
Các GPU trung tâm dữ liệu hàng đầu của NVIDIA thuộc các dòng NVIDIA Ampere, NVIDIA Hopper và NVIDIA Blackwell đều có các đặc điểm truy cập bộ nhớ không đồng nhất (NUMA), nhưng chỉ hiển thị một không gian bộ nhớ duy nhất. Do đó, hầu hết các chương trình không gặp vấn đề với sự không đồng nhất của bộ nhớ. Tuy nhiên, khi băng thông tăng lên ở các GPU thế hệ mới hơn, sẽ có những cải thiện đáng kể về hiệu năng và điện năng khi xét đến tính cục bộ của tính toán và dữ liệu.
Bài viết này trước tiên phân tích hệ thống phân cấp bộ nhớ của GPU NVIDIA, thảo luận về tác động đến điện năng và hiệu năng của việc truyền dữ liệu qua liên kết giữa các chip. Sau đó, bài viết xem xét cách sử dụng chế độ NVIDIA Multi-Instance GPU (MIG) để đạt được khả năng địa phương hóa dữ liệu. Cuối cùng, bài viết trình bày kết quả khi chạy ở chế độ MIG so với chế độ không địa phương hóa dữ liệu cho trường hợp sử dụng toán tử stencil Wilson-Dslash.
Cấu trúc phân cấp bộ nhớ trong GPU NVIDIA
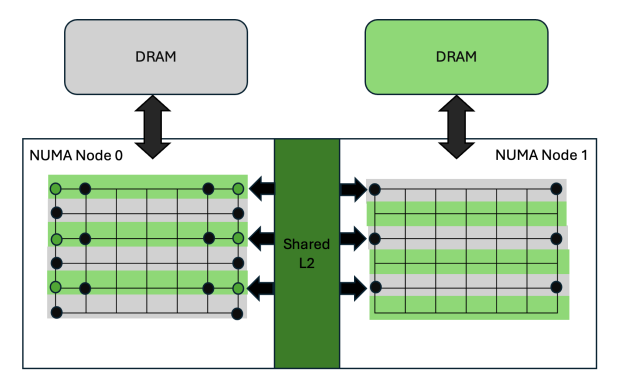
Hãy xem xét hình ảnh trừu tượng về hệ thống phân cấp bộ nhớ với hai node NUMA được mô tả trong Hình 1. Khi một bộ xử lý đa luồng (SM) trên node 0 cần truy cập vào một vị trí bộ nhớ trong bộ nhớ truy cập ngẫu nhiên động (DRAM) của node 1, nó phải truyền dữ liệu qua lớp L2. Trong trường hợp GPU NVIDIA Blackwell, mỗi node NUMA là một chip vật lý riêng biệt, điều này làm tăng độ trễ và tăng công suất cần thiết cho việc truyền dữ liệu. Mặc dù phức tạp hơn, mã không nhận biết NUMA vẫn có thể đạt được băng thông DRAM tối đa.
