
Các mô hình AI mới nhất tiếp tục phát triển về kích thước và độ phức tạp, đòi hỏi hiệu năng tính toán ngày càng cao cho việc huấn luyện và suy luận — vượt xa khả năng đáp ứng của Định luật Moore. Đó là lý do tại sao NVIDIA đã đưa ra hệ thống thiết kế đồng bộ cực kỳ phức tạp này. Việc thiết kế hệ thống đa chip và stack phần mềm đồ sộ vận hành một cách thống nhất cho phép tạo ra những bước nhảy vọt mạnh mẽ về hiệu năng và tính hiệu quả của AI Factory.
Các định dạng AI có độ chính xác thấp hơn sẽ là chìa khóa để cải thiện hiệu năng tính toán và hiệu quả năng lượng. Việc mang lại lợi ích của các phép toán số có độ chính xác cực thấp cho việc huấn luyện và suy luận AI trong khi vẫn duy trì độ chính xác cao đòi hỏi kỹ thuật chuyên sâu trên mọi phân lớp của tầng công nghệ. Điều này bao gồm việc tạo ra các định dạng, triển khai trên chip silicon, kích hoạt trên nhiều thư viện và làm việc chặt chẽ với hệ sinh thái để triển khai các công thức huấn luyện mới và các kỹ thuật tối ưu hóa suy luận. NVFP4, được phát triển và triển khai cho GPU của NVIDIA bắt đầu từ NVIDIA Blackwell, mang lại lợi ích về hiệu năng và hiệu quả năng lượng của độ chính xác dấu phẩy động 4 bit trong khi vẫn duy trì độ chính xác tương đương với các định dạng có độ chính xác cao hơn.
Đối với những ai muốn tối ưu hóa hiệu suất huấn luyện và suy luận AI, đây là ba điều cần biết về NVFP4.
1. NVFP4 mang lại những bước tiến vượt bậc về hiệu năng cho quá trình huấn luyện và suy luận trên kiến trúc Blackwell—và hơn thế nữa.
