Con đường từ một mô hình AI đã huấn luyện hoàn chỉnh cho đến khi chạy production thực tế đáng lẽ phải mượt mà, nhưng thực tế lại hiếm khi được như vậy. Nhiều đội ngũ kỹ sư mất hàng tuần trời để tinh chỉnh (fine-tune) mô hình, nhưng cuối cùng lại phát hiện ra rằng việc xuất (export) mô hình sang định dạng triển khai làm lỗi các tầng (layers), kích thước đầu vào (input shapes) gây ra lỗi runtime, hoặc sự bất đồng bộ về phiên bản (version mismatches) làm giảm hiệu năng một cách âm thầm. Những vấn đề này được gọi chung là “lực cản quy trình” (pipeline friction), và chúng khiến các tổ chức tiêu tốn thời gian, tiền bạc cũng như đánh mất lợi thế cạnh tranh.
Bài viết này sẽ chia sẻ những kinh nghiệm thực tiễn tốt nhất (Best Practice) có thể áp dụng ngay để loại bỏ các nguyên nhân gây ra lực cản phổ biến nhất trong các quy trình phục vụ mô hình AI (AI model serving pipelines). Kết quả mang lại rất cụ thể: các API phản hồi nhanh hơn dưới lượng traffic thực tế; mỗi GPU xử lý được nhiều request hơn; việc mở rộng quy mô (scaling) vào giờ cao điểm trở nên mượt mà và ít áp lực hơn; chi phí cho mỗi lượt suy luận (cost per inference) giảm xuống; và bản thân việc triển khai (deployment) sẽ không còn là phần “cứ đến mỗi đợt release là lỗi” nữa.
Lực cản quy trình (Pipeline Friction) trong triển khai mô hình AI là gì?
Lực cản quy trình (pipeline friction) là bất kỳ trở ngại nào làm chậm hoặc gián đoạn hành trình của một mô hình từ giai đoạn huấn luyện (training) đến suy luận thực tế trên production (production inference). Không giống như các lỗi (bugs) thông thường hiển thị thông báo lỗi rõ ràng, lực cản thường biểu hiện dưới dạng các vấn đề kém hiệu quả rất tinh vi: ví dụ, một mô hình tiêu tốn lượng bộ nhớ GPU gấp đôi dự kiến, hoặc một máy chủ suy luận (inference server) bị rớt request khi quá tải, hoặc một bản deploy chạy tốt trên kiến trúc GPU này nhưng lại thất bại trên kiến trúc GPU khác.
Các nguồn gây ra lực cản quy trình thường gặp nhất có thể được nhóm thành 4 danh mục:
-
Các vấn đề xuất mô hình (Model export issues): Phát sinh khi chuyển đổi từ các framework huấn luyện như PyTorch hoặc TensorFlow sang định dạng suy luận đã được tối ưu hóa.
-
Các toán tử không được hỗ trợ (Unsupported operations): Các tầng tùy biến (custom layers) hoặc mới được giới thiệu không được runtime đích nhận diện.
-
Kích thước đầu vào động (Dynamic input sizes): Gây ra sự không khớp về hình dạng tensor (shape mismatches) hoặc buộc hệ thống phải biên dịch lại (recompilation) không cần thiết.
-
Bất đồng bộ phiên bản (Version mismatches): Gây ra các lỗi ngầm (silent failures) hoặc sụt giảm hiệu năng (performance regressions) do sự không tương thích giữa thư viện, driver và phần cứng.
Mỗi danh mục đều yêu cầu các công cụ và kỹ thuật xử lý đặc thù. Hiện tại đã có một hệ sinh thái giải pháp hoàn thiện, và việc áp dụng chúng một cách có hệ thống có thể loại bỏ phần lớn lực cản trước khi mô hình được đưa lên production. Các phần tiếp theo sẽ trình bày chi tiết về từng danh mục này, cùng với một số cách khác để giảm thiểu lực cản quy trình.
