
Vấn đề cold start
Trong các triển khai suy luận ở môi trường production, nhu cầu biến động theo thời gian, đòi hỏi các bản sao suy luận phải mở rộng một cách co giãn. Tuy nhiên, việc cold-start các khối lượng công việc suy luận trên Kubernetes có thể mất vài phút. Trong thời gian đó, GPU đã được cấp phát nhưng ở trạng thái nhàn rỗi, không tạo ra token nào và không phục vụ yêu cầu nào.
Độ trễ này làm tăng nguy cơ vi phạm thỏa thuận mức dịch vụ (SLA) trong các đợt tăng vọt lưu lượng, vì hệ thống không thể mở rộng đủ nhanh để hấp thụ những mức tăng nhu cầu đột ngột.
Đối với một workload vLLM (v0.20.0) dùng một GPU, độ trễ cold-start được phân tách như sau:
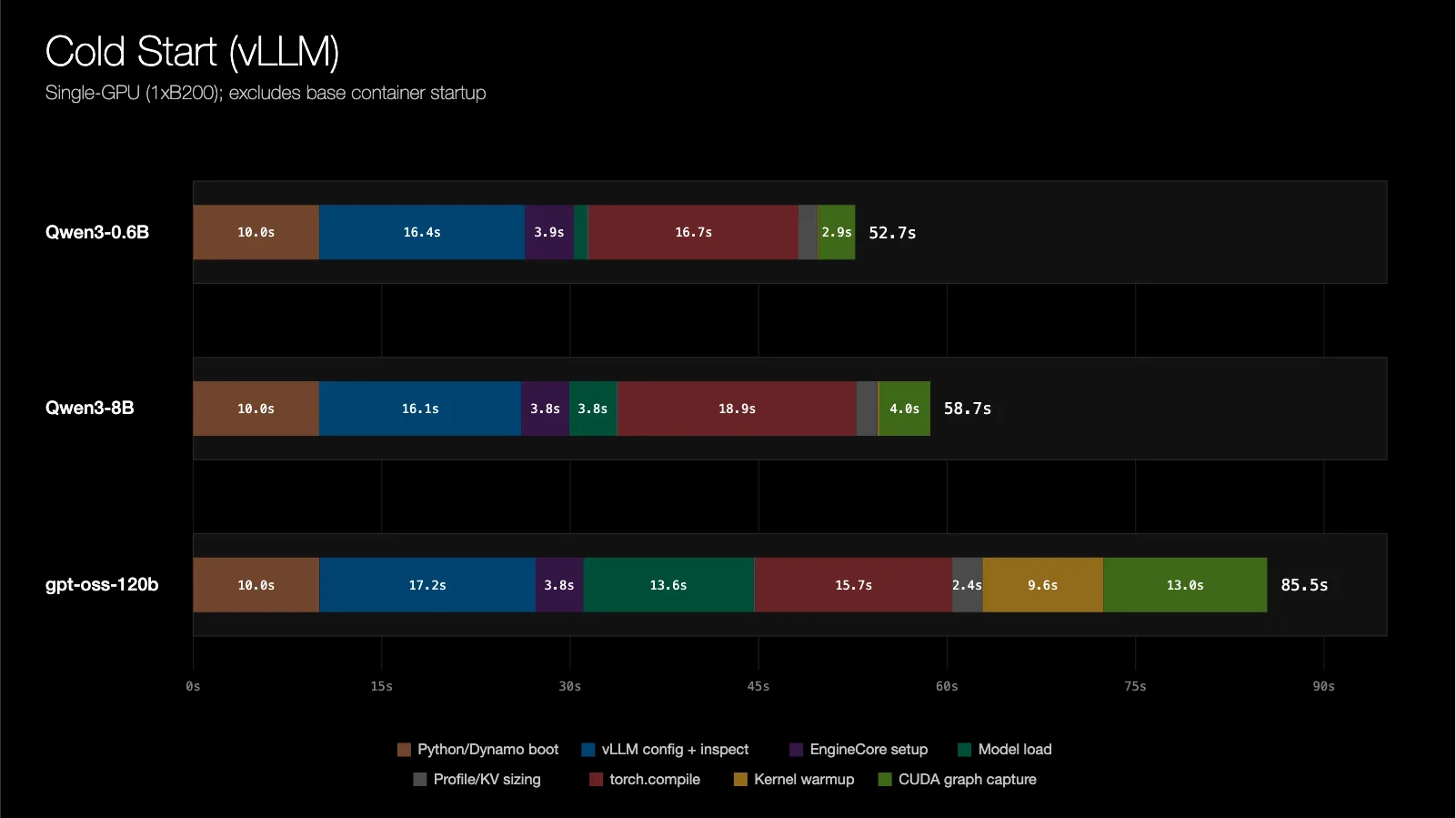
Hình 1. Phân rã độ trễ khởi động lạnh cho một inference worker dùng một GPU
Để giảm đáng kể thời gian khởi động, chúng tôi giới thiệu NVIDIA Dynamo Snapshot, phương pháp checkpoint/restore của chúng tôi dành cho các workload suy luận AI trên Kubernetes. Trong bài viết này, chúng tôi mô tả các lựa chọn thiết kế và tối ưu hóa đằng sau nguyên mẫu ban đầu, đạt được thời gian khởi động gần với tốc độ ánh sáng cho các workload dùng một GPU.
Đây là bài viết đầu tiên trong loạt bài về khởi động nhanh trong Dynamo.
CRIU và cuda-checkpoint
Trạng thái có thể checkpoint của một inference worker đang chạy gồm hai thành phần:
- Trạng thái thiết bị (phía GPU): CUDA contexts, streams, device memory, ánh xạ địa chỉ ảo, v.v. Trạng thái này không hiển thị với host. Để tuần tự hóa trạng thái này, chúng tôi sử dụng khả năng checkpoint của CUDA driver (cũng được cung cấp qua công cụ dòng lệnh cuda-checkpoint) để dump trạng thái thiết bị vào bộ nhớ CPU của tiến trình sở hữu từng CUDA context.
- Trạng thái host (phía CPU): bộ nhớ CPU, threads, file descriptors, namespaces, v.v. Linux kernel có toàn bộ thông tin bookkeeping cần thiết để có thể tuần tự hóa trạng thái này. Chúng tôi sử dụng một công cụ mã nguồn mở, CRIU (Checkpoint/Restore in Userspace), để duyệt qua phần bookkeeping của Linux kernel và tuần tự hóa trạng thái của cây tiến trình xuống đĩa.
Hai công cụ này kết hợp với nhau một cách gọn gàng để cho phép checkpoint/restore toàn bộ trạng thái của inference worker. Khi checkpoint:
- cuda-checkpoint dump toàn bộ trạng thái thiết bị vào bộ nhớ CPU.
- CRIU dump toàn bộ trạng thái cây tiến trình phía host vào một thư mục trong bộ lưu trữ.
Khi khôi phục (trên cùng node hoặc node khác):
- CRIU khôi phục cây tiến trình theo trạng thái đã được tuần tự hóa từ bộ lưu trữ phân tán như NFS/SMB, cho phép chúng ta lấy artifact đã được checkpoint từ một node khác.