GPU NVIDIA Blackwell Ultra cung cấp thông lượng NVFP4 tối đa lên đến 15 petaFLOPS—gấp 3 lần so với FP8 trên cùng một GPU. Những cải tiến này không chỉ thể hiện ở thông số kỹ thuật tối đa; chúng còn được thể hiện rõ ràng trong hiệu năng đo được của các tác vụ huấn luyện và suy luận.
Đối với suy luận, như đã được trình bày trong một bài đăng blog kỹ thuật gần đây , việc chuyển từ FP8 sang NVFP4 dẫn đến những cải tiến đáng kể về thông lượng token được phân phối ở một mức độ tương tác nhất định trên DeepSeek-R1, một mô hình hỗn hợp các chuyên gia (MoE) phổ biến với 671 tỷ tham số. Thông lượng tăng lên ở một tỷ lệ token nhất định và thậm chí ở tỷ lệ token cao hơn, cho phép trải nghiệm người dùng tốt hơn.
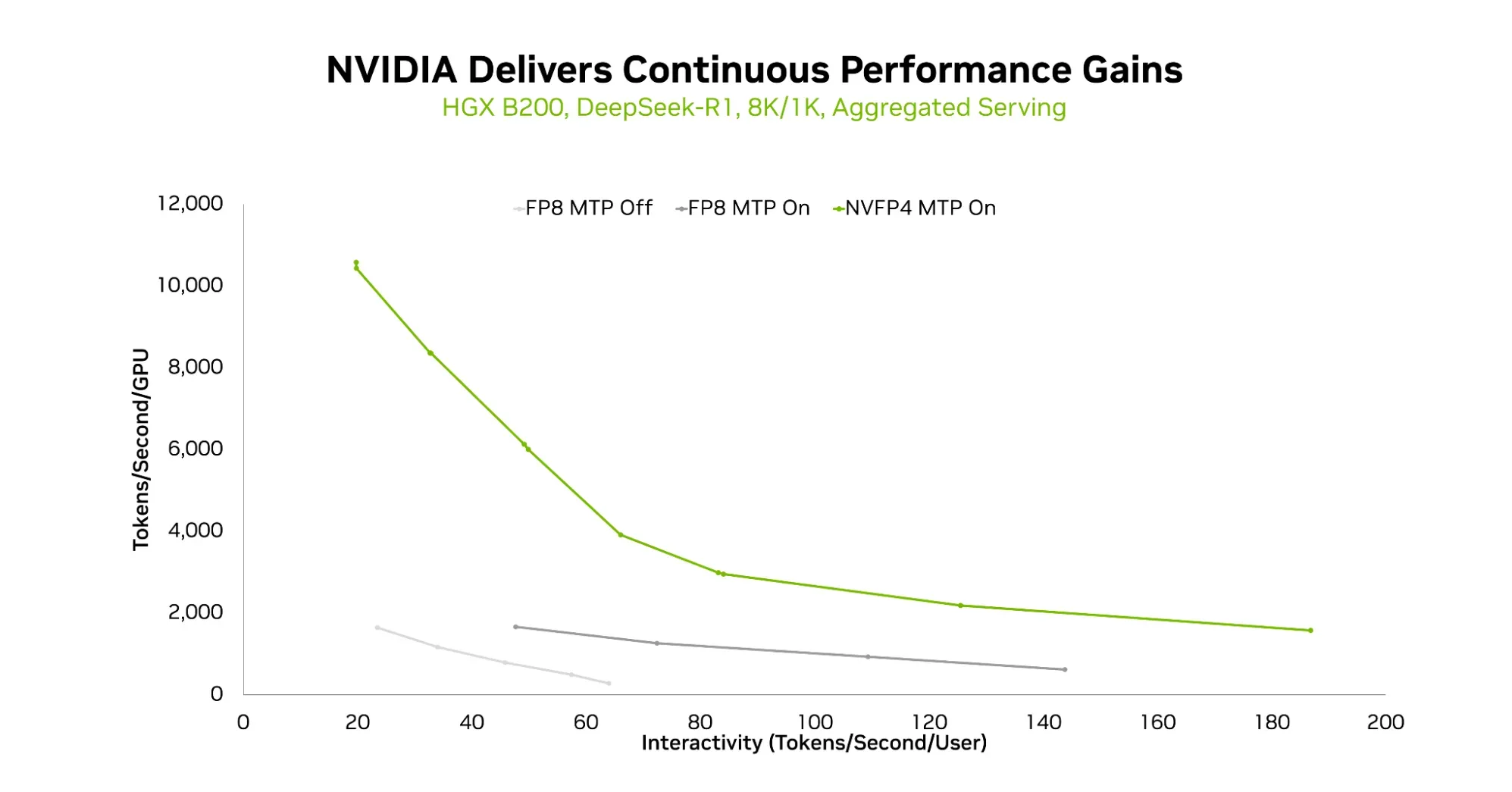 Hình 1. Đường cong hiệu suất so với khả năng tương tác trên FP8 không có MTP, FP8 có MTP và NVFP4 có MTP trên HGX B200, với độ dài chuỗi 8K/1K và phục vụ tổng hợp.
Hình 1. Đường cong hiệu suất so với khả năng tương tác trên FP8 không có MTP, FP8 có MTP và NVFP4 có MTP trên HGX B200, với độ dài chuỗi 8K/1K và phục vụ tổng hợp.
Gần đây, NVIDIA cũng đã công bố một công thức huấn luyện NVFP4, mang lại những lợi ích hiệu năng đáng kể của NVFP4 cho việc huấn luyện mô hình, cho phép các nhà sản xuất mô hình huấn luyện AI nhanh hơn và với chi phí thấp hơn.
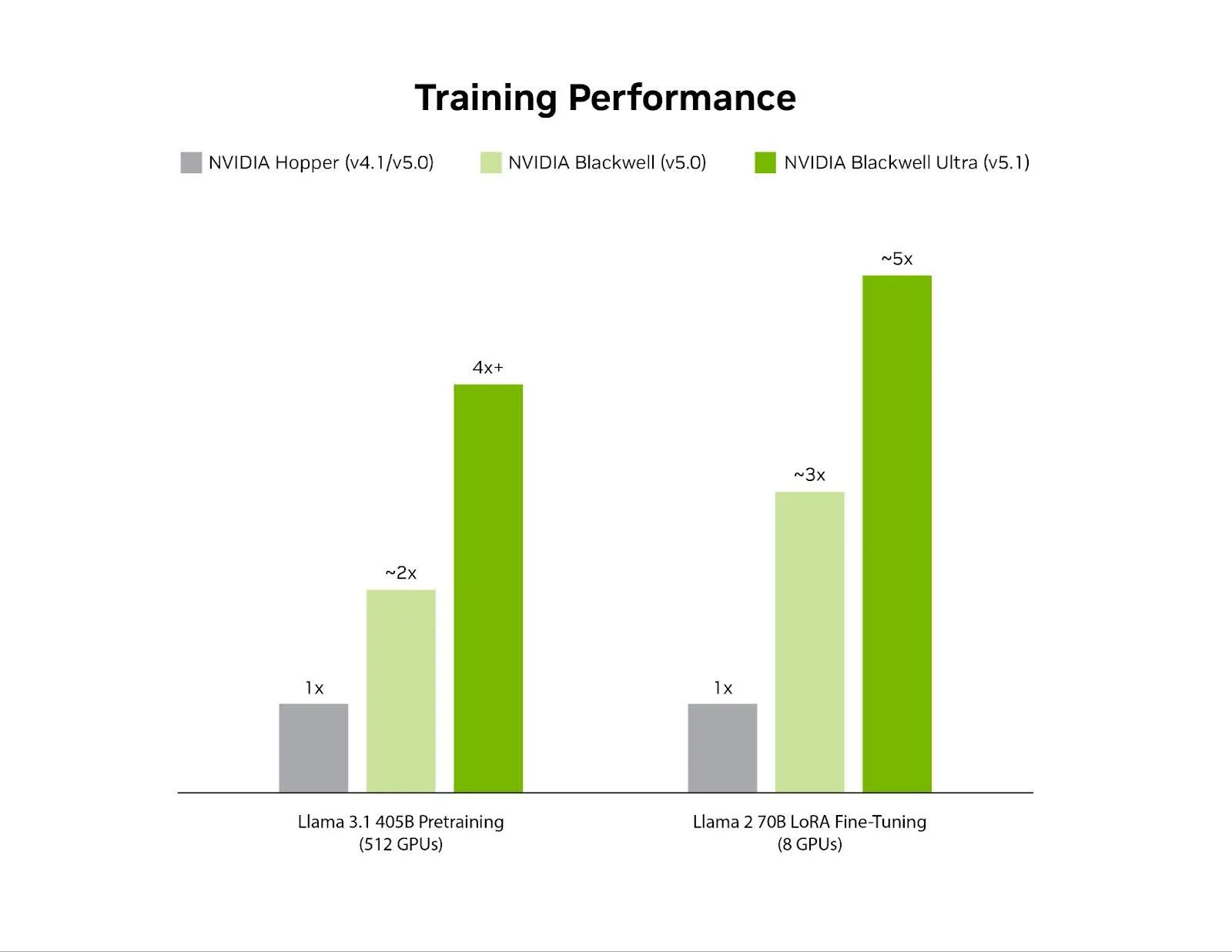 Hình 2. Hiệu năng tương đối của quá trình tiền huấn luyện Llama 3.1 405B và quá trình tinh chỉnh Llama 2 70B LoRA ở quy mô 512 GPU và 8 GPU tương ứng.