Cách giải quyết các vấn đề xuất mô hình (Model Export Issues)
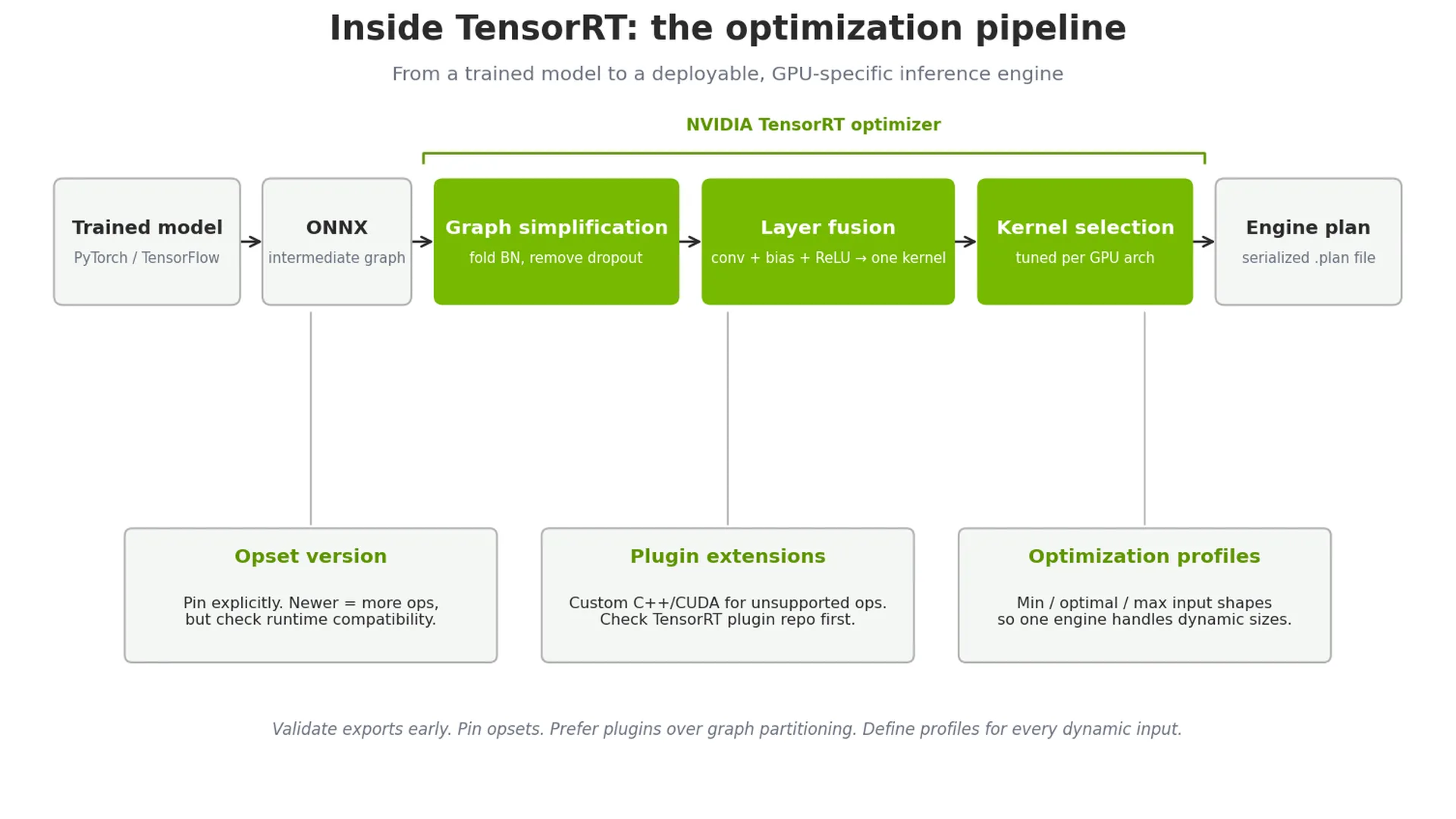
Hầu hết các đội ngũ đều huấn luyện mô hình trên PyTorch hoặc TensorFlow, sau đó xuất sang định dạng ONNX như một dạng biểu diễn trung gian (intermediate representation) trước khi tối ưu hóa bằng NVIDIA TensorRT. Bước chuyển đổi này chính là nơi phát sinh nhiều vấn đề: luồng điều khiển động không được hỗ trợ (unsupported dynamic control flow), các toán tử thiếu phần tương đương trong ONNX, và sự không khớp về hình dạng tensor (tensor shape mismatches) giữa những gì framework huấn luyện tạo ra và những gì công cụ export kỳ vọng.
Best Practice 1: Xác thực việc xuất mô hình sớm và thường xuyên (Validate exports early and often). Hãy tích hợp quy trình xác thực xuất mô hình vào workflow CI/CD của bạn để mọi checkpoint mô hình đều được kiểm tra khả năng export. Cách tiếp cận này giúp phát hiện sớm các quyết định thiết kế kiến trúc có vấn đề trước khi chúng bám sâu vào codebase của bạn.