- cuda-checkpoint khôi phục trạng thái GPU từ những gì đã được tuần tự hóa trong bộ nhớ CPU lên các GPU mới.
Về cơ bản, CRIU là một cơ chế đóng băng và rã đông. Khi một tiến trình được khôi phục, quá trình thực thi tiếp tục tại đúng chỉ lệnh nơi nó đã được checkpoint, hoàn toàn không biết rằng việc checkpoint hoặc khôi phục đã diễn ra.
Vì vậy, mọi điều phối cần thiết trước khi checkpoint, chẳng hạn như đưa workload về trạng thái tĩnh, hoặc sau khi khôi phục, chẳng hạn như thiết lập lại trạng thái bên ngoài, đều phải được xử lý từ bên ngoài thông qua một orchestrator hoặc các hook dành riêng cho workload. Chúng tôi mô tả các cơ chế này trong các phần tiếp theo.
Dynamo Snapshot: Kubernetes
Trong Kubernetes, các khối lượng công việc chạy bên trong container trong các pod. Vì checkpoint của CRIU chứa các tham chiếu đến lớp hệ thống tệp có thể ghi của container, chúng tôi checkpoint ở cấp container để trạng thái cây tiến trình và hệ thống tệp đi cùng nhau.
Chúng tôi cung cấp một DaemonSet đặc quyền, snapshot-agent, có thể cài đặt thông qua Helm chart. Một agent chạy trên mọi node và xử lý checkpoint cũng như khôi phục cho các container do runc quản lý mà không cần sửa đổi chính runc.
Khi checkpoint, agent chờ readiness probe của khối lượng công việc, sau đó gọi cuda-checkpoint và CRIU từ phía host trước khi ghi artifact vào bộ nhớ dùng chung. Khối lượng công việc có thể đã tạo/xóa các tệp cục bộ trong container (tức là hệ thống tệp overlay), và agent cũng checkpoint phần này sau giai đoạn CRIU.
Khi khôi phục, agent khởi chạy một pod placeholder nhẹ, khôi phục overlay filesystem, rồi khôi phục checkpoint CRIU/CUDA vào các namespace của nó. Worker đã được khôi phục sau đó tiếp quản việc thực thi.
Mỗi agent hoạt động độc lập trên node cục bộ của nó, cho phép checkpoint và khôi phục được song song hóa một cách tự nhiên trên toàn cluster. Chúng tôi xây dựng cơ chế này thay vì dựa vào hỗ trợ checkpoint/restore native của Kubernetes trong runc, vốn cũng ủy quyền cho CRIU. Cách tiếp cận DaemonSet hoàn toàn portable và không phụ thuộc vào hỗ trợ của cloud provider đối với các feature gate checkpoint/restore.
Điều này cũng cho chúng tôi quyền kiểm soát CRIU chặt chẽ hơn để tinh chỉnh hiệu năng và cho phép các artifact checkpoint nằm trong các backend lưu trữ linh hoạt thay vì được nhúng vào image OCI.
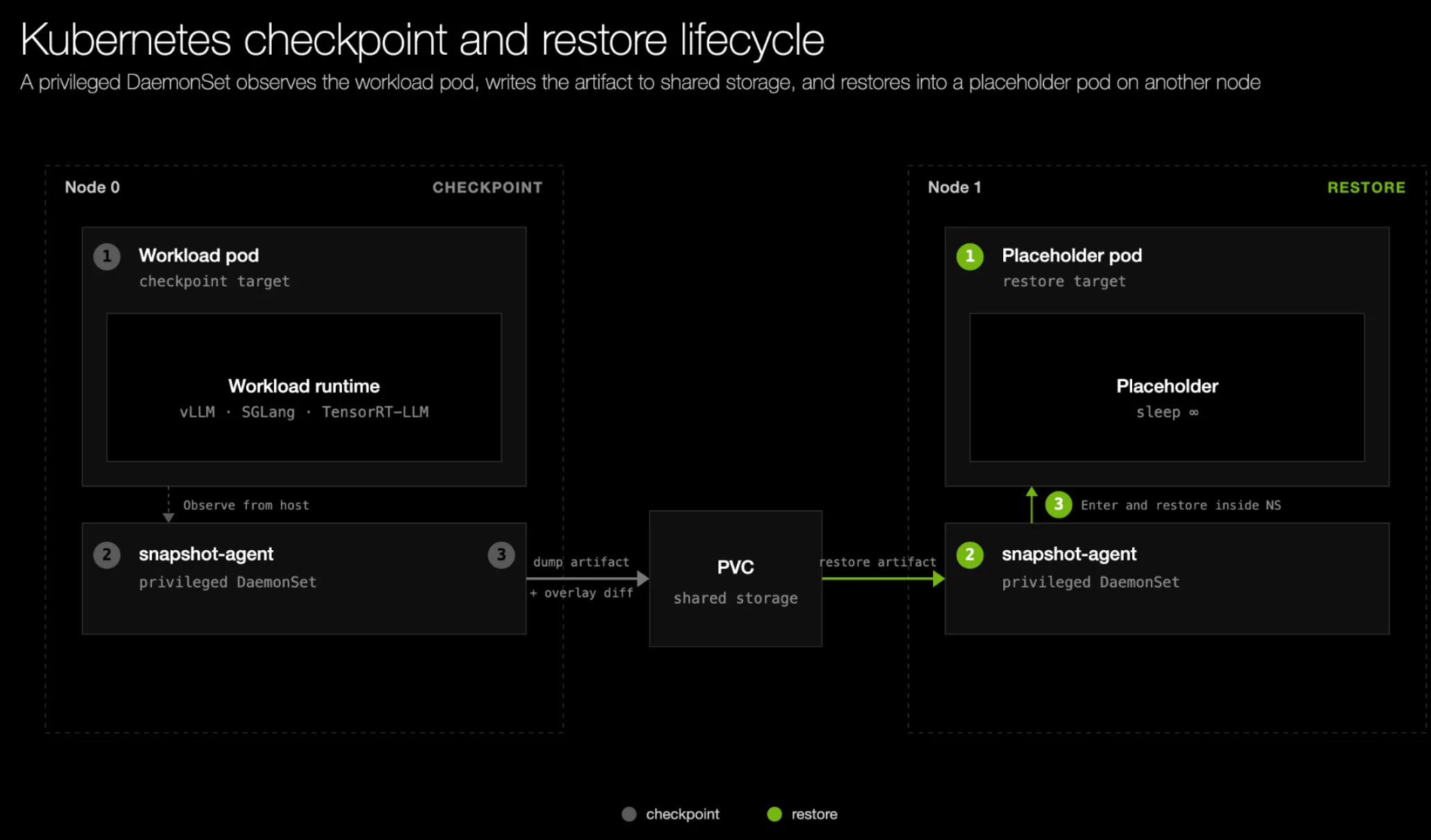
Hình 2. Vòng đời checkpoint và khôi phục của Kubernetes với Dynamo Snapshot
Dynamo Snapshot: Workload
Một inference worker của Dynamo khởi chạy qua hai giai đoạn:
- Khởi tạo engine: Inference engine đã được cấu hình được khởi động: các communicator được khởi tạo, weights được tải, kernels được làm nóng, graphs được biên dịch/ghi lại, v.v. Đến cuối giai đoạn này, worker đã được làm nóng hoàn toàn. Nó có thể phục vụ một request, nhưng chưa thể được phát hiện bởi bất kỳ thứ gì bên ngoài pod của chính nó.