Hình 2. Hiệu năng tương đối của quá trình tiền huấn luyện Llama 3.1 405B và quá trình tinh chỉnh Llama 2 70B LoRA ở quy mô 512 GPU và 8 GPU tương ứng.
Trong phiên bản mới nhất của bộ công cụ đánh giá hiệu năng MLPerf Training, nhiều hệ thống NVIDIA GB300 NVL72 — tổng cộng 512 GPU Blackwell Ultra — đã cùng nhau hoạt động với độ chính xác NVFP4 để hoàn thành bài kiểm tra hiệu năng tiền huấn luyện Llama 3.1 405B trong 64,6 phút. Kết quả này nhanh hơn 1,9 lần so với 512 GPU Blackwell trên nhiều hệ thống NVIDIA GB200 NVL72, vốn đã hoàn thành bài kiểm tra hiệu năng bằng FP8 trong vòng trước đó.
Nhìn về phía trước, nền tảng NVIDIA Rubin mang lại những bước tiến lớn về khả năng NVFP4 cho việc huấn luyện và suy luận, cung cấp 35 petaFLOPS tính toán huấn luyện NVFP4 và 50 petaFLOPS tính toán suy luận bằng Transformer Engine NVFP4. Đây là bước nhảy vọt gấp 3,5 lần và gấp 5 lần so với Blackwell.
2. NVFP4 mang lại độ chính xác cao, đã được chứng minh qua các tiêu chuẩn đánh giá trong ngành.
Để các bài dự thi MLPerf Training và Inference trong hạng mục kín được công nhận, chúng phải đáp ứng các yêu cầu về độ chính xác do các tiêu chuẩn quy định. Đối với phần suy luận, các câu trả lời phải đáp ứng các ngưỡng độ chính xác nhất định, còn đối với phần huấn luyện, các mô hình phải được huấn luyện đến các mục tiêu chất lượng cụ thể (nghĩa là quá trình huấn luyện mô hình phải hội tụ).