Best Practice 2: Sử dụng các phiên bản tập toán tử ONNX (ONNX operator sets) một cách có chủ đích. ONNX hỗ trợ nhiều phiên bản tập toán tử (opset). Các opset mới hơn hỗ trợ nhiều toán tử hơn nhưng có thể không tương thích với các bộ runtime cũ hơn. Hãy cố định (pin) phiên bản opset một cách rõ ràng và ghi chú lại lý do. Khi nâng cấp, hãy kiểm thử kỹ lưỡng với bộ runtime suy luận đích.
Best Practice 3: Đơn giản hóa đồ thị mô hình (model graph) trước khi xuất. Hãy loại bỏ các thành phần chỉ dùng cho huấn luyện như các tầng dropout, auxiliary loss heads và các đoạn hook để debug. Sử dụng các lượt tối ưu hóa đồ thị (graph optimization passes) để gộp batch normalization (fold batch normalization) và loại bỏ các toán tử thừa. Một đồ thị sạch hơn sẽ giúp xuất mô hình tin cậy hơn và chạy nhanh hơn.
TensorRT cung cấp tính năng tối ưu hóa đồ thị tích hợp sẵn, tự động xử lý nhiều bước chuyển đổi trong số này, bao gồm việc nén các tầng (fusing layers), lựa chọn các kernel tối ưu cho từng dòng GPU cụ thể của bạn và loại bỏ việc sao chép bộ nhớ (memory copies) không cần thiết.
Cách xử lý các toán tử không được hỗ trợ (Unsupported Operations)
Ngay cả khi áp dụng các quy trình xuất mô hình cẩn thận, đôi khi bạn vẫn sẽ gặp phải một toán tử mà bộ runtime đích không hỗ trợ gốc (natively support). Điều này đặc biệt phổ biến đối với các kiến trúc tiên tiến (cutting-edge) mới ra mắt, vốn thường giới thiệu các cơ chế attention mới lạ, các hàm kích hoạt tùy biến (custom activation functions) hoặc các tầng chuẩn hóa chuyên biệt (specialized normalization layers). Nếu không có sự can thiệp, TensorRT sẽ chuyển sang một đường thực thi chậm hơn (fallback) hoặc hoàn toàn thất bại khi build engine.
Best Practice 4: Sử dụng các phần mở rộng TensorRT plugin cho các toán tử không được hỗ trợ. Các plugin cho phép bạn viết các triển khai tùy biến bằng C++ hoặc CUDA để tích hợp trực tiếp vào pipeline tối ưu hóa, từ đó được hưởng lợi từ việc lựa chọn kernel và tối ưu hóa bộ nhớ giống như các toán tử tích hợp sẵn. Cách này tối ưu hơn nhiều so với việc phân tách đồ thị (graph partitioning) – phương pháp vốn làm phát sinh việc sao chép bộ nhớ giữa các bộ runtime và ngăn cản các hoạt động tối ưu hóa liên tầng (cross-layer optimizations).
Best Practice 5: Kiểm tra kho lưu trữ TensorRT plugin trước khi tự viết code. NVIDIA duy trì một kho lưu trữ các plugin (plugin repository), và các đóng góp từ cộng đồng liên tục mở rộng kho lưu trữ này.
Best Practice 6: Thiết kế mô hình với tư duy hướng triển khai (Design models with deployment in mind). Khi lựa chọn kiến trúc mô hình, hãy đánh giá sớm chi phí triển khai của các toán tử “lạ” (exotic operations). Đôi khi, một toán tử có chức năng tương đương nhưng được hỗ trợ tốt hơn đã có sẵn, và việc chọn nó sẽ giúp tiết kiệm hàng tuần trời làm việc của đội ngũ kỹ sư.
Cách quản lý kích thước đầu vào động (Dynamic Input Sizes)
Nhiều ứng dụng AI phải xử lý các đầu vào có kích thước thay đổi liên tục: các câu có độ dài khác nhau, hình ảnh ở các độ phân giải khác nhau, hoặc kích thước batch (batch sizes) biến động theo lưu lượng traffic. Nếu một TensorRT engine được build cho một cấu hình hình dạng cố định (fixed input shape), bất kỳ sự thay đổi nào cũng sẽ đòi hỏi phải đệm thêm dữ liệu trống (padding – gây lãng phí tính toán), thay đổi kích thước (resizing – có khả năng làm thay đổi hành vi mô hình), hoặc phải build lại engine (rất tốn kém và chậm).
Best Practice 7: Định nghĩa các cấu hình đầu vào động (dynamic input profiles) trong TensorRT. Các hồ sơ tối ưu hóa (optimization profiles) chỉ định các kích thước tối thiểu (minimum), tối ưu (optimal) và tối đa (maximum) cho mỗi tensor đầu vào, tạo ra một engine duy nhất có thể xử lý nhiều dải kích thước khác nhau mà không cần biên dịch lại. Ví dụ, đối với hình ảnh có kích thước từ 224×224 đến 1024×1024, bạn hãy định nghĩa một profile với các ranh giới đó và một kích thước tối ưu trùng với độ phân giải phổ biến nhất của bạn.
