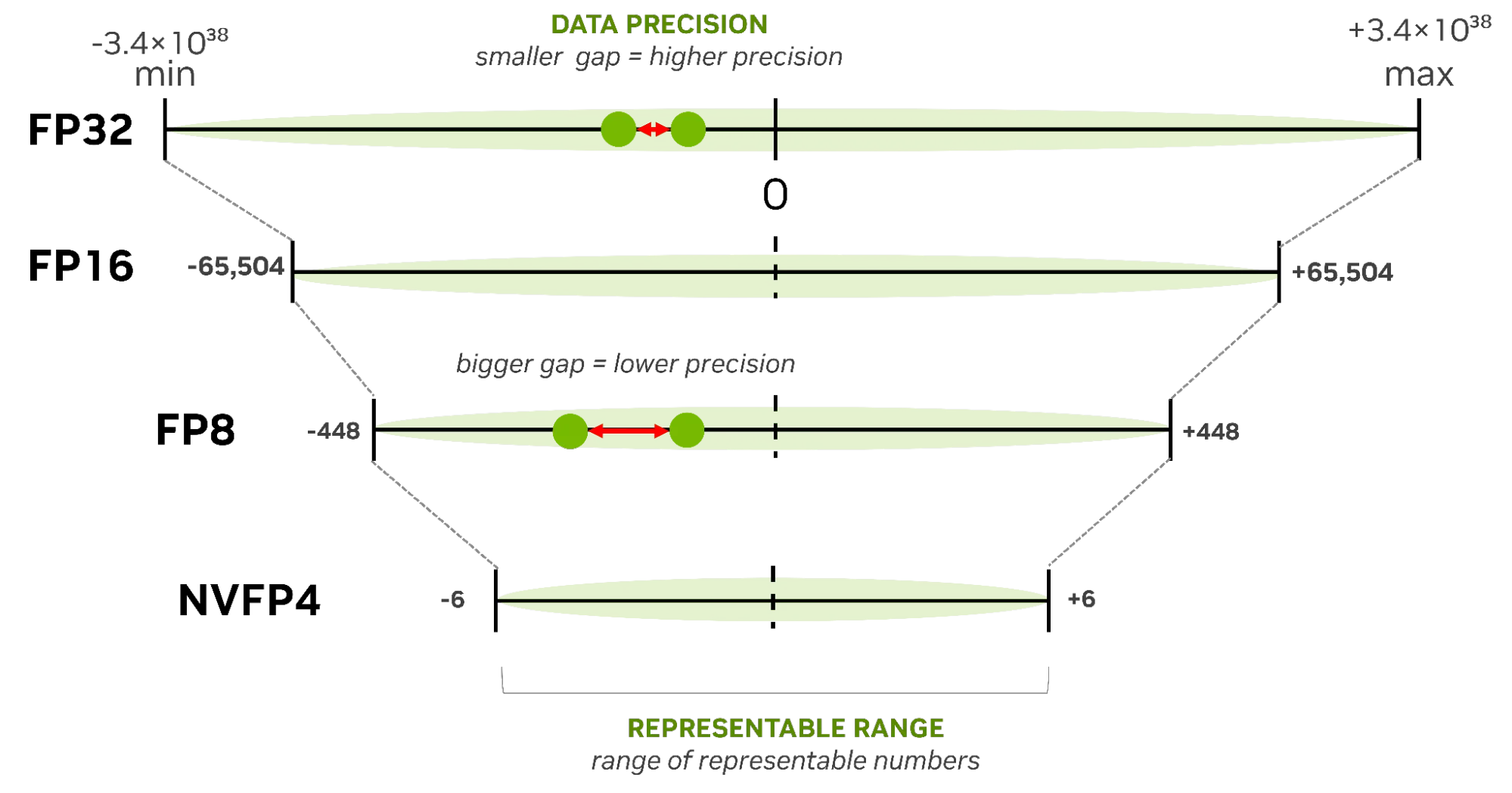
Lượng tử hóa sau huấn luyện (PTQ) là con đường nhanh nhất để tối ưu hóa mô hình. Bạn có thể tận dụng một mô hình hiện có (FP16/BF16/FP8) và nén nó xuống định dạng có độ chính xác thấp hơn (FP8, NVFP4, INT8, INT4) bằng cách sử dụng tập dữ liệu hiệu chuẩn—mà không cần thay đổi vòng lặp huấn luyện ban đầu. Đây là điểm mà hầu hết các nhóm nên bắt đầu. Phương pháp này dễ áp dụng với Model Optimizer và mang lại lợi ích ngay lập tức về độ trễ và thông lượng, ngay cả trên các mô hình nền tảng quy mô lớn (foundation models).
