

Các chatbot chạy một lượt (single-turn) đang phát triển thành các agent hoạt động lâu dài, có khả năng suy luận, duy trì ngữ cảnh, sử dụng công cụ và vận hành hiệu quả qua nhiều lượt để hoàn thành các quy trình công việc phức tạp.
Tuy nhiên, các quy trình làm việc multi-agent này khiến số lượng token tăng lên nhanh chóng. Các agent lập kế hoạch, gọi công cụ, kích hoạt các agent phụ, nhận thông tin, và sau đó liên tục truyền lịch sử, đầu ra và các bước suy luận trở lại mô hình. Khi các tác vụ kéo dài hơn, việc giao tiếp liên tục này làm tăng chi phí và nguy cơ lệch mục tiêu.
Các nhà phát triển có thể giải quyết vấn đề này bằng cách sử dụng một hệ thống các mô hình: mô hình suy luận tiên tiến để điều phối và lập kế hoạch phức tạp, và các mô hình hiệu quả để thực thi, xác thực và gọi công cụ với khối lượng lớn.
NVIDIA đang phát hành NVIDIA Nemotron 3 Ultra, một mô hình mã nguồn mở được xây dựng để giúp các tác vụ chạy dài hạn hoàn thành nhanh hơn đồng thời giảm chi phí token.
Nemotron 3 Ultra dành cho điều phối agent
Nemotron 3 Ultra là một mô hình hỗn hợp các chuyên gia (Mixture-of-Experts) với 550 tỷ tham số và 55 tỷ tham số hoạt động, được xây dựng cho lập luận nâng cao và điều phối trong các hệ thống agent.
Trong bất kỳ quy trình làm việc nào của chuyên gia, hầu hết các lệnh gọi đều mang tính chất thường nhật, nhưng một số ít quan trọng đòi hỏi khả năng suy luận sâu hơn. Nemotron 3 Ultra được thiết kế để xử lý những lệnh gọi khó khăn này: duy trì các quyết định kiến trúc xuyên suốt các phiên lập trình, tổng hợp các bằng chứng mâu thuẫn từ hàng trăm nguồn nghiên cứu, hoặc xác minh thiết kế chip dựa trên hàng nghìn ràng buộc.
| Nemotron 3 Ultra (550B) | GLM 5.1 (744B) | Kimi K2.6 (1T) | Qwen3.5 (397B) | |
| Công cụ đo năng suất của agent | 91% | 84% | 91% | 89% |
| Lập kế hoạch dài hạnEnterpriseOps-Gym | 33% | 40% | 29% | 30% |
| Lập trình thiết bị đầu cuối- Bàn làm việc 2.0 | 54% | 64% | 67% | 53% |
| Hướng dẫn theoIFBench | 82% | 77% | 74% | 78% |
| Công việc tri thứcGDPVal-AA | 1.448 | 1.594 | 1.508 | 1.192 |
| Nhiệm vụ công việc chuyên nghiệpProfBench (Tìm kiếm) | 56% | 46% | 56% | 53% |
| Thước đo ngữ cảnh dài@1M | 95% | Không áp dụng (tối đa 256K) | Không áp dụng (tối đa 256K) | 90% |
Bảng 1. Nemotron 3 Ultra mang lại độ chính xác vượt trội trong một mô hình nhỏ gọn hơn.
Nemotron 3 Ultra cũng chạy rất nhanh. Nó đạt được thông lượng cao hơn gấp 5 lần so với các mô hình mã nguồn mở khác cùng loại, cho phép các agent chạy dài hoàn thành nhiệm vụ nhanh hơn và hiệu quả hơn.