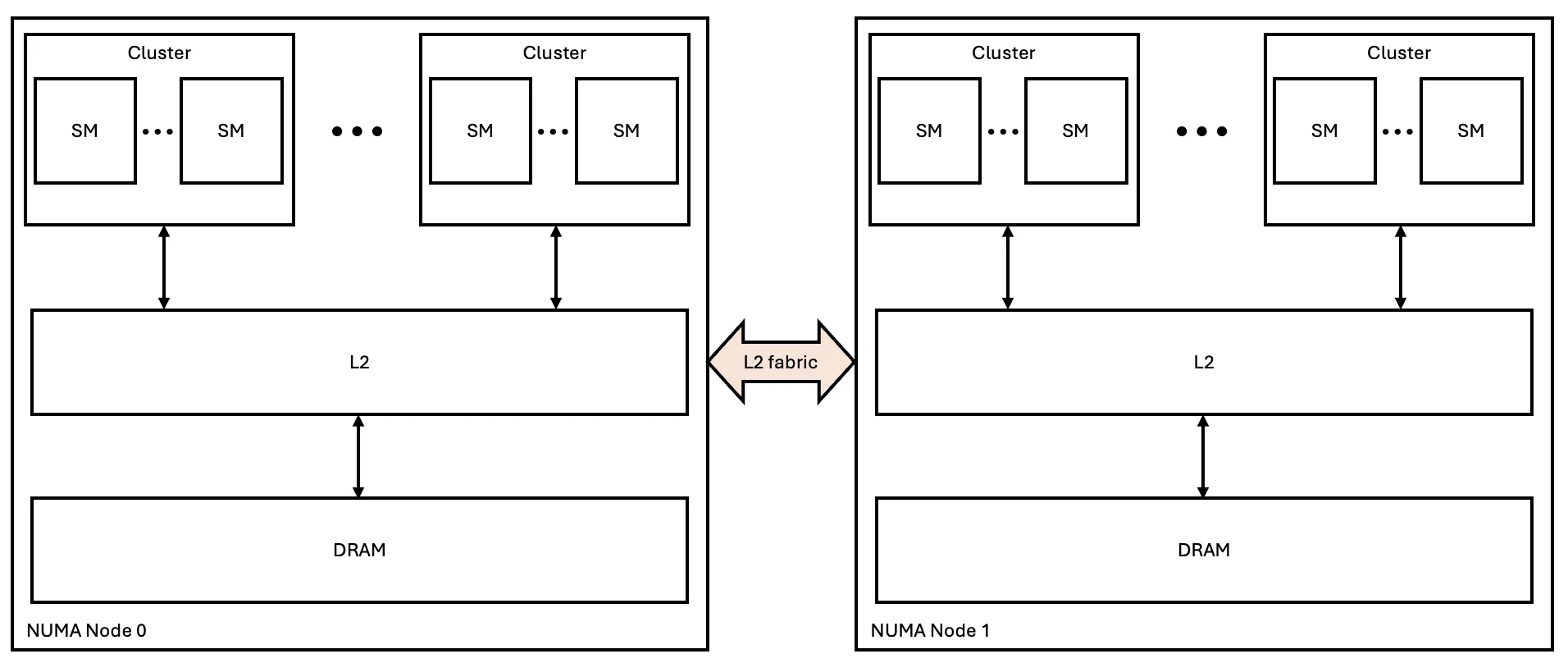
Để khắc phục những nhược điểm này, việc giảm thiểu truyền dữ liệu giữa các node NUMA là rất có lợi. Khi một không gian bộ nhớ duy nhất được cung cấp cho người dùng, kiến trúc NVIDIA sử dụng bộ nhớ đệm nhất quán trong L2 để giảm thiểu việc truyền dữ liệu giữa các node NUMA. Cơ chế này giúp ngăn chặn việc truy cập lặp đi lặp lại vào cùng một địa chỉ bộ nhớ bằng cách tải lại dữ liệu qua giao diện mạng L2. Lý tưởng nhất là, một khi địa chỉ đã được tải vào bộ nhớ đệm L2 cục bộ, tất cả các lần truy cập tiếp theo vào cùng một địa chỉ sẽ truy cập được từ bộ nhớ đệm đó.
Trước khi có sự ra đời của bộ nhớ đệm nhất quán, bộ nhớ đệm L2 thống nhất cho phép tất cả các SM đạt được băng thông tối đa (như trong NVIDIA Volta ), mặc dù độ trễ thay đổi tùy thuộc vào khoảng cách của SM đến các phân đoạn L2 khác nhau. Với thế hệ NVIDIA Ampere, các chip lớn hơn đã giới thiệu một hệ thống phân cấp các node NUMA, mỗi node có bộ nhớ đệm L2 riêng và kết nối nhất quán với các node khác.