| Ưu điểm | Nhược điểm |
| –Thời gian đạt được giá trị nhanh nhất –Có thể đạt được với tập dữ liệu hiệu chuẩn nhỏ –Lợi ích về bộ nhớ, độ trễ và thông lượng được cộng dồn với các tối ưu hóa khác –Các công thức lượng tử hóa tùy chỉnh cao ( ví dụ: NVFP4 KV Cache ) |
– Có thể cần áp dụng kỹ thuật khác (QAT/QAD) nếu chất lượng tối thiểu giảm xuống dưới mức SLA. |
Để tìm hiểu thêm, hãy xem bài viết Tối ưu hóa LLM để đạt hiệu suất và độ chính xác cao hơn với lượng tử hóa sau huấn luyện .
2. Huấn luyện có tính đến lượng tử hóa
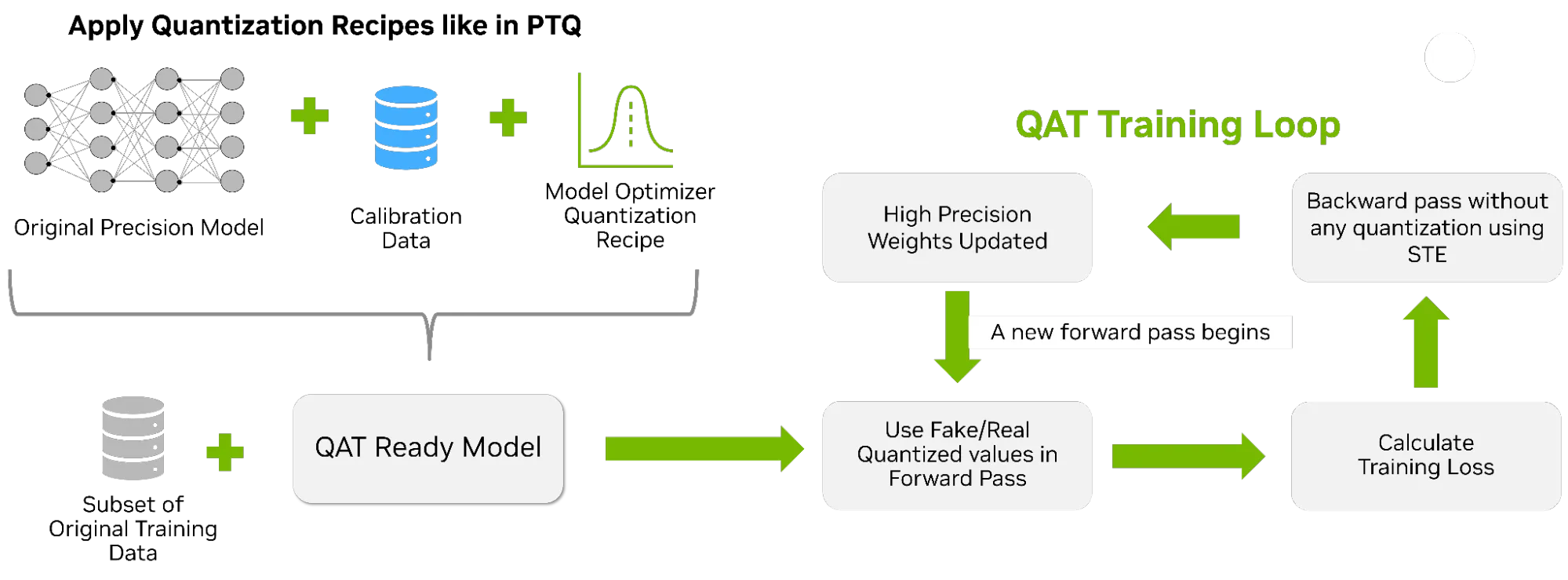
Huấn luyện có nhận thức lượng tử hóa (QAT) đưa vào một giai đoạn tinh chỉnh ngắn, có mục tiêu, trong đó mô hình được điều chỉnh để tính đến lỗi độ chính xác thấp. Nó mô phỏng nhiễu lượng tử hóa trong vòng lặp tiến trong khi tính toán gradient ở độ chính xác cao hơn. QAT là bước tiếp theo được khuyến nghị khi cần độ chính xác bổ sung vượt quá những gì PTQ đã cung cấp.
| Ưu điểm | Nhược điểm |
| –Khôi phục toàn bộ hoặc phần lớn độ chính xác bị mất ở độ chính xác thấp –Hoàn toàn tương thích với NVFP4, đặc biệt là về độ ổn định FP4 |
– Yêu cầu ngân sách huấn luyện cộng với dữ liệu – Thời gian triển khai lâu hơn so với chỉ sử dụng PTQ đơn thuần |
Để tìm hiểu thêm, hãy xem Cách huấn luyện có nhận thức về lượng tử hóa giúp khôi phục độ chính xác ở độ phân giải thấp .