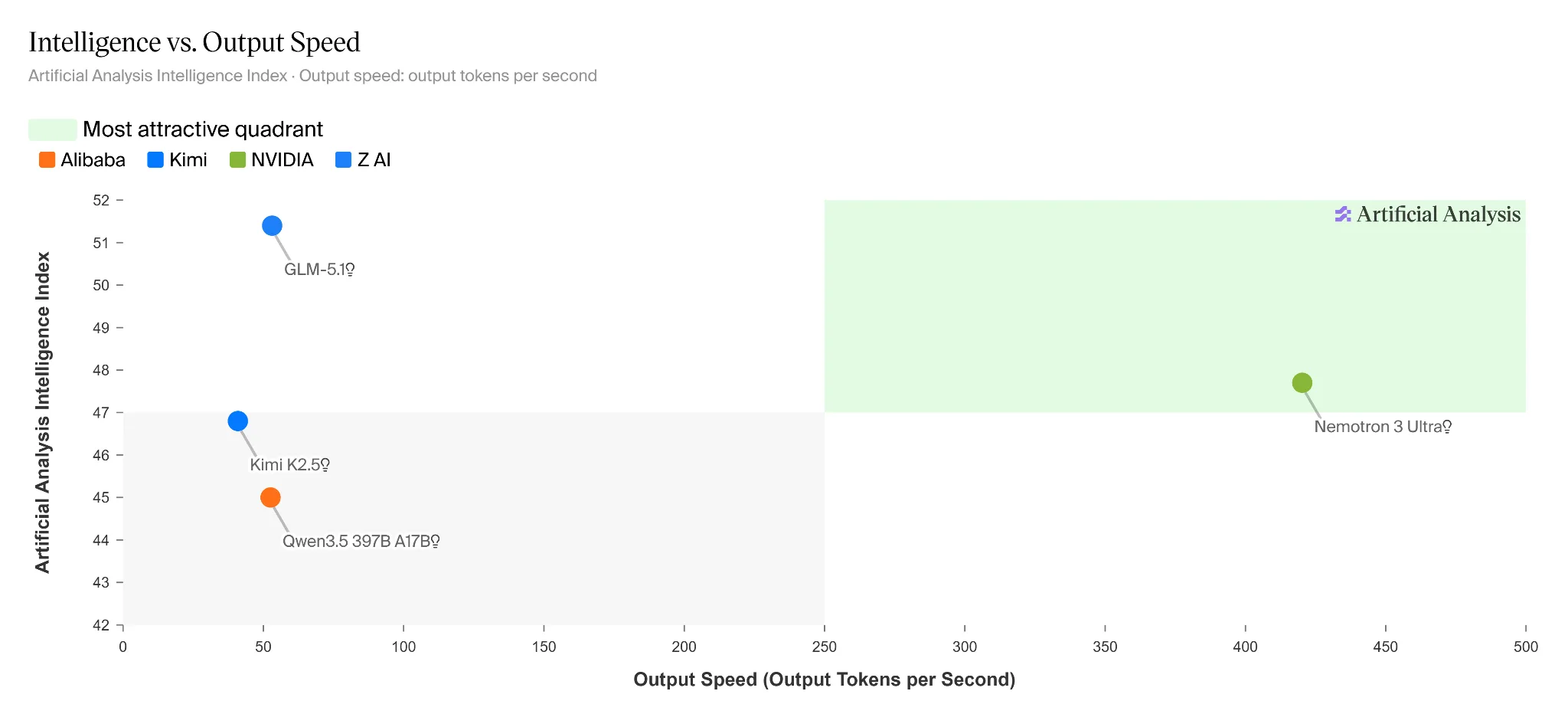
Hình 2. Nemotron 3 Ultra đạt được tốc độ suy luận nhanh hơn gấp 5 lần đồng thời mang lại độ chính xác hàng đầu trên bảng xếp hạng Chỉ số Trí tuệ Phân tích Nhân tạo, với tốc độ đầu ra của Nemotron 3 Ultra được đo bằng các điểm cuối Blackbox.
Nemotron 3 Ultra cũng được thiết kế để hoạt động hiệu quả. Trong các thí nghiệm trên SWE-bench và Terminal bench 2.0, nó đã hoàn thành các bài kiểm tra hiệu năng bằng cách sử dụng tổng số token ít hơn và số token mỗi lượt ít hơn so với các mô hình tương đương. Điều này giúp giảm chi phí cho các tác vụ của agent lên đến 30%.