Mặc dù các GPU trung tâm dữ liệu lớn từ kiến trúc NVIDIA Ampere trở đi đã sử dụng thiết kế này (không giống như các GPU chơi game nhỏ hơn), kết nối mạng L2 duy trì băng thông tối đa như đã đề cập trong kiến trúc NVIDIA Blackwell Ultra.
Hai thách thức đã xuất hiện khi GPU tiếp tục phát triển: độ trễ tăng và hạn chế về điện năng.
- Độ trễ tăng: Việc truy cập vào các phần xa của bộ nhớ đệm L2 dẫn đến độ trễ ngày càng tăng, ảnh hưởng đến hiệu năng, đặc biệt là đối với việc đồng bộ hóa.
- Giới hạn về điện năng: Trên các GPU lớn nhất, mức tiêu thụ điện năng trở thành yếu tố giới hạn khi các lõi tensor hoạt động. Giảm mức tiêu thụ điện năng thông qua truy cập L2 cục bộ cho phép giảm xung nhịp của bộ nhớ L2 và tăng xung nhịp tính toán thông qua cơ chế Điều chỉnh Điện áp và Tần số Động (DVFS) liên kết với GPU Boost. Bằng cách này, hiệu năng của lõi tensor có thể được cải thiện đáng kể.
MIG giúp giảm thiểu việc truyền dữ liệu giữa các node NUMA. Được giới thiệu cùng với kiến trúc NVIDIA Ampere, tính năng này cho phép phân chia một GPU duy nhất thành nhiều phiên bản. Bằng cách sử dụng MIG, các nhà phát triển có thể tạo một phiên bản GPU cho mỗi node NUMA, từ đó loại bỏ việc truy cập qua giao diện mạng L2.
Phương pháp này cũng đi kèm với một số chi phí riêng, bao gồm chi phí phát sinh khi giao tiếp giữa các phiên bản GPU khác nhau bằng PCIe. Phần tiếp theo trình bày kết quả từ việc chạy các tác vụ sử dụng chế độ MIG và bộ nhớ không cục bộ để chứng minh hiệu quả của phương pháp này.
Địa phương hóa dữ liệu bằng MIG
MIG cho phép phân vùng các GPU NVIDIA được hỗ trợ thành nhiều phiên bản riêng biệt, mỗi phiên bản có bộ nhớ, bộ nhớ đệm và lõi tính toán băng thông cao chuyên dụng. Điều này cho phép sử dụng GPU hiệu quả và hiệu suất cao cho nhiều người dùng hoặc khối lượng công việc. MIG có thể đạt được hiệu suất tài nguyên GPU gấp 7 lần trên một GPU duy nhất. Nó cho phép nhiều GPU ảo (vGPU) và do đó, nhiều máy ảo (VM) chạy song song trên một GPU duy nhất, đồng thời cung cấp các đảm bảo về tính cô lập mà vGPU mang lại.
Các khả năng do MIG cung cấp có thể được tận dụng để đạt được việc địa phương hóa các node NUMA. Bằng cách tạo một phiên bản MIG cho mỗi node NUMA, bạn có thể đảm bảo sự cô lập giữa các phiên bản GPU khác nhau. Cách tiếp cận này giúp loại bỏ lưu lượng truy cập giữa các node NUMA.