Best Practice 8: Sử dụng nhiều optimization profiles cho các mẫu khối lượng công việc (workload patterns) khác biệt. Nếu ứng dụng của bạn phục vụ các mẫu đầu vào khác nhau hoàn toàn vào các thời điểm khác nhau, chẳng hạn như suy luận ảnh đơn (single-image) khi ít traffic và suy luận batch lớn (large-batch) trong giờ cao điểm, hãy định nghĩa các profile riêng biệt cho từng trường hợp. TensorRT sẽ chuyển đổi giữa các cấu hình này trong quá trình runtime với chi phí tài nguyên (overhead) cực kỳ nhỏ.
Best Practice 9: Đánh giá hiệu năng (Benchmark) trên toàn bộ dải đầu vào của bạn. Sử dụng công cụ trtexec để đo lường độ trễ (latency) và băng thông xử lý (throughput) trên các kích thước tối thiểu, tối ưu và tối đa. Điều này giúp phát hiện ra các “vách đá hiệu năng” (performance cliffs) – nơi engine chuyển đổi giữa các triển khai kernel khác nhau.
Cách ngăn ngừa bất đồng bộ phiên bản (Version Mismatches)
Bất đồng bộ phiên bản (version mismatches) là một trong những nguồn gây ra lực cản nguy hiểm và khó chịu nhất (insidious sources), bởi vì chúng thường không đưa ra bất kỳ thông báo lỗi nào. Mô hình có thể vẫn chạy nhưng với độ chính xác bị giảm sút, hoặc bộ runtime có thể tự động chuyển sang một đường code chậm hơn (fallback) mà không có cảnh báo. Những lỗi ngầm (silent failures) này có thể tồn tại hàng tháng trời mà không bị phát hiện.
Ma trận phiên bản trong một stack triển khai điển hình là rất phức tạp: framework huấn luyện, công cụ xuất ONNX, TensorRT, CUDA Toolkit, cuDNN, GPU driver và hệ điều hành. Sự không tương thích giữa bất kỳ hai thành phần nào trong số này đều có thể gây ra sự cố.
Best Practice 10: Cố định và ghi chép lại toàn bộ stack phụ thuộc (dependency stack) của bạn. Hãy tạo một bản kê khai phiên bản (version manifest) liệt kê mọi thành phần với số phiên bản chính xác của nó, sau đó lưu trữ nó cùng với các artifact của mô hình.
Best Practice 11: Sử dụng container để đảm bảo tính tái lập (reproducibility). Các container từ NVIDIA NGC được đóng gói sẵn các phiên bản tương thích của TensorRT, CUDA, cuDNN và các framework phổ biến, giúp loại bỏ các vấn đề bất đồng bộ phổ biến nhất trong các môi trường phát triển (development), kiểm thử (testing) và production.
Best Practice 12: Kiểm thử việc nâng cấp một cách cô lập. Chỉ thay đổi một thành phần duy nhất tại một thời điểm và chạy toàn bộ bộ test suite trước khi tiếp tục nâng cấp các thành phần khác.
Bây giờ, sau khi đã đi qua 4 danh mục chính, các phần tiếp theo sẽ khám phá thêm một vài cách nữa để giảm thiểu lực cản quy trình.
Cách đo kiểm hiệu năng (Profile) và gỡ lỗi (Debug) pipeline của bạn
Ngay cả một pipeline có vẻ như không có lực cản vẫn có thể tiềm ẩn các vấn đề về hiệu năng bên dưới bề mặt. Do đó, việc đo kiểm hiệu năng (profiling) một cách hiệu quả là vô cùng thiết yếu.