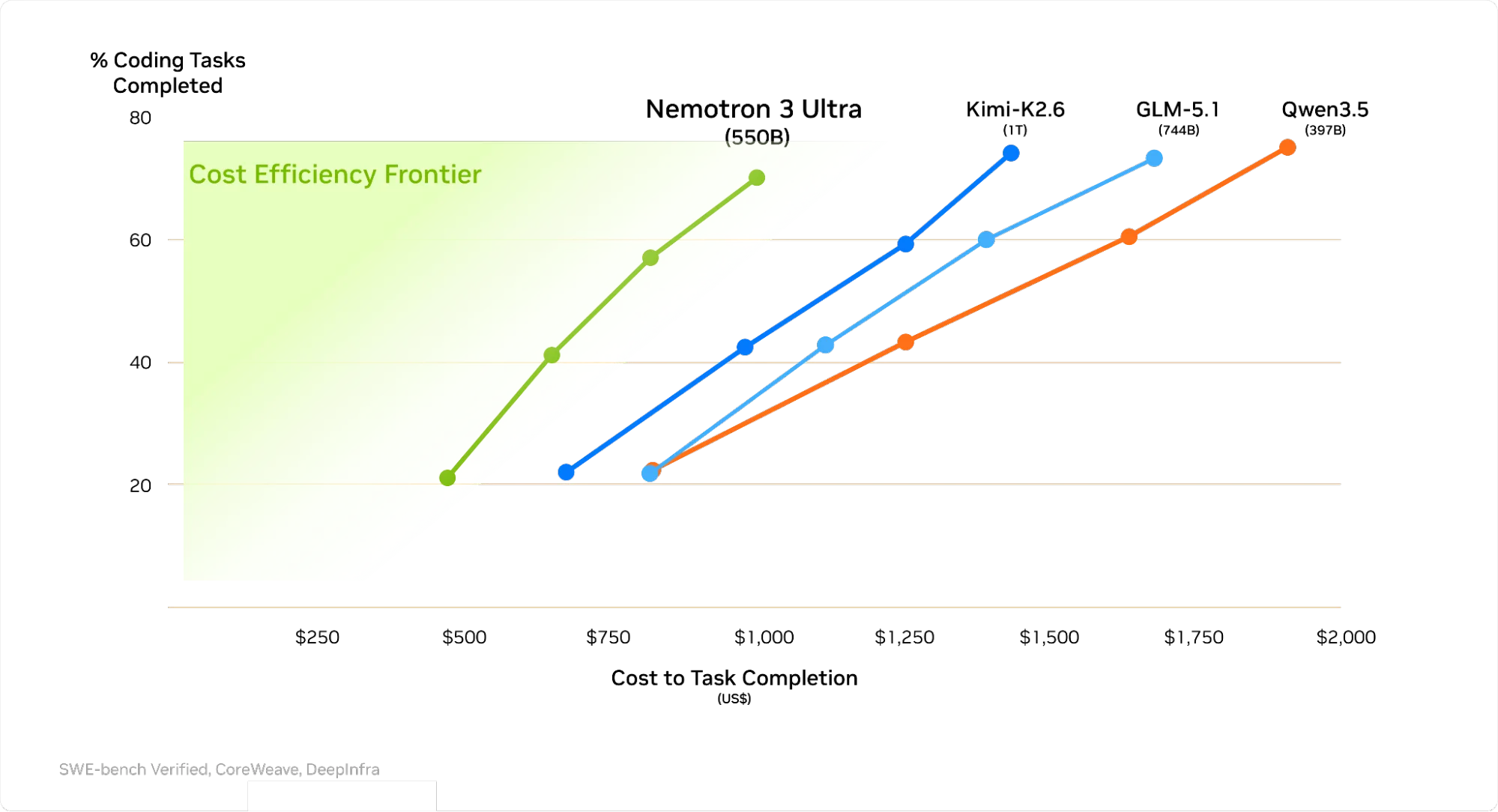
Hình 3. Nemotron 3 Ultra giảm chi phí hoàn thành nhiệm vụ xuống 30%.
Những đột phá tạo nên sức mạnh của Nemotron 3 Ultra
Để giảm thiểu sự đánh đổi giữa hiệu quả và độ chính xác thường thấy ở các mô hình suy luận dung lượng cao, các mô hình Nemotron giới thiệu những cải tiến về kiến trúc:
Được huấn luyện sau để kiểm soát agent
Nemotron Ultra được huấn luyện hậu kỳ để mang lại độ chính xác nhất quán trên các hệ thống huấn luyện hàng đầu. Mô hình được huấn luyện bằng thư viện mở NVIDIA NeMo RL và Gym với một trong những bộ dữ liệu sử dụng công cụ, giải quyết nhiệm vụ dài hạn lớn nhất thế giới.