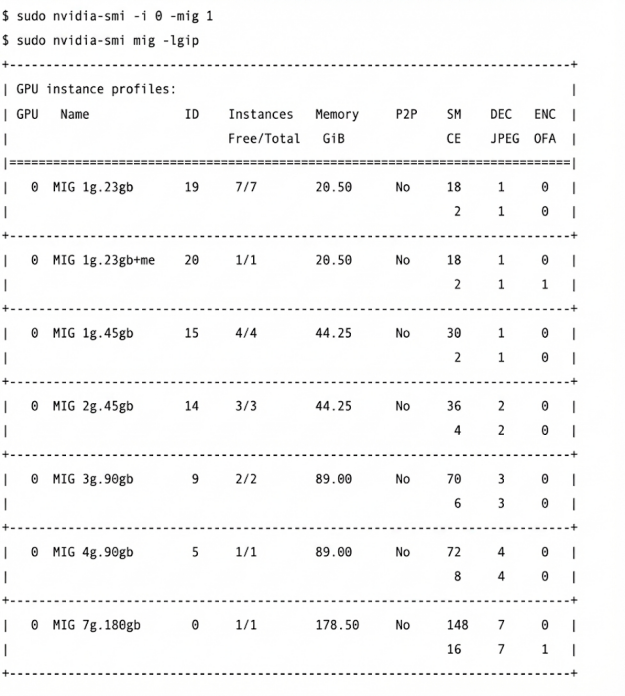
MIG cho phép chia GPU thực tế thành các thể hiện GPU (GI), trong đó một hoặc nhiều thể hiện tính toán (CI) được định nghĩa. Một CI chứa tất cả (trong trường hợp một CI cho mỗi GI) hoặc một phần các SM thuộc về GI. Để cho phép địa phương hóa trong một GI, ý tưởng là tạo ra hai thể hiện GPU được ánh xạ tới mỗi node NUMA. Trên GPU Blackwell, bạn có thể bật chế độ MIG và liệt kê các cấu hình thể hiện GPU có sẵn, như được hiển thị trong đoạn mã ở Hình 2.
Vì Blackwell có hai node NUMA (một node cho mỗi chiplet), hãy tìm cấu hình có nhiều SM nhất mà có hai phiên bản. Như thể hiện trong Hình 2, đó là cấu hình có ID 9, có thể có hai phiên bản. Mỗi phiên bản sẽ có 89 GB và 70 SM. Sử dụng hai phiên bản như vậy sẽ chỉ dẫn đến tổng cộng 70×2=140 SM, thay vì 148 SM đầy đủ trên thiết bị.
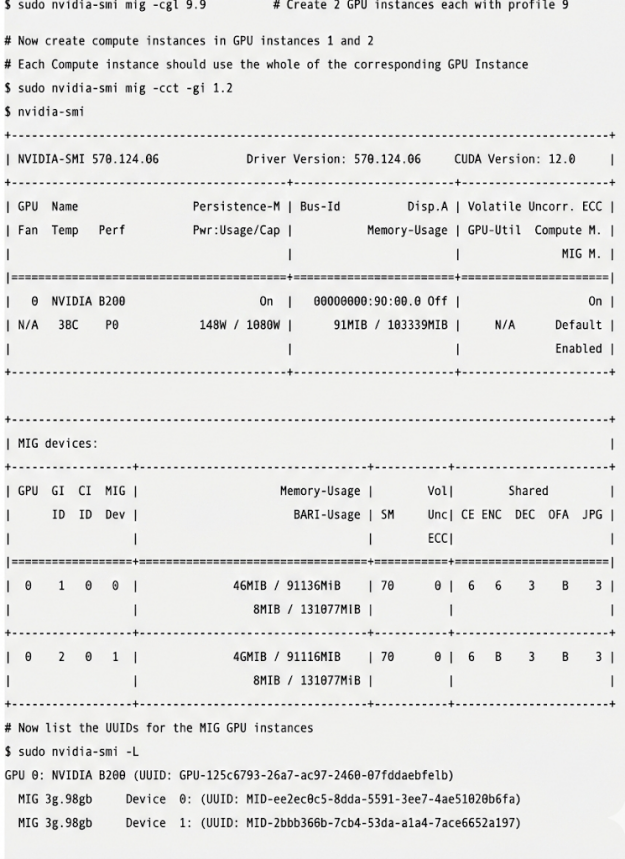
Đến bước này, cần tạo một CI trong mỗi phiên bản GPU. Việc này có thể được thực hiện bằng cách sử dụng các lệnh được hiển thị trong Hình 3. GPU chính và các phiên bản GPU hiện đã có mã băm định danh riêng. Hãy sử dụng các mã này cho hai node NUMA:
MIG 3g.90gb Device 0: (UUID: MIG-ee2ec0e5-0dda-5591-9ee7-4ae51028b6fa) MIG 3g.90gb Device 1: (UUID: MIG-2bbb368b-7cb0-53da-b1a4-7ace0652a197) |
Để sử dụng các thiết bị này, hãy thêm chúng vào CUDA_VISIBLE_DEVICESbiến môi trường. Ví dụ, để chạy một tác vụ MPI hai tiến trình, bạn có thể tạo một tập lệnh bao bọc ( wrapper.sh):
#!/bin/bash#case $SLURM_PROCID in0) CUDA_VISIBLE_DEVICES=”MIG-ee2ec0e5-0dda-5591-9ee7-4ae51028b6fa” ;;1) CUDA_VISIBLE_DEVICES=”MIG-2bbb368b-7cb0-53da-b1a4-7ace0652a197” ;;esac$* |
Sau đó khởi chạy các tác vụ MPI:
$ mpirun -n 2 ./wrapper.sh my_executable |
Cuối cùng, khi mọi công việc đã hoàn tất, chế độ MIG có thể được tắt đi.

