
Trong kỷ nguyên AI Agent, rào cản lớn nhất khi chuyển dịch từ trợ lý dạng văn bản (Text-based) sang giọng nói (Voice Agent) chính là độ trễ (Latency) và trải nghiệm hội thoại tự nhiên. Người dùng không muốn nói chuyện với một hệ thống mà họ phải chờ vài giây mới nhận được phản hồi, hoặc không thể ngắt lời khi AI đang nói sai hướng.
Để giải quyết triệt để bài toán này, giải pháp kiến trúc Speech-to-Speech Streaming Pipeline dựa trên tiêu chuẩn NVIDIA Blueprint dưới đây sẽ cung cấp một khung thiết kế mẫu mực cho doanh nghiệp. Giải pháp này tập trung tối ưu hóa độ trễ cảm nhận xuống mức dưới một giây (sub-second), mang lại trải nghiệm giao tiếp tự nhiên như người với người.
Lưu ý định vị giải pháp: Đây là kiến trúc tối ưu hóa cho Voice Runtime thời gian thực, không phải là một chatbot RAG tra cứu tài liệu truyền thống. Hệ thống tập trung vào luồng xử lý âm thanh tốc độ cao và không tích hợp sẵn Vector DB hay hệ thống Feedback loop lưu dữ liệu ở backend.
1. Sơ Đồ Kiến Trúc Luồng Dữ Liệu Thời Gian Thực (Streaming Pipeline)
Hệ thống được thiết kế theo mô hình hướng sự kiện (Event-driven Pipeline), gộp chuỗi liên hoàn ASR $\rightarrow$ LLM $\rightarrow$ TTS thành một dòng chảy dữ liệu liên tục thay vì xử lý theo kiểu Request/Response thông thường:
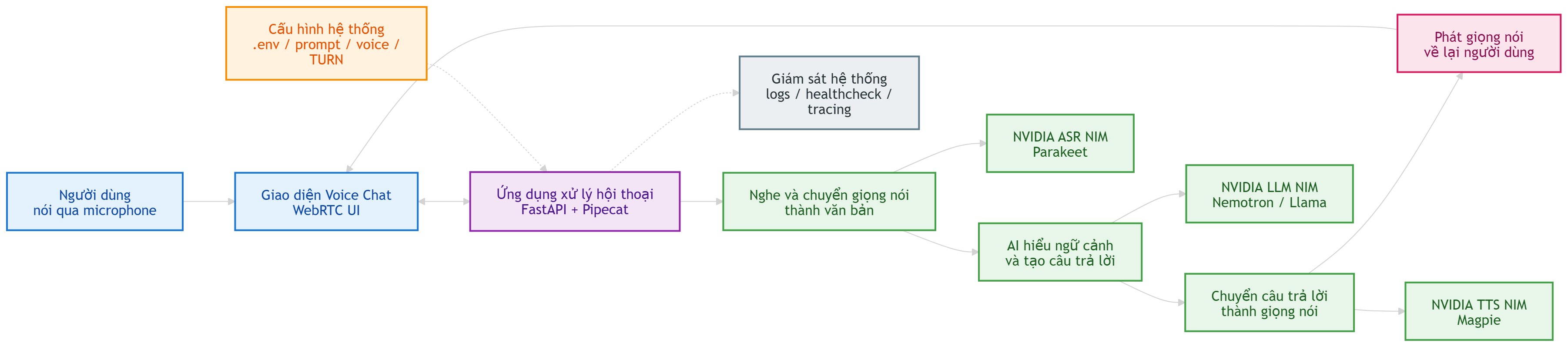
(Chi tiết luồng vận hành microservices từ Frontend đến các container suy luận chuyên dụng)
Các thành phần cốt lõi trong giải pháp:
- Người dùng & Voice UI: Người dùng nói qua microphone, giao diện WebRTC nhận và phát âm thanh theo thời gian thực.
- Ứng dụng FastAPI + Pipecat: Trung tâm điều phối luồng thoại, nhận âm thanh, xử lý hội thoại và trả âm thanh về lại UI.
- ASR: Chuyển giọng nói của người dùng thành văn bản để AI có thể hiểu.
- LLM: Hiểu nội dung người dùng vừa nói, giữ ngữ cảnh hội thoại và tạo câu trả lời.
- TTS: Chuyển câu trả lời dạng văn bản của AI thành giọng nói.
- NVIDIA NIM: Cung cấp các model xử lý AI phía sau, gồm ASR, LLM và TTS.
- Configuration: Chứa các thiết lập như API key, prompt, giọng nói và cấu hình mạng.
- Observability: Theo dõi log, trạng thái service và tracing để kiểm tra hệ thống khi chạy.
2. Kỹ Thuật Tối Ưu Độ Trễ (Latency Engineering)
Điểm ăn tiền của giải pháp này nằm ở các cơ chế tối ưu hóa trải nghiệm hội thoại, giúp xóa bỏ cảm giác “chờ đợi” của người dùng:
-
Speculative Speech (Nói đoán đầu): Khi được kích hoạt (
ENABLE_SPECULATIVE_SPEECH=true), Context Aggregator sẽ gửi các bản dịch tạm thời (Interim Transcript) từ giọng nói sang chữ cho LLM xử lý sớm hơn, kết hợp với bộNvidiaTTSResponseCacherđể điều phối thời gian phát âm thanh. Kỹ thuật này giúp giảm độ trễ cảm nhận xuống chỉ còn khoảng ~300ms. -
Hội thoại có khả năng ngắt lời (Barge-in / Interruption): Hệ thống tích hợp bộ lọc âm thanh và cơ chế đồng bộ hóa transcript. Người dùng hoàn toàn có thể nói chen ngang khi bot đang phát âm thanh, hệ thống sẽ tự động ngắt luồng đầu ra của TTS ngay lập tức để tiếp thu câu nói mới.