Ultra được tối ưu hóa cho các cuộc hội thoại mở do agent dẫn dắt, không chỉ là hội thoại một lượt, và được thiết kế để hoạt động trong các quy trình làm việc mà agent lập kế hoạch, gọi công cụ, đọc quan sát, giao nhiệm vụ cho agent phụ, xác nhận đầu ra và khắc phục lỗi trong nhiều lượt.
Hybrid Mamba transformer
Các Mamba layers cải thiện hiệu quả xử lý chuỗi cho các tác vụ có ngữ cảnh dài, trong khi các lớp Transformer duy trì khả năng truy xuất chính xác khi các agent cần truy xuất các thông tin cụ thể từ các cửa sổ ngữ cảnh lớn.
Độ chính xác NVFP4
Cùng một điểm kiểm tra NVFP4 chạy trên GPU NVIDIA Hopper, NVIDIA Blackwell và Ampere. Các nhà phát triển có thể sử dụng một điểm kiểm tra duy nhất trên tất cả các kiến trúc GPU của NVIDIA nhờ các nhân lượng tử hóa NVFP4 chuyên dụng. NVFP4 cũng mang lại thông lượng cao hơn tới 5 lần trên mỗi GPU với cùng mức độ tương tác so với BF16 trên Blackwell.
LatentMoE
LatentMoE hỗ trợ định tuyến chuyên gia hiệu quả hơn, cho phép mô hình xử lý các quy trình công việc bao gồm suy luận, tạo mã, gọi công cụ và logic chuyên biệt theo lĩnh vực.
Dự đoán đa token (Multi-token prediction – MTP)
MTP giúp giảm thời gian tạo bằng cách dự đoán nhiều token trong tương lai chỉ trong một lần truyền dữ liệu, cải thiện hiệu suất cho các đầu ra dài và quy trình làm việc nhiều lượt.
Nemotron 3 Ultra bổ sung tính năng Multi-Teacher On-Policy Distillation
Multi-Teacher On-Policy Distillation (MOPD) là một phương pháp đào tạo trong đó Ultra học hỏi từ nhiều mô hình giáo viên chuyên biệt đồng thời tự tạo ra các nỗ lực của riêng mình trong quá trình huấn luyện. Hơn 10 mô hình giáo viên chuyên biệt được huấn luyện, mỗi mô hình có quy trình huấn luyện riêng biệt cho từng lĩnh vực. Mỗi giáo viên chấm điểm mô hình trong lĩnh vực chuyên môn của mình, giúp Ultra cải thiện khả năng suy luận trên nhiều lĩnh vực một cách hiệu quả hơn.
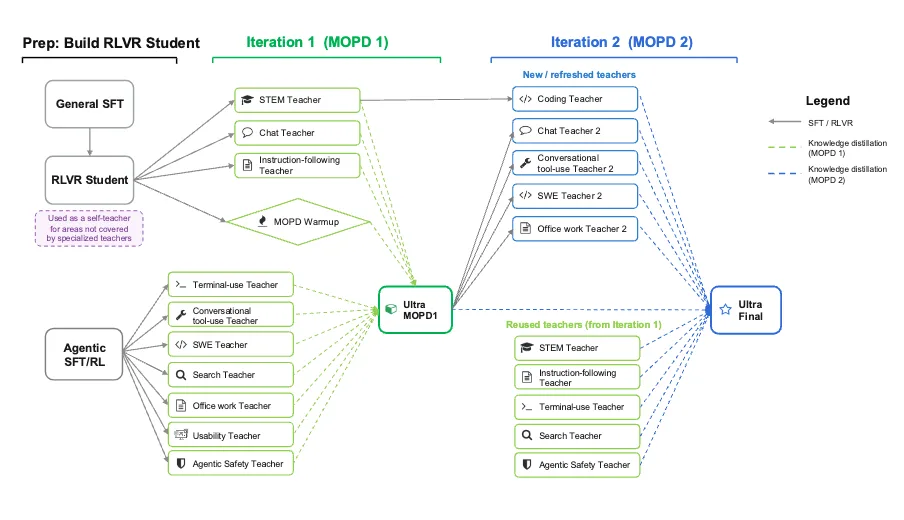
Hình 4. Hướng dẫn trực quan về MOPD và quy trình cụ thể được sử dụng cho Nemotron 3 Ultra
Trong quá trình MOPD, mô hình học sinh tạo ra các kết quả triển khai trên nhiều lĩnh vực và nhận tín hiệu phần thưởng dày đặc từ các mô hình giáo viên tương ứng. Để tối đa hóa hiệu quả, MOPD hoạt động bất đồng bộ, với việc tạo kết quả triển khai của học sinh, chấm điểm của giáo viên và tối ưu hóa học sinh được thực hiện theo trình tự hoàn chỉnh.