Việc sử dụng công nghệ địa phương hóa MIG mang lại những lợi ích gì?
Để minh họa lợi ích của việc địa phương hóa với MIG, hãy xem xét toán tử stencil Wilson-Dslash, một nhân tố quan trọng cho sắc động lực học lượng tử mạng tinh thể (LQCD) được lấy từ thư viện QUDA. Thư viện này được sử dụng để tăng tốc một số mã LQCD lớn, chẳng hạn như Chroma và MILC.
Nhân Dslash là một phép toán sai phân hữu hạn trên lưới hình xuyến 4 chiều, trong đó dữ liệu tại mỗi điểm trên lưới được cập nhật tùy thuộc vào giá trị của tám điểm lân cận trực giao của nó. Bốn chiều trong trường hợp này là các chiều không gian thông thường (X, Y, Z) và chiều thời gian (T). Nhân này bị giới hạn bởi băng thông bộ nhớ.
Nếu mạng lưới được phân chia đều thành hai node NUMA, chẳng hạn dọc theo trục thời gian, thì mỗi miền sẽ cần truy cập các vị trí trên ranh giới chiều T của miền kia. Như thể hiện trong Hình 5, các vị trí mạng lưới màu xanh lá cây trên ranh giới của các miền con cần các vị trí màu đỏ để hoàn thành các khuôn mẫu của chúng. Mạng lưới được bố trí trên hai node NUMA. Các vị trí màu xanh lá cây cần các vị trí màu đỏ để hoàn thành các khuôn mẫu của chúng. Các đường dẫn dữ liệu khả thi là truy cập bộ nhớ thông thường (mũi tên đen) khi không được địa phương hóa, hoặc truyền thông điệp MPI thông qua máy chủ ở chế độ địa phương hóa MIG (mũi tên đen).
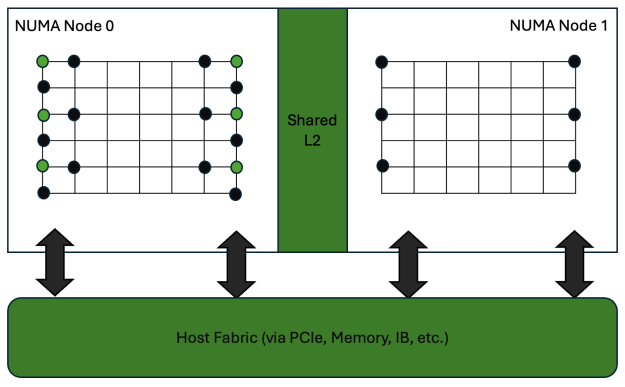
Cách thuận tiện nhất để truy cập các thiết bị lân cận là thông qua bộ nhớ đệm L2 dùng chung và kết nối liên thông. Tuy nhiên, khi hoạt động ở chế độ MIG, đường dẫn này yêu cầu giao tiếp giữa các phiên bản MIG thông qua MPI sử dụng PCIe hoặc NVLink. Do đó, đường dẫn này sẽ chậm hơn so với việc truy cập bộ nhớ chính được gắn với phiên bản MIG.