- Khởi động distributed runtime: Worker kết nối với control plane của Dynamo và đăng ký chính nó với discovery backend, để router và phần còn lại của graph có thể tìm thấy nó. Từ thời điểm này trở đi, worker ở trạng thái “live” — có các kết nối mở tới control plane, và các thành phần khác trong cluster biết được danh tính pod của worker này.
Nếu triển khai checkpoint/restore một cách ngây thơ, khi workload không biết rằng nó đang được checkpoint, readiness probe của checkpoint job sẽ tương ứng với một distributed runtime đã được khởi tạo đầy đủ và đã đăng ký với discovery plane, nghĩa là có các kết nối TCP đang hoạt động mà CRIU không thể ghi lại.
Mẫu tổng quát để giải quyết vấn đề này là các hook quiesce/resume: workload đảm bảo nó đang ở trạng thái tĩnh lặng và chặn trên một tín hiệu bên ngoài được kích hoạt khi quá trình restore hoàn tất. Đây là một abstraction mạnh mẽ cho checkpoint/restore vì:
- Nó cho phép workload dọn dẹp tài nguyên của mình trước khi được checkpoint, nhờ đó tối ưu hóa kích thước checkpoint cuối cùng (và do đó giảm thời gian restore).
- Nó cho phép workload tạo lại các tài nguyên không thể checkpoint sau khi resume. Điều này đặc biệt quan trọng đối với checkpoint đa GPU và đa node (được lên kế hoạch cho một bản phát hành trong tương lai): các kết nối TCP outbound dùng cho RPC không thể được checkpoint ở trạng thái đã thiết lập vì pod IP thay đổi giữa thời điểm checkpoint và restore, đồng thời các đăng ký RDMA và trạng thái NIC cũng cần được tạo lại sau khi restore.
Trong Dynamo Snapshot, chúng tôi triển khai các hook này bằng cách định nghĩa readiness probe là sự hiện diện của một file tín hiệu “ready for checkpoint”. Worker ghi file này sau khi engine khởi tạo nhưng trước khi khởi động distributed runtime.
Tại thời điểm đó, worker đi vào một vòng lặp polling để chờ một file tín hiệu “restore complete” riêng biệt, trong khi snapshot agent checkpoint nó từ bên ngoài. Checkpoint có thể diễn ra tại bất kỳ instruction nào bên trong vòng lặp polling đó.
Vì CRIU khôi phục quá trình thực thi đúng tại instruction nơi việc checkpoint đã diễn ra, worker resume trực tiếp bên trong vòng lặp polling, phát hiện file tín hiệu và tiếp tục khởi tạo distributed runtime mà không cần đồng bộ hóa bổ sung.
Tối ưu hóa #1: Unmap và release KV cache
Một tối ưu hóa để giảm kích thước checkpoint là giải phóng bộ nhớ KV cache trước khi checkpoint. Sau khi đo mức sử dụng bộ nhớ GPU đỉnh trong lúc weights, CUDA graphs và các buffer/activation khác được cấp phát, các inference engine sẽ cấp phát phần bộ nhớ GPU còn lại làm một buffer KV cache lớn.
Tuy nhiên, vì checkpoint của chúng tôi được tạo ở trạng thái tĩnh trước khi replica phục vụ bất kỳ request nào, buffer KV cache này hoàn toàn không cần được checkpoint. Nhưng chúng tôi cần giữ địa chỉ ảo của KV cache này ổn định vì nó đã được nhúng vào CUDA graph. Điều này có nghĩa là chúng tôi cấp phát buffer KV cache thông qua CUDA Virtual Memory Management API ( cuMemCreate và cuMemMap); sau đó, việc giải phóng cấp phát vật lý bên dưới trong khi vẫn giữ địa chỉ ảo ổn định chỉ đơn giản là gọi cuMemUnmap và cuMemRelease , nhưng không gọi cuMemAddressFree . May mắn là chức năng này đã có sẵn nguyên bản trong vLLM (thông qua sleep() và wake_up() ) và SGLang (thông qua torch_memory_saver ).
Việc unmap và release KV cache giúp giảm tổng kích thước artifact của Qwen3-0.6B trên B200 từ khoảng ~190 GiB xuống còn ~6 GiB. Mức cải thiện rõ rệt nhất khi kích thước KV cache lớn (tức là weights của model nhỏ hơn tương đối so với dung lượng GPU).
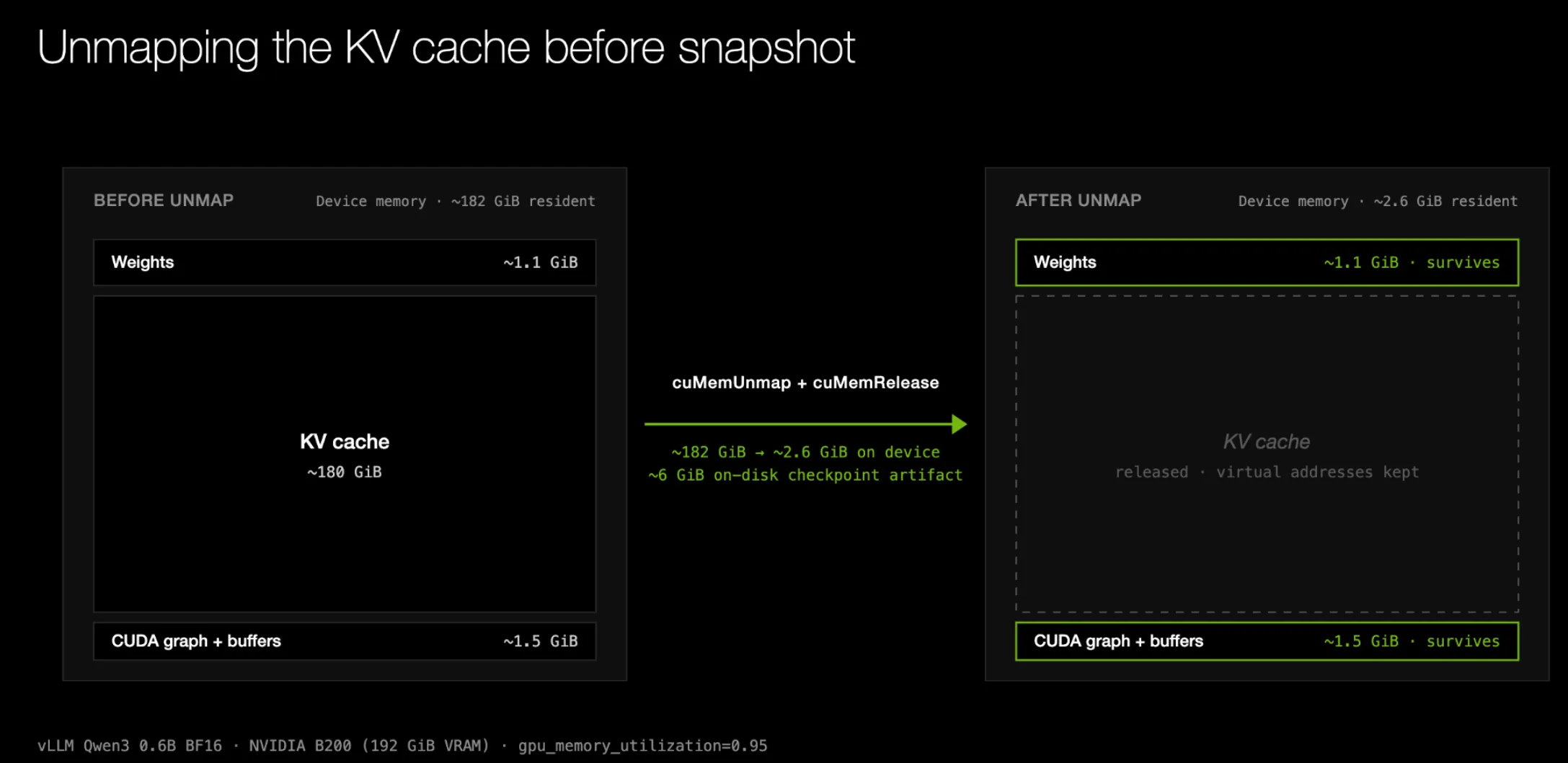
Hình 3. Việc unmap và giải phóng KV cache giúp giảm kích thước checkpoint
Tối ưu hóa #2: Tăng tốc CRIU
Tại thời điểm này, thời gian khôi phục vẫn còn xa mới đạt mức chấp nhận được. Và với các mô hình lớn hơn, thời gian khôi phục thực tế còn vượt quá thời gian khởi động nguội, làm mất đi toàn bộ mục đích của checkpoint/restore.