MOPD cũng là một quy trình lặp đi lặp lại. Sau khi tạo ra một điểm kiểm tra được đào tạo bằng MOPD, các vòng đào tạo giáo viên mới được khởi tạo từ mô hình học sinh được cập nhật, và những cải tiến được hợp nhất vào giai đoạn MOPD tiếp theo.
Sự cùng phát triển giữa sinh viên và giáo viên này cho phép cải thiện năng lực liên tục và chuyên môn hóa ngày càng sâu rộng trên nhiều lĩnh vực. Người dùng có thể thử các công thức MOPD thông qua NeMo-RL, thư viện đã huấn luyện mô hình Ultra.
Dữ liệu huấn luyện để tăng cường khả năng suy luận của agent.
Cũng như tất cả các lần ra mắt mô hình mở của Nemotron, phần lớn dữ liệu huấn luyện được công bố một cách dễ dàng nhất có thể. Đối với các đối tác trong lĩnh vực phát triển AI doanh nghiệp và quốc gia, tính minh bạch và nguồn gốc dữ liệu huấn luyện quan trọng không kém gì khả năng của nó.
Dữ liệu huấn luyện trước chuyên biệt theo lĩnh vực
Dựa trên nền tảng đào tạo trước đó với 10 nghìn tỷ token, Nemotron 3 Ultra bổ sung thêm 212 tỷ token mới, nhắm mục tiêu vào ba khoảng trống thị trường có giá trị cao:
- 4 tỷ token dữ liệu pháp lý tổng hợp, làm tăng mức trung bình của chỉ số LegalBench từ 64,6% lên 74,7%.
- 35 tỷ token dữ liệu tổng hợp dựa trên Wiki, giúp tăng thị phần của proxy SimpleQA từ 40,2% lên 50,2%.
- 173 tỷ token GitHub đã được làm mới đến ngày 30 tháng 9 năm 2025.
Dữ liệu sau huấn luyện và môi trường RL
Việc ra mắt này cũng công bố 10 triệu mẫu SFT mới, 1 triệu tác vụ RL mới trên nhiều lĩnh vực và 15 môi trường RL hoàn toàn mới, nâng tổng số dữ liệu mở của Nemotron lên 50 triệu mẫu SFT, 2 triệu tác vụ RL và 55 môi trường RL.
Kết quả là điểm số SWEBench Verified nằm trong khoảng từ 65% đến 70,4% trên các framework Pi, OpenHands, Hermes, OpenCode và Mini SWE Agent — hiệu suất ổn định bất kể bạn sử dụng framework nào.
Tinh chỉnh cho tên miền của bạn
Nemotron 3 Ultra có thể được tinh chỉnh bằng LoRA, SFT và học tăng cường sử dụng thư viện NVIDIA NeMo . Các nhà phát triển có thể bắt đầu với các hướng dẫn sau.
Công thức chế tạo Nemotron 3 Ultra:
- SFT LoRA: Mô hình tự động NeMo ( Công thức H100 , Công thức GB200)
- Full SFT: Công thức chế tạo cầu NeMo Megatron
- Học tăng cường: Công thức NeMo RL GRPO , công thức GRPO LoRA , công thức MOPD
Triển khai
Triển khai Nemotron Ultra bằng cách sử dụng Dynamo Recipes để định tuyến nhận biết KV, dự đoán đa token (MTP) và điền trước/giải mã phân tách.