3. Chưng cất có tính đến lượng tử hóa
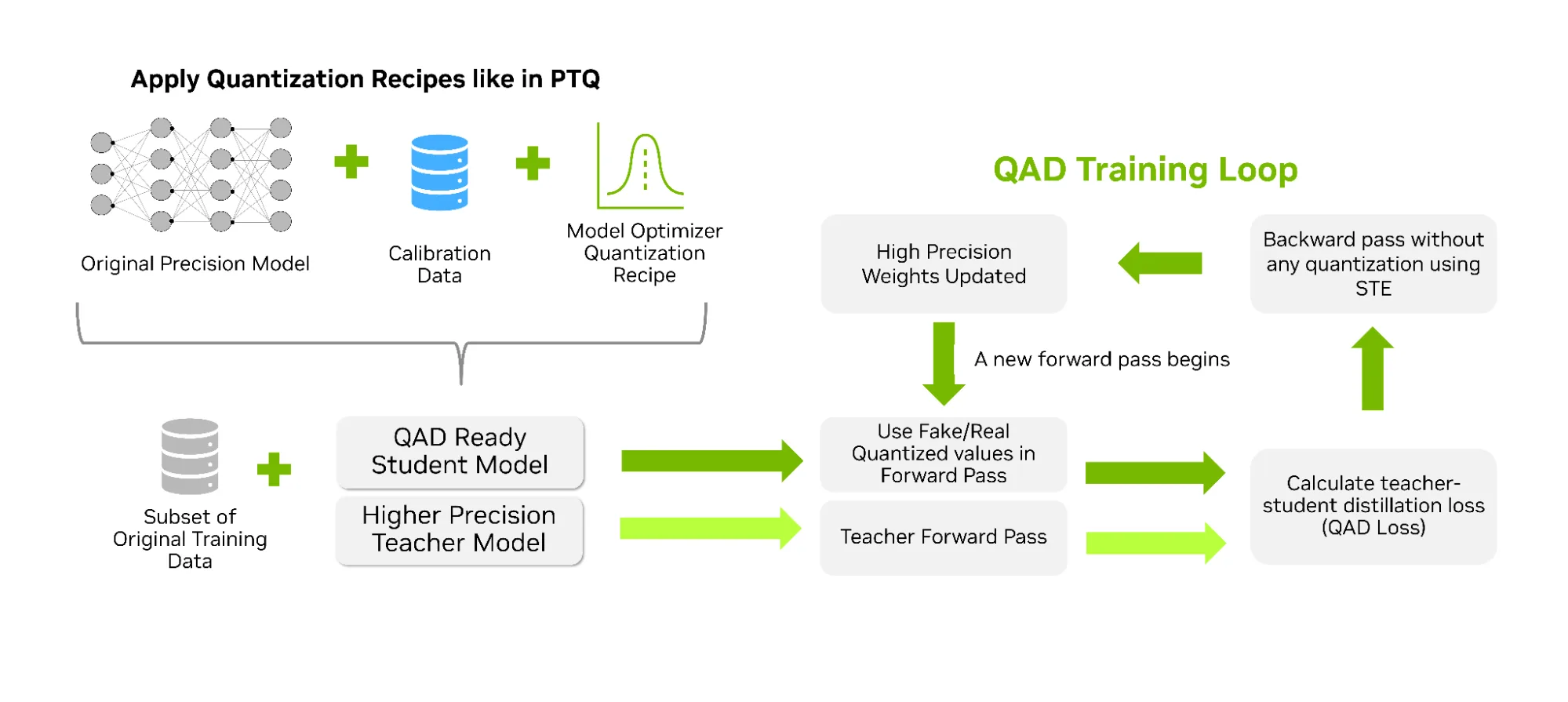
Phương pháp chưng cất có tính đến lượng tử hóa (QAD) tiến thêm một bước so với QAT. Với kỹ thuật này, mô hình học sinh học cách tính đến các lỗi lượng tử hóa đồng thời được căn chỉnh theo độ chính xác tối đa của mô hình giáo viên thông qua hàm mất mát chưng cất (distillation loss). QAD tăng cường khả năng của QAT bằng cách thêm các yếu tố giảng dạy từ các nguyên tắc chưng cất, cho phép bạn trích xuất chất lượng tối đa có thể trong khi vẫn chạy ở độ chính xác cực thấp trong quá trình suy luận. QAD là một lựa chọn hiệu quả cho các tác vụ tiếp theo thường bị suy giảm hiệu suất đáng kể sau khi lượng tử hóa.