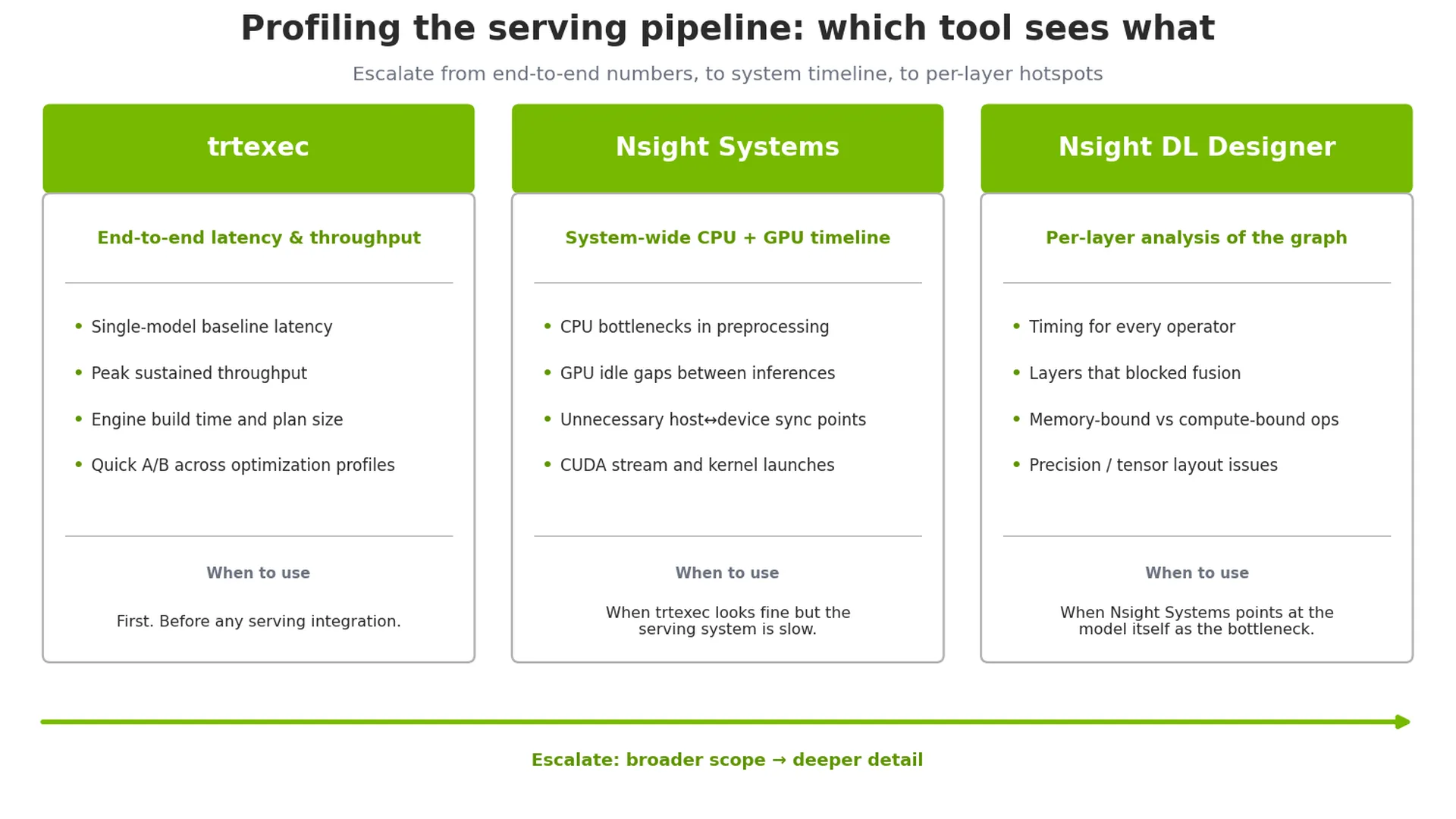
Best Practice 13: Sử dụng công cụ dòng lệnh trtexec của TensorRT để đo lường hiệu năng cơ sở (baseline performance). Hãy chạy mô hình của bạn một cách độc lập để thiết lập độ trễ và băng thông cơ sở trước khi tích hợp vào một hệ thống serving. Nếu hiệu năng ở bước này không đạt kỳ vọng, vấn đề nằm ở chính mô hình hoặc cấu hình của engine.
Best Practice 14: Đo kiểm với NVIDIA Nsight Deep Learning Designer để phân tích ở cấp độ tầng (layer-level analysis). Công cụ này cung cấp thông tin chi tiết về thời gian thực thi của từng toán tử trong đồ thị mô hình, giúp bạn dễ dàng phát hiện các nút thắt cổ chai (bottlenecks) như các toán tử bị giới hạn bởi bộ nhớ (memory-bound operations), bố cục dữ liệu không hiệu quả (inefficient data layouts) hoặc các toán tử ngăn cản việc nén tầng (fusion).
Best Practice 15: Sử dụng NVIDIA Nsight Systems để đo kiểm ở cấp độ hệ thống (system-level profiling). Nsight Systems trực quan hóa hoạt động của CPU và GPU trên một dòng thời gian thống nhất (unified timeline), giúp vạch trần các nút thắt cổ chai của CPU trong quá trình tiền xử lý (preprocessing), các điểm đồng bộ hóa không cần thiết và thời gian GPU nhàn rỗi (idle time) giữa các lệnh gọi suy luận. Điều này vô cùng quan trọng để tối ưu hóa băng thông tổng thể (end-to-end throughput), thay vì chỉ tập trung vào độ trễ suy luận của riêng mô hình.