NVIDIA đã gửi thành công kết quả trong phân khúc kín trên mọi bài kiểm tra mô hình ngôn ngữ lớn (LLM) sử dụng NVFP4 trên GPU Blackwell và Blackwell Ultra trong phiên bản MLPerf Training mới nhất. Và, NVIDIA đã gửi kết quả trên nhiều mô hình và kịch bản khác nhau bằng cách sử dụng NVFP4 trong MLPerf Inference. Điều này bao gồm DeepSeek-R1, Llama 3.1 8B và 405B, và Llama 2 70B. NVIDIA đã sử dụng các phiên bản được lượng tử hóa bằng NVFP4 của các mô hình, đồng thời đáp ứng các yêu cầu nghiêm ngặt của bài kiểm tra chuẩn.
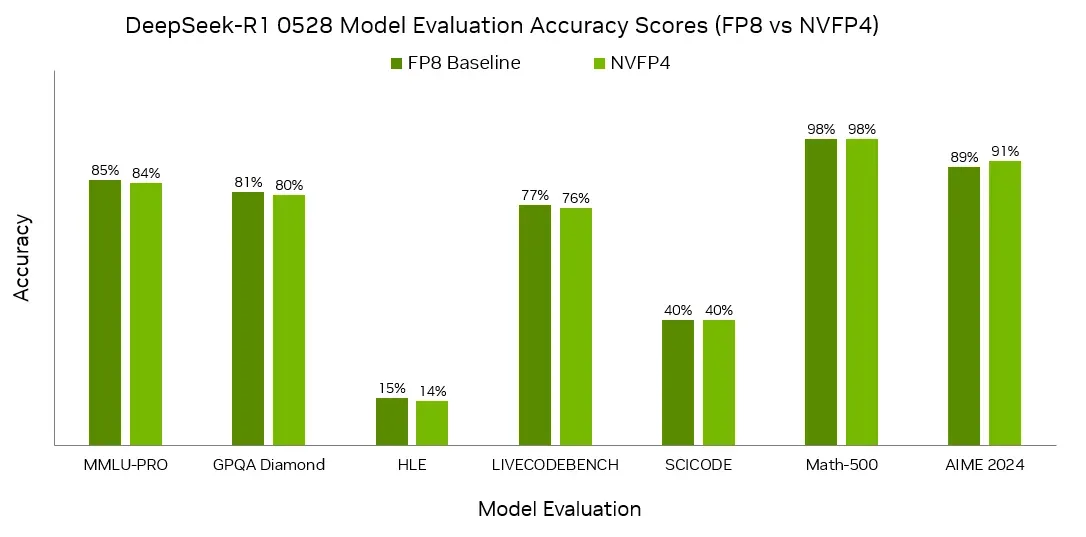 Hình 3. Điểm đánh giá mô hình DeepSeek-R1 cho thấy NVFP4 có độ chính xác gần bằng với mô hình cơ sở FP8.
Hình 3. Điểm đánh giá mô hình DeepSeek-R1 cho thấy NVFP4 có độ chính xác gần bằng với mô hình cơ sở FP8.
3. NVFP4 được hỗ trợ rộng rãi và ngày càng tăng bởi hệ sinh thái.
Các thư viện như NVIDIA Model Optimizer, LLM Compressor và torch.ao cho phép các nhà phát triển lượng tử hóa các mô hình được huấn luyện ở độ chính xác cao hơn thành NVFP4 và triển khai bộ nhớ đệm NVFP4 KV để hỗ trợ ngữ cảnh dài và kích thước lô lớn trong khi vẫn duy trì độ chính xác. Các khung suy luận phổ biến, bao gồm NVIDIA TensorRT-LLM , vLLM và SGLang, hiện cũng hỗ trợ chạy các mô hình ở định dạng NVFP4 với các mô hình có sẵn ở các biến thể NVFP4. Ví dụ, trên HuggingFace, các nhà phát triển có thể tìm thấy các phiên bản NVFP4 sẵn sàng triển khai như Llama 3.3 70B , FLUX.2 , DeepSeek-R1-0528, Kimi-K2-Thinking, Qwen3-235B-A22B và NVIDIA Nemotron Nano .
Hệ sinh thái này cũng đang áp dụng NVFP4 để tăng thông lượng suy luận trong môi trường sản xuất trên nhiều mô hình khác nhau. Các công ty đó bao gồm Black Forest Labs, Radical Numerics, Cognition và Red Hat.
