Chương đầu tiên bùng nổ của Trí tuệ nhân tạo tạo sinh được định hình bởi việc con người gửi yêu cầu và các mô hình phản hồi. Chương về trí tuệ nhân tạo có tính tác nhân thì khác.
Các tác nhân không tuân theo một trình tự hành động được xác định trước. Chúng gọi các công cụ, tạo ra các tác nhân phụ với các nhiệm vụ và mô hình khác nhau, lưu trữ thông tin trong bộ nhớ, quản lý cửa sổ ngữ cảnh của riêng chúng và tự quyết định khi nào chúng hoàn thành. Khi làm như vậy, các hệ thống này đẩy mức tiêu thụ token, độ dài ngữ cảnh và yêu cầu độ trễ vào các vùng cực kỳ khắt khe — chính xác là những áp lực hiện đang định hình ngăn xếp đồng thiết kế cực mạnh của NVIDIA và nền tảng NVIDIA Vera Rubin.
Bài viết này phân tích sự tiến hóa đó qua ba phần:
- Cách các tác nhân sử dụng token
- Vì sao nền kinh tế của họ sụp đổ dưới hình thức phục vụ thông thường?
- Cấu trúc hạ tầng được xây dựng riêng cho các tác nhân trông như thế nào?
Chuyển đổi từ chatbot sang agent
Như thể hiện trong Hình 1 bên dưới, sự phổ biến của trí tuệ nhân tạo tạo sinh bắt đầu với một mô hình tương tác đơn giản: một tin nhắn của người dùng, một tin nhắn của chatbot, lặp lại. Mô hình phản hồi từ bộ nhớ trong cửa sổ ngữ cảnh, lịch sử trò chuyện tăng lên theo tuyến tính và các yêu cầu đối với hệ thống có thể dự đoán được.
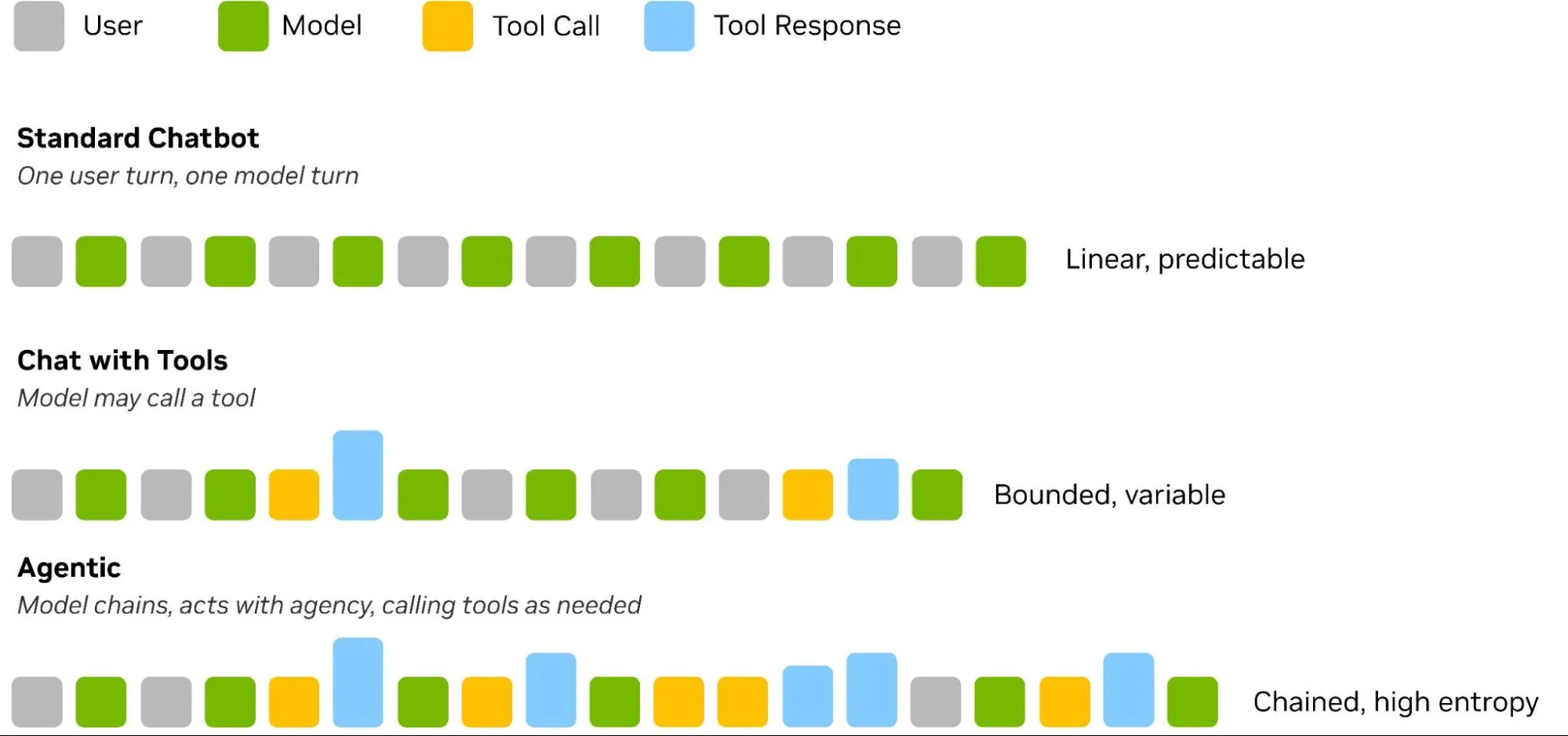
Hình 1. Ba mô hình tương tác AI được xếp hạng theo độ phức tạp: Chatbot tiêu chuẩn (tuyến tính); trò chuyện với công cụ (có giới hạn, biến đổi); và tác nhân (chuỗi, độ nhiễu cao)
Việc giới thiệu tính năng gọi công cụ đã thay đổi căn bản cách thức hoạt động của chatbot AI. Khi một mô hình có thể gọi máy tính thay vì đoán mò các phép toán, toàn bộ khối lượng công việc sẽ thay đổi. Vì phản hồi của công cụ được thêm trực tiếp vào cửa sổ ngữ cảnh, chúng tạo ra sự không thể đoán trước trong chuỗi đầu vào. Điều này xảy ra vì kích thước đầu ra của công cụ phụ thuộc vào truy vấn cụ thể và thiết kế của công cụ, bao gồm cả cách nó xử lý dữ liệu liên quan. Mặc dù quy trình vẫn bị giới hạn bởi lời nhắc và câu trả lời cuối cùng, nhưng tính dễ đoán của một cuộc trò chuyện thông thường đã bị mất đi.
Sự tương tác này trở nên phức tạp hơn nữa khi chúng ta đưa vào các tác nhân. Nếu một mô hình có khả năng gọi một công cụ, nó cũng có khả năng quyết định sử dụng bao nhiêu công cụ và theo thứ tự nào. Ví dụ, một tác nhân được giao nhiệm vụ soạn thảo email có thể:
- Đọc thư từ hiện có
- Kiểm tra ổ đĩa để biết thêm chi tiết.
- Xác nhận danh tính người nhận
- Sau đó soạn thảo email.
Chuỗi liên kết này là nơi các mô hình trở thành tác nhân, và nơi khối lượng công việc chuyển từ “có thể dự đoán tuyến tính với các đỉnh xác suất” sang “có tính xác suất về cấu trúc”, sao cho hình dạng của mỗi phiên tác nhân có thể hoạt động rất khác nhau.
Đặc điểm của kiến trúc tác nhân
Kiến trúc tác nhân hiện đại bao gồm sự kết hợp giữa hệ thống phân cấp tác nhân và các kỹ thuật tối ưu hóa, cho phép quản lý ngữ cảnh hiệu quả, sử dụng công cụ và tối ưu hóa nhiệm vụ:
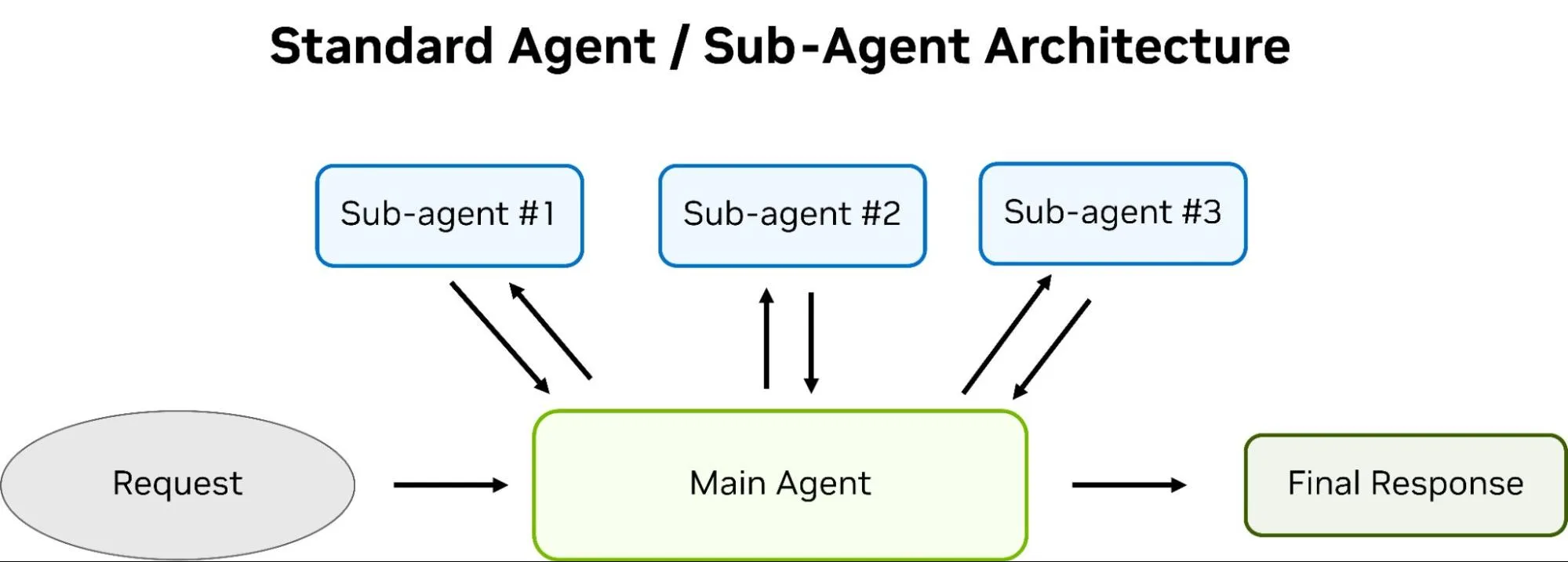
Hình 2. Sơ đồ luồng đơn giản của kiến trúc tác nhân/tác nhân con tiêu chuẩn.
- Tác nhân chính: Chịu trách nhiệm thực hiện toàn bộ nhiệm vụ từ đầu đến cuối. Có thể điều phối các tác nhân phụ để xử lý các nhiệm vụ phụ. Thông thường, tác nhân chính được hỗ trợ bởi mô hình thông minh nhất và giao tiếp trực tiếp với người dùng.
- Các tác nhân phụ: Được tác nhân chính tạo ra để xử lý các tác vụ hẹp hơn, có khả năng tự quản lý cửa sổ ngữ cảnh của chúng giống như tác nhân chính. Thông thường, các tác nhân phụ có kiến trúc giống hệt hoặc rất giống với tác nhân chính, ngoại trừ phạm vi tác vụ bị giới hạn hơn so với lời nhắc mà tác nhân chính cung cấp cho tác nhân phụ.
- Trạng thái hệ thống tập tin: Trạng thái bổ sung phát sinh từ việc các tác nhân ghi dữ liệu đầu ra từ bộ nhớ và lệnh gọi công cụ vào các tập tin, và sau đó tìm kiếm hoặc đọc lại nội dung của chúng. Điều này đóng vai trò như một phương pháp quản lý ngữ cảnh và bộ nhớ.
- Tóm tắt và thu gọn: Một kỹ thuật trong đó cửa sổ ngữ cảnh của một tác nhân được tóm tắt và thu gọn lại để tạo không gian cho thông tin mới và giảm chi phí xử lý đầu vào.
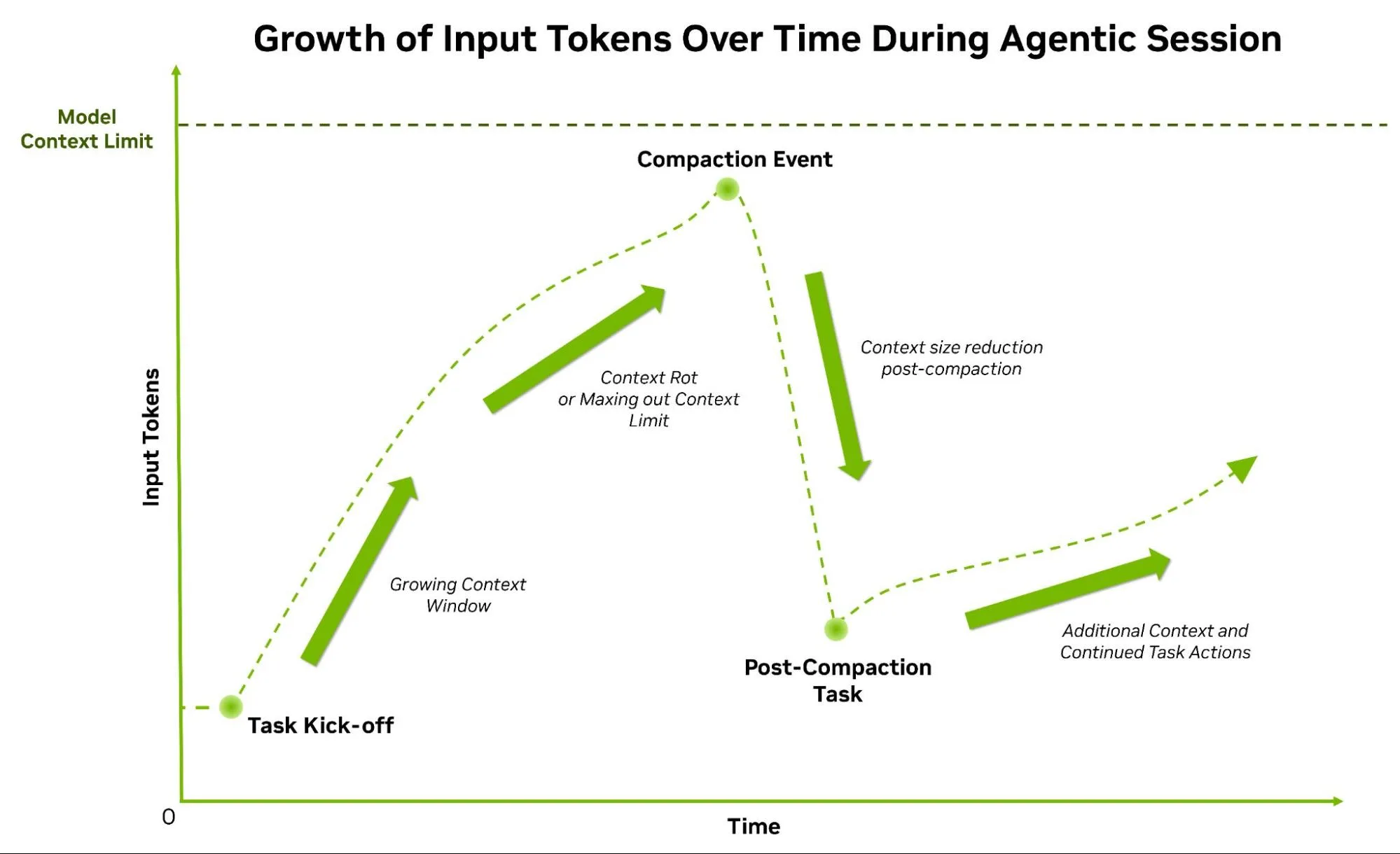
Hình 3. Đồ thị định tính đơn giản minh họa sự tăng trưởng của token đầu vào trên mỗi yêu cầu trong suốt một phiên tác nhân.
Một số công cụ dựa trên tác nhân phổ biến nhất hiện nay tuân theo các kiến trúc tương tự. Các tác nhân chính trong các công cụ như Claude Code thường ủy thác công việc cho các tác nhân phụ để tận dụng các cửa sổ ngữ cảnh nhỏ hơn và song song hóa các tác vụ. Bởi vì hệ thống phải xử lý các token đầu vào trong mỗi bước suy luận, việc sử dụng các ngữ cảnh nhỏ hơn sẽ mang lại hiệu quả cao hơn và dẫn đến chi phí xử lý token đầu vào thấp hơn. Kiến trúc này cung cấp một biện pháp phòng vệ cần thiết chống lại hiện tượng gọi là suy giảm ngữ cảnh , trong đó ngữ cảnh mở rộng chắc chắn sẽ làm giảm chất lượng đầu ra. Khi các tác vụ trở nên phức tạp hơn, các sự kiện nén có chủ đích sẽ buộc cửa sổ ngữ cảnh của tác nhân chính giảm mạnh để bù đắp cho việc không thể mở rộng tokens vô hạn.
Động lực khối lượng công việc và kinh tế của các hệ thống tác nhân
Trong báo cáo về việc xây dựng hệ thống đa tác nhân , Anthropic ước tính rằng các hệ thống này tiêu thụ lượng token nhiều hơn tới 15 lần so với các ứng dụng trò chuyện thông thường. Sự gia tăng đáng kể này đòi hỏi phải cải thiện hiệu quả kinh tế của token để các ứng dụng này có thể sinh lời về mặt kinh tế ở quy mô lớn. Giải quyết thách thức về kinh tế suy luận này đòi hỏi sự hiểu biết sâu sắc về thông lượng token ở cấp hệ thống và các yêu cầu về độ trễ chi phối kinh tế của các tác nhân.
Chi phí và độ phức tạp của các khối lượng công việc này được hiểu rõ nhất thông qua việc phân tích một phiên làm việc thực tế giữa các tác nhân. Hình 4 cung cấp một ví dụ đo lường về nhiệm vụ mã hóa Claude Code. Các đường trên biểu đồ thể hiện độ dài chuỗi đầu vào (ngữ cảnh + ISL) tại mỗi yêu cầu được thực hiện trong phiên bởi các tác nhân phụ (màu cam) và tác nhân chính (màu xám). Ngay cả trong một phiên duy nhất, dấu vết cũng cho thấy rõ tại sao dung lượng ngữ cảnh dài, khả năng lập trình bộ nhớ cache và độ trễ dự đoán được trên mỗi token lại quan trọng không kém chất lượng mô hình thô.
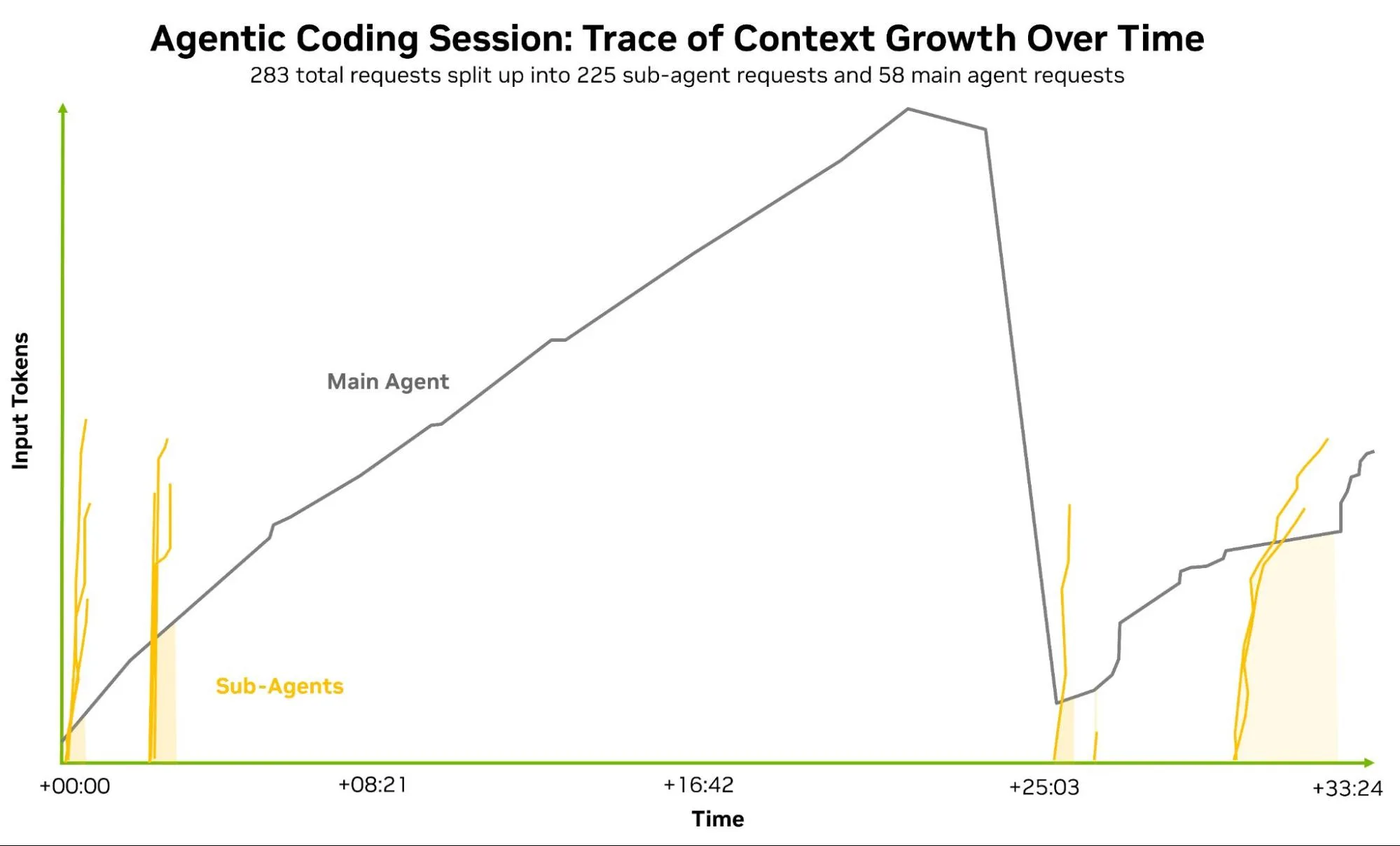
Hình 4. Đường biểu diễn sự phát triển ngữ cảnh từ một phiên lập trình tác nhân Claude Code trực tiếp trải dài 283 yêu cầu trên một tác nhân chính và các tác nhân phụ trong 33 phút.
Phiên hoạt động kéo dài 33 phút này theo dõi 58 lượt điều phối của tác nhân chính với 225 lời gọi tác nhân phụ. Trải qua 283 yêu cầu suy luận, cửa sổ ngữ cảnh tăng từ 15.000 token lên đến đỉnh điểm là 156.000 token trước khi một sự kiện nén ngữ cảnh làm giảm nó xuống còn khoảng 20.000 token. Dấu vết này cho thấy rõ ràng rằng mức tiêu thụ token của tác nhân bị ảnh hưởng bởi hành vi của hệ thống tác nhân cũng như bản chất của các nhiệm vụ.
Tác nhân chính tích lũy ngữ cảnh đầu vào nhanh chóng khi nó không ủy quyền hoặc nén ngữ cảnh, điều này khiến chi phí token đầu vào đọc bộ nhớ cache lặp lại trong mỗi lượt. Trong 40 lượt đầu tiên, tác nhân chính trung bình xử lý khoảng 85.000 token ngữ cảnh và tích lũy khoảng 3,5 triệu token đầu vào trước khi thêm một triệu token khác trong phiên sau khi nén. Đây chính xác là những điều kiện mà bộ nhớ băng thông cao (HBM), nền tảng thông lượng cao như Vera Rubin NVL72 trở nên quan trọng, bởi vì các lời nhắc ngữ cảnh dài cần phải duy trì tính khả thi về mặt kinh tế trong khi nhu cầu điền trước tiếp tục tăng lên.
Việc lưu trữ thông tin phản hồi nhanh (prompt caching) là yếu tố giúp mô hình này hoạt động hiệu quả. Nếu không có khả năng tái sử dụng bộ nhớ cache KV, mỗi token đầu vào sẽ cần được xử lý lại hoàn toàn. Các nhà cung cấp API phổ biến thường giảm giá trị cache hit khoảng 90%, vì vậy ở tỷ lệ cache hit 95%, chi phí xử lý đầu vào giảm khoảng 85%; nếu không có prompt caching, chi phí sẽ cao hơn khoảng 6 lần. Các tác nhân mã hóa thường duy trì tỷ lệ cache hit 95-98%, đặc biệt khi đầu ra của công cụ nhỏ. Đó là lý do tại sao prompt caching ngày càng trở thành vấn đề của hệ thống chứ không chỉ là một tính năng của API: Duy trì tỷ lệ cache hit cao phụ thuộc vào việc quản lý bộ nhớ cache KV hiệu quả ở phía CPU và bộ nhớ lưu trữ ngữ cảnh dung lượng cao được thiết kế riêng, chẳng hạn như NVIDIA CMX, để bảo toàn các tiền tố dài và khôi phục chúng nhanh chóng khi số lượng phiên tăng lên.
225 yêu cầu trong dấu vết của các tác nhân phụ làm nổi bật các phiên suy luận riêng biệt, mỗi phiên sử dụng các ngữ cảnh độc đáo và các định nghĩa công cụ cụ thể. Các tác nhân phụ thường làm tăng tổng khối lượng token đầu ra, nhưng chúng làm giảm chi phí đầu vào bằng cách bắt đầu từ các cửa sổ ngữ cảnh mới và chỉ chuyển tiếp những gì liên quan đến nhiệm vụ được ủy thác. Chúng cũng có thể chạy trên các mô hình nhỏ hơn, giúp giảm độ trễ và chi phí trong khi vẫn duy trì độ chính xác cho các nhiệm vụ hẹp hơn.
Việc nén ngữ cảnh cũng quan trọng không kém. Nó cung cấp một cơ chế để tránh vượt quá giới hạn cửa sổ ngữ cảnh, giảm thiểu tác động của việc ngữ cảnh bị lỗi thời và mang lại các hiệu ứng phụ về quản lý chi phí. Việc giảm cửa sổ ngữ cảnh từ 156.000 token xuống còn 20.000 token sẽ ngay lập tức giảm lượng token đầu vào được lưu trong bộ nhớ cache và tạo không gian cho tập hợp các tác vụ tiếp theo.
Hình 5 bên dưới cho thấy rõ ràng rằng hầu hết các token được xử lý đều được truy xuất từ bộ nhớ đệm. Khi điều đó xảy ra, hành vi của mạng và hệ thống bộ nhớ bắt đầu ảnh hưởng trực tiếp đến độ trễ mà người dùng cảm nhận được, và các kiến trúc mạng có độ trễ thấp như NVLink 6, ConnectX-9, BlueField-4 và Spectrum-X giúp duy trì khả năng truy cập ngữ cảnh được chia sẻ và giảm thiểu chi phí tính toán lại khi các phiên được phân tán trên nhiều tác nhân.
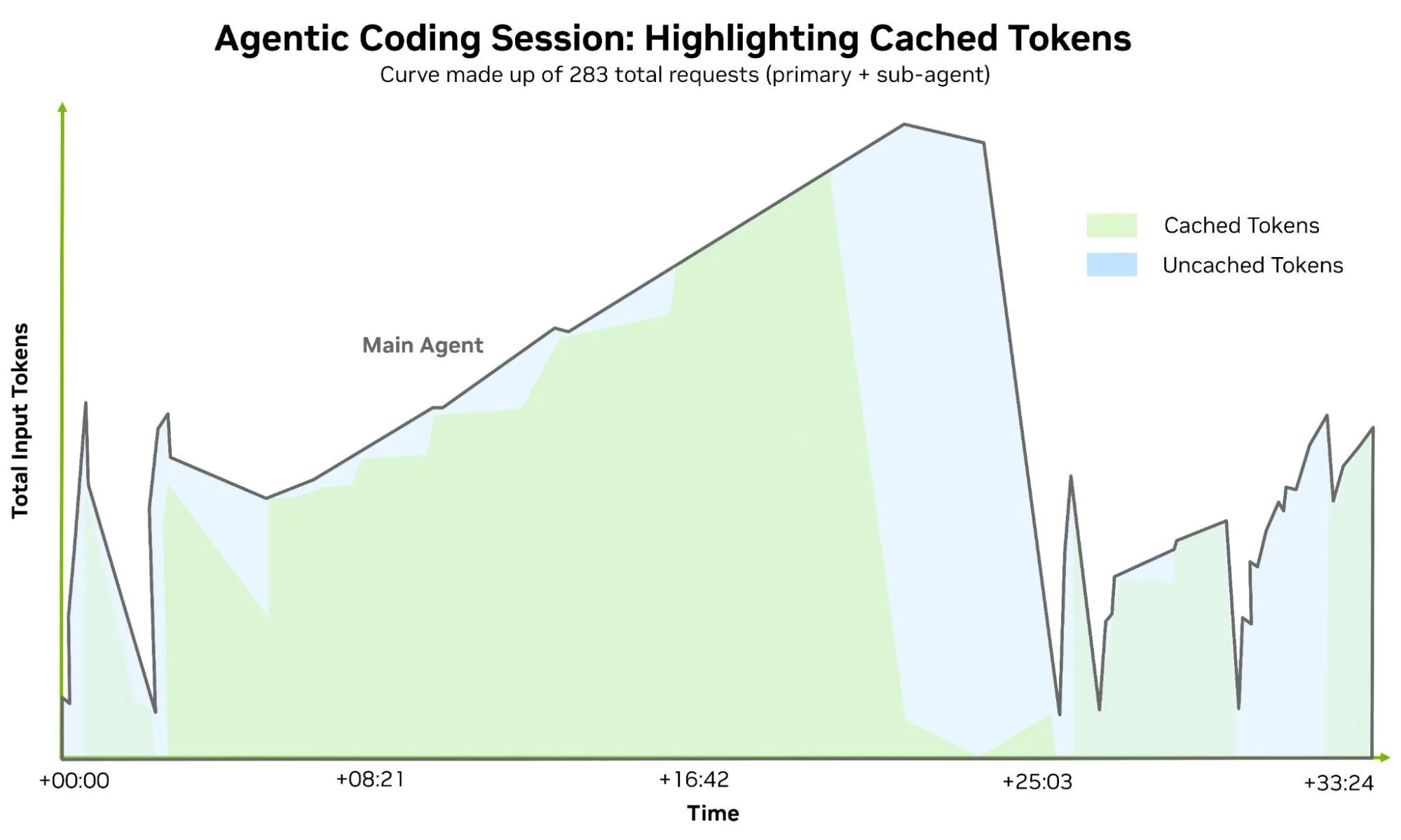
Hình 5. Bản ghi phân tích bộ nhớ đệm token từ một phiên lập trình Claude Code trực tiếp, phân biệt token đầu vào đã được lưu vào bộ nhớ đệm và chưa được lưu vào bộ nhớ đệm trong 283 yêu cầu trong 33 phút; cùng phiên với Hình 4.
Từ ví dụ này, rõ ràng là động lực của token tác nhân khá phức tạp và mức tiêu thụ token có thể nhanh chóng tăng lên giữa các tác nhân chính và tác nhân phụ. Để hiểu được những thách thức trong việc mở rộng quy mô các ứng dụng này dưới nhu cầu token ngày càng tăng, chúng ta phải xem xét các yêu cầu về hiệu năng cần đạt được.
Yêu cầu về hiệu năng của khối lượng công việc của tác nhân
Để khai thác giá trị của các tác nhân, cần có trí thông minh mô hình cao, ngữ cảnh rộng và độ trễ thấp. Các tác nhân càng nhanh chóng tạo ra thông tin chi tiết, giá trị của chúng càng tăng theo cấp số nhân. Tốc độ này rút ngắn chu kỳ nghiên cứu và phát triển, cải thiện khả năng kiểm soát hệ thống và cho phép các vòng lặp đa tác nhân phức tạp. Vì việc xử lý các token cho phép các khả năng này vốn dĩ rất tốn kém, hiệu suất được cung cấp là đòn bẩy quan trọng để làm cho các hệ thống này vừa có khả năng mở rộng vừa mang lại lợi nhuận.
Để giảm chi phí của các token này, các nhà sản xuất cần duy trì quy mô trong vùng tương tác cao đối với các mô hình lớn trên nhiều bối cảnh khác nhau. Hình 6 bên dưới minh họa điểm nghẽn này thông qua biểu đồ Pareto hiệu suất suy luận tiêu chuẩn. Phía bên trái của đường cong cho thấy thông lượng cao nhưng ở mức độ tương tác thấp hơn, nơi mà các tác vụ xử lý dữ liệu tự động không thể hoạt động.
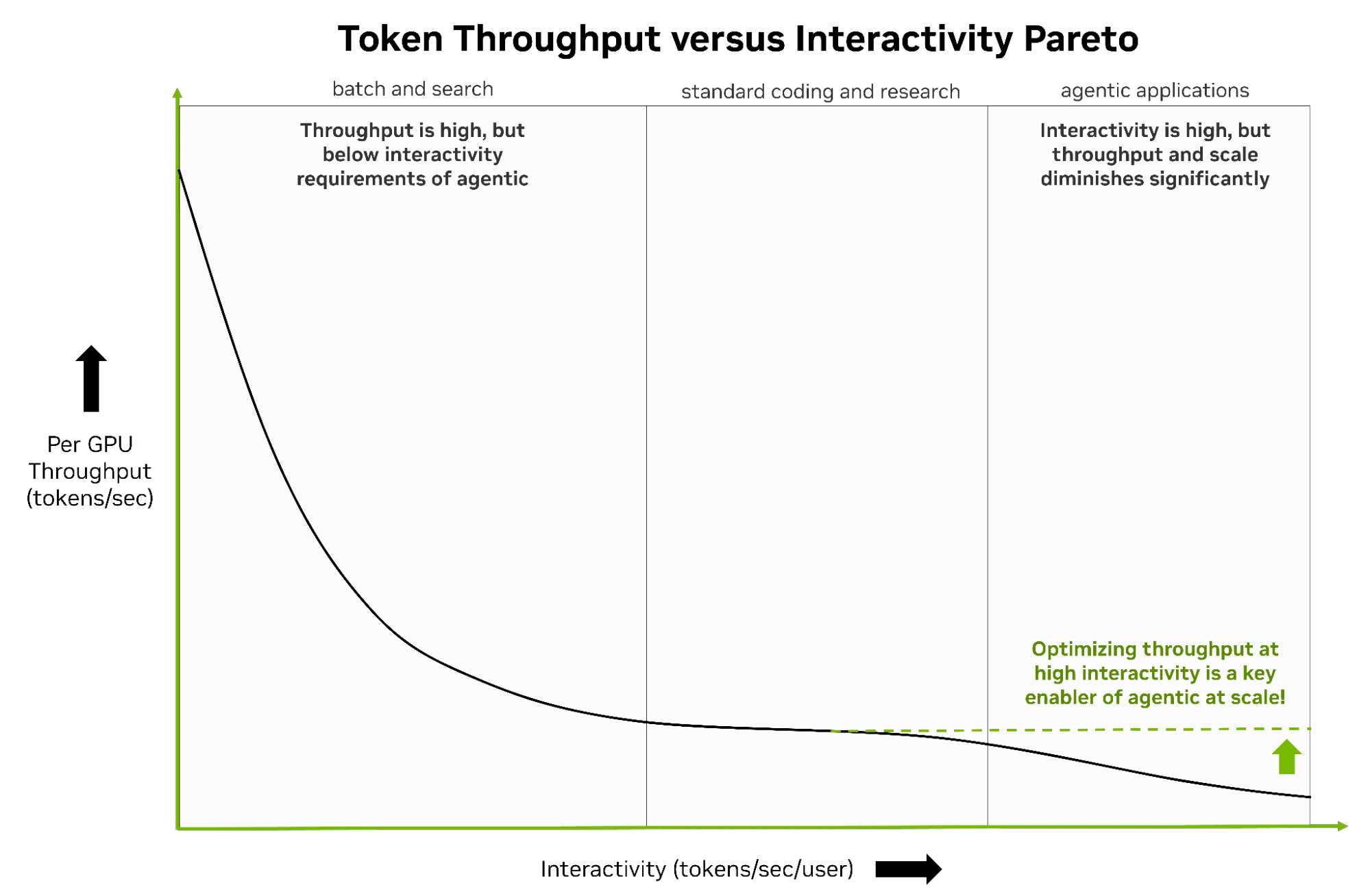
Hình 6. Đường cong Pareto định tính, minh họa sự đánh đổi giữa thông lượng và khả năng tương tác trên các khối lượng công việc xử lý theo lô, mã hóa tiêu chuẩn và ứng dụng tác nhân trên cơ sở mỗi GPU.
Thay vào đó, các khối lượng công việc này phải chuyển sang phía có tính tương tác cao hơn của đường cong (bên phải) để hoạt động thành công. Hệ thống tác nhân tiêu thụ một lượng lớn token trong khi yêu cầu tốc độ tạo nhanh để duy trì tính tương tác của người dùng cuối. Vấn đề là việc đạt được độ trễ thấp này thường khiến thông lượng hệ thống giảm mạnh. Thông lượng giảm dẫn đến chi phí trên mỗi token quá cao, khiến cho hệ thống tác nhân gặp khó khăn về mặt kinh tế khi mở rộng quy mô.
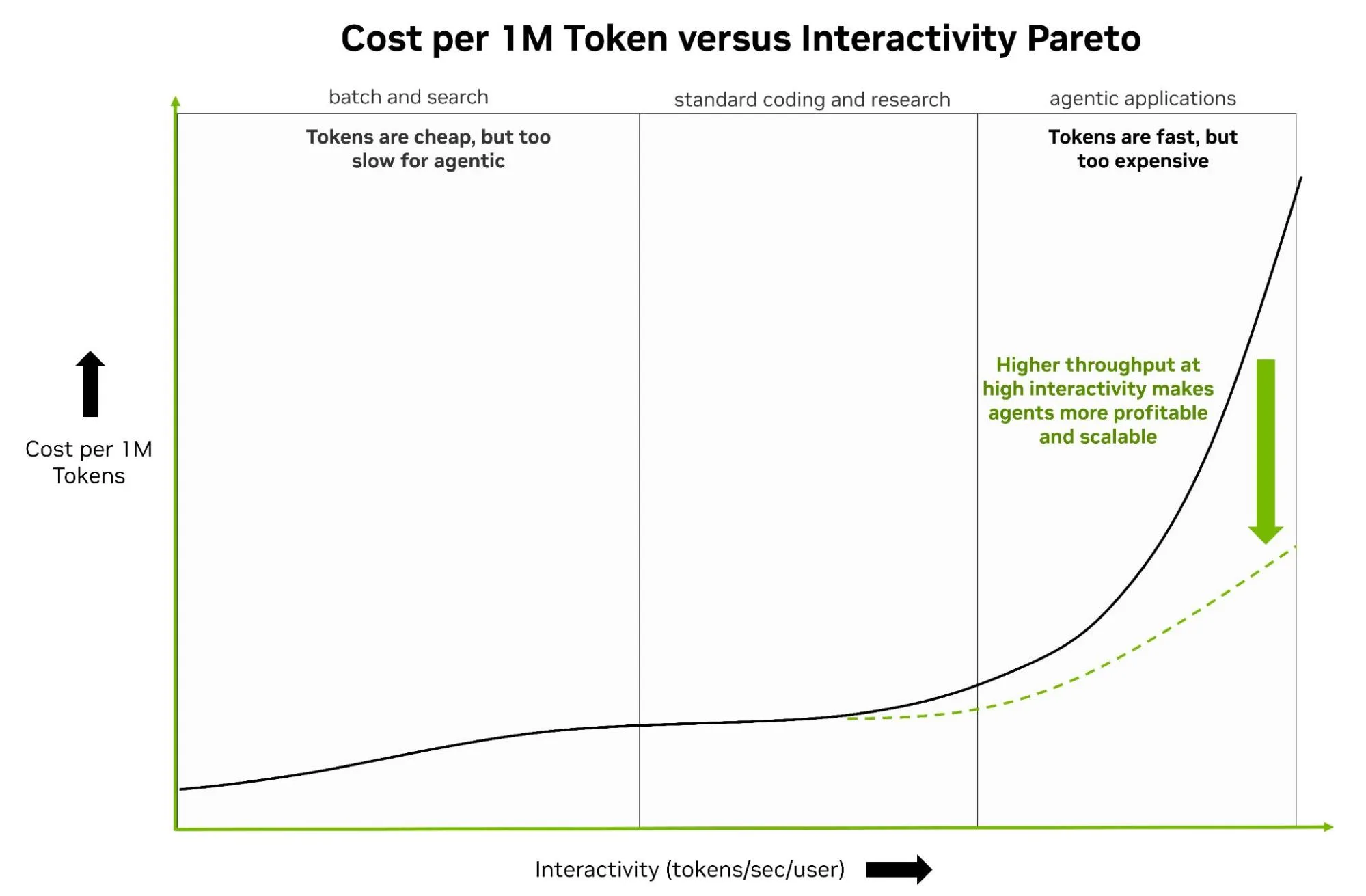
Hình 7. Đường cong Pareto định tính minh họa sự đánh đổi giữa chi phí trên mỗi triệu token và tính tương tác trong các khối lượng công việc xử lý theo lô, lập trình tiêu chuẩn và ứng dụng dựa trên tác nhân.
Để phá vỡ nút thắt cổ chai này, cần có sự thay đổi hoàn toàn trong thiết kế cơ sở hạ tầng. GPU hiện đại cung cấp khả năng tính toán khổng lồ và băng thông đáng kể, nhưng duy trì quy mô ở độ trễ thấp đòi hỏi nhiều hơn bất kỳ kiến trúc đơn lẻ nào có thể cung cấp. Câu trả lời là thiết kế đồng bộ cực kỳ hiệu quả. Cách tiếp cận này tối ưu hóa suy luận trên phần cứng chuyên dụng cho từng giai đoạn và giao phó những thách thức riêng biệt này cho toàn bộ nền tảng chứ không chỉ một bộ xử lý.
Vì sao một bộ xử lý là không đủ
Những yêu cầu đặc thù này sẽ không được giải quyết chỉ bằng cách tăng thêm số phép tính FLOP và dung lượng bộ nhớ. Các yêu cầu này xuất phát từ đặc tính kiến trúc của cách thức hoạt động của các tác nhân, và không một bộ xử lý nào có thể giải quyết chúng cùng một lúc.
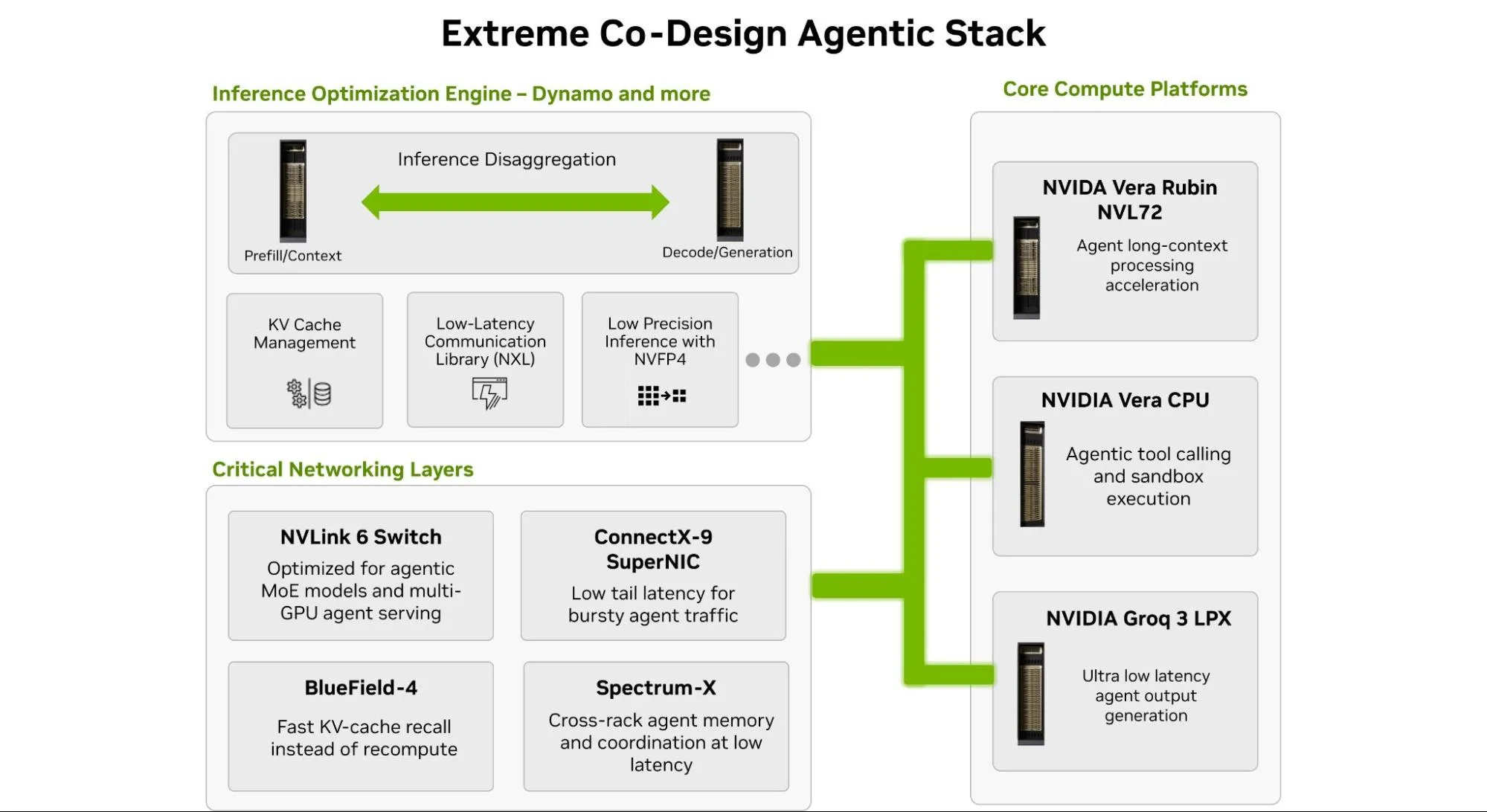
Hình 8. Sơ đồ minh họa một phần chiến lược đồng thiết kế cực kỳ hiệu quả của NVIDIA, nhấn mạnh lợi ích cho các tác vụ dựa trên tác nhân.
Điều cần thiết là một nền tảng trong đó mỗi điểm nghẽn được ánh xạ tới phần cứng chuyên dụng, được điều phối như một hệ thống thống nhất với sự đồng thiết kế tối ưu (xem Hình 8, ở trên):
- Nền tảng
- Vera Rubin NVL72 xử lý dung lượng và tính toán với chi phí trên mỗi triệu token chỉ bằng một phần mười so với Blackwell . Dung lượng HBM là yếu tố giúp cho các pipeline xử lý dữ liệu dài hạn trở nên khả thi; mật độ tính toán giúp giảm chi phí điền dữ liệu trước khi xử lý ở quy mô lớn.
- Vera CPU thu hẹp khoảng cách thực thi công cụ với độ trễ tác nhân thấp hơn, khả năng chuyển tải bộ nhớ đệm KV liền mạch và thực thi CPU-GPU thống nhất.
- Groq 3 LPX phá vỡ sự đánh đổi giữa thông lượng và độ trễ. Kiến trúc ưu tiên SRAM mang lại khả năng tạo token với độ trễ thấp và giới hạn chặt chẽ — điều cực kỳ quan trọng khi sự biến đổi trong bất kỳ tác nhân nào lan truyền khắp toàn bộ quy trình.
- Các chip mạng (bộ chuyển mạch NVLink 6, ConnectX – 9 SuperNIC, BlueField – 4 DPU và Spectrum – X Ethernet) tạo ra một kiến trúc phục vụ thống nhất, độ trễ thấp cho các khối lượng công việc dựa trên tác nhân, cho phép các tác nhân phối hợp nhanh hơn, duy trì khả năng truy cập ngữ cảnh được chia sẻ và tránh việc tính toán lại tốn kém khi số lượng phiên tăng lên.
- Các thành phần của ngăn xếp phần mềm:
- Dynamo và Attention-FFN Disaggregation (AFD) tạo ra một đường dẫn phục vụ mạch lạc bằng cách phân chia công việc cho các bộ xử lý phù hợp nhất và điều phối việc thực thi để giảm thiểu xung đột tài nguyên và độ trễ. Ngoài ra, Dynamo còn cung cấp khả năng lập trình bộ nhớ đệm cho hệ thống điều khiển tác nhân.
- NVFP4 giảm thiểu chi phí xử lý chính xác, cho phép các tác nhân MoE hoạt động với độ trễ thấp hơn, thông lượng cao hơn và áp lực bộ nhớ thấp hơn mà không làm giảm hiệu năng.
- TRT-LLM WideEP tối ưu hóa khả năng xử lý song song của các chuyên gia quy mô lớn cho các MoE tiên tiến, cho phép các tác nhân cung cấp phản hồi thông minh cao với độ trễ thấp hơn và thông lượng cao hơn.
- Giải mã suy đoán giúp giảm độ trễ phản hồi của tác nhân bằng cách tạo ra các token có khả năng xảy ra song song và xác minh chúng nhanh chóng, tăng tốc quá trình suy luận độ trễ thấp cho các mô hình lớn.
Bằng cách kết hợp bảy chip này và một bộ phần mềm thông qua thiết kế đồng bộ tối ưu, nền tảng Vera Rubin có thể cung cấp hơn 400 tokens mỗi giây cho mỗi người dùng trên các mô hình MoE nghìn tỷ tham số với ngữ cảnh lớn 400k. Mức hiệu năng này thay đổi mô hình đánh đổi truyền thống đối với các tác nhân – bạn không còn cần phải hy sinh chất lượng bằng cách sử dụng các mô hình nhỏ hơn và cửa sổ ngữ cảnh hạn chế để đạt được tốc độ cao cho mỗi người dùng và thông lượng hệ thống cao. Trong lĩnh vực này, kiến trúc tác nhân trở thành sản phẩm khả thi ở quy mô lớn thay vì những thử nghiệm tốn kém.
Để biết thêm chi tiết về thông số kỹ thuật của nền tảng Vera Rubin và LPX, hãy xem các bài đăng trên blog ngày ra mắt sản phẩm của họ:
- Bên trong nền tảng NVIDIA Vera Rubin: Sáu chip mới, một siêu máy tính AI.
- Bên trong NVIDIA Groq 3 LPX: Bộ tăng tốc suy luận độ trễ thấp dành cho nền tảng NVIDIA Vera Rubin.
Bài viết liên quan
- Hướng dẫn tạo LangChain Deep Agents Harness Profile cho NVIDIA Nemotron-3 Ultra để tối ưu hóa hiệu năng hệ thống Agent
- BioNeMo Agent Toolkit: Khi AI Agent bước vào phòng thí nghiệm số
- NVIDIA dẫn đầu hiệu suất Agentic Coding trên bài đo benchmark Agentic AI đầu tiên
- Khám phá Omniverse: 3 quy trình giúp cải thiện độ chính xác của Vision AI Agent với dữ liệu tổng hợp và fine-tuning
- NVIDIA Nemotron 3 Ultra tăng cường khả năng suy luận nhanh hơn, hiệu quả hơn cho các agent chạy trong thời gian dài
- Kỷ nguyên của Agentic AI: Hạ tầng Blackwell thiết lập tiêu chuẩn hiệu năng mới với Benchmark AgentPerf