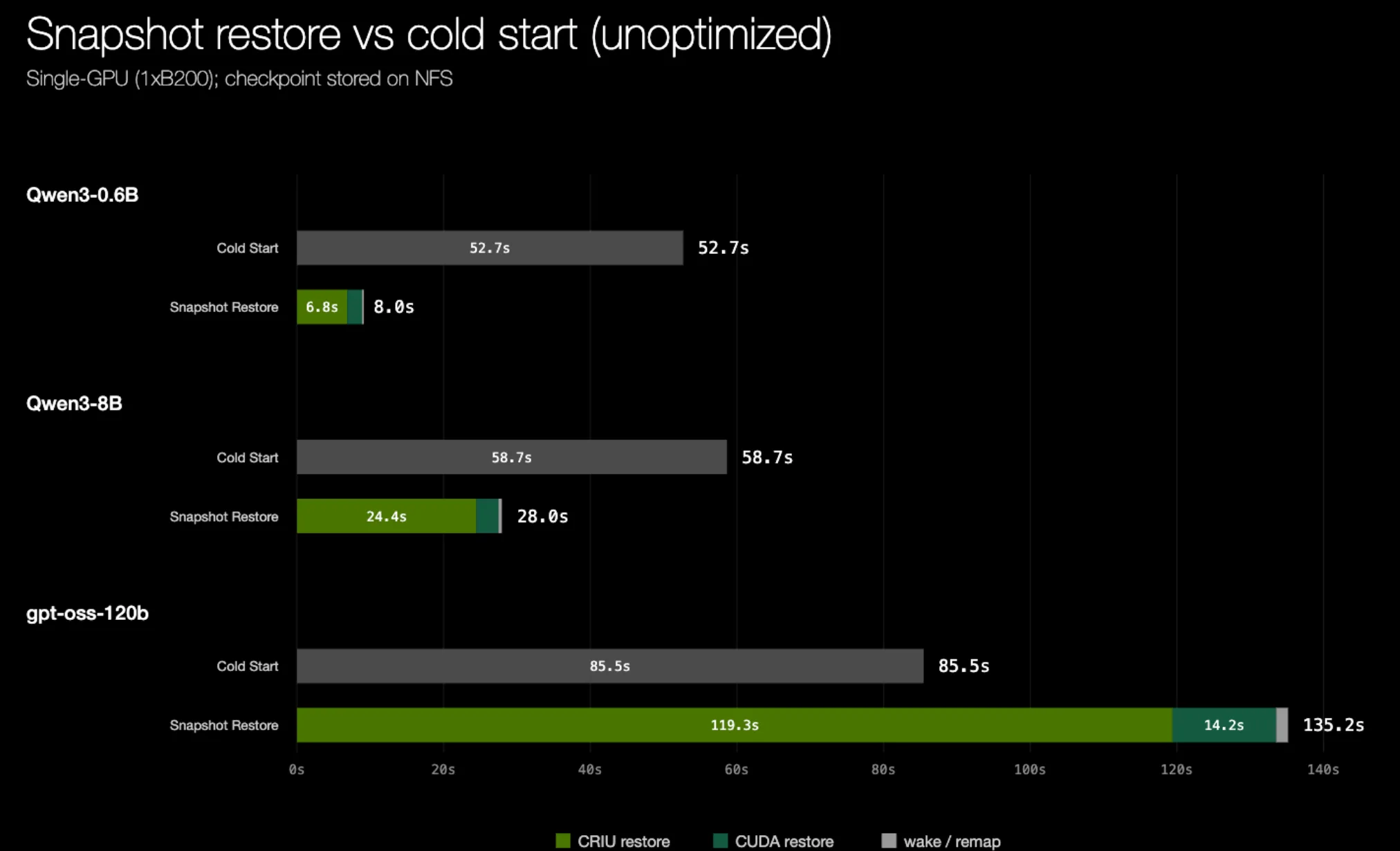
Hình 4. Thời gian khôi phục với CRIU upstream vượt quá thời gian khởi động lạnh
Lý do chính là CRIU và cuda-checkpoint không sao chép bộ nhớ ở tốc độ speed-of-light (SOL). Trong một tiến trình Linux, có hai loại bộ nhớ: bộ nhớ ẩn danh (heap, stack, v.v. của một tiến trình) và bộ nhớ chia sẻ (được chia sẻ giữa các tiến trình). CRIU chịu trách nhiệm khôi phục cả hai loại bộ nhớ, và cả hai đều trở thành nút thắt đáng kể đối với các mô hình lớn. Trong phần này, chúng tôi phác thảo các tối ưu hóa cho CRIU mà chúng tôi đã phát triển nhằm tăng tốc đáng kể việc khôi phục bộ nhớ tiến trình.
Lưu ý: Các tối ưu hóa CRIU này chưa được phát hành như một phần của Dynamo Snapshot, và sẽ có sẵn sau khi chúng được merge vào upstream CRIU.
Lưu ý #2: Overlay filesystem cho các workload được benchmark của chúng tôi rất nhỏ (<100 MiB) và không đáng kể trong thời gian khôi phục, nên được bỏ qua.
Tối ưu hóa #2.1: Khôi phục memfd song song
Đường dẫn sleep() / wake_up() của vLLM và torch_memory_saver của SGLang (mà chúng tôi gọi trong các hook quiesce/resume) di chuyển các cấp phát GPU được gắn thẻ weight vào các buffer shadow CPU được pinned. Đây là thực hành phổ biến cho các bản sao bộ nhớ host-to-device/device-to-host (H2D/D2H) băng thông cao. CUDA hỗ trợ các cấp phát này bằng shared anonymous memory, sau đó được pinned thông qua driver NVIDIA. Bên trong Linux kernel, chúng xuất hiện dưới dạng memfd: các file ẩn danh, được RAM hỗ trợ, có thể được ánh xạ với MAP_SHARED .