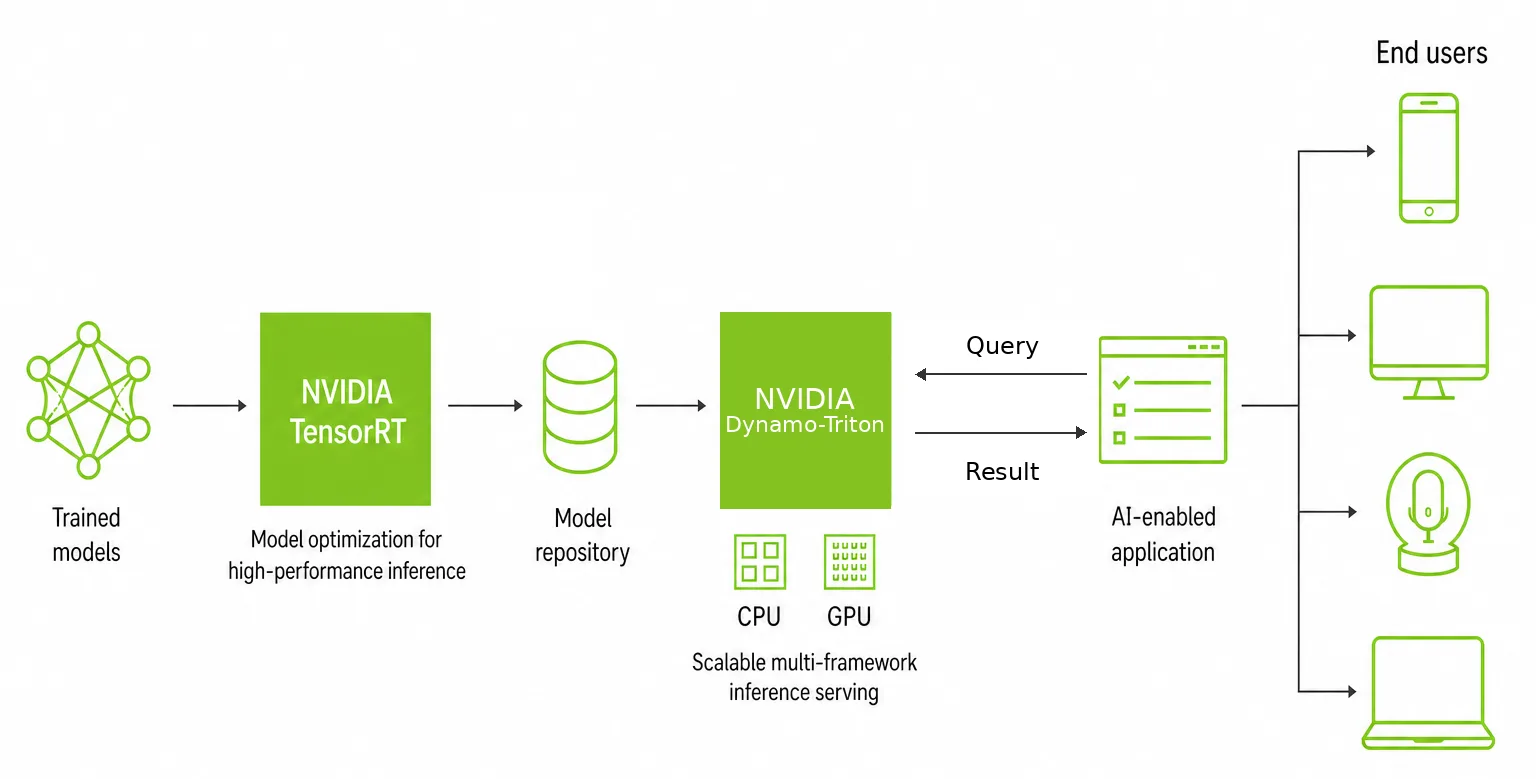
Cách tích hợp TensorRT với Dynamo-Triton
Tối ưu hóa một mô hình mới chỉ là một nửa chặng đường. Trên môi trường production, bạn cần xử lý các request đồng thời (concurrent requests), quản lý các phiên bản mô hình, cân bằng tải giữa các GPU và duy trì tính sẵn sàng cao (high availability). NVIDIA Dynamo-Triton (trước đây là NVIDIA Triton Inference Server) là một nền tảng phục vụ (serving platform) mã nguồn mở hỗ trợ gốc các engine TensorRT bên cạnh các framework khác, tạo nên một stack sẵn sàng cho production.