Các tác vụ yêu cầu ít hoặc không cần giao tiếp giữa hai phiên bản MIG sẽ có xu hướng hưởng lợi nhiều hơn khi sử dụng chế độ MIG. Thay vào đó, một phiên bản sẽ đóng gói các vùng nhớ trống ở ranh giới và gửi chúng qua MPI. Bước này làm tăng thêm độ trễ (đóng gói bộ đệm, gửi và giải nén). Mặc dù tiết kiệm năng lượng GPU bằng cách không sử dụng kết nối liên vùng L2 dùng chung, nhưng nó vẫn tiêu tốn năng lượng cho việc truyền tải qua máy chủ (ví dụ: đối với PCIe).
Lượng dữ liệu cần truyền giữa hai tiến trình có liên quan đến số lượng vị trí mặt phẳng cần truyền trong các thông điệp, cụ thể là đến thể tích ba chiều bề mặt vuông góc với hướng phân tách. Trong ví dụ này, sự phân tách luôn theo hướng T, do đó mỗi node NUMA về mặt lý thuyết sẽ có (N s N t )/2 vị trí, trong đó N s là số vị trí trong thể tích không gian của chúng ta và N t là chiều dài của chiều thời gian. Tỷ lệ diện tích bề mặt trên thể tích là N s /(N s N t /2) = 2/N t . Trong trường hợp của các bài toán, N t = 64 được xem xét và tỷ lệ diện tích bề mặt trên thể tích không đổi ở mức 1/32 ~ 3,13%.
Hình 6 minh họa trường hợp không cục bộ. Bộ nhớ toàn cục được tạo thành từ hai bộ nhớ được kết nối với các node NUMA thông qua bộ điều khiển bộ nhớ. Các vùng được tô màu trên mạng lưới cho thấy dữ liệu có thể đến từ DRAM cục bộ hoặc từ DRAM từ xa thông qua L2 dùng chung.
Điều này cần được so sánh với trường hợp cơ bản, trong đó MIG không được sử dụng. Trong trường hợp này, cả dữ liệu lẫn quá trình xử lý đều không được cục bộ hóa, và kịch bản được thể hiện rõ hơn trong Hình 8. Mỗi node NUMA nhận dữ liệu từ cả bộ điều khiển bộ nhớ cục bộ của nó và từ node NUMA khác. Trên thực tế, chỉ có một mạng lưới toàn cục duy nhất và sự phân chia thành hai phần cho hai node NUMA trong hình là không có ý nghĩa.
Trong kịch bản này, các khối luồng để xử lý một tập hợp các vị trí được gán cho các node NUMA khác nhau hoàn toàn theo ý muốn của bộ lập lịch. Vì dữ liệu được phân phối đều trên hai bộ nhớ NUMA, nên lượng dữ liệu được truyền qua L2 dùng chung nhiều hơn đáng kể so với trường hợp địa phương hóa MIG, nơi chỉ có các vị trí bề mặt cần thiết tối thiểu được truyền đi. Điều này có thể gây ra chi phí năng lượng đáng kể.
Mặt khác, toàn bộ hoạt động có thể được thực hiện chỉ với một nhân xử lý duy nhất. Có thể tránh được độ trễ bằng cách đóng gói các bộ đệm để truyền thông điệp và tích lũy các khuôn mặt nhận được ở cuối.