Black Forest Labs đã hợp tác với NVIDIA để mở rộng khả năng suy luận NVFP4 cho FLUX.2 trên Blackwell. “Bằng cách kết hợp các tối ưu hóa như CUDA Graphs, torch.compile, độ chính xác NVFP4 và TeaCache, chúng tôi đạt được tốc độ tăng lên tới 6,3 lần trên một chip B200 duy nhất — giảm đáng kể độ trễ và cho phép triển khai sản phẩm hiệu quả hơn,” Robin Rombach, đồng sáng lập kiêm CEO của Black Forest Labs cho biết.
Radical Numerics đã tận dụng NVFP4 để đẩy nhanh quá trình mở rộng mô hình thế giới khoa học. “Không giống như ngôn ngữ, dữ liệu khoa học buộc chúng ta phải vượt ra ngoài công thức tự hồi quy đơn phương thức cổ điển, đòi hỏi các phương pháp ngữ cảnh cực dài và sự kết hợp đa phương thức mạnh mẽ,” Michael Poli, đồng sáng lập và nhà khoa học AI trưởng tại Radical Numerics cho biết. Ông nói thêm rằng công ty “rất lạc quan” về việc sử dụng các công thức độ chính xác thấp để huấn luyện trước và sau khi huấn luyện kiến trúc mới của mình.
Steven Cao, một thành viên của nhóm nghiên cứu Cognition, cho biết Cognition đang nhận thấy “những cải tiến đáng kể về độ trễ và thông lượng” khi sử dụng NVFP4 trong học tăng cường quy mô lớn.
Và Red Hat đang mở rộng quy mô khối lượng công việc LLM của mình với lượng tử hóa NVFP4, mang lại cho các nhà phát triển độ chính xác gần như cơ bản trên cả các mô hình tiên tiến và MoE trong khi vẫn tuân thủ ngân sách bộ nhớ hạn chế. Bằng cách giảm đáng kể dung lượng kích hoạt và trọng lượng mà không làm giảm chất lượng đáng kể, NVFP4 giúp các kỹ sư của Red Hat có thể đào tạo và phục vụ các mô hình LLM hiện đại trên các cửa sổ ngữ cảnh lớn hơn và khả năng xử lý đồng thời cao hơn bằng cách sử dụng cơ sở hạ tầng hiện có.
Thư viện NVIDIA Transformer Engine tích hợp sẵn thuật toán huấn luyện NVFP4, và các framework huấn luyện như Megatron-Bridge cũng cung cấp các triển khai để các nhà phát triển có thể bắt đầu sử dụng. NVIDIA cũng tiếp tục đổi mới và hợp tác với hệ sinh thái để mang lại lợi ích về hiệu suất và hiệu quả của huấn luyện NVFP4 cho toàn bộ hệ sinh thái, mở đường cho các mô hình thông minh hơn, phức tạp hơn được huấn luyện nhanh hơn và hiệu quả hơn.
Tìm hiểu thêm
Việc sử dụng NVFP4 có thể mang lại hiệu suất vượt trội trên cả nền tảng NVIDIA Blackwell và NVIDIA Rubin. Thông qua thiết kế đồng bộ tối ưu, hiệu suất vượt trội này cũng có thể đạt được với độ chính xác tuyệt vời cho cả quá trình huấn luyện và suy luận mô hình. Các phiên bản NVFP4 của các mô hình LLM mã nguồn mở phổ biến hiện có sẵn rộng rãi, cho phép các dịch vụ chạy các mô hình này với thông lượng cao hơn và chi phí thấp hơn trên mỗi triệu token.
Tìm hiểu thêm về cách những bước tiến vượt bậc về kiến trúc được nền tảng Rubin mang lại, bao gồm cả NVFP4 được nâng cấp, cho phép đạt được hiệu năng cao hơn trong quá trình huấn luyện và suy luận AI.
Bài viết liên quan
- BioNeMo Agent Toolkit: Khi AI Agent bước vào phòng thí nghiệm số
- NVIDIA dẫn đầu hiệu suất Agentic Coding trên bài đo benchmark Agentic AI đầu tiên
- Bảo mật AI bắt nguồn từ phần cứng sẽ không làm bạn chậm lại
- Tăng tốc Tổng hợp BEV trên GPU NVIDIA cho các Ứng dụng AI Vật lý
- Triển khai các agent tự tiến hóa để nghiên cứu nhanh hơn và an toàn hơn với Hermes agent và NVIDIA NemoClaw
- NVIDIA Blackwell lập kỷ lục STAC-AI về suy luận LLM trong lĩnh vực tài chính