| Ưu điểm | Nhược điểm |
| – Khả năng phục hồi độ chính xác cao nhất – Lý tưởng cho các quy trình xử lý hậu huấn luyện nhiều giai đoạn, giúp thiết lập dễ dàng và hội tụ mạnh mẽ |
– Thêm chu kỳ huấn luyện sau giai đoạn huấn luyện sơ bộ – Tiêu tốn nhiều bộ nhớ hơn – Quy trình triển khai hiện nay phức tạp hơn một chút. |
Để tìm hiểu thêm, hãy xem Cách huấn luyện có nhận thức về lượng tử hóa giúp khôi phục độ chính xác ở độ phân giải thấp .
4. Giải mã suy đoán
Bước giải mã trong suy luận được biết đến là thường gặp phải các nút thắt cổ chai về thuật toán xử lý tuần tự. Giải mã suy đoán giải quyết trực tiếp vấn đề này bằng cách sử dụng một mô hình dự thảo nhỏ hơn hoặc nhanh hơn (như EAGLE-3) để đề xuất nhiều token trước, sau đó xác minh chúng song song với mô hình mục tiêu. Điều này giúp giảm độ trễ tuần tự xuống chỉ còn một bước duy nhất và giảm đáng kể số lần forward pass cần thiết ở độ dài chuỗi dài, mà không cần thay đổi trọng số của mô hình.
Phương pháp giải mã suy đoán được khuyến nghị khi bạn muốn tăng tốc độ tạo dữ liệu ngay lập tức mà không cần huấn luyện lại hoặc lượng tử hóa, và nó kết hợp hoàn hảo với các tối ưu hóa khác trong danh sách này để tăng cường thông lượng và độ trễ.