Đối với gpt-oss-120b , các buffer này tiêu thụ hơn 120 GiB, được chia thành nhiều buffer độc lập có kích thước 2 GiB hoặc nhỏ hơn. Upstream CRIU khôi phục các buffer đó theo tuần tự: nó tạo một object được shmem hỗ trợ, thay đổi kích thước object đó, ánh xạ object, đọc nội dung của object từ checkpoint image, và chỉ sau đó mới chuyển sang object tiếp theo.
Chúng tôi đã sửa đổi CRIU để trước tiên liệt kê tất cả các đối tượng duy nhất được backing bởi shmem, sau đó khởi chạy một thread pool để khôi phục chúng song song. Mỗi worker cấp phát buffer riêng và đọc từ checkpoint một cách độc lập, cho phép quá trình restore sử dụng băng thông lưu trữ sẵn có và khả năng song song của CPU thay vì xử lý từng buffer một.
Tối ưu hóa #2.2: Linux native AIO cho bộ nhớ anonymous
Sau khi CRIU đã khôi phục các tài nguyên dùng chung (files, sockets, đối tượng shmem, memfds, v.v.), nó vẫn phải điền lại bộ nhớ private của từng process: heap pages, stacks, anonymous mappings và copy-on-write private file mappings. Các page này không được chia sẻ; chúng thuộc về một process và cần được đặt đúng tại các địa chỉ ảo mà chúng đã có trước khi checkpoint.
Trong upstream CRIU, đường điền dữ liệu đó là một vòng lặp preadv đồng bộ. Restorer lấy một job từ danh sách, chuyển nó cho preadv, rồi chờ. Kernel phát lệnh đọc đơn lẻ đó tới thiết bị lưu trữ, thiết bị DMA các byte vào các page VMA đích, và preadv trả về. Chỉ khi đó restorer mới chuyển sang job tiếp theo. Tại bất kỳ thời điểm nào cũng chỉ có đúng một lệnh đọc đang diễn ra, khiến thiết bị lưu trữ bị nhàn rỗi giữa các request. Một luồng blocking đơn lẻ không thể bão hòa băng thông NVMe tốc độ cao, và trên storage gắn qua mạng, mỗi lần đọc cũng phải trả giá bằng một round trip trước khi lần đọc tiếp theo có thể bắt đầu.
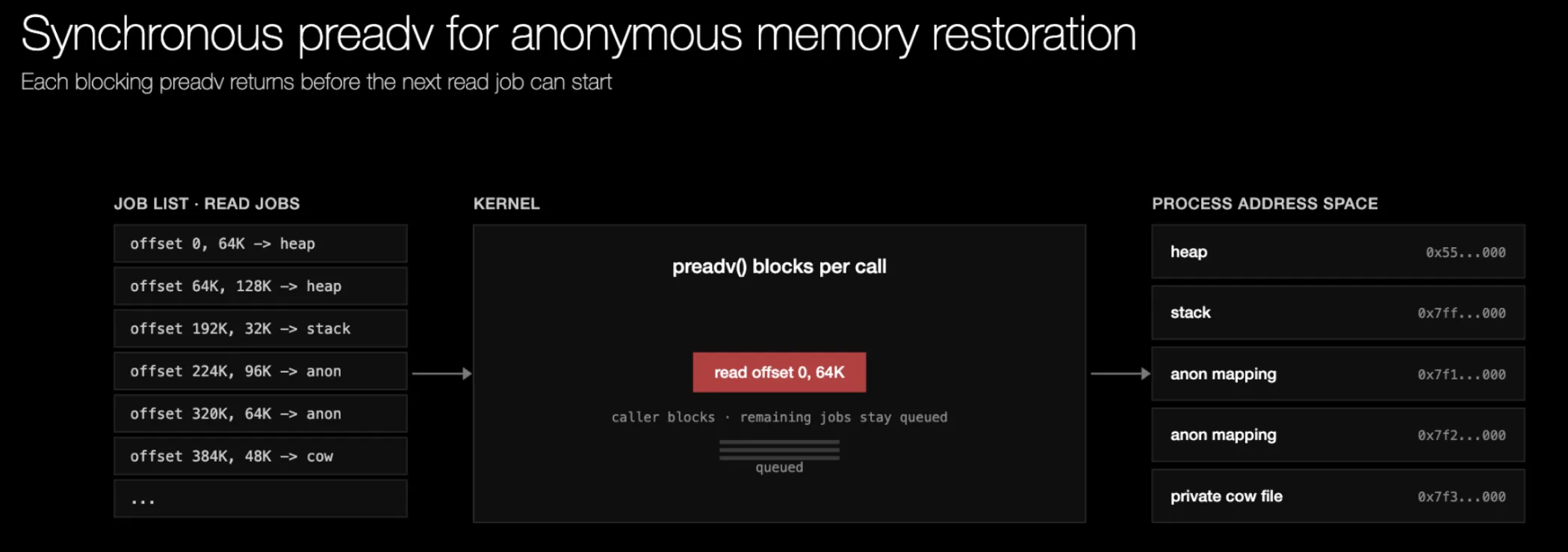
Hình 5. Khôi phục bộ nhớ bằng preadv tuần tự (mỗi lần chỉ có một thao tác đọc đang thực thi)
Chúng tôi đã thay thế vòng lặp preadv bằng Linux native AIO. CRIU xây dựng trước một danh sách các tác vụ đọc. Mỗi tác vụ là một iocb mô tả offset trong tệp, số byte và một iovec trỏ đến các trang VMA đích. Restorer tạo một AIO context, có thể giữ đồng thời nhiều giao dịch đọc riêng biệt, cho phép thiết bị lưu trữ chạy chúng song song trên các kênh nội bộ của nó. Restorer tạo một AIO context, gửi một lô iocb bằng io_submit, và duy trì một cửa sổ tối đa 128 thao tác đọc đang thực thi. Khi các hoàn tất được trả về qua io_getevents, các lần gửi mới sẽ lấp đầy lại cửa sổ cho đến khi mọi tác vụ hoàn tất.