Cùng xem cách nó hoạt động như thế nào
Vido này trình bày cách khởi tạo và chạy quy trình tự động tìm kiếm bằng Hermes Agent được hỗ trợ bởi Nemotron 3 Ultra trên build.nvidia.com.
Video 1. Hướng dẫn từng bước xây dựng trợ lý tự động với Hermes Agent và Nemotron 3 Ultra.
Chạy các tác vụ an toàn hơn với NVIDIA NemoClaw và NVIDIA OpenShell
Các mô hình Nemotron tích hợp với các khung phần mềm agent mở hàng đầu. Để xây dựng một hệ thống agent an toàn, luôn hoạt động, điều quan trọng là phải hiểu rõ kiến trúc tham chiếu:
- Hermes Agent và OpenClaw: Đây là những công cụ hỗ trợ agent phổ biến, cung cấp các vòng lặp điều phối, bộ nhớ và công cụ cho quy trình làm việc nhiều lượt. Hermes Agent hiện đã chính thức có sẵn và được hỗ trợ đầy đủ để sử dụng với Nemotron.
- NVIDIA OpenShell: Hiện đã có bản xem trước sớm, OpenShell là môi trường chạy an toàn (một phần của NVIDIA Agent Toolkit) nơi các agent tự động và mã do chúng tạo ra được thực thi.
- NVIDIA NemoClaw: Đây là bản thiết kế mã nguồn mở kết nối toàn bộ môi trường. Chỉ với một lệnh duy nhất, NemoClaw cài đặt môi trường chạy OpenShell—cung cấp một môi trường an toàn để chạy các agent tự động như Hermes Agent một cách an toàn hơn cùng với các mô hình mã nguồn mở như Nemotron.
Xây dựng các agent an toàn hơn và hỗ trợ giọng nói
Hai mẫu Nemotron mới cũng sẽ được ra mắt:
Nemotron 3.5 Content Safety
Đối với các nhóm xây dựng AI doanh nghiệp an toàn hơn, Nemotron 3.5 Content Safety là một mô hình rào chắn 4B mở, hiệu quả để phân loại nội dung không an toàn, bị cấm hoặc vi phạm chính sách trên văn bản, hình ảnh và các đầu vào kết hợp.
Bao gồm 23 danh mục an toàn và 12 ngôn ngữ, công cụ này có thể được sử dụng như một rào cản trong quá trình suy luận, như một tiêu chí đánh giá an toàn cho việc kiểm tra và đánh giá LLM, hoặc cùng với bộ dữ liệu huấn luyện đi kèm để huấn luyện lại các mô hình nhằm đạt được hành vi an toàn hơn. Hỗ trợ chính sách tùy chỉnh và các quy trình suy luận giúp các doanh nghiệp điều chỉnh các quyết định an toàn theo các quy tắc cụ thể trong từng lĩnh vực, kiểm toán phân loại và triển khai các biện pháp kiểm soát an toàn trên toàn bộ quy trình làm việc AI toàn cầu. Hãy đọc bài viết của Hugging Face để tìm hiểu thêm.
Nemotron 3.5 ASR
Đối với các agent tự nhận diện giọng nói, sử dụng cùng kiến trúc truyền phát dữ liệu có bộ nhớ đệm như phiên bản tiền nhiệm tiếng Anh, Nemotron 3 ASR, để xử lý các thay đổi âm thanh tức thì. Việc loại bỏ các tác vụ tính toán đệm dư thừa đảm bảo độ trễ dưới 100 ms cho việc điều phối giọng nói tự nhiên, theo thời gian thực cho các nhóm agent của bạn.
Mô hình tiếng Anh đã nhận được sự đón nhận mạnh mẽ từ các nhà phát triển, bao gồm cả việc hỗ trợ tính năng nhập liệu bằng giọng nói trong Microsoft GitHub Copilot CLI, được hơn 20 triệu nhà phát triển sử dụng. Một bài kiểm tra độc lập trên hơn 50 cấu hình nhận dạng giọng nói tự động (ASR) trên thiết bị đã xác định Nemotron 3 ASR là ứng cử viên mạnh nhất cho việc truyền phát tiếng Anh theo thời gian thực trên phần cứng có tài nguyên hạn chế. Giờ đây, kiến trúc tương tự đã được nâng cấp lên đa ngôn ngữ với khả năng hỗ trợ hơn 40 ngôn ngữ trong một lần kiểm tra duy nhất.