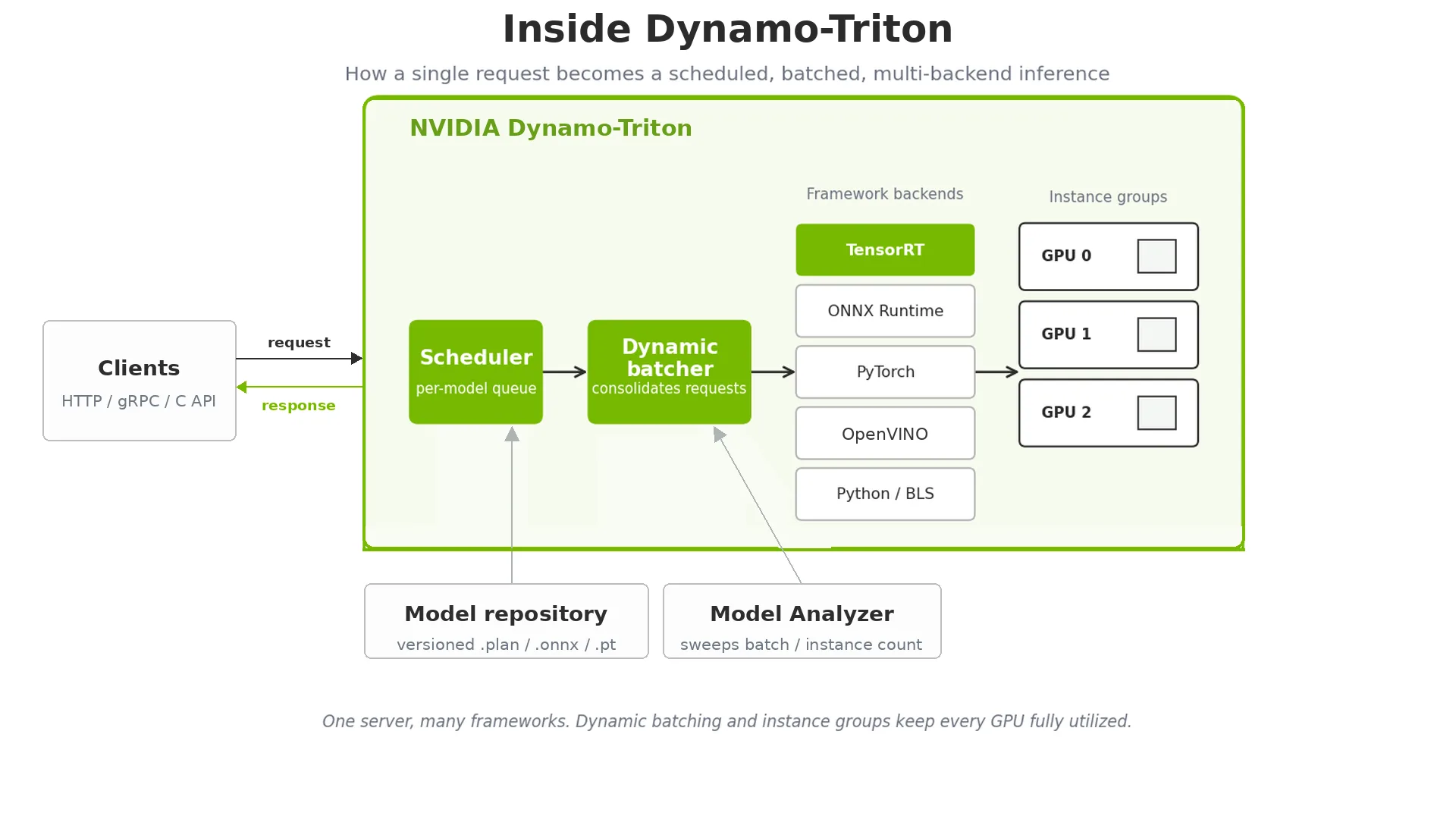
Best Practice 16: Cấu hình tính năng gom cụm động (dynamic batching) trong Dynamo-Triton khớp với các TensorRT profiles của bạn. Hãy thiết lập kích thước batch tối đa (maximum batch size) trong Dynamo-Triton sao cho khớp với chiều batch tối đa trong các optimization profiles của bạn, từ đó các request được gom cụm động sẽ luôn nằm trong dải kích thước đã được tối ưu.