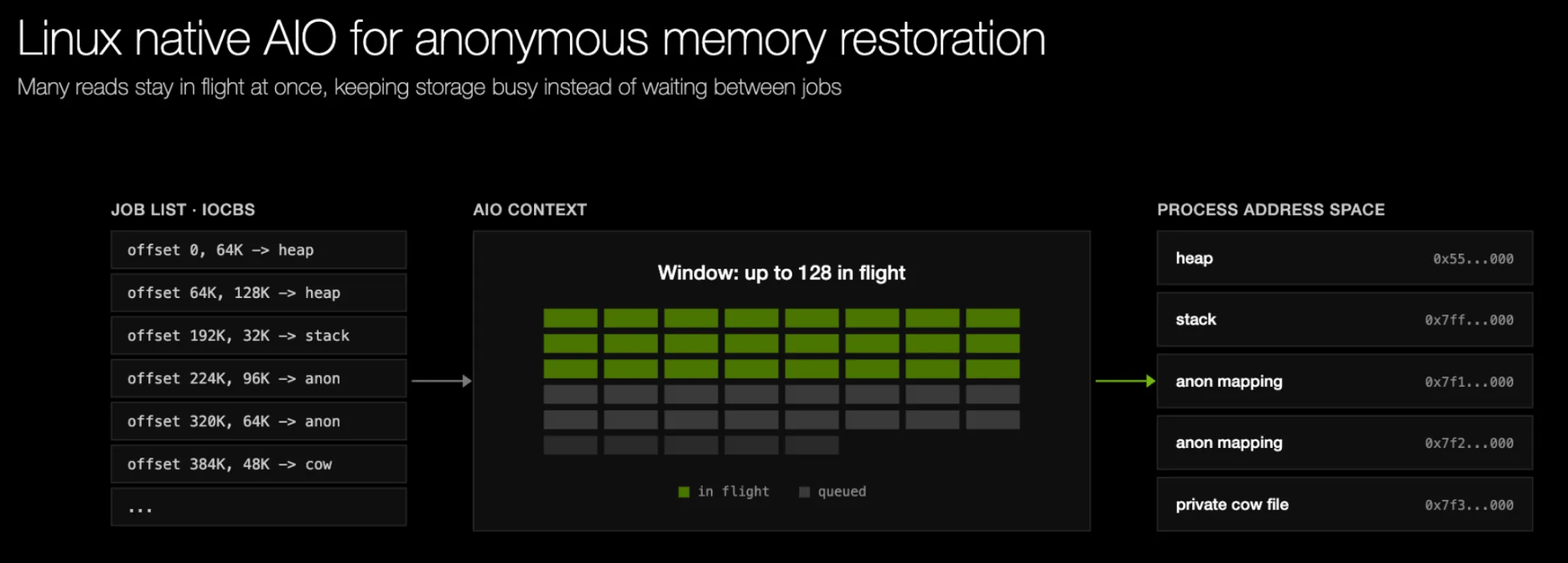
Hình 6. Khôi phục bộ nhớ bằng Linux Native AIO (tối đa 128 thao tác đọc đang thực thi đồng thời)
Direct I/O và page cache
Ở nơi backend lưu trữ hỗ trợ, cả thao tác đọc bộ nhớ anonymous lẫn shared memory đều dùng O_DIRECT. Restore chủ yếu là một luồng một lượt từ các tệp checkpoint vào bộ nhớ đích, nên việc lưu các trang đầu vào trong kernel page cache thường là lãng phí. Nếu không có direct I/O, một lần restore lớn có thể tạm thời lấp đầy page cache bằng dữ liệu checkpoint trong khi cũng cấp phát các trang shmem đích, làm tăng áp lực bộ nhớ và đẩy dữ liệu hữu ích của các workload khác ra khỏi cache.
Quan trọng hơn nữa, Linux native AIO chỉ thực sự bất đồng bộ trên các tệp được mở với O_DIRECT. Trên các filesystem mà O_DIRECT không khả dụng hoặc không đáng tin cậy, chẳng hạn như một số triển khai NFS, restore sẽ fallback sang buffered I/O với readahead tuần tự để kernel vẫn thấy một mẫu truy cập streaming có thể dự đoán, nhưng lợi ích từ AIO bị giảm đáng kể.
Kết quả
Trên cùng một thiết lập, chúng tôi thấy thời gian khôi phục CRIU được cải thiện rất lớn, và hiện việc khôi phục từ checkpoint nhanh hơn đáng kể so với khởi động nguội một inference worker:
| Model | Checkpoint size | CRIU (upstream) | CRIU (AIO) | CRIU (AIO + parallel memfd) | Speedup over upstream | SOL |
|---|---|---|---|---|---|---|
| Qwen3-0.6B | 6.2 GiB | 6.8 s | 2.9 s | 2.4 s | 2.8x | 0.95 s |
| Qwen3-8B | 26 GiB | 24 s | 11 s | 4.7 s | 5.1x | 1.8 s |
| gpt-oss-120b | 129 GiB | 119 s | 54 s | 15 s | 7.9x | 11 s |
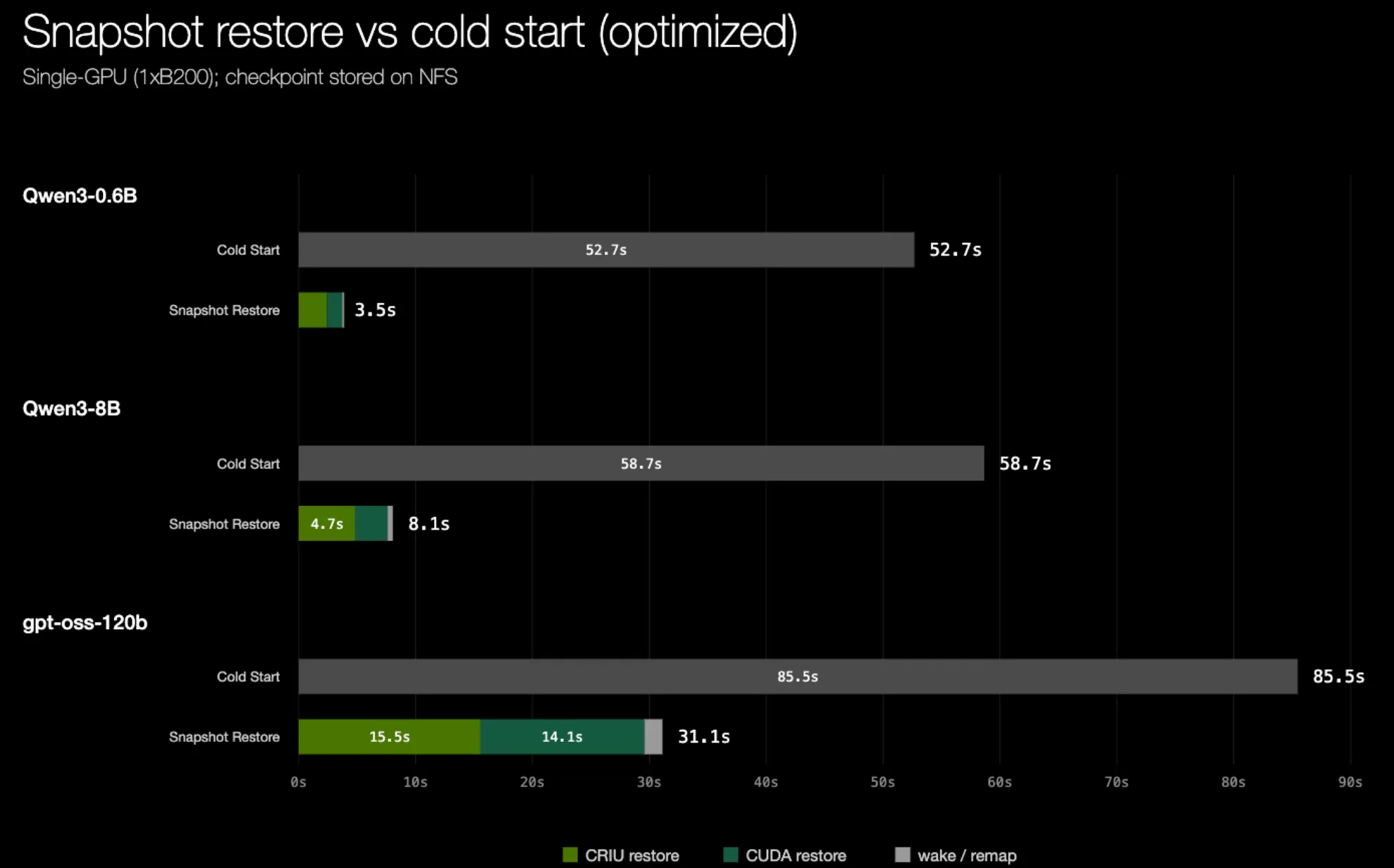
Hình 7. Thời gian khôi phục CRIU sau các tối ưu hóa Linux native AIO và parallel memfd
Ở thời điểm này, thời gian khôi phục CRIU đã gần với SOL hơn nhiều, nhưng thời gian khôi phục end-to-end vẫn bị chi phối bởi việc di chuyển tuần tự các trọng số mô hình lớn từ PVC, qua bộ nhớ host, rồi lên GPU. Quy trình này về cơ bản là tuần tự: cuda-checkpoint không thể khôi phục bộ nhớ GPU cho đến khi CRIU hiện thực hóa các trọng số trong bộ nhớ host. Vì các trọng số này chiếm phần lớn kích thước checkpoint, việc giữ chúng bên trong image CRIU tạo ra một giới hạn cứng đối với tốc độ khôi phục và chặn các kênh truyền trực tiếp tới GPU nhanh hơn.