Cập nhật giấy phép mở để áp dụng rộng rãi hơn
Các bản phát hành mô hình Nemotron đang chuyển sang OpenMDW-1.1, giấy phép tự do của Linux Foundation được thiết kế dành riêng cho việc phân phối mô hình AI mở. OpenMDW được thiết kế để bao quát toàn bộ các tài liệu mô hình, bao gồm kiến trúc, tham số, tài liệu, phần mềm và các thành phần liên quan khác, trong một khuôn khổ duy nhất.
Điều này giúp các nhà phát triển và doanh nghiệp có các điều khoản rõ ràng hơn để sử dụng, sửa đổi, phân phối lại và triển khai các mô hình Nemotron, đồng thời giảm bớt sự mơ hồ về cấp phép có thể làm chậm quá trình đánh giá và áp dụng các mô hình mã nguồn mở.
Cùng bắt đầu build ngay hôm nay
Nemotron 3 Ultra hoàn toàn mã nguồn mở—bao gồm cả trọng số, dữ liệu và công thức—cho phép các nhà phát triển điều chỉnh mô hình cho phù hợp với quy trình làm việc cụ thể và triển khai chúng ở bất cứ đâu. Nó có sẵn trên các nền tảng suy luận hàng đầu và được đóng gói dưới dạng dịch vụ vi mô NVIDIA NIM, có thể chạy ở bất cứ đâu.
Hãy thử trên Perplexity với gói đăng ký Pro hoặc thông qua API, OpenRouter, Anaconda hoặc build.nvidia.com.
Tải xuống các thông số trọng lượng từ Hugging Face, khởi chạy một phiên bản được tối ưu hóa thông qua NVIDIA NIM hoặc bắt đầu với các tập lệnh để chạy trong vài phút.
Nemotron 3 Ultra được cung cấp thông qua hệ sinh thái các đối tác:
- Dịch vụ tùy chỉnh mô hình: Applied Compute , Prime Intellect , Unsloth
- Phần mềm suy luận: SGLang , TRT-LLM , vLLM
- Các nhà cung cấp dịch vụ đám mây: Amazon SageMaker JumpStart , Google Cloud, Microsoft Foundry , Oracle Cloud
- Các nhà cung cấp dịch vụ suy luận: Baseten , DeepInfra, Eigen AI , fal (ASR), Fireworks AI, FriendliAI, Modal , ModelScope , Ollama cloud , Simplismart
- Điện toán đám mây và dịch vụ AI: Bitdeer AI , CoreWeave , Dell Enterprise Hub , Crusoe , DigitalOcean , GMI Cloud , Lightning AI , Nebius Token Factory , Together AI , Vultr
Hãy xem kho lưu trữ GitHub để biết hướng dẫn bắt đầu sử dụng bộ công cụ agent, bao gồm BlackBox AI , Cline , CrewAI , Factory AI , Hermes Agent, Kilo Code , LangChain Deep Agents , OpenClaw , OpenCode , OpenHands và Pi .
Để biết đầy đủ thông tin chi tiết về mặt kỹ thuật, hãy đọc báo cáo kỹ thuật của Nemotron 3 Ultra.
Bài viết liên quan
- Kỷ nguyên của Agentic AI: Hạ tầng Blackwell thiết lập tiêu chuẩn hiệu năng mới với Benchmark AgentPerf
- NVIDIA Riva giải pháp Voice RAG: tối ưu luồng dữ liệu âm thanh và đồng bộ Avatar 3D
- Triển khai kiến trúc Multi-Agent Intelligent Warehouse cho việc vận hành kho hàng hiện đại
- Triển khai NVIDIA Retail Agentic Commerce Blueprint: Merchant-Controlled
- Triển khai hệ thống Voice RAG bằng NVIDIA Riva framework trên hạ tầng cục bộ