Best Practice 17: Sử dụng Dynamo-Triton Model Analyzer để tìm cấu hình tối ưu. Công cụ này kiểm thử một cách có hệ thống các tổ hợp của kích thước batch, số lượng instance và mức độ đồng thời (concurrency levels) để tối đa hóa băng thông xử lý trong khi vẫn đáp ứng các yêu cầu về độ trễ.
Best Practice 18: Triển khai quản lý phiên bản mô hình (model versioning) thông qua kho lưu trữ mô hình (model repository) của Dynamo-Triton. Dynamo-Triton có thể phục vụ đồng thời nhiều phiên bản khác nhau, cho phép triển khai canary (canary deployments) và tung ra tính năng dần dần (gradual rollouts). Hãy kết hợp tính năng này với bản kê khai phiên bản (version manifest) của bạn để đảm bảo tính tương thích.
Thêm các mẹo để xây dựng một pipeline không có lực cản
Để loại bỏ lực cản quy trình, bạn cần đưa các thực hành này vào workflow hằng ngày của mình nhằm ngăn chặn việc tích tụ lỗi. Hãy tạo một danh mục kiểm tra triển khai (deployment checklist) bao gồm việc xác thực xuất mô hình, đo kiểm hiệu năng (performance benchmarking), tính tương thích phiên bản và cấu hình production. Hãy tự động hóa danh mục này thông qua các pipeline CI/CD.
Hãy đầu tư vào hệ thống giám sát (monitoring) để phát hiện sự sụt giảm hiệu năng (regressions) trên môi trường production. Theo dõi sát sao độ trễ suy luận, băng thông, mức độ sử dụng GPU (GPU utilization) và độ chính xác của mô hình. Khi bất kỳ chỉ số nào lệch khỏi mức cơ sở (baseline), hãy tiến hành điều tra ngay lập tức.
Thúc đẩy sự giao tiếp và gắn kết giữa đội ngũ huấn luyện (training) và đội ngũ triển khai (deployment). Nhiều nguồn gây ra lực cản bắt nguồn từ các quyết định về kiến trúc trong quá trình huấn luyện mà không lường trước được hệ quả khi triển khai. Sự cộng tác sớm sẽ giúp các đội ngũ đưa ra các quyết định và sự đánh đổi (trade-offs) sáng suốt hơn.
Bắt đầu hành trình loại bỏ lực cản quy trình
Lực cản trong pipeline triển khai mô hình AI hoàn toàn là một bài toán có thể giải quyết được. TensorRT mang đến khả năng tối ưu hóa mạnh mẽ với các profile đầu vào động và các phần mở rộng plugin. Các công cụ đo kiểm hiệu năng như trtexec, Nsight Deep Learning Designer và Nsight Systems đem lại khả năng hiển thị chi tiết (visibility) vào từng tầng của mô hình. Trong khi đó, Dynamo-Triton đảm nhận vai trò phục vụ trên production và quản lý lưu lượng traffic.
Chìa khóa ở đây là áp dụng các công cụ này một cách có hệ thống. Hãy xác thực việc xuất mô hình sớm, thiết kế mô hình hướng triển khai, quản lý phiên bản cẩn thận, đo kiểm hiệu năng kỹ lưỡng và giám sát liên tục. Thành quả đạt được sẽ là tốc độ lặp lại chu kỳ phát triển (iteration) nhanh hơn, tối ưu hóa việc sử dụng tài nguyên hiệu quả và mang lại hiệu năng nhất quán cho người dùng cuối.
TensorRT và Dynamo-Triton hoàn toàn là mã nguồn mở trên các kho lưu trữ GitHub NVIDIA/TensorRT và triton-inference-server/server. TensorRT được viết bằng C++ với các API hỗ trợ C++ và Python; Dynamo-Triton cung cấp các thư viện client (client libraries) bằng C++, Python và Java.
Cả hai đều được hỗ trợ trên Linux (Ubuntu, RHEL), riêng TensorRT có hỗ trợ thêm Windows. Con đường nhanh nhất để có được một môi trường có tính tái lập cao là pull một container được build sẵn từ danh mục NGC (NGC catalog).
Để bắt đầu, hãy khám phá thư mục chứa các mẫu (samples directory) của TensorRT. Công cụ trtexec giúp build các engine từ các mô hình ONNX và đo kiểm hiệu năng. Mẫu chuyển đổi từ ONNX sang TensorRT sẽ hướng dẫn chi tiết về xác thực xuất mô hình, cấu hình các optimization profiles và các phần mở rộng plugin. Hãy tham khảo thêm tài liệu Dynamo-Triton Quickstart để biết chi tiết về kho lưu trữ mô hình (model repositories), gom cụm động (dynamic batching) và cách cấu hình Model Analyzer.
Bài viết liên quan