Tối ưu hóa #3: Dịch vụ bộ nhớ GPU
Để loại bỏ nút thắt này, chúng tôi đã phát triển GPU Memory Service (GMS). GMS sử dụng API CUDA Virtual Memory Management (VMM) để tách các trọng số mô hình lớn khỏi vòng đời tiến trình của inference worker, chuyển phần lớn bộ nhớ tiến trình sang một artifact GMS riêng biệt.
Bằng cách loại bỏ trọng số khỏi checkpoint CRIU lõi, GMS cho phép chúng tôi thực hiện khôi phục trạng thái tiến trình và khôi phục trọng số đồng thời bằng các kênh băng thông bộ nhớ khác nhau, thay vì tuần tự. Việc khôi phục trọng số giờ đây cũng có thể dùng các đường dẫn nhanh nhất hiện có như GPUDirect Storage (GDS) hoặc peer-GPU RDMA/NVLink. Checkpoint CRIU cũng được thu nhỏ đáng kể, chỉ chứa trạng thái phía host của cây tiến trình trong container và một vài bộ đệm phụ được double-buffer, trong khi artifact trọng số GMS hiện chứa phần lớn bộ nhớ tiến trình có thể được khôi phục nhanh hơn nhiều.
| Model | CRIU checkpoint size (baseline) | CRIU checkpoint size (with GMS) | GMS weight artifact |
|---|---|---|---|
| Qwen3-0.6B | 6.2 GiB | 4.3 GiB | 1.2 GiB |
| Qwen3-8B | 26 GiB | 4.8 GiB | 15 GiB |
| gpt-oss-120B | 129 GiB | 6.7 GiB | 74 GiB |
Bảng 2. Phân tích kích thước artifact checkpoint cho từng mô hình sau khi tách riêng weights vào GMS
Ngay cả khi việc khôi phục trọng số diễn ra thông qua NFS, chúng tôi vẫn thấy thời gian khôi phục được tăng tốc đáng kể:
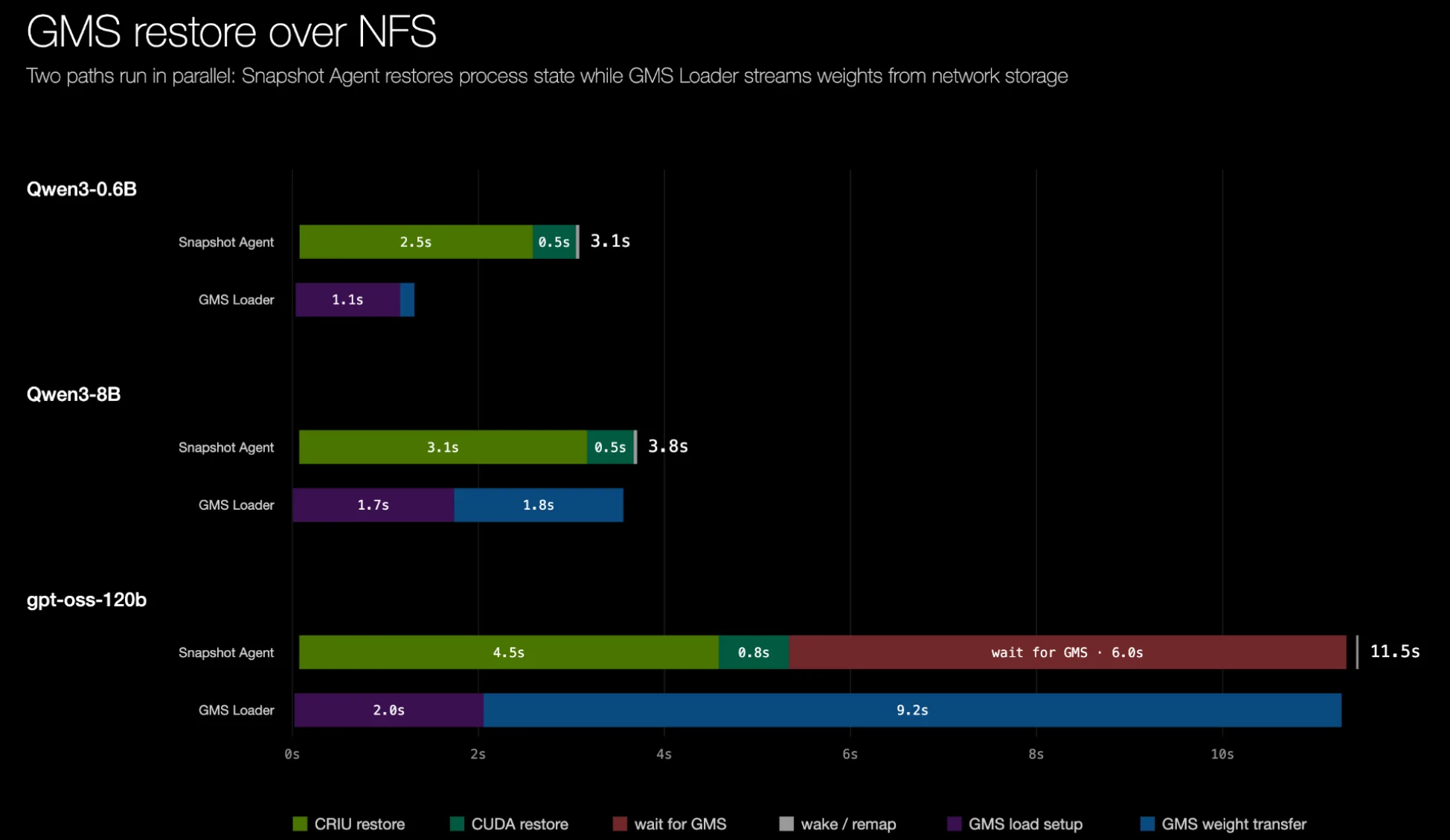
Hình 8. Thời gian khôi phục đầu cuối với GMS Weight Decoupling qua NFS. Thời gian khôi phục được đo từ một dấu thời gian kích hoạt khôi phục chung, không bao gồm thời gian khởi động container.
