
Trong thế giới AI đang phát triển không ngừng, sau các mô hình ngôn ngữ lớn (LLM) làm mưa làm gió, một khái niệm mới đang nổi lên và hứa hẹn sẽ đưa trí tuệ nhân tạo tiến thêm một bước lớn: Trí tuệ Nhân tạo Đa Phương thức (Multimodal AI).
Bài viết này sẽ giới thiệu chi tiết về Multimodal AI – công nghệ mô phỏng cách con người cảm nhận và xử lý thế giới, kết hợp thông tin từ nhiều giác quan cùng một lúc.
Multimodal AI là gì? Bước tiến hóa mới của AI
Trí tuệ Nhân tạo Đa Phương thức (Multimodal AI) là thế hệ AI tiếp theo, được thiết kế để xử lý, tích hợp và hiểu nhiều loại dữ liệu (hay còn gọi là “phương thức” – modalities) một cách đồng thời.
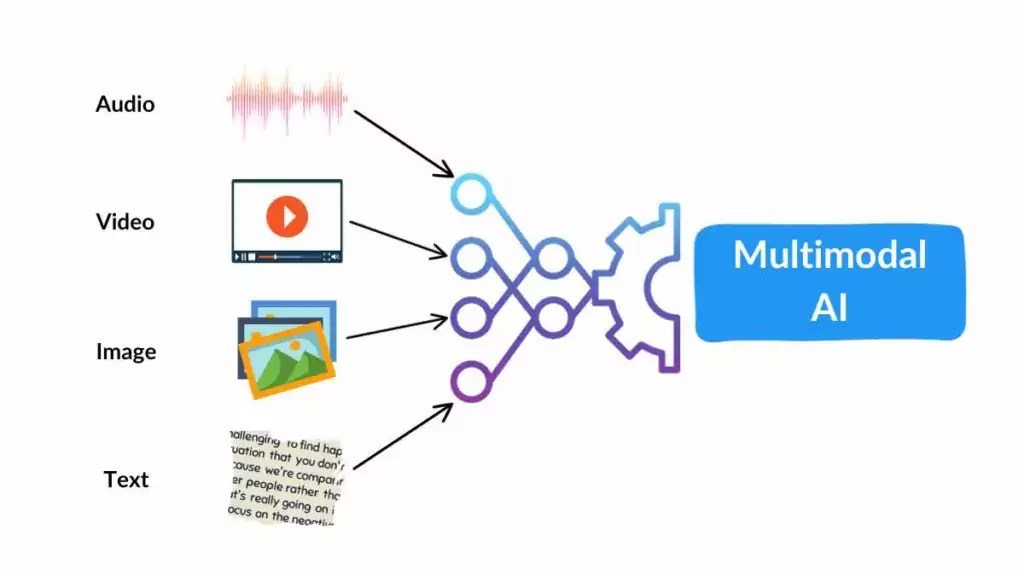
Trong ngữ cảnh AI, phương thức (modality) chỉ đơn giản là các loại dữ liệu khác nhau mà hệ thống có thể tiếp nhận, bao gồm:
- Văn bản (Text): Các từ, câu, tài liệu.
- Hình ảnh (Images): Ảnh tĩnh, đồ họa.
- Âm thanh (Audio): Giọng nói, tiếng ồn, âm nhạc.
- Video: Sự kết hợp của hình ảnh và âm thanh theo thời gian.
- Dữ liệu Cảm biến: Nhiệt độ, áp suất, dữ liệu xúc giác, v.v.
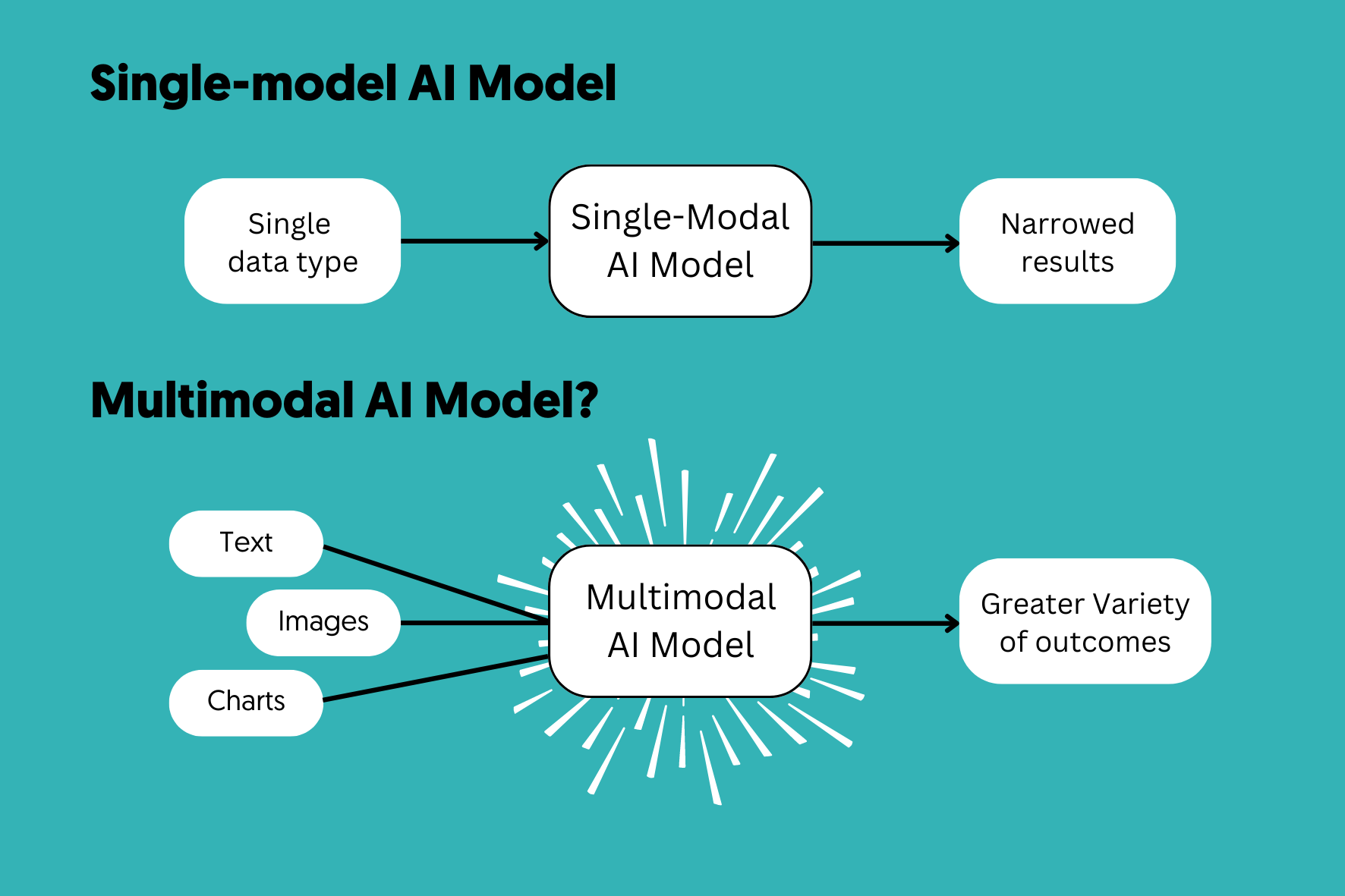
Khác với các hệ thống AI Đơn Phương thức (Unimodal AI) truyền thống (ví dụ: một mô hình chỉ xử lý văn bản như các phiên bản đầu của ChatGPT), Multimodal AI có thể nhận đầu vào từ nhiều nguồn khác nhau—chẳng hạn như văn bản và hình ảnh—để tạo ra kết quả phong phú và phức tạp hơn.
Ví dụ tiêu biểu:
- GPT-4V (Vision) của OpenAI: Có thể phân tích cả văn bản và hình ảnh.
- Runway gen-2: Tạo video từ mô tả văn bản.
Cơ chế hoạt động: Cách multimodal AI Tạo ra sự hiểu biết toàn diện
Để có thể hiểu được một thế giới đa dạng như con người, Multimodal AI phải trải qua một quy trình xử lý phức tạp, thường được chia thành ba thành phần chính:
1. Module đầu vào (Input module)
Hệ thống bắt đầu bằng cách sử dụng các mạng lưới thần kinh đơn phương thức (unimodal neural networks) riêng biệt để xử lý từng loại dữ liệu đầu vào.
- Mạng nơ-ron cho văn bản sẽ mã hóa văn bản.
- Mạng nơ-ron cho hình ảnh sẽ xử lý pixel và trích xuất đặc trưng.
2. Module kết hợp (Fusion module) – Trái tim của Hệ thống
Đây là nơi kỳ diệu xảy ra. Module kết hợp có nhiệm vụ căn chỉnh và hợp nhất các luồng dữ liệu khác biệt này. Nó phải học cách hiểu mối quan hệ ngữ nghĩa giữa một đoạn văn bản và một hình ảnh tương ứng.
Các kỹ thuật kết hợp (Fusion) phổ biến:
- Kết hợp sớm (Early fusion): Dữ liệu được hợp nhất ngay từ giai đoạn đầu, trước khi trích xuất đặc trưng sâu.
- Kết hợp giữa (Mid fusion): Kết hợp sau khi các đặc trưng đã được trích xuất từ mỗi phương thức.
- Kết hợp muộn (Late fusion): Mỗi phương thức đưa ra dự đoán riêng, và module hợp nhất các kết quả cuối cùng này để đưa ra quyết định tổng thể.
Mục tiêu là tạo ra một biểu diễn chung thống nhất (unified understanding) của các dữ liệu đầu vào.
3. Module đầu ra (Output module)
Dựa trên biểu diễn chung đã được hợp nhất, module này tạo ra kết quả mong muốn, có thể là văn bản, một hình ảnh mới, hoặc thậm chí là một hành động (như trong xe tự lái).
Lợi ích vượt trội và Ứng Dụng thực Tế
Khả năng kết hợp các phương thức mang lại cho Multimodal AI những lợi thế đáng kể so với các mô hình truyền thống:
Lợi ích
- Hiểu ngữ cảnh chính xác hơn: Bằng cách xem xét nhiều loại dữ liệu, mô hình có thể tạo ra kết quả chi tiết, nhiều sắc thái và bám sát ngữ cảnh hơn, gần giống với cách con người suy nghĩ.
- Giải quyết vấn đề phức hợp: Multimodal AI là công cụ lý tưởng cho các vấn đề đòi hỏi nhiều loại thông tin khác nhau. Ví dụ: hệ thống chăm sóc khách hàng có thể đọc khiếu nại bằng văn bản và phân tích ảnh đính kèm về sản phẩm bị hỏng để đưa ra quyết định bồi thường.
- Tương tác tự nhiên hơn: Kết quả đầu ra mang tính “con người” và trực quan hơn.
Ứng dụng Thực tế
| Lĩnh vực | Ứng dụng Multimodal AI |
| Y tế & Chẩn đoán | Tích hợp dữ liệu từ kết quả chụp chiếu (ảnh), hồ sơ bệnh án (văn bản) và xét nghiệm di truyền để hỗ trợ chẩn đoán toàn diện và chính xác hơn. |
| Xe tự lái | Thiết yếu để diễn giải dữ liệu từ nhiều loại cảm biến (camera, LiDAR, radar) theo thời gian thực để đưa ra quyết định lái xe an toàn. |
| Trợ lý Ảo (Virtual assistants) | Trợ lý ảo như Siri, Alexa trở nên tinh vi hơn, có thể hiểu lệnh bằng giọng nói, phân tích hình ảnh và trả lời bằng văn bản/giọng nói. |
| Giải trí & Game | Tạo ra các nhân vật game với trí tuệ động và cốt truyện có thể thay đổi dựa trên đầu vào đa phương thức của người chơi. |
Thách thức và Vấn đề Đạo đức
Dù đầy hứa hẹn, con đường phát triển Multimodal AI vẫn còn nhiều chông gai:
1. Thách thức Kỹ thuật
- Khối lượng Dữ liệu Đa Dạng: Cần một lượng lớn dữ liệu đa phương thức, được gán nhãn chính xác để mô hình có thể học được mối quan hệ giữa các loại dữ liệu. Việc thu thập và chú thích dữ liệu này rất tốn kém và mất thời gian.
- Căn chỉnh và Kết hợp Dữ liệu: Hợp nhất các loại dữ liệu khác nhau—vốn có mức độ nhiễu khác nhau và thường không được căn chỉnh theo thời gian hoặc không gian—là một bài toán cực kỳ phức tạp.
- Dịch chuyển Giữa các Phương thức (Modal translation): Đảm bảo mô hình hiểu được ngữ nghĩa và bối cảnh để tạo ra đầu ra ở phương thức này (ví dụ: hình ảnh) từ đầu vào ở phương thức khác (ví dụ: văn bản).
2. Vấn đề Đạo đức và Quyền riêng tư
- Quyền riêng tư: Hệ thống dựa vào khối lượng dữ liệu khổng lồ, thường bao gồm thông tin cá nhân và nhạy cảm, đặt ra yêu cầu bảo vệ dữ liệu ở mức độ ưu tiên cao nhất.
- Thiên vị (Bias) và Phân biệt đối xử: Dữ liệu huấn luyện nếu phản ánh những định kiến xã hội sẽ khiến AI tạo ra các kết quả thiên vị hoặc phân biệt đối xử.
- Vấn đề “Hộp đen” (Black box): Sự phức tạp của các mô hình đa phương thức khiến việc kiểm tra và hiểu quy trình ra quyết định của chúng trở nên khó khăn hơn nhiều so với các mô hình đơn phương thức.
Tương lai của Multimodal AI
Multimodal AI là một bước nhảy vọt quan trọng. Mặc dù cần thời gian để vượt qua các rào cản về kỹ thuật và đạo đức, công nghệ này chắc chắn sẽ trở thành một phần không thể thiếu trong nhiều ngành công nghiệp, từ y tế đến giải trí.
Khi lĩnh vực này trưởng thành, chúng ta có thể mong đợi các hệ thống Multimodal AI sẽ trở nên đáng tin cậy, hiệu quả và có khả năng mở rộng hơn, mang lại những trải nghiệm phong phú và bối cảnh hóa tốt hơn cho người dùng.
Với khả năng mô phỏng nhận thức con người, Multimodal AI không chỉ là một công cụ mà còn là một cánh cửa mở ra kỷ nguyên tương tác mới giữa con người và máy móc.
Bài viết liên quan