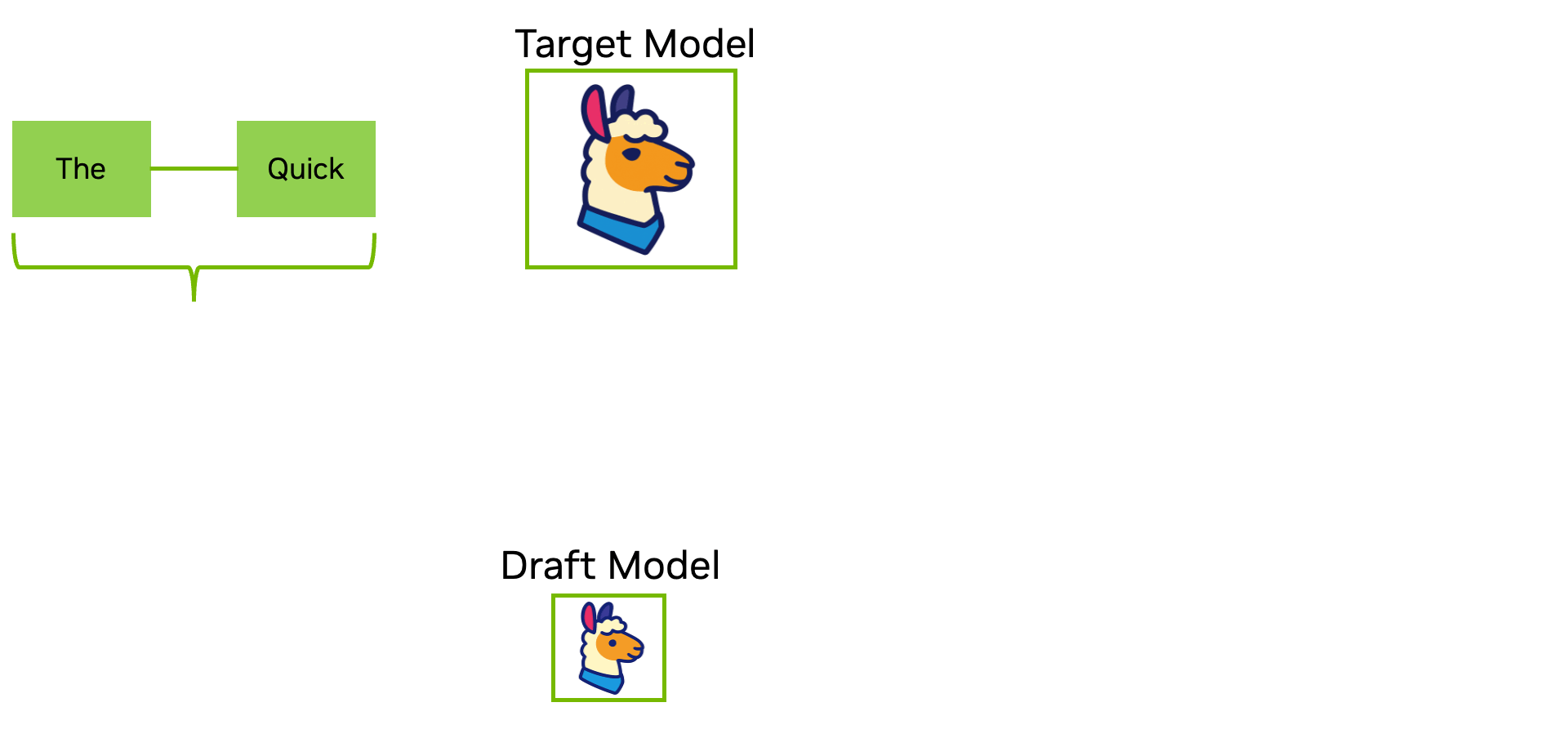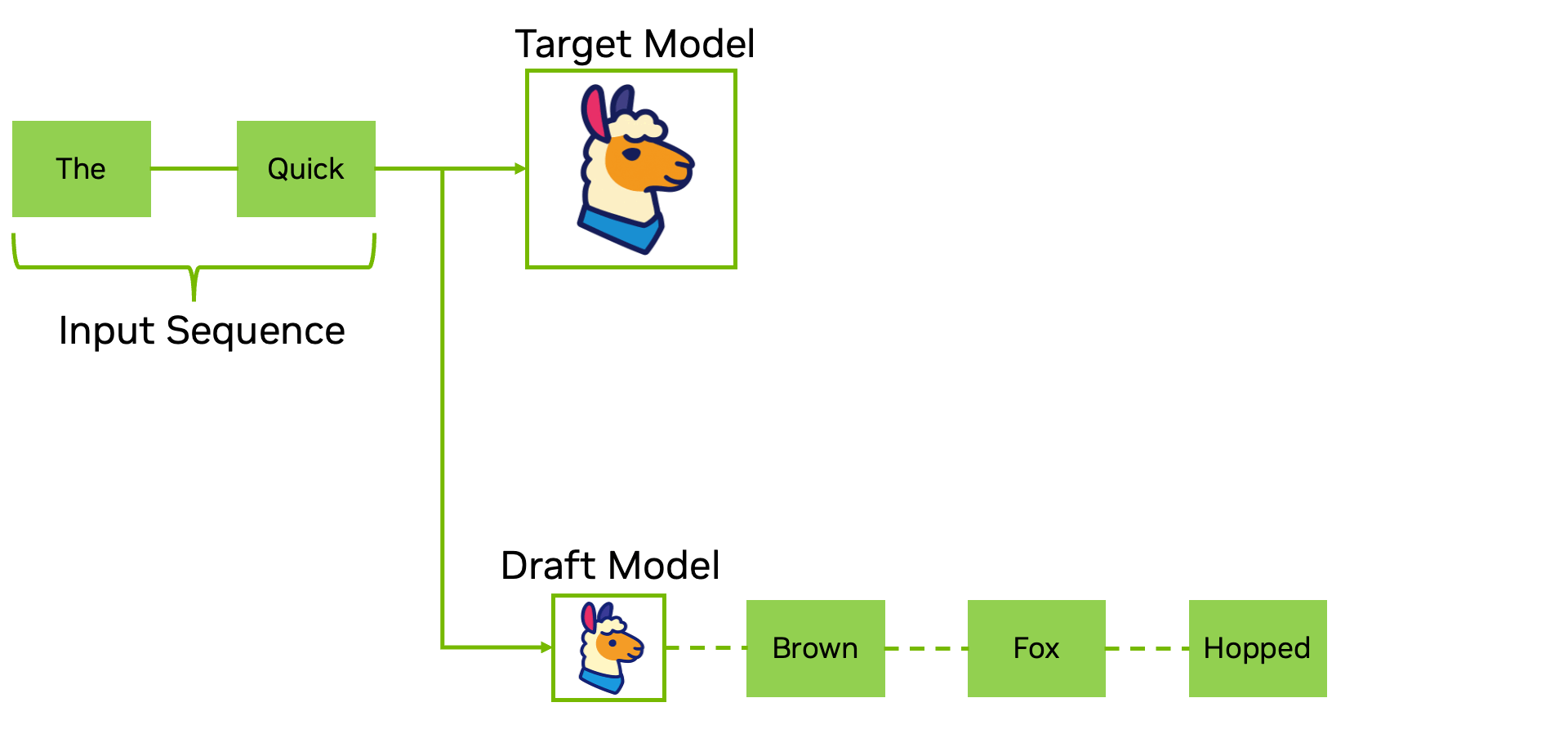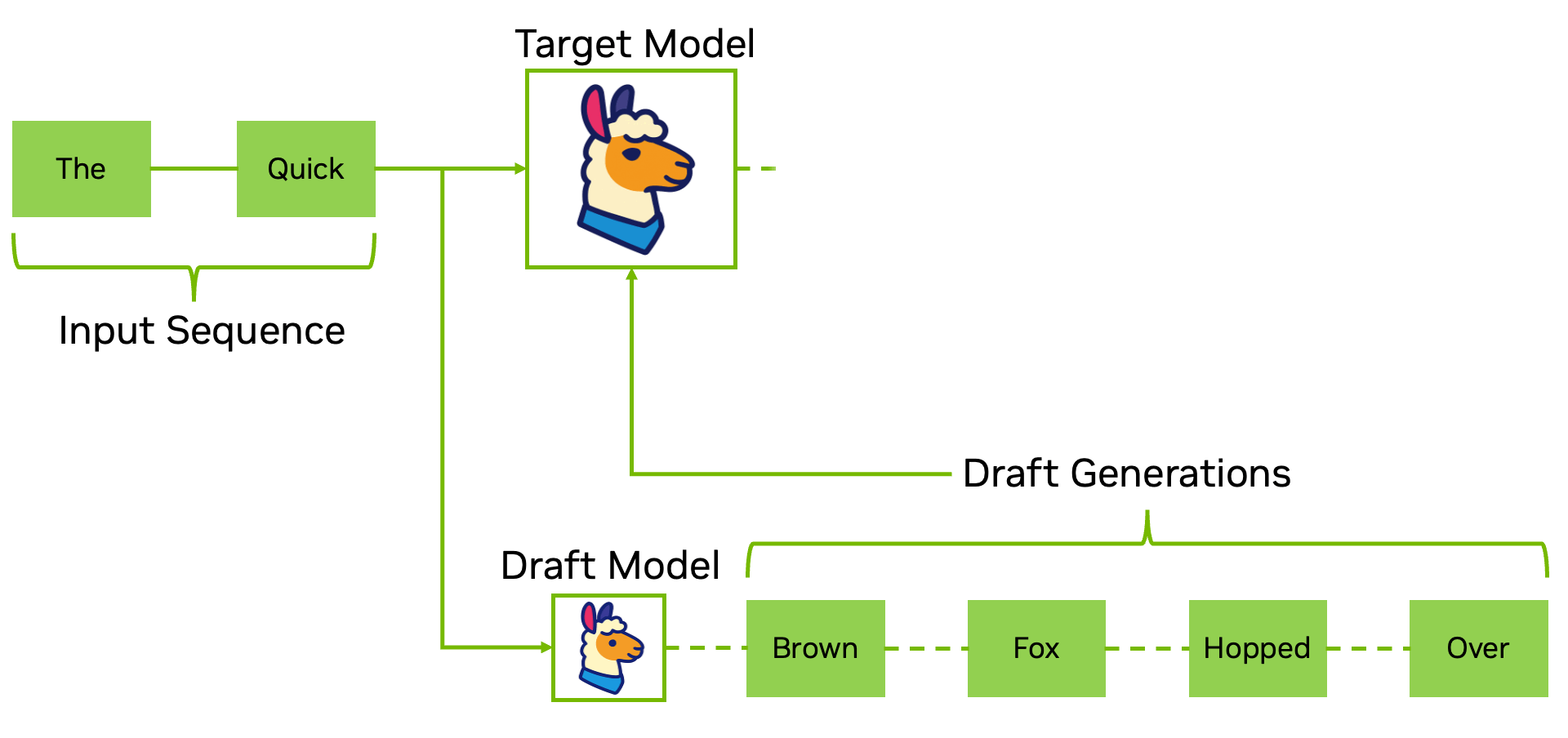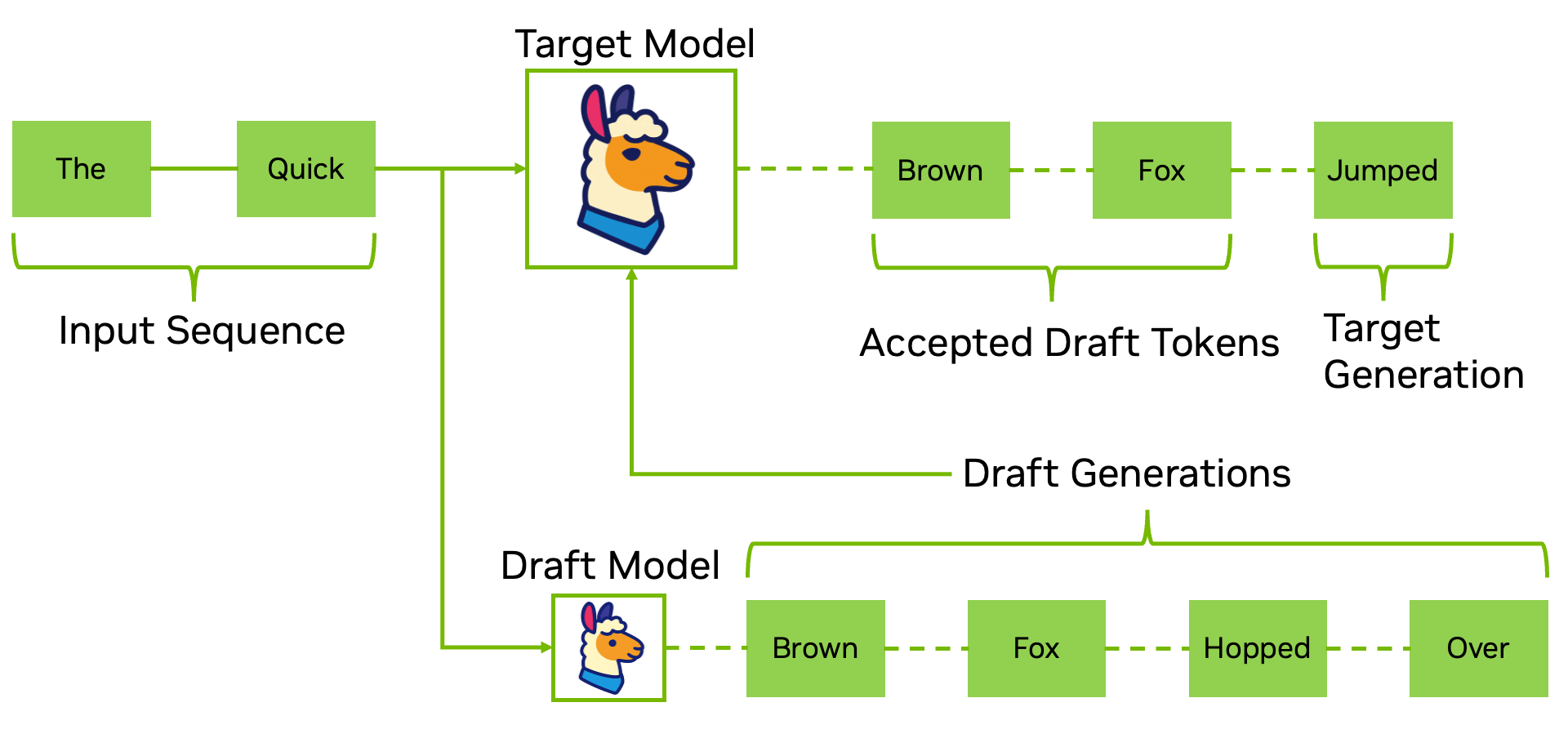
| Ưu điểm | Nhược điểm |
| –Giảm đáng kể độ trễ giải mã –Tương thích hoàn hảo với PTQ/QAT/QAD và NVFP4 |
–Cần điều chỉnh (tỷ lệ chấp nhận là yếu tố quan trọng nhất) –Cần có mô hình hoặc head thứ hai tùy thuộc vào biến thể |
Để tìm hiểu thêm, hãy xem Giới thiệu về Giải mã suy đoán để giảm độ trễ trong suy luận AI .