Khi các trọng số được khôi phục qua một kênh độc lập khác, đó là lúc chúng tôi thấy cách tiếp cận tách rời thực sự phát huy hiệu quả – việc khôi phục trọng số có thể hoàn tất song song, trước cả khi CRIU restore hoàn tất (giả sử có một cơ chế truyền trọng số đủ nhanh). Dưới đây là kết quả từ một backend khôi phục trọng số proof-of-concept, trong đó các trọng số được phân dải trên 8 SSD NVMe cục bộ – quá trình khôi phục hoàn tất trong chưa đầy 5 giây. Kết quả cuối cùng là thời gian khởi động của gpt-oss-120b giảm 21 lần.
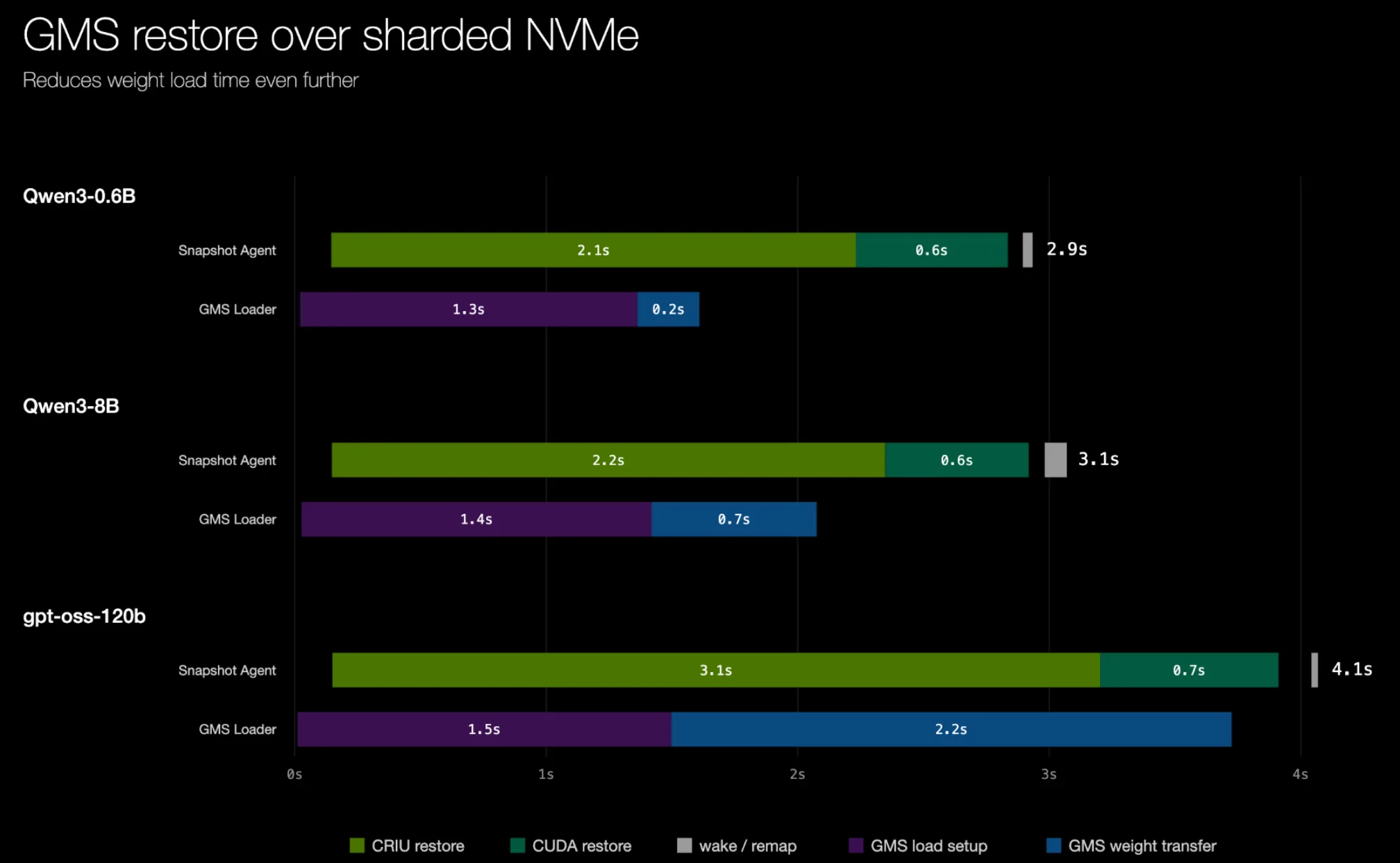
Hình 9. Khôi phục dưới 5 giây với GMS và các ổ SSD NVMe cục bộ dạng striped. Lưu ý: Kiến trúc đầy đủ và các tính năng chi tiết của GMS áp dụng cho những trường hợp sử dụng khác (chẳng hạn như khả năng phục hồi) sẽ được mô tả trong một bài đăng blog tiếp theo.
Tính khả dụng và lộ trình
Hiện chúng tôi đã có bằng chứng ban đầu cho thấy khởi động nhanh cho các workload suy luận trên Kubernetes là khả thi, và chúng tôi đang làm việc để ổn định phần triển khai cũng như mở rộng hỗ trợ cho nhiều loại workload hơn. Dynamo Snapshot sẽ được triển khai dần trong những tháng tới.
Hiện tại, bản phát hành thử nghiệm hỗ trợ các workload vLLM và SGLang một GPU thông qua đường dẫn checkpoint/restore không dùng GMS.
Chúng tôi hiện đang tích hợp các tính năng sau:
- Đường dẫn khôi phục GMS với các backend có thể cắm thêm (GDS, UCX, v.v.), hiện đang bị chặn bởi bản vá CUDA driver đang chờ xử lý
- Hỗ trợ TensorRT-LLM
- Hỗ trợ multi-GPU và multi-node thông qua các hook quiesce/resume cho PyTorch, NCCL, NIXL, v.v.
Source: NVIDIA Dynamo Snapshot: Fast Startup for Inference Workloads on Kubernetes | NVIDIA Technical Blog
Bài viết liên quan
- Cách đánh giá các chính sách Robot đa năng cho triển khai thực tế
- Xác suất xảy ra các sự kiện cực đoan với các mô hình tạo sinh được hướng dẫn
- Triển khai NVIDIA Cosmos 3 sau huấn luyện trong một ngày bằng Kỹ năng Agent
- NVIDIA Ising Decoding giảm tỷ lệ lỗi Logic mã màu hơn 300 lần
- Xây dựng Ứng dụng Theo dõi 3D Đa Camera với Kỹ năng NVIDIA DeepStream 9.1
- Nâng cao hiệu suất trong huấn luyện LLM quy mô lớn bằng cách sử dụng song song tensor không đồng nhất