-
Tuning Knobs thực chiến: Giải pháp cho phép can thiệp sâu vào các tham số vận hành phần cứng như
AUDIO_OUT_10MS_CHUNKS(kích thước chunk âm thanh xuất ra), giới hạn lịch sử chat (CHAT_HISTORY_LIMIT) và cấu hình bộ lọc giọng nói VAD (VAD_PROFILE).
3. Bộ Model Đầu Não Đứng Sau Giải Pháp
Để đảm bảo tốc độ streaming, danh mục các mô hình sử dụng đều được tối ưu hóa qua các container chuyên dụng (NVIDIA NIM):
| Nhiệm vụ | Tên Model mặc định | Đặc trưng kỹ thuật |
| ASR (Dịch giọng nói) | parakeet-1.1b-en-US-asr-streaming... |
Mô hình Parakeet 1.1B CTC hỗ trợ streaming và tích hợp sẵn tính năng nhận diện khoảng lặng Silero VAD. |
| LLM (Suy luận nghiệp vụ) | nvidia/nemotron-3-nano |
Model nhỏ, tốc độ sinh token cực nhanh, đóng vai trò sinh phản hồi text thô dựa trên file cấu hình kịch bản prompt.yaml. |
| TTS (Tổng hợp giọng nói) | magpie_tts_ensemble-Magpie-Multilingual |
Dòng Magpie hỗ trợ đa ngôn ngữ, cho phép can thiệp cách phát âm qua file từ điển custom ipa.json. |
4. Hướng Dẫn Triển Khai Nhanh Cụm Giải Pháp (Quick Start)
Giải pháp hỗ trợ đóng gói hoàn chỉnh bằng Docker Compose giúp bạn dựng nhanh toàn bộ môi trường và các container NIM nội bộ:
# 1. Tải bộ khung giải pháp và cập nhật các submodule liên quan
git clone git@github.com:NVIDIA-AI-Blueprints/nemotron-voice-agent.git
cd nemotron-voice-agent
git submodule update --init
# 2. Thiết lập cấu hình môi trường từ file mẫu
cp config/env.example .env
export NVIDIA_API_KEY=<your-nvidia-api-key>
export NGC_API_KEY=<your-nvidia-api-key>
# 3. Đăng nhập và khởi động cụm microservices trên hạ tầng GPU
docker login nvcr.io
docker compose up -d
-
Kiểm tra trạng thái: Chạy lệnh
docker compose psđể đảm bảo cả 5 service (asr-service,tts-service,nvidia-llm,python-app,ui-app) đều ở trạng thái khỏe mạnh (healthy). -
Truy cập giao diện: Mở trình duyệt tại địa chỉ
http://<machine-ip>:9000/. -
Mẹo nhỏ: Đối với các kết nối HTTP từ xa (Remote IP), bạn cần bật cờ
Insecure origins treated as securetrongchrome://flags/của trình duyệt Chrome để cho phép UI truy cập vào Microphone.
5. Những Mảnh Ghép Cần Hardening Khi Lên Production
Vì đây là một giải pháp tập trung vào Voice Runtime tối ưu độ trễ, khi đưa vào vận hành thực tế trong môi trường Enterprise, các kỹ sư hệ thống cần chủ động xây dựng thêm các module bảo vệ sau:
-
Hệ thống Thu Thập Feedback & Consent: Bản thân giải pháp không tích hợp sẵn giao diện Like/Dislike hay API backend để lưu điểm đánh giá cuộc gọi. Bạn cần xây dựng một tầng thu thập dữ liệu riêng (có sự đồng ý của người dùng) nếu muốn tạo vòng lặp cải tiến mô hình (Data Flywheel).
-
Bảo mật mạng và WebRTC: Khi deploy trên hạ tầng cloud hoặc mạng ngoài, luồng WebRTC có thể bị chặn bởi tường lửa. Cần bổ sung cấu hình TURN Server qua các biến
TURN_SERVER_URL,TURN_USERNAMEđể điều hướng stream audio ổn định. -
Hạ tầng Giám sát nâng cao: Giải pháp đã tích hợp sẵn OpenTelemetry spans. Anh em có thể trỏ biến
OTEL_EXPORTER_OTLP_ENDPOINTvề một cụm Arize Phoenix hoặc hệ thống quan trắc nội bộ để theo dõi trực quan các chỉ số chất lượng âm thanh và độ trễ của từng lượt thoại.
Bài viết liên quan
- Cách đánh giá các chính sách Robot đa năng cho triển khai thực tế
- Xác suất xảy ra các sự kiện cực đoan với các mô hình tạo sinh được hướng dẫn
- Triển khai NVIDIA Cosmos 3 sau huấn luyện trong một ngày bằng Kỹ năng Agent
- NVIDIA Ising Decoding giảm tỷ lệ lỗi Logic mã màu hơn 300 lần
- Xây dựng Ứng dụng Theo dõi 3D Đa Camera với Kỹ năng NVIDIA DeepStream 9.1
- Nâng cao hiệu suất trong huấn luyện LLM quy mô lớn bằng cách sử dụng song song tensor không đồng nhất