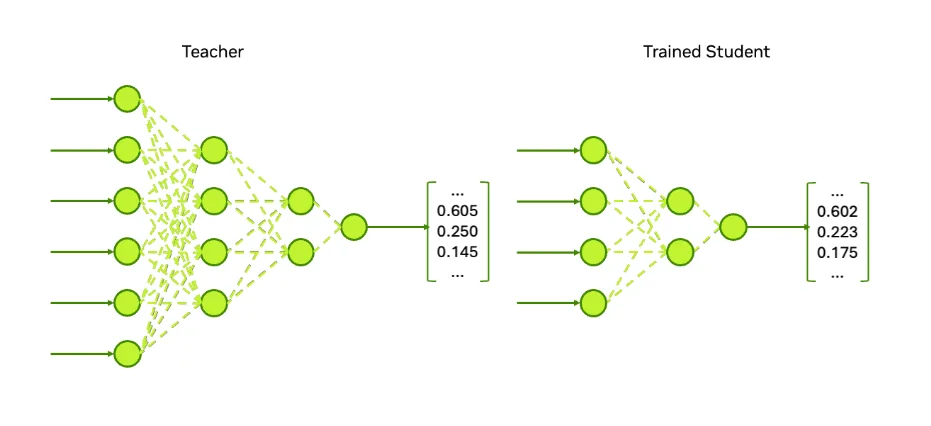
5. Cắt tỉa kết hợp chưng cất tri thức
Cắt tỉa là một con đường tối ưu hóa cấu trúc. Kỹ thuật này loại bỏ các trọng số, lớp và/hoặc đầu để làm cho mô hình nhỏ hơn. Sau đó, quá trình chưng cất sẽ dạy mô hình nhỏ hơn cách suy nghĩ giống như mô hình lớn hơn. Chiến lược tối ưu hóa nhiều bước này thay đổi vĩnh viễn hiệu suất của mô hình vì mức độ tính toán và bộ nhớ cơ bản được giảm xuống vĩnh viễn.
Việc cắt tỉa kết hợp với chưng cất tri thức có thể được tận dụng khi các kỹ thuật khác trong danh sách này không thể mang lại sự tiết kiệm bộ nhớ hoặc tài nguyên tính toán cần thiết để đáp ứng yêu cầu của ứng dụng. Cách tiếp cận này cũng có thể được sử dụng khi các nhóm sẵn sàng thực hiện những thay đổi mạnh mẽ hơn đối với mô hình hiện có để điều chỉnh nó cho các trường hợp sử dụng chuyên biệt cụ thể ở khâu sau.
| Ưu điểm | Nhược điểm |
| – Giảm số lượng tham số → tiết kiệm chi phí lâu dài và về mặt cấu trúc – Cho phép tạo ra các mô hình nhỏ hơn nhưng vẫn hoạt động như các mô hình lớn |
–Cắt tỉa mạnh tay mà không dùng distill → làm giảm độ chính xác đột ngột –Đòi hỏi nhiều công sức hơn để xây dựng pipeline so với chỉ sử dụng PTQ đơn thuần |
Để tìm hiểu thêm, hãy xem bài viết “Cắt tỉa và tinh chế LLM bằng NVIDIA TensorRT Model Optimizer” .
Bắt đầu với tối ưu hóa mô hình AI
Các kỹ thuật tối ưu hóa rất đa dạng và phong phú. Bài viết này sẽ nêu bật năm kỹ thuật tối ưu hóa mô hình hàng đầu được hỗ trợ thông qua Model Optimizer.
- PTQ, QAT, QAD, cùng với việc cắt tỉa và chưng cất giúp mô hình của bạn trở nên rẻ hơn, nhỏ gọn hơn và tiết kiệm bộ nhớ hơn khi vận hành.
- Giải mã suy đoán giúp quá trình tạo ra dữ liệu nhanh hơn bằng cách giảm thiểu độ trễ tuần tự.
Để bắt đầu và tìm hiểu thêm, hãy khám phá các bài viết chuyên sâu liên quan đến từng kỹ thuật để có được giải thích kỹ thuật, thông tin chi tiết về hiệu suất và hướng dẫn sử dụng Jupyter Notebook.