Đối với kết quả thực nghiệm, hãy xem xét tốc độ tăng hiệu suất thực thi khối lượng công việc với các giới hạn công suất GPU khác nhau tính bằng watt. Tốc độ tăng hiệu suất là tỷ lệ giữa thời gian thực tế (wallclock time) của phương pháp không cục bộ (unlocalized) và phương pháp MIG khi chạy ở cùng giới hạn công suất (ví dụ: cả hai đều ở mức 700 W).
Như thể hiện trong Hình 7, ở giới hạn công suất GPU là 400 W, MIG cho hiệu suất vượt trội hơn so với dữ liệu không được địa phương hóa, với tốc độ tăng lên tới 2,25 lần tùy thuộc vào khối lượng công việc. Lý do là vì công suất tiêu thụ bởi giao diện mạng L2 trở thành yếu tố hạn chế khi GPU hoạt động ở giới hạn công suất thấp. Với chế độ MIG, vì không có công suất mạng L2 nào được tiêu thụ để truyền dữ liệu giữa các node NUMA, nên khối lượng công việc có thể chạy nhanh hơn nhiều.
Tuy nhiên, khi giới hạn công suất GPU được tăng lên, chế độ MIG hoạt động kém hơn một chút trong trường hợp các thí nghiệm được biểu diễn bằng các đường màu xám, xanh đậm và đen trong Hình 9, và một phần của đường màu xanh lá cây. Điều này là do ở giới hạn công suất cao hơn, độ trễ bổ sung do việc truyền thông điệp có thể vượt trội hơn lợi ích của việc địa phương hóa.
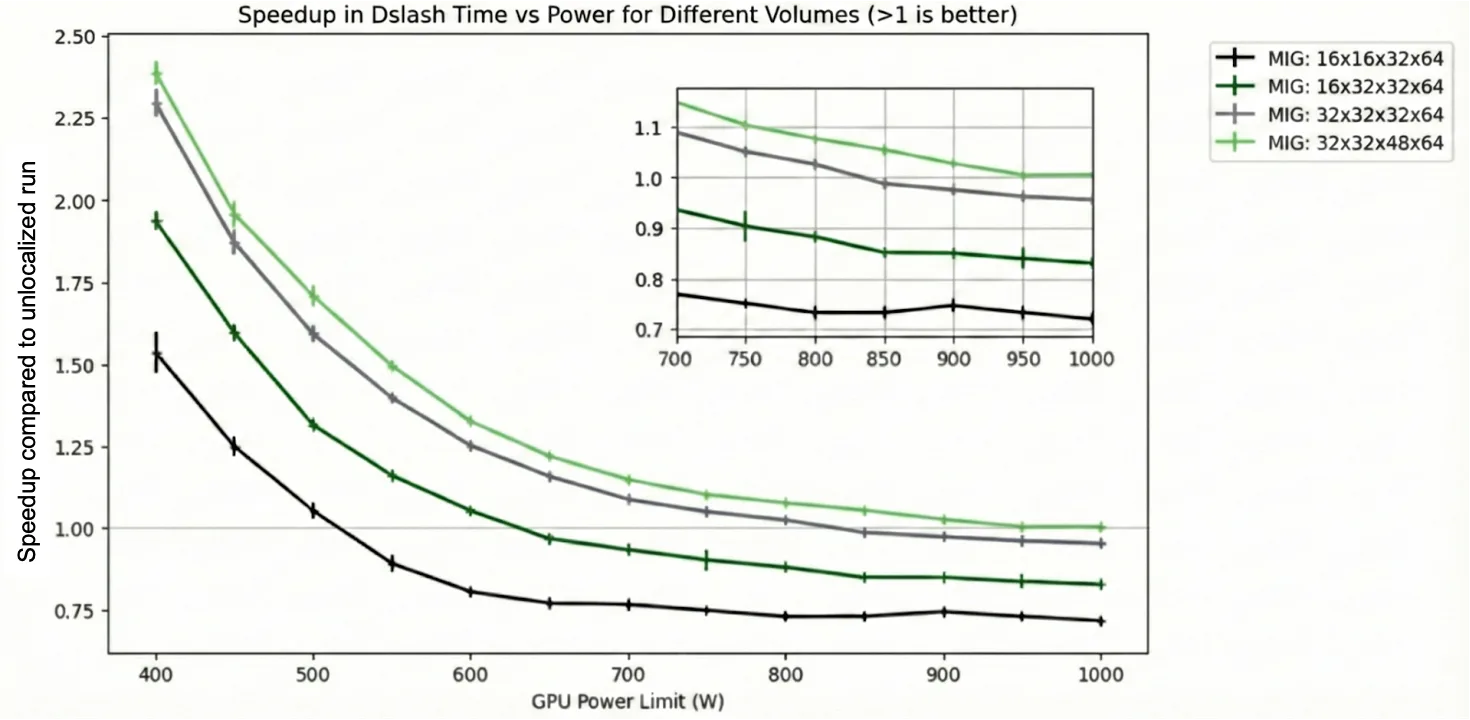
Thực tế cho thấy, các trường hợp nhỏ hơn (đặc biệt là những trường hợp được biểu thị bằng đường màu đen và xanh đậm trong Hình 7) không bao giờ sử dụng hết công suất khả dụng ở giới hạn công suất cao hơn ngay cả trong trường hợp không cục bộ. Do đó, chúng ít được hưởng lợi từ việc tiết kiệm điện năng GPU nhờ cục bộ hóa, và ở các dung lượng nhỏ hơn này, độ trễ do khởi chạy kernel dễ nhận thấy hơn nhiều. Các dung lượng lớn hơn (ví dụ như màu xanh lá cây) yêu cầu nhiều điện năng hơn và do đó có thể đạt được lợi thế so với thiết lập không cục bộ ngay cả ở giới hạn công suất cao hơn.
Bắt đầu với việc địa phương hóa NUMA Node dựa trên MIG
Việc sử dụng bộ nhớ đệm L2 cục bộ trên GPU trung tâm dữ liệu của NVIDIA có thể tác động đến hiệu năng trong các tác vụ không hỗ trợ NUMA. Các thí nghiệm của chúng tôi sử dụng toán tử Wilson-Dslash ở chế độ MIG cho thấy rằng khi GPU hoạt động ở giới hạn công suất thấp hơn và việc truyền dữ liệu qua MPI (PCIe/NVLink) thấp so với việc truy cập bộ nhớ cục bộ, việc thực hiện địa phương hóa NUMA Node dựa trên MIG có thể mang lại tốc độ tăng lên tới 2,25 lần so với trường hợp không được địa phương hóa ở cùng giới hạn công suất.
Mặc dù các hệ thống hoạt động ở mức công suất cao hơn 1.000 W có thể đạt được hiệu suất tuyệt đối cao hơn so với cấu hình 400 W, nhưng việc địa phương hóa dựa trên MIG mang lại những lợi thế rõ ràng trong điều kiện hạn chế công suất. Trong các kịch bản công suất thấp hơn, nó cho phép hiệu suất nhanh hơn đáng kể, khiến nó trở thành một giải pháp tối ưu hóa đặc biệt hiệu quả khi hoạt động trong các giới hạn công suất nghiêm ngặt.
Tuy nhiên, nhìn chung thì MIG không cung cấp tính linh hoạt cần thiết để đạt được hiệu quả địa phương hóa dữ liệu một cách nhất quán, đặc biệt khi chi phí giao tiếp giữa các tiến trình trở nên rõ rệt hơn ở giới hạn công suất cao hơn. MIG chỉ được hỗ trợ cho các trường hợp sử dụng quá nhỏ để phù hợp với GPU. Vì lý do này, nó không được khuyến nghị cho các trường hợp được trình bày trong bài viết này. Để khắc phục những hạn chế này, các phương pháp thay thế đang được nghiên cứu.
NVIDIA Developer Blog
